改进PersonalRank算法进行个性化推荐
2021-03-13李维



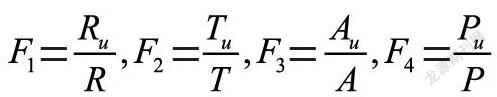
摘 要:PersonalRank就是一种基于随机游走的图推荐算法。传统的PersonalRank算法是在PagePank算法的基础上进行了改进,但依旧存在个性化推荐召回率和准确率不高,过度偏重同物品中其他用户操作的问题,导致覆盖率不高。现针对PersonalRank问题,文章从推荐系统评测指标的覆盖率、召回率和准确率三个维度出发,加强算法发掘长尾的能力,同时提高推荐结果的用户满意度。
关键词:信息资源;图推荐算法;PersonalRank;长尾
中图分类号:TP391 文献标识码:A文章编号:2096-4706(2021)15-0025-04
Abstract: PersonalRank is a graph recommendation algorithm based on random walk. The traditional PersonalRank algorithm is based on the changes made by pagepank algorithm, but there are still problems of low recall and accuracy of personalized recommendation and excessive emphasis on the operation of other users in the same item, resulting in low coverage. Aiming at the PersonalRank problems, the paper starts from three dimensions of the evaluation indicators of the recommendation system: coverage, recall and accuracy, strengthens the ability of algorithms to discover long tail and improves the user satisfaction of the recommendation results.
Keywords: information resources; graph recommendation algorithm; PersonalRank; long tail
0 引 言
随着互联网与高新技术的发展,我们正身处高度信息化的时代,每天互联网上产生的信息数据正以惊人的速度增长。但Internet给用户带来丰富信息资源的同时,也阻碍了用户快速找到自己所需的信息。虽然用户通过在百度、谷歌等搜索框中输入关键字能够展现出其所需的内容,但由于缺少用户的偏好数据,搜索出来的内容不能很有效地过滤出垃圾数据。为了响应这种用户对高质量的用户信息服务的需求,产生了很多个性化推荐算法。诸如基于用户的推荐算法[1],基于物品的推荐算法[2],或者是基于图模型的推荐算法[3]等。
个性化推荐就是运用推荐算法,从海量数据中筛选出用户所需但不易搜索出来的结果,也就是获取所需数据的效率。由于现代化的迅猛发展,体现出用户个性化服务的要求日益增加,在电商领域、在金融以及在医疗等与人们息息相关的各个领域都充斥着个性化的影子。例如:金融系统根据个人的财富情况所提供的针对性的理财服务,医疗机构针对不同年龄段的人提供的个性化养生项目;尤其是在电商领域,淘宝和京东都会为潜在的用户推荐符合其历史购物需求的商品;在流媒体业务中,优酷和爱奇艺等流媒体平台也都会出现个性化影视服务,给用户推荐专属电影院。
有一種推荐算法是图推荐算法,以图这种有流程的直观的形式来展示复杂的用户操作数据,利用图论中的算法进行个性化推荐的算法,它是现今较为重要和流行的推荐策略。PersonalRank算法就是基于图的推荐算法。PersonalRank算法是在PageRank算法的基础上发展而来的。但PersonalRank算法存在覆盖率不高,导致很多质量高的,用户喜欢的物品未能被推荐出来。基于此类问题,本文将对PersonalRank算法做出改进,加强算法发掘长尾的能力,同时增加物品评分,以提高推荐物品的质量,其在准确率、召回率和覆盖率上有较好的提升。
