基于Python的网络爬虫系统的设计与实现分析
2021-03-15新疆交通职业技术学院李文华
◇新疆交通职业技术学院 李文华
本文首先对Python与网络爬虫的概念进行了简要阐释,并分析了基于Python的网络爬虫系统的基本原理;其后从关键设计原则与模块结构设计角度入手,提出了基于Python的网络爬虫系统的设计思路;最后对基于Python的网络爬虫系统的编程实现进行了研究。
在“互联网+”的新时代中,大数据技术、人工智能技术、应用程序技术等现代科技与现代社会的融合关系日益紧密。在此背景下,Python逐渐从编程语言领域中脱颖而出,以其低成本、低难度、开放化、简洁化等特点受到了人们的青睐与好评,并长期占据各大编程语言排行榜的领先地位。据此,我们有必要对基于Python的网络爬虫系统的设计与实现展开探究讨论。
1 基于Python的网络爬虫系统的基本原理
网络爬虫亦称“网页追逐者”或“网页蜘蛛”,是一种基于预设规则进行网络信息自动抓取的程序工具。现阶段,网络爬虫还可根据应用功能的不同,分化为全网爬虫、聚焦爬虫、增量爬虫、深层爬虫等多个种类,并在搜索引擎搭建、网络信息检索、网络数据分析等领域发挥着重要作用。从基本结构来看,网络爬虫系统主要由页面采集模块、页面解析模块、连接处理模块等部分组成,其应用运行的主要流程为:首先,对待爬取的目标网站进行确定,并从已给定的初始URL链接中提取出一个,对该链接上的信息内容进行分析采集,最终储存到数据库当中。其后,将网站中未经访问的链接纳入到待爬行列表当中,按照特定顺序逐个进行链接页面的提取、访问、分析、采集、储存。最后,在循环执行爬行动作并达到程序预设的停止条件时,网络爬虫系统即可自动终止运行[1]。
在此基础上,网络爬虫系统还可根据URL链接爬行路线的不同,分为递归网络爬虫与非递归网络爬虫两种。其中,前者为单一性的线程设计,即在同一动作周期中只能对一个链接进行分析处理;后者则为多线程设计,即以URL队列为运行支持,按照“初始URL链接→等待队列→运行队列→错误队列/完成队列→完成URL爬行”的流程执行网络爬行任务。在此过程中,若判定某URL链接在信息采集的过程中出现下载错误、爬行失败的情况,将会将该URL链接加入到错误队列中,该队列的URL链接将不会参与后续系统循环。
Python是目前应用最广泛的计算机编程语言之一,其本身携带有requests、bs4、pyspider等多个基础库,可为网络爬虫系统的代码编写与结构搭建提供优质环境条件。因此,以Python为基础进行网络爬虫系统的设计与实现,具有良好的可行性与适应性。
2 基于Python的网络爬虫系统的设计思路
2.1 基于Python的网络爬虫系统的关键设计原则
为了实现Python编程语言下网络爬虫系统的顺利产出,并确保网络爬虫系统在实际投用中的高效可靠、合法合规,相关人员在设计实践中应遵循以下几点关键设计原则。
第一,可行性原则。众所周知,互联网中的数据信息具有海量化特点,若采取全网爬虫的系统设计方式,将会形成大量不必要的时间浪费与成本损耗。所以,相关人员在正式开展设计实践之前,必须要明确网络爬虫系统的应用目标与爬行对象,以此实现网络爬虫系统爬取信息主题、爬行动作范围的精准确定,保证网络爬虫系统在设计完成后具有高度的应用可行性。同时,还需做好URL链接过滤机制、评价标准的合理设置,以进一步确保网络爬虫系统设计与实现的“有的放矢”。
