基于SVM的商品评论情感研究
2021-03-13韩美玉
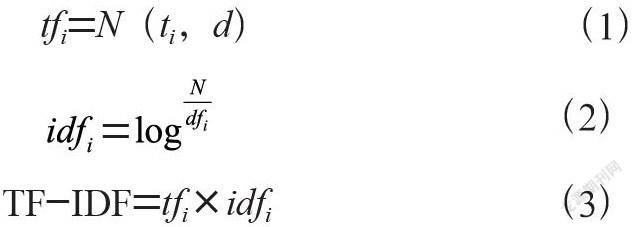
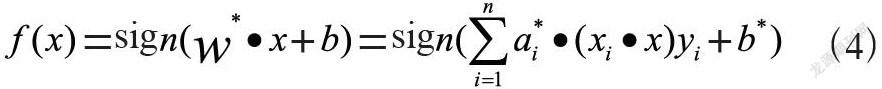


摘 要:为充分挖掘用户对网购商品的评论信息,为消费者的购买决策提供参考,同时帮助商家改进自身产品、提高市场竞争力,文章提出一种基于支持向量机(SVM)的细粒度商品评论情感分析方法。首先,使用Python中的网络爬虫获取京东某品牌的冰箱评论信息作为语料库并对其进行预处理,将语料数据分为训练集和测试集;接着,通过特征选择对词汇集做降维处理并使用支持向量机(SVM)的算法对商品评论信息进行情感分类;最后,统计包含每个基本属性和其扩充的特征词集的正面评论个数及负面评论个数,分析并给出结论。
关键词:SVM;文本情感研究;商品评论情感研究
中图分类号:TP181 文献标识码:A文章编号:2096-4706(2021)15-0122-03
Abstract: In order to fully mine the online shopping comment information of a certain product, provide reference for consumers’ purchase decision, and help merchants improve their own products and enhance market competitiveness, this paper proposes a fine-grained sentiment analysis method of product comment based on support vector machine (SVM). Firstly, the network crawler in Python is used to obtain the comments of a refrigerator of Jingdong brand as a corpus. The corpus data is divided into training set and test set, and the corpus is preprocessed. Secondly, feature selection is used to reduce the dimension of the word collection and support vector machine (SVM) algorithm is used to classify the product review information. Finally, the number of positive comments and negative comments of each basic attribute and it’s expanded feature word set are counted, analyzed and concluded.
Keywords: SVM; text emotion research; goods comments emotion research
0 引 言
隨着电子商务的发展,在线购物成为人们生活中的常态,消费者在购买商品后往往会对商品作出评价,这些网购评论信息中包含了对所购商品的情感,充分挖掘和利用这些评价信息能够为在线购物的诚信交易提供参考。对于潜在的消费者来说,可以借助评价信息进一步了解商品;对于商家来说,能够督促其改进自身产品、提高市场竞争力。然而,从商品评价中挖掘出结构化信息的工作却无法依赖于人工,文本的挖掘和情感研究能够为解决这一问题提供有效的手段。
1 国内外研究现状
近年来,对文本挖掘和自然语言处理技术的相关研究迅速崛起,而其中的情感分析研究更是一个广为研究者研究的活跃领域。目前,对情感分析的研究主要包括基于词典、基于机器学习及基于深度学习这三个方面,本文研究的内容属基于机器学习的情感分析。Pang等以影评信息作为语料,对比分析了四个文本分类算法的效果,给出了支持向量机(SVM)的分类效果最优的结论[1]。李明等比较了朴素贝叶斯、决策树、支持向量机(SVM)、K最邻近算法( KNN)四种常用的情感分类算法,实验发现支持向量机(SVM)的召回率和精确率最高,均达到94.5%[2]。支持向量机(SVM)最初由Vapnik提出,它能够保证在特征空间中建构最优分类超平面,实现在统计样本量较少的情况下具有良好的统计规律。本文使用支持向量机(SVM)对商品评论进行情感分析,开展商品评论情感分析和统计的研究。