1 PersonalRank算法及其改进算法
1.1 PersonalRank算法
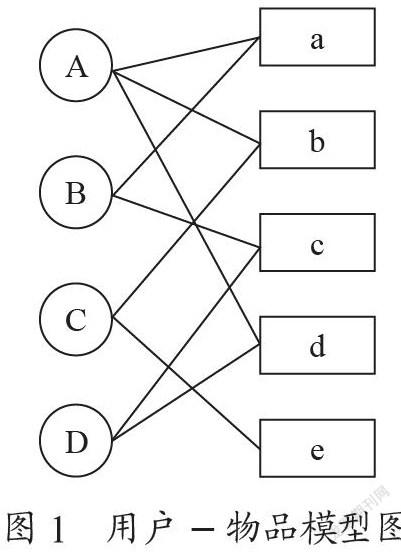
PersonalRank算法是一种随机游走算法,采用二分图的方式构建图,包含两种类型的顶点:用户和物品,二分图就是在同一边的各点没有连线,就像图1中,用户这边:俩俩用户之间没有连线;物品这边:俩俩物品之间没有连线,都是根据物品与用户之间的连线相互关联,即这些用户数据由二元组组成(可以表示成(u,i),即用户u对物品i产生过行为)。目标用户与推荐结果物品以二分图来展示,推荐结果中越靠前的物品,也就是权重越重的物品,就是与目标用户关联性最高的物品,这就是图推荐的直观性体现。
由于PersonalRank算法是基于PageRank算法[4]发展来的,那么PersonalRank算法也沿用了PageRank算法的思想,PageRank算法的核心思想是根据网页链接到其他网页或者其他网页链接到本网页的出入度来计算网页的得分,并且通过网页的得分进行推荐的排序。但PageRank算法主要是通过网页或者称为物品之间的相互联系来计算PR值,这样就缺少用户与物品之间的协同操作,不能为用户提供个性化的服务,而PageRank算法所推荐的网页都是根据引用的链接来计算的,不能为特定用户推荐个性化服务。那么为了实现为用户提供个性化推荐,就在此基础上发展了PersonalRank算法。当然PersonalRank也沿用了其思想,另外在其基础上加上了协同过滤的个性化推荐思想,即根据用户操作的物品,来计算其他用户操作同物品及其他物品的得分情况。
通过迭代计算,可以得到每个用户的推荐结果,这样就成了个性化推荐,可以得到每个物品节点的得分排名,并进行重要性排名。
度量图中两个顶点之间的关联性很多,但一般取决于下面3个方面[5]:
(1)两个顶点之间的路径数。
(2)两个顶点之间路径的长度。
(3)两个顶点之间的路径经过的顶点。
相关性高的一对顶点一般具有以下特征:
(1)两个顶点之间有很多路径相连。
(2)连接两个顶点之间的路径长度都比较短。
(3)连接两个顶点之间的路径不会经过出度比较大的顶点。
从上面的例子可知:
这里A可以到达a,b,d,不能到达c,e,那么是优先推荐c,还是优先推荐e呢?
第一条:两个顶点之间有很多路径相连:
A→c:A→a→B→c,A→d→D→c
A→e:A→b→C→e
从这一条就可以看出,c优先于e。
图中A、B、C和D表示4个不同的用户,a、b、c、d和e表示5个不同的物品,用户与物品之间的边表示用户和物品的关联性。如果根节点为A,就是给用户A推荐物品,大致的游走方向为:从节点A出发,由于用户A与物品a、b和d有关,因此从节点A到节点a、b和d。到达节点a、b和d后,就从当前节点开始随机游走到下一个节点,节点游走的概率为α。由于PersonalRank是随机游走算法,多次游走后,每个物品节点的PR值就会趋向于一个稳定数值。在推荐结果中给物品的权重就是这个稳定数值,当然从目标节点出发时,游走后如果下一步是返回到目标节点,概率设定为1-α,算法迭代,直到游走结束。
每个节点的PR值如公式(1)所示:
其中,PR(v)表示节点v的访问概率,PR(v’)表示节点v’的访问概率,out(v’)表示节点v’的出度,int(v)表示节点v的入度。α决定继续访问的概率。一般情况下,α取值为0.8。
1.2 PersonalRank算法的不足
从PersonalRank算法公式来看,该算法存在以下几点不足:
(1)长尾问题。该算法注重对同物品有过行为的用户。也就是说节点的PR值取决于入度的节点,如果存在某个节点没有用户访问就会被遗弃,不会被推荐。比如:某个物品很热门,很多用户有过行为,那么该物品的PR值就会比较高,也会比较容易受到推荐。
(2)推荐质量不高。由于PersonalRank算法注重于用户和物品的协同行为,不注重用户对物品的反馈,就会存在差质量的物品由于被多个用户行为过,也就存在较高的PR值,导致推荐出来的结果并不是最好的。
2 PersonalRank算法改进
PersonalRank的改进算法主要从以下两个方面着手于对节点PR值的计算公式进行改进:一是除了原有的用户和物品两个节点外,增加用户显示反馈评分节点,通过评分节点可以提高推荐结果的质量,可以将用户曾给过高评分的物品,通过其与其他用户的关联性,然后再通过其他用户给出的高评分的物品推荐出来,从而提高推荐结果的质量。二是发掘算法的长尾能力,通过用户有过行为的高评分物品,找到同类型的物品,也就是类似于将该物品打上标签,获取到用户偏好信息和反馈信息,找到同类型物品后,将评分高的物品推荐给用户,提高覆盖率。