第二,避险性原则。在目前,为了保护网页信息,很多网站会设计出一定的“反爬取”机制,进而导致网络爬虫系统在运行过程中出现异常,不仅难以达到预期的网络信息采集效果,还会对爬虫系统本身的爬取有效性产生影响。例如,一些网页会依托动态技术构建出“爬虫陷阱”。当网络爬虫系统在此类网络中执行信息爬取任务时,该URL链接的地址日历会发生频繁更改,进而导致网络爬虫系统循环往复地登入同一个地址,陷入到重复抓取、无法跳出的境地当中。在基于Python的网络爬虫系统设计当中,为了防止此类情况出现,相关人员务必要贯彻落实避险性原则,对反爬取的陷阱风险进行提前感知、预先防范。例如,可设置出网络爬虫系统对同一网站的最大抓取次数,当网络爬虫系统在单一网页中重复抓取信息的次数超过预设限值,该任务就会主动结束,从而使网络爬虫系统及时跳出陷阱网页,转而进行URL队列中其他链接的信息爬取[2]。
第三,合理性原则。在网络爬虫系统的应用实践中,会涉及到一种名为“robots”的安全协议,其对爬取行为具有约束性作用。当网络爬虫系统作用于某一网站时,会首先访问该网站的robots.txt文本,以得知该网站中不被允许搜索采集的具体内容,或网络爬虫系统被赋予的有限权限。然后,网络爬虫系统便可依据协议内容,实施有选择、有约束的信息爬取行为。同理,若网络爬虫系统在爬取某网站时,并未检测到robots.txt文本存在,也就意味着该网站的所有信息均处于无协议保护的状态,网络爬虫系统可进行自由无拘的采集活动。基于此,由于robots在本质上是网站与网络爬虫系统之间的一种通俗协议,而非强制性的规定。所以,相关设计人员应将robots.txt文本的检测与约束机制纳入到设计过程中,以保证网络爬虫系统投用运行的合理性与礼貌性。
2.2 基于Python的网络爬虫系统的模块结构设计
在实践中,相关人员可以如图1的网络信息爬取流程为基础,进行网络爬虫系统总体结构的设计。具体来讲,应包含系统调度、URL链接管理、网页下载、网页解析、数据储存、robots管理、线程管理以及风险处理八个功能部分。
第一,系统调度模块为网络爬虫系统的“头脑”,主要负责其他功能模块的调度控制与指令管理。在系统运行的过程当中,系统调度模块应与其他模块持续建立反馈连接,当某一模块的动作结束后,系统调度模块可同步向下一环节模块发出驱动指令,以推动网络信息爬取流程的进展,直至满足预设程序的全部条件,即爬取任务完全结束。
第二,URL链接管理模块主要作用于网络爬虫系统涉及到的所有URL链接,如待爬取URL链接、已爬取URL链接、新URL链接对象等。
第三,网页下载模块为网络爬虫系统获取网页信息的工具,当网络爬虫系统进入到URL链接的网页界面后,网页下载模块会自动启动下载功能,对HTML、XML、JSON等多种数据文件进行下载爬取。
第四,网页解析模块位于网页下载模块后端,当网络爬虫系统获取到网页中的海量数据信息后,网页解析模块可对数据信息进行去噪处理,从而实现冗余性文件的有效剔除,仅保留用户所需的相关数据。
第五,数据存储模块主要作为计算机存储空间与网络爬虫系统的连接纽带。当目标信息采集、处理完成后,数据存储模块即可对数据信息的类型进行判断。若数据具备结构化特点,则将其导入到数据库当中;若数据为非结构化,则将其直接导入计算机的本地硬盘。在此基础上,再辅以简洁合理的索引机制,即可满足已爬取信息的检索利用需求。
