基于步态特征提取的ELM身份识别方法
2021-03-15马添力肖文栋
马添力,肖文栋
(1.北京科技大学自动化学院,北京 100083;2.北京市工业波谱成像工程技术研究中心,北京 100083)
0 引言
利用步态信息进行身份识别是近年来新兴的一种生物识别技术,它根据人体的步态特征来进行身份的认证。某些场景下,人们会对自己进行乔装打扮,比如戴口罩和帽子以及化妆等,但自身的步态特征难以控制。在多重因素的影响下,人体走路姿态具有唯一性。相较于其他生物识别技术,利用步态信息作身份识别具有非侵犯性、不易察觉、不易伪装、远距离识别等优点[1],在安防领域具有非常大的应用前景和广阔的研究空间。
利用步态信息识别身份的研究方法主要有两类:基于非模型方法和基于模型的方法[2]。非模型的方法是对人体步态的轮廓、外形和原始图像等进行特征提取,从而进行身份识别[3]。基于模型的方法是指对人体或者运动进行建模,获得如人体的重心、肢体长度、关节角度、运动速度等参数,在模型上进行度量和分类。这类方法存在计算量大、模型难以准确建立的问题。在分类的方法上,目前大多采用支持向量机(support vector machine,SVM)或深度学习的方法,存在训练时间长、分类准确率不高的问题。
本文采用非模型的方法,利用步态能量图作为识别基础;为了解决训练时间长和准确率不高的问题,采用超限学习机(extreme learning machine,ELM)算法进行分类。与传统的训练方法相比,ELM具有学习速度快、泛化性能好等优点。测试结果表明,采用ELM算法可以在保证准确率的前提下大幅缩短训练时间。
1 基础工作
1.1 运动目标检测
首先将步态视频数据进行分帧处理,然后对分帧后的图像序列进行运动目标检测。运动目标检测的目的是提取步态图像中有用的目标信息,削减图像中的无效信息,便于后期对图像进行处理和分析。常用的目标提取方法包括帧差法、光流法、背景减除法[4]。帧差法对于背景缓慢变化的情况不敏感;光流法计算复杂,实时性很差;背景减除法简单、快速,适合视频采集设备固定的场景。本文利用背景减除法提取运动目标。
背景减除法主要包括以下三种算法[5]:Back ground Subtract or MOG、 Back ground Subtract or GMG和Back ground Subtract or MOG2(以下简称MOG、GMG和MOG2)。其中,GMG算法仅用很少的图像进行背景建模,准确度不高,现在使用的很少。本文选用MOG2算法进行前景提取。该算法是以高斯混合模型为基础的前景分割算法。这个算法的特点是它为每一个像素选择一个合适数目的高斯分布,相比于MOG算法中使用的K高斯分布(K为3或5),MOG2算法更适用于亮度发生变化而引起的场景变化。该算法还可以进行阴影检测,速度也快于MOG算法。MOG2算法前景提取示意图如图1所示。

图1 MOG2算法前景提取示意图
1.2 形态学处理
