基于YOLOv3的自然环境下茶叶嫩芽目标检测方法研究
2021-03-15施莹莹李祥瑞孙凡
施莹莹 李祥瑞 孙凡
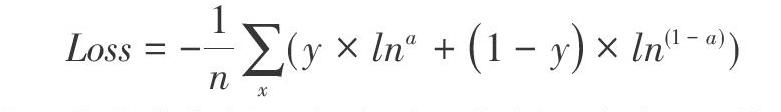

摘要:以自然环境下手机拍摄的多天气情况、多品种的茶叶嫩芽图像为实验样本数据集,研究茶叶嫩芽目标检测方法。采用基于深度神经网络的YOLOv3算法构建模型,将经过数据增强处理的多品种茶叶嫩芽图像作为模型输入,通过单一的特征提取网络,进行多尺度目标检测,对输入图像进行粗、中、细的网格划分,将茶叶嫩芽目标检测任务看作目标区域预测和类别预测的回归问题。实验结果表明,基于YOLOv3的目标检测算法对自然环境下多品种的茶叶嫩芽目标具有较高的召回率及检测精度,为农业机械化、智能化提供了思路。
关键词:目标检测;YOLOv3;茶叶嫩芽识别;深度学习
中图分类号:TP3 文献标识码:A
文章编号:1009-3044(2021)03-0014-03
中国茶文化源远流长,而茶叶作为茶文化的中心,同时也是中国与世界文化沟通的桥梁之一,其种植与采摘自然是不可忽视的方面。目前,主要的茶叶采摘方式分为人工采摘和机械采摘2种。一方面,人工采摘虽然能较准确地识别嫩芽,但效率低下、成本高昂,且在采茶洪峰时期务工难[1];另一方面,使用机械采摘代替人工手采虽能提高采摘速度,但采摘时老叶、嫩叶、嫩芽一起采,缺乏选择性,并有部分叶片遭破损现象,降低了原料品质[2]。因此,研究一种面向自动采茶装置的高效、低损伤的茶叶嫩芽目标检测方法十分必要。
目前,茶叶嫩芽的识别与检测主要依赖于茶叶形状和颜色特征的提取,且大多是基于传统机器学习和数字图像处理技术的。如杨福增[3]等针对白色背景下的茶叶图像,利用其在RGB颜色空间中的G分量,通过双阈值方法进行分割,再根据茶叶嫩芽的形状特征进行边缘检测,展开嫩芽识别的研究。吴雪梅[2]等提出基于茶叶嫩芽图像在Lab颜色模型中a分量、b分量信息的K -means聚类法,为智能采摘技术的研究提供了支持。
近年来,由于深度神经网络在目标检测领域的发展迅速,一系列框架及经典算法的相继出现,如R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD等目标检测网络为目标的精确定位与检测提供了基础。孙肖肖[4]等基于端到端检测框架的代表算法YOLO,通过超绿特征以及OSTU算法的结合对复杂背景下的茶叶嫩芽进行预处理分割,用大尺度和中尺度检测,进行了有较高精度的茶叶嫩芽目标检测。
鉴于自然环境下茶叶嫩芽的识别研究有待深入展开,且目前尚无适用于多品种、多天气情况下的茶叶嫩芽目标检测算法的研究成果,本研究以清明前后、晴天阴天多种情况下的待采摘茶叶为研究对象,基于YOLOv3算法检测图像中的茶叶嫩芽,拟为快速识别多场景、多品种的茶叶嫩芽目标提供有效的经验。
1 基本理论
1.1 YOLOv3基本思想
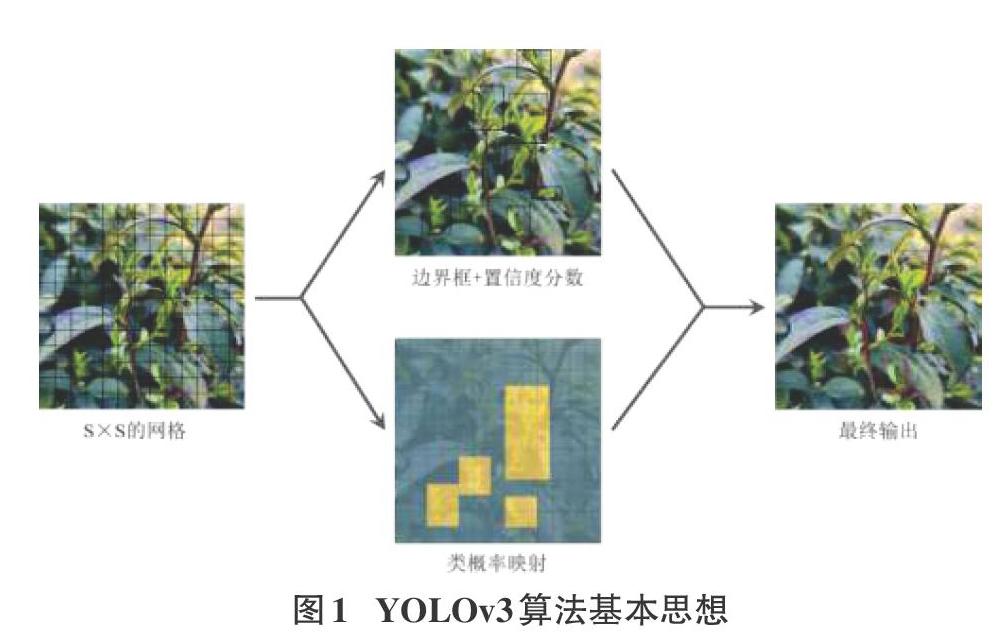
YOLO(You Only Look Once)与其他two-stage算法(例如Fast RCNN、Faster RCNN、Mask RCNN)不同,是一种采用单步(one-stage)檢测的算法,two-stage算法是将目标位置框的检测和分类预测分为两步进行,而YOLO通过先提出候选框,再进行分类的方法,直接将目标检测问题处理为回归问题,即使用一个神经网络就可以完成图像的边界框(bounding box)和类概率(class probabilities)的预测。因此,可以实现端到端的物体检测性能优化[5]。