2.1 增加用户反馈维度改进PersonalRank算法
针对PersonalRank算法传统的仅仅依靠用户与物品之间的行为关系来进行推荐,在其基础上增加评分节点。评分节点表示用户对所行为过物品的评分,此属于显示反馈。显示反饋表示用户主动参与对物品的认同度,一般可以设置1-5分的评分维度,1分为最低,表示用户对该物品有过行为,但是认可度低。5分为最高,表示用户对该物品的认可度高。这种评分行为是可以很直观地表示用户对某一类物品的兴趣。
一个好的推荐结果需要满足用户获得优质资源的心态。这就依赖于用户操作的物品行为,这种显示反馈是最为有效的。通过将用户反馈维度加入对PR值的计算公式中,就是希望通过用户这种评分的显示反馈进而影响推荐结果的排列顺序,也就是通过用户以往对物品的行为,调整对不同物品的权重,降低一些低质量物品的权重,提高高质量物品的权重,进而改善算法的推荐结果。
一般情况下,用户在所推荐的结果中,对那些与自己曾经给过高评分类似的物品往往比曾经自己给出低评分的物品更为感兴趣,这种推荐结果会让用户更加满意。这样就可以判定建立用户、物品和评分反馈三者的关系,收集其显示反馈的信息,来调整PR值的计算,增加入度中节点的PR值计算,就能有效地降低低质量对反馈结果的影响。例如:如果某个物品每个用户对其评分并不高,但仅仅因为其物品属于热门物品,就会使得其用户基数大,那么在计算物品相似度的时候,热门物品往往更具有优势。由于这里是计算每个节点的PR值,而不是计算用户之间的相似度,在每个PR值计算的时候加上评分维度,就能保证推荐结果的质量。
由于物品评分维度是用户显示反馈,故而其值与该节点所获得的PR值正相关。假设目标节点为v,所有链向它的各节点的评分集合为G={G1,G2,G3,…,Gn},将评分维度加入公式中,如公式(2)所示:
其中,G表示目标节点v的所有链向它的各节点的评分,由于最高分是5,故而分母为5,使用权重来影响其PR值。这里G值与PR值结果是正相关的。
2.2 发掘PersonalRank算法的长尾能力
那些平时看着不起眼的商品,那些微不足道逐渐被遗弃的物品,占据物品种类很大的比例,甚至超过热门物品的种类,这些被遗弃的物品隐藏着巨大商机,也是企业在无力从热门商品中再获取利益的情况下,可以榨取的收入来源,即使这些快被市场抛弃的物品所带来的利润低,但只要符合用户需求,也是优质的推荐结果,这就是推荐算法需要增强长尾理论的缘由。
现今世界正经历着巨大的变革,互联网的极速发展,使商品的更新换代速度极快。而且当前的企业绩效不再遵循二八原则,而是有严重的重尾分布。以前20%的产品销量占收入的80%,或者说20%的商品品种带来80%的销量,往往又由于追捧热门产品,80%的产品都被遗弃。那么为了发掘算法的长尾能力,就需要从以下两个方面入手:一是推荐结果的多样性。PersonalRank之前的算法是根据对共同物品有过行为的用户进行的推荐,如果存在某些物品由于过于冷门,导致没有用户对其操作过,那么冷门物品将不会被推荐。推荐结果应该以多样性为重要目标,给用户更多的选择。二是保证推荐结果的准确率。当然为了增加算法的长尾能力,增强推荐结果的多样性,并不代表给用户推荐低质量的物品,这样会使得用户对推荐结果不满意。既然推荐结果的用意是给用户推荐用户感兴趣的物品,使得用户对推荐物品产生行为。这样就需要尽可能地了解用户对物品的兴趣,譬如用户的兴趣爱好,或者用户对某些物品有过多次行为,又或者对某些物品有过高的显示反馈也就是评分。通过用户对以往物品给过的高评分,推荐同类型的并且有高评分的物品,从而提高用户对推荐结果的满意度,提高准确率。
当然,推荐物品的多样性与推荐物品的准确率是有一定冲突的。为了保证推荐结果的多样性可能会影响推荐物品的准确率,因为推荐出来的物品可能是用户之前从未有过行为的物品,可能推荐出来的物品是用户不喜欢的。既然如此,从对用户、物品和用户显示反馈三个维度出发,通过用户的显示反馈,推荐出同类型的物品,并且,给出一定的限制措施,这里在同类型的推荐结果中,限制只有被其他用户评分为5分以上的,才会被推荐,这样就能保证推荐结果的多样性以及准确率。