2 基于SVM的商品评论情感研究
本文的商品评论情感分析包括下述四个方面:
(1)语料库的准备。使用Python中的网络爬虫获取京东在售的海尔冰箱BCD-506WSEBU1商品评论信息作为语料库,将语料数据分为训练集和测试集,对语料库进行预处理。具体包括以下步骤:
首先,获取原始数据。使用爬虫模拟人工登录的过程,获取型号为BCD-506WSEBU1的冰箱的评论原始数据,包括发起请求、获取响应、解析数据和保存数据四个过程。发起请求即发起Request请求,在京东网站中找到目标商品的评论信息并使其加载数据,借助浏览器的开发者工具抓包并获取该冰箱评论信息的真实URL地址,使用Python中的Request库发起HTTP请求,获取到json字符串形式的响应内容。最后,将json字符串的响应内容解析并保存在本地即获取了本研究的原始数据,实现代码见下:
import requests
import json
import time
import random
headers = {
‘User-Agent’ Mozilla/5.0 (Windows NT 10.0;WOW64) AppleWebKit/537.36 (KHTML,like Gecko) Chrome/80.0.3987.100 Safari/537.36
}
def spider_comment(page=0):
url=
‘https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=100008568481&score=0&sortType=5&page=%s&pageSize=10&isShadowSku=0&rid=0&fold=1’% page
try:
r = requests.get(url,headers=headers)
r.raise_for_status()
except:
print(“error”)
# 將json转换为python对象
json_obj = json.loads(json_str)
# 获取评价列表
comments = json_obj[‘comments’]
# 遍历列表并写入
for comment in comments:
with open(‘E:/python/comments.txt’,’a+’) as f:
f.write(comment[‘content’])
f.write(‘\n’)
def change_page():
for i in range(100):
spider_comment(i)
time.sleep(random.random( ) * 5)
print(“ok”)
if __name__ == ‘__main__’:
# spider_comment( )
change_page( )
第二,对原始数据进行数据清理。包括识别字符串的语言类型,剔除提取到的中文评论中混杂的英文信息及广告信息。此外,由于电商平台对于评论字数达到一定要求的评论给予奖励,导致评论中有较多无意义的感叹词,剔除这些无意义的感叹词。
第三,将经数据清理后的原始数据分为训练集和测试集,并进行分词处理。
(2)特征选择。在进行分类算法之前,需要将高维稀疏空间映射为低维稠密空间,从特征空间中择优选择一部分特征子集。本研究选用基于特征频率-倒文档频率(TF-IDF)的方法构造特征项。TF-IDF的核心思想是:最有意义的特征项应该选用在当前文本中出现频率最高而在其他文本中出现频率足够小的词语。通过TF-IDF方法构造的特征项具有区分性强,适于分类的特点。假定特征集合为(t1,t2,…tn),可以将特征集合看作一个词表,整个文本为d。特征频率(TF)表示该特征项在当前文本中出现的次数,可以根据公式(1)计算,TF越大,代表其重要性越大。倒文档频率(IDF)表示了特征项在整个语料库中的全局性统计特征,可以根据公式(2)计算。TF-IDF定义为TF与IDF的乘积,可以根据公式(3)计算为:
根据公式(3)计算分词后的TF-IDF值,取前5个特征词并建立向量空间模型。
(3)使用支持向量机(SVM)的算法对商品评论信息进行情感分类。本研究使用SVM分类器对训练集数据进行模型训练,然后对测试集进行结果预测,得到分类结果。
SVM是统计机器学习中经典的算法,而基于线性核函数的支持向量机算法适用于文本分类,SVM是一种两分类任务的线性分类模型,其分类准则为最大间隔准则[3]。其中,SVM通过拉格朗日对偶法对问题进行高效的求解,对偶问题符合KTT条件,当KTT条件成立时,拉格朗日乘子ai不为0,得到分类决策函数为公式(4):
(4)统计每个属性及其扩充的特征词集的积极评价和负面评价的数量,分析数据并给出结论。
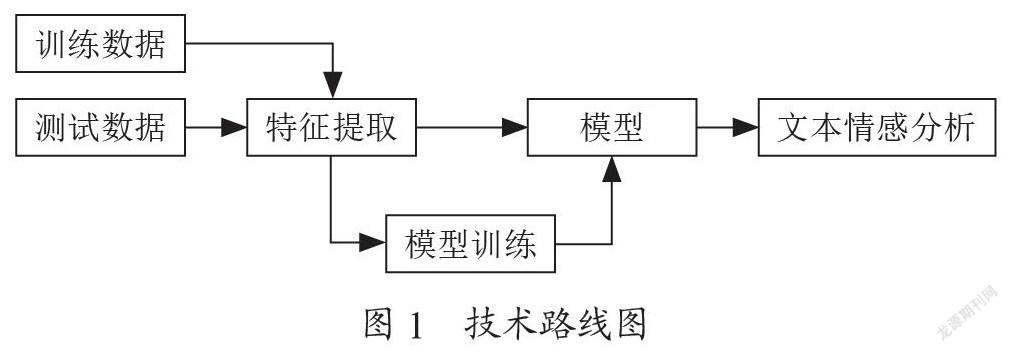
技术路线图如图1所示:
3 实验及分析
本实验主要分为三部分:第一,对语料数据的准备及预处理工作;第二,对高维的特征空间进行降维,进行特征选择;第三,选取支持向量机(SVM)的机器学习算法对冰箱的评论信息开展情感分析及统计工作。
3.1 语料数据的预处理
本文选取京东在售型号为BCD-506WSEBU1的海尔冰箱商品评论信息为研究对象,开展对该商品评论的情感分类研究。本实验挖掘1 000条原始评论信息,其中训练集共800条,测试集200条,并对数据进行人工标注,实验数据构成如表1所示。本研究将评论内容只包含正面评价或者负面评价的评论数据抽取出来,仅保留那些情感倾向较为明确的评论信息。
3.2 特征提取
通过随机抽样分析发现评论语句中的情感词一般与商品属性相关。而根据中文的表达习惯,商品的特征属性一般是名词,最后,根据冰箱的产品说明书和基于TF-IDF的方法,构建冰箱的特征属性有外观、价格、噪音、质量、服务五类,并建立向量空间模型。
3.3 针对冰箱属性特征的商品评论情感分析实验
文本经过文本表示和特征选择后就可以选取支持向量机(SVM)的机器学习算法进行分类研究[4]。使用PMI算法计算每个特征属性与特征词的相关程度,取相关程度较高的前25个特征词。构造基于SVM的情感分类模型,并将测试集投入构建好的情感分类模型中。为了更明确用户对冰箱属性相关的特征词的情感态度,分别统计了每个属性及其相关特征的积极评价及负面评价的数量,如表2所示。
通过上述的评论统计分析可以明显看出,用户对冰箱外觀和质量持负面情感的人数较多,说明用户对这款冰箱的质量并不是很看好;而在物流、服务和价格上多数人持积极情感,表明该冰箱定价合理,服务及物流都做得不错。因此,该品牌商家应该在冰箱的质量方面努力提升,提高用户满意度,提升销量。
4 结 论
本文采用基于SVM的算法进行文本特征选择并使用PMI算法扩展了商品的属性特征,以京东在售型号为BCD-506WSEBU1的海尔冰箱为研究对象,对其属性特征进行文本情感分析和统计。商品属性特征的评论情感分析对商家和消费者都具有重要意义。对于潜在的消费者来说,可以借助评价信息进一步了解商品;对于商家来说,能够督促其改进自身产品、提高市场竞争力。本研究的商品评论情感分析仅从积极情感和消极情感两个方面进行,然而情感是非常复杂的,因此,后续研究可以考虑细化的情感分类研究。
参考文献:
[1] PANG B,LEE L,VAITHYANATHAN S.Thumbs up Sentiment classification using machine learning techniques [C]//Computation and Language,may28,2002.
[2] 李明,胡吉霞,侯琳娜,等.商品评论情感倾向性分析 [J].计算机应用,2019,39(S2):15-19.
[3] 宗成庆,夏睿,张家俊.文本数据挖掘 [M].北京:清华大学出版社,2019:65-67.
[4] 肖江,王晓进.基于SVM的在线商品评论的情感倾向性分析 [J].信息技术,2016(7):172-175.
[5] 刘若雨.基于电商评论文本的用户情感分析 [J].现代信息科技,2021,5(4):85-87+92.
作者简介:韩美玉(1991—),女,汉族,宁夏银川人,助教,硕士研究生,研究方向:文本情感研究。
3686500338252