YOLO中,先将图像划分为S×S的网格,每个网格负责监测中心落入格子中的目标。每个网格都会输出边界框(bounding box),置信度分数(confidence scores)和类概率(class probability map),如图1所示。其中,bounding box包含x,y,w,h四个值,box中心用(x,y)表示,box的宽和高用(w,h)表示,预测框包含一个对象的模型的置信度即它认为该框预测的准确性用confidence scores表示,置信度在形式上定义为[PrObject*IOUtruthpred],[PrObject]为单元格中存在目标的概率,[IOUtruthpred]为预测框与真实框之间的IOU值,物体的类别概率表示为class probability,在YOLOv3中采用的是二分类的方法。
在推理阶段,通过置信度定义得到每个网格中的各类置信度得分,然后将低于设定阈值分数的检测框过滤掉,而后用非极大值抑制算法(non-maximum suppression, NMS)处理剩下的检测框。此外,在预测对象类别时,以logistic回归模型替代softmax逻辑回归模型,以便支持多标签对象的分类。
1.2 特征提取网络结构
YOLOv3算法的特征提取网络结构为DarkNet-53结构[6],它主要由卷积层和残差模块所组成,没有池化和全连接层。当网络层数过多时,会出现梯度消失问题,因此DarkNet-53届用了残差网络(ResNet)的思想,通过在网络结构中加入残差模块来解决该问题。为了使网络集中地学习输入和输出之间的残差,残差模块通过恒等映射(identity mapping)的方法在输入和输出之间建立了一条直接关联的通道。其中,每个残差模块都是由两个卷积层和一个快捷链路(shortcut connections)组成。而每个卷积层的实现又包含了卷积层Conv2d,批量归一化曾(Batch Normalization)和激活函数LeakyReLU,每个残差模块之后加上zero padding对图片等的2D输入进行边界填充(填充数字0),来控制卷积操作以后的特征图的大小。
1.3 多尺度检测
YOLOv3采用3种不同尺度的特征图,对输入的图像进行细、中和粗的网格划分,从而分别实现对小、中和大物体的预测。在前向传播的过程中,张量的尺寸变换是 通过卷积核的步长改变来达到的,如stride=(2, 2),这就相当于将图像边长缩小一半( 即图像面积缩小为原来的1/4),经历5次下采样变换,网络会将输出特征图缩小到输入的1/25(即1/32)。因此,输入图像尺寸 一般是32的倍数,那么如果输入图像尺寸为416×416时, 那么得到细、中和粗网格尺寸分别为52×52、26×26和13×13。
1.4 损失函数
YOLOv3将目标检测看作是目标类别预测和区域预测的回归问题,YOLOv3的损失函数包括置信度损失、框回归损失及分类损失。其中,置信度损失,用于判断预测框有无目标,分辨图片的背景和前景区域,其判定规则为:如果一个预测框与所有真实框的IOU都小于某个阈值,那么就判定它是背景,否则为前景(包含目标);框回归损失,仅在预测框中包含预测目标时计算;分类损失,采用二分类交叉熵(即把所有类别的分类问题归结为是否属于这个类别),公式为
如此便将多分类问题理解为二分类问题,有益于排除类别的互斥性和解决因为多个 类别物体重叠导致的漏检问题。
2 实验方法
2.1 数据获取
首先要确定数据收集范围、数据类型及总量。目前主流手机后置摄像头成像效果足够清晰,满足实验要求,故本文采用手机后摄,使用正常的采摘距离、多角度进行拍摄,模拟人工采茶的实际情况。实验选择镇江五峰白茶、安徽养心谷黄茶、青茶和青岛崂山绿茶共4个品种的茶叶,分别在2019年10月、2020年4月前往对应茶场拍摄,共计拍摄3340张有效原始图像。构成数据集的茶叶品种多样,茶叶的实际拍摄场景包括晴天和阴天2种不同天气状况下拍摄的图像,以此确保模型具有良好的泛化能力和鲁棒性。拍摄的图像如图2所示。
2.2 工具选择
基于前述YOLOv3算法的特点,本研究采用Tensorflow2进行模型构建。通过tf.keras,能够方便地构建、修改网络模型结构。该框架支持多种硬件加速和分布式运算,大大提高模型的训练速度。其对多种语言的支持也保证了模型的可移植性。
2.3 算法流程