通过背景减除法获得的步态图像存在空洞、噪声等影响。为了减小这些瑕疵对最终识别的影响,可采用图像处理中的形态学方法对获得的二值步态图像进行处理。常用的形态学方法有腐蚀、膨胀、开操作、闭操作等。
腐蚀是一种简单地消除不相关元素的方法,可以消除图像中的噪声等。其定义为:
AΘB={x|(B)x⊆A}
(1)
式中:A为图像;B为结构元素;AΘB为B对A进行腐蚀操作,即使用B遍历A,去除两者不完全相交的像素值,以达到腐蚀的目的。
膨胀可以看作是一种简单的连接操作,可以修复图像中的断裂。其定义为:
(2)
在腐蚀和膨胀的基础上,又得到了开操作和闭操作两种处理方法。
开操作能够平滑物体的轮廓,断开细小的间隔。其定义为:
A°B=(AΘB)⊕B
(3)
式中:A为图像;B为结构元素;AB为B对A进行开操作。
闭操作能够将图像中细小的空洞填充完整并且也可以平滑物体的边界。其定义为:
A·B=(A⊕B)ΘB
(4)
式中:A为图像;B为结构元素;A·B为B对A进行闭操作。
本文对二值化后的步态图像先进行开操作,再进行闭操作。形态学处理前后对比图如图2所示。
图2 形态学处理前后对比图
1.3 步态图像归一化
一般视频采集设备是固定的,这就导致了在视频设备的采集范围内目标的形状由小到大再变小的过程,产生了不一致性。在步态特征提取过程中,相同的目标图像会有更好的表达。因此,采用归一化的方法对步态图像进行处理,使不同运动目标的图像相同,包括运动目标在图像中的位置和大小[6]。
步态图像归一化首先从二值步态图像中提取出人体运动目标,通过遍历步态图像的像素点找到人体轮廓的边界,以此生成最大的运动目标矩形框,并裁剪出人体目标轮廓图像。在程序中,设置图像大小,将目标图像归一化至64×64像素。归一化前后对比图如图3所示。

图3 归一化前后对比图
2 ELM算法介绍
ELM是一类基于单隐层前馈神经网络的机器学习算法。ELM算法随机产生输入层与隐藏层的连接权值,通过最小二乘优化来训练网络,且在训练过程中无需调整,只需要设置隐藏层神经元个数,便可获得唯一的最优解,学习过程仅需计算输出权重。ELM具有学习效率高、泛化能力强的优点,被广泛应用于分类、回归、聚类、特征学习等问题中[7]。
单隐层神经网络原理如图4所示[8]。

图4 单隐层神经网络原理图
若有N个任意的样本{(Xi,ti)}Ni=1⊂Rn×Rm,对于一个由L个隐藏层节点的单隐层神经网络,可以表示为:
(5)
式中:g(x)为激活函数;WI=[ωi1,ωi2,…,ωin]T为输入权重;βI为输出权重;bi为第i个隐藏层单元的偏置;WiXj为Wi和Xj的内积。
该神经网络的学习目标是使得输出的误差最小,可表示为:
(6)
即存在βi、Wi和bi,使得:
(7)
将式(7)矩阵表示为Hβ=T。其中,H为隐藏层的输出矩阵,具体表示为:
H(W1,W2,…,WL,b1,b2,…,bL,X1,X2,…,XL)=
(8)
β为输出权重,T为期望输出,可分别表示为:

(9)
其中,i=1,2,…,L。这等价于最小化损失函数:
(10)
综上所述,ELM的训练分为以下三步。