第六,robots管理模块主要用于检测、下载与更新目标网站的robots.txt文本文件,并对robots文本中的允许访问目录或限制访问目录进行感知。当系统调度模块获得robots管理模块的信息反馈后,即可按照相应权限进行爬取指令的下达,以保证网络爬虫系统的运行边界持续处在网站允许范围内,从而将网络爬虫系统的信息爬取行为维持在较高的合理性与礼貌性水平当中。
第七,线程管理模块主要用于多线程的网络爬虫系统,相关人员在设计时,应保证系统线程具备良好的灵活性,即用户可根据具体的URL链接数量进行线程数调整,以确保网络爬虫系统运行资源的有效分配,达成较高网络爬虫系统的网络信息爬取效率。
第八,风险处理模块主要是为了应对各类反爬取机制而形成的。在基于Python的网络爬虫系统设计中,相关人员应制定出多种风险处理方案,如爬虫陷阱循环访问风险的有效规避、同一URL链接下网站内容的变更适应等,并落实到Python语言的代码编程当中。
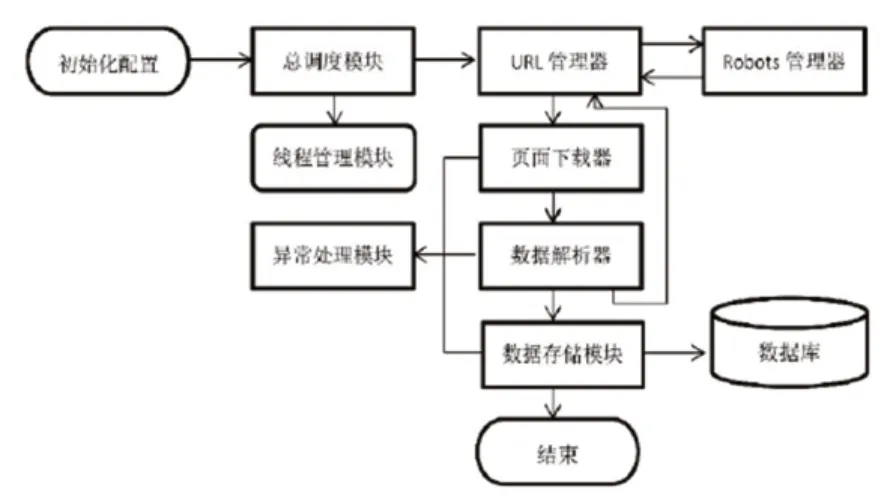
图1 网络爬虫系统的基本流程
3 基于Python的网络爬虫系统的实现研究
在运行流程、模块结构设计完成后,相关人员即可依托Python开发平台,进行网络爬虫系统的开发实现。具体来讲,各类模块的实现策略如下所示。
第一,系统调度模块的实现。在Python开发环境中建立初始模块“__main__”,并在该模块中建立Spidermain类。然后,按照图1的系统运行流程,开放信息爬区目标选定、系统参数设置、robots.txt导入、URL链接提取、robots.txt目录检查、页面信息下载、页面信息解析、爬取信息储存等环节模块的调度权限。最后,对各项模块参数进行初始化,即可正式启动网络爬虫系统。
第二,URL链接管理模块的实现。以Python开发平台的set去重功能为基础,创建出“已爬取”与“待爬取”两个URL队列。然后,使用set的pop算法,对待爬取队列中的URL队列进行随机选取,以此作为网络爬虫系统下一环节的信息爬取目标[3]。
第三,网页下载模块的实现。依托request基础库的urlopen工具,对目标网页中的数据信息进行下载获取。在此基础上,可进一步设置headers代码,从而在实现网页下载功能的同时,将网络爬虫系统的行为伪装为浏览器访问,以进一步提高信息获取的成功几率。
第四,网页解析模块的实现。在Python平台中,网页解析模块可依托Beautiful Soup基础库以及lxml?解析器进行搭建实现。其程序代码包括“soup=BeautifulSoup(data,“lxml”)”、“urls=soup.find_all('a',href=re.compile(pattern[,flag])”等。
第五,数据存储模块的实现。数据存储模块在网络爬虫系统与MySQL数据库之间建立连接,实现爬取信息向pymysql模块的导入。其程序代码包括“sql=“insert into `table(`datal`,`data2`,`data3`)values(%s,%s,%s)”、“connnection.cmmit()”等。
第六,其他功能模块的实现。线程管理、风险处理等其他模块可依托Python平台的threading、urllib.error等基础库实现。
4 结语
总而言之,在利用Python编程语言及开发平台进行网络爬虫系统的设计与实现时,相关人员需要充分考虑到网络爬虫系统复杂多样的功能需求,以及其在应用过程中可能遇到的陷阱风险、robots协议等问题,继而设计出功能完善的模块结构方案与系统运行流程,并付诸于编程实践当中,以确保网络爬虫系统可行性、避险性、合理性等原则的充分体现。