基于YOLOv3算法,使用DarkNet-53的网络结构,准备标注好的茶叶嫩芽图像数据集、标注框类别的汇总(即数据集中所标注物体的全部类别)、预测特征图的anchor框集合作为模型输入参数。输入图像将统一缩放到416×416,通过随机剪裁、旋转、镜像等对数据进行增强处理。将预训练模型的权重及上述参数输入网络模型,模型通过边界框的K-Means聚类,产生3个尺度的特征图,每个特征图3个anchor框,共9个框。根据预测结果计算损失函数值,对网络权重使用反向传播和Adam作为优化器的梯度下降算法进行调整,拟合输入与输出之间的关系。在训练的过程中,不 断保存每个epoch完成后 的模型权重,直到训练完成。
3 结果与分析
实验所用复杂背景多光照下四种茶叶嫩芽图像数据集信息如表1所示。
实验测试环境为普通笔记本电脑,实验代码适用于Windows、Mac及Linux。将测试集中的茶叶嫩芽图像输入到 训练好的网络模型中,即可得到每张检测图像,四种茶叶嫩芽的测试结果如图3所示。
由于在以前的研究中没有使用多类型多光照条件下的茶叶嫩芽图像数据,本实验具有开创性,因此在此只列举本文算法的数据结果。根据训练及测试结果计算mAP(平均精度均值,mean average precision),mAP是对检测器检测各个类别的AP(平均精度,average precision)求平均值,由于本文中所有茶叶嫩芽分为一类,故mAP即为AP。本文提出的算法在复杂背景不同光照下四种茶叶嫩芽图像数据集上的AP和Recall结果如表2所示。
由表2可得,本文在多种类多光照条件对复杂背景下对茶叶嫩芽检测的召回率Recall的表现较好,平均精度AP的表现一般。因为AP是在召回率Recall从0到1各个点的查准率Precision的均值,所以可以推出查准率Precision的表现一般。我们多次就单张图片进行测试,分析后发现,由于所有标签是人为标注的,且复杂背景下图片中茶叶嫩芽数量较大,因此难免会有遗漏的情况,而当模型将没有标注到的嫩芽识别出来时,会被认定为False Positives,因此降低了查准率,实际上的查准率应略高于当前查准率,则AP也应当略高于0.637。
根据模型我们也开发了相应的可视化界面,可以直接运行可视化界面进行单张图片的上传、检测与结果分析,如图4所示。
4 结论
针对复杂背景下茶叶嫩芽目标检测问题,本文创新性地使用了多种光照条件、多种类型的茶叶嫩芽数据集作为网络输入,使得模型具有较强泛化能力与检测效果。首先,使用数据增强扩充数据集,然后采用基于深度学习的YOLOv3目标检测算法对茶叶嫩芽进行检测,最后开发了可视化界面方便用户使用。在下一步的实验中,拟采用GAN生成对抗网络(generative adversarial networks)或者迭代的形式进行标签的标记,来解决查准率较低的问题。
参考文献:
[1] 邵明. 基于计算机视觉的龙井茶叶嫩芽识别方法研究[D]. 中国计量学院,2013.
[2] 吴雪梅,唐仙,张富贵,等.基于K-means聚类法的茶叶嫩芽识别研究[J].中国农机化学报,2015,36(5):161-164,179.
[3] 杨福增,杨亮亮,田艳娜,等.基于颜色和形状特征的茶葉嫩芽识别方法[C]//智能化农业信息技术国际学术会议,2009.
[4] 孙肖肖,牟少敏,许永玉,等.基于深度学习的复杂背景下茶叶嫩芽检测算法[J].河北大学学报(自然科学版),2019,39(2):211-216.
[5] Redmon J,Divvala S,Girshick R,et al.You only look once:unified,real-time object detection[EB/OL].2015:arXiv:1506.02640[cs.CV].https://arxiv.org/abs/1506.02640
[6] Redmon J , Farhadi A . YOLOv3: An Incremental Improvement[J]. arXiv e-prints, 2018.
【通联编辑:代影】