①随机分配隐藏层参数。
②计算隐藏层输出矩阵H。
③得到输出权重向量β。
输出权重β可以被确定为:
(11)
式中:H+为矩阵H的Moore-Penrose广义逆。
3 本文所提方法
系统结构如图5所示。
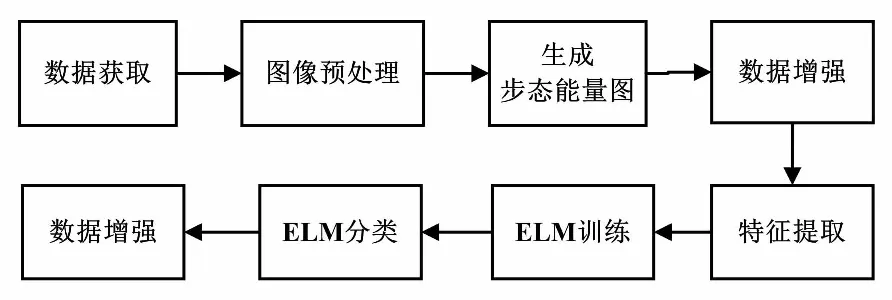
图5 系统结构图
身份识别过程可以分为两个阶段:第一阶段是利用特征提取算法进行步态特征的提取;第二阶段是采用ELM算法进行分类。第一步是进行图像的特征提取,采用步态能量图(gait energy image,GEI)作为输入。
3.1 步态能量图
首先介绍GEI的构造过程。人体行走可以视为周期性动作。图6是步态序列周期图。从图6可以看出,人体行走行为呈周期性展现。
图6 步态序列周期图
一个周期内的二值图像如图7所示。灰度级的GEI定义为:
(12)
式中:N为一个周期内的图像帧数目,通过视频分帧和图像预处理可以得到每一帧二值步态图;bI(x,y)为周期内的每一帧二值步态图;x,y为二维图像平面坐标;G(x,y)为步态能量图。
一个周期内的二值图像如图7所示。

图7 一个周期内的二值图像
步态能量图反映了人体行走的步态轮廓在一个周期内的变化。相比一般的二值图像,GEI对图像序列中的个别帧的图像轮廓变形没有那么敏感,对噪声有很好的鲁棒性。GEI反映了侧影的主要形状和在步态周期上人体运动信息的变化,可以作为身份识别的依据。步态能量如图8所示。
图8 步态能量图
3.2 HOG特征提取
梯度方向直方图(histogram of oriented gradient,HOG)是图像处理中的一种特征提取算法。HOG算法原理图如图9所示。

图9 HOG算法原理图
HOG特征是将图像像素点的方向梯度作为图像特征,包括梯度大小和方向。通过计算图像局部区域的梯度直方图特征,将局部的特征串联起来,构成整幅图像的HOG特征。该方法首先将图像分成很多小的连通区域,叫作细胞单元(cell),比如大小可为8×8,采集细胞单元中各像素点的梯度和边缘方向;然后在每个单元中累加一个一维的梯度方向直方图,这就是一个细胞单元的描述符。将几个细胞单元组成一个block,例如将2×2的细胞单元组成一个block,将一个block内每个细胞单元的描述符串联,即可以得到一个block的HOG描述符。在统计一个cell的梯度直方图时,一般考虑采用9个bin的直方图来统计8×8像素的梯度信息,即将cell的梯度方向0~180°(不考虑正负)分成9个方向块。若一个block由2×2个cell组成,每个cell包含8×8个像素点,每个cell提取9个直方图通道,那么一个block的特征向量长度为2×2×9。再根据图像的大小,即可得到一幅图像的特征向量长度。然后将图像的特征向量送入分类器进行训练和识别[8-9]。
3.3 分类器训练
经过对多幅GEI的HOG特征提取,可以得到每幅GEI的一行多维的特征向量。每一个特征向量用来描述一幅GEI的信息。选用的训练集和测试集数据都进行标记,训练集和测试集都是经过HOG算法提取特征之后的特征向量。若有N类样本,每个样本的特征向量长度为n,则第i个样本的ELM输入如下:
II=(ai1,ai2,…,ain)T
(13)
本文ELM结构如图10所示。得到训练后的模型并保存,接着在该模型上对用测试集的数据进行验证。
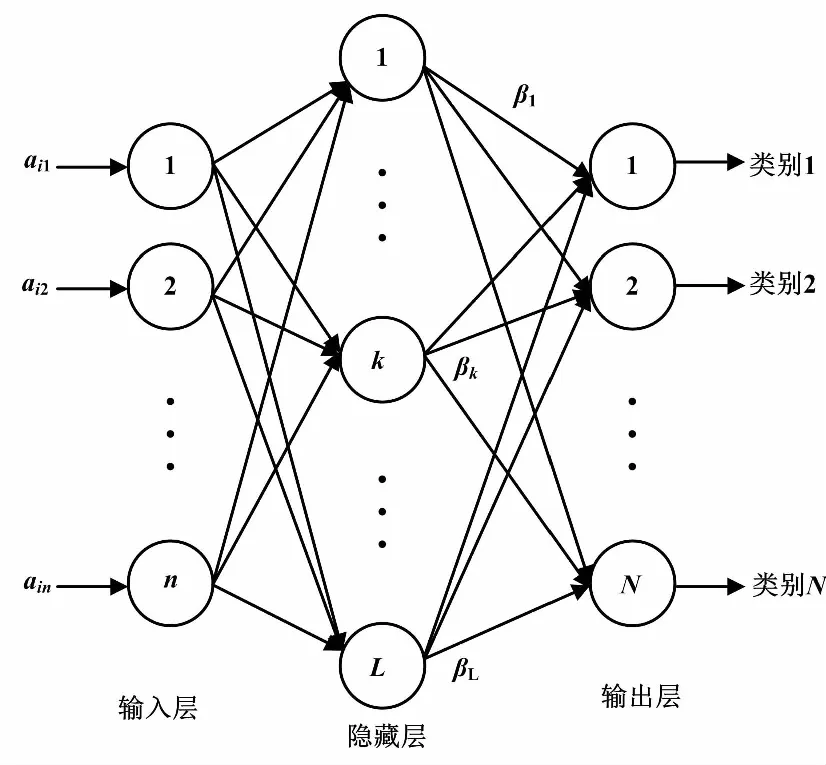
图10 本文ELM结构图
ELM在训练之前可以随机产生W和b,因此在参数设计上只需要确定隐含层节点个数即可,通过调整该参数,可以计算出输出层的权重β。因为ELM在训练前产生参数的随机性,因此选取节点个数后需要进行多次测试,对得到的测试结果取平均值,得出最终测试结果。
4 测试结果
为了验证本文方法的有效性和可行性,在CASIA数据集上进行了测试。该数据库由中国科学院自动化研究所提供,可通过http://www.cbsr.ia.ac.cn/china/Gait%20Databases%20CH.asp进行申请后获取。利用ELM算法和SVM算法进行了身份识别的测试,通过调节模型参数及对比试验结果,验证了使用ELM算法进行身份识别的可行性。将ELM算法和SVM算法进行对比,凸显ELM算法在训练速度上的优势。
本测试过程的计算机配置为处理器Intel(R)Core(TM)i5-8265U,软件配置为Python3.7、PyCharm2018.2、opencv3.4.4、Matlab2016b。
4.1 数据集介绍
本文测试选用CASIA步态数据库中的数据。库中共有三个数据集:Dataset A,Dataset B,Dataset C。在现实生活中所采集的步态视频数据往往是少量的,并不像公开数据集中一样可以获得上百人的步态视频。因此,本文选用Dataset B中的部分数据,模拟视频数据量少的情况下的识别情况。该数据集共有124个人的行走视频,每个人有11个视角的视频,在普通条件、携带包裹和穿大衣三种条件下行走采集。本测试对从该数据集中随机选取的24个人共96个视角为90°的常规步态视频进行处理。对这些视频数据进行分帧以及图像预处理后,共可生成96张GEI。接着,对这些GEI进行特征提取,并利用ELM算法和SVM算法进行身份识别。
4.2 数据增强
数据过拟合现象如图11所示。
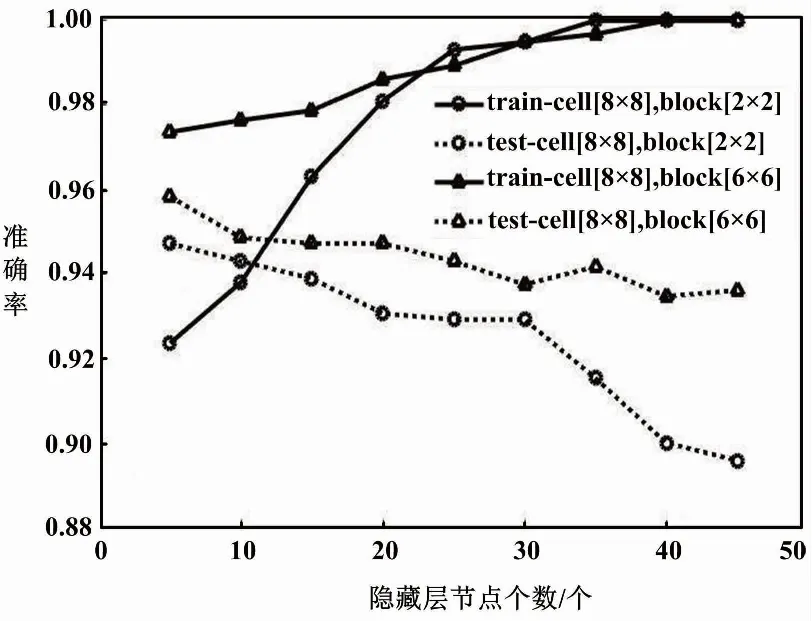
图11 数据过拟合现象图
利用上述数据集进行处理,24个人共得到96张GEI(其中训练集72张、测试集24张),提取GEI的HOG特征并送入ELM分类器进行测试。
图11是激活函数为sigmoid、在不同的cell和block大小下进行测试的结果。从图11可以发现,随着隐含层节点个数的增加,训练集的准确率不断提升,但测试集的准确率却在下降。这是由于数据过少造成的过拟合。本次测试的训练集为72张GEI、测试集为24张GEI,数据过少,因此需要对数据进行数据增强。本文采用了旋转、镜像和改变对比度等方法对数据集进行数据增强,将训练集和测试集的数据分别扩增为2 160张和720张GEI。通过数据增强,可以有效地避免过拟合现象。
本文对测试选取的每个节点个数均进行了30次测试,取30次的测试结果的平均值,得到最后的识别率。
4.3 结果分析
在隐含层不同节点个数下,将ELM算法识别的结果用Matlab绘制。Matlab试验结果如图12所示。
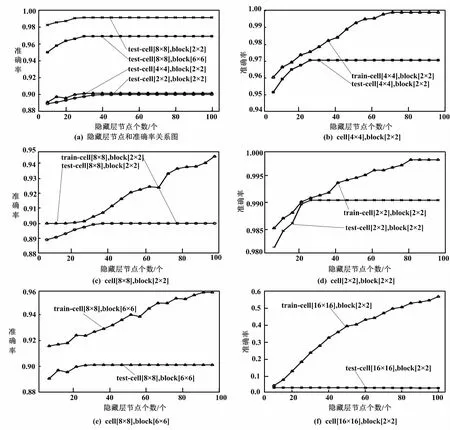
图12 Matlab试验结果
图12(a)是4种参数下的测试结果汇总,图12(b)~图12(f)是不同参数下的具体测试结果。从图12(f)中可以看出,当cell的大小取16×16、block的大小取2×2时,如隐含层节点个数增加,训练集准确率不断提升,但是测试集的准确率一直很低。因此,该特征提取参数对识别是无效的。经计算可知,该参数下的特征向量长度为324,特征过少,因此无法训练出有效的模型。将另外四种参数下的训练和测试的结果绘制在同一个坐标系中,可以看出各个参数下的识别效果。当选取cell为2×2、block为2×2时,随着隐含层节点个数的增加,测试准确率不断提升。从图12(e)中可以看出,当隐含层节点个数取30时,测试集准确率达到99.17%;之后,当节点个数再增加时,测试准确率也不再提升,而且训练时间会增加。所以在该参数下,隐含层节点个数取30最为合适。在其他的cell和block取值下,测试准确率均没有上述参数高,因此可以采用上述参数进行模型的训练和测试。
ELM和SVM算法的识别结果对比如表1所示。

表1 识别结果对比
将结果绘制为条形图,可以更直观地看出ELM的优势。试验结果如图13所示。
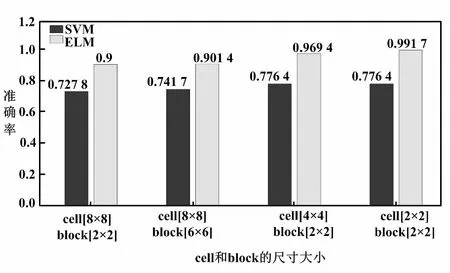
图13 试验结果图
从表1和图13可以看出,SVM算法测试的准确率没有ELM算法的准确率高,并且训练模型的时间都比较长[10]。当cell大小为16×16、block大小为2×2时,虽然训练的时间缩短了,但是由于特征向量的长度比较小,其准确率也下降了。ELM算法的一个显著提升是训练时间大大缩短。当cell选用2×2、block选用2×2时,虽然特征向量长度大,但是训练时间只有9 s左右。这比SVM的训练时间少得多,准确率达到了99.17%。
5 结论
本文提出了一种利用步态信息的基于ELM的身份识别方法。通过对视频进行分帧处理,从视频数据中获取测试对象行走的图像帧,经过图像预处理后生成步态能量图。为了避免过拟合现象进行了数据增强处理,利用HOG特征描述子对步态能量图进行特征提取,使用ELM作为分类器进行身份的识别。试验结果表明,本文使用的特征提取方法和分类算法可以取得较好的识别效果。与SVM相比,ELM能获得更好的识别准确率,并且在训练速度上有大幅提升。
在实际生活中,人行走时或多或少会受到衣物、灌木或路边杂物的遮挡,并且获得的视频拍摄角度不一定是90°。这都会对识别准确率造成一定的影响。今后可在消除遮挡影响和多视角识别这两个方面进行进一步研究。