加上同类型物品后,其物品的向量表表示为:Citem={C1,C2,C3,…,Cn},将该物品的向量表加入到PR值公式计算中,如公式3所示:
其中,PRa表示通过用户与物品的协同行为产生的推荐结果;Citem是同类型物品的推荐结果;a是通过PRa推荐出来的结果数,a是通过Citem推荐出来的结果数,N为推荐出来的总数。
3 實验结果及分析
3.1 实验数据及评测指标介绍
本文的数据集来自MovieLens数据集,该数据集中有用户行为数据集和物品详细数据集。由于用户行为数据集庞大,这里采用90位用户的操作数据,共11 724条用户对物品的行为数据。在用户行为数据集中,分别包含了用户主键和物品主键,以及用户对物品的评分。每个用户平均对50个物品有过行为操作。物品详细数据集共包含3 952条数据,分别为物品主键、物品名称和物品分类。
为了避免单次实验导致数据结果的偏差,现将实验数据运行30次,取其平均数,以减小数据的偏差,同时每次运行结果都会推荐30条数据,以验证精确率、召回率、覆盖率和新颖度。
其中,F1为精确率;R为某个用户的推荐结果;Ru为推荐结果与测试数据的某个相同用户的物品数;F2为召回率;T为某个用户的测试数据;Tu为推荐结果与测试数据某个相同用户的物品数;F3为覆盖率;A为某用户的训练数据;Au为某个用户的推荐结果;F4为新颖度;P为推荐结果与测试数据某个相同用户的物品数;Pu为某个用户推荐结果与测试数据某个相同用户的物品数与相同用户的训练数据物品集的对数。
3.2 实验对比
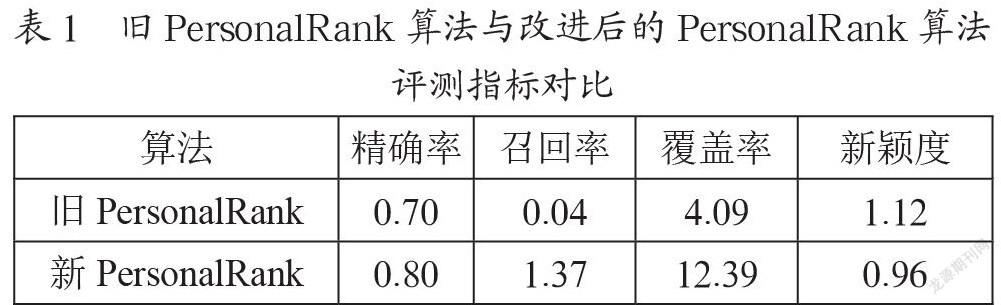
为了验证改进的PersonalRank算法,将旧PersonalRank算法与改进后的PersonalRank算法进行对比,两个算法在数据集中所求的精确率、召回率、覆盖率和新颖度,如表1所示。
由表1中的变化数据可以发现:在改进后的PersonalRank算法下,推荐结果的精确率和召回率有了进一步提升,说明增加用户显示反馈维度后,能够给用户提供更加优质的推荐数据,同时满足了用户个性化高品质推荐的要求。
由表1还可知,在改进后的PersonalRank算法下,覆盖率有了很大的提升,说明公式对数据有较好的契合度。新颖度稍微有所下降。
本文引入了用户显示反馈评分维度并且以用户曾经有过行为的高质量的物品为基础,推荐同类型的高评分的物品,有效地提升了推荐算法的长尾问题和推荐结果质量不高的问题。
4 结 论
本文主要针对传统的personalRank算法存在的长尾问题和推荐质量不高的问题进行了相应的改进。该改进算法根据加入用户显示反馈评分维度来解决质量不高的问题,通过推荐同类型高评分物品来解决长尾问题,通过正相关维度来改善每个点的PR值。实验结果表明:改进后的PersonalRank算法对评测指标的召回率、准确率和覆盖率都有所提高。这就意味着推荐出来的结果更能满足用户的需求。
当然本文算法也还存在不足的情况:其一,PersonalRank算法是基于随机游走的算法,也就是说每个点都会进行运算,这样对于时间运算和空间运算都是一个不小的挑战,此时就需要一种能够有效缓解时间,空间复杂度的算法。其二,该算法需要收集,存储以及处理与用户相关的物品以及物品的类型,所以不适用于冷启动问题。在今后的工作中,尚需不断优化算法,提高推荐结果的精确率和召回率,并将最符合用户需求的物品展示在最前列,同时在时间复杂度和空间复杂度上也要做到均衡,减少算法的时间复杂度和空间复杂度。例如:既然是图算法,就可以从子图构造等方面入手,以减少时间复杂度的运算。当然,除了评分维度这个用户显示反馈外,用户反馈也是可以获取到直观的用户偏好信息,同时也应该注意增强用户隐示反馈,例如那些没有用户明确参与下,通过日志系统分析,或者在线系统分析得到的用户数据,也是可以加入公式中进行完善的。如何以在评测指标为基础,在此基础上制定出更符合用户需求,推荐出用户所需物品的策略,都是未来工作中需要深度探讨的问题。
参考文献:
[1] BREESE J S,HECKERMAN D,KADIE C. Empirical Analysis of Predictive. Algorithms for Collaborative Filtering [J/OL].arXiv:1301.7363 [cs.IR].[2021-05-02].https://arxiv.org/abs/1301.7363.
[2] KARYPIS G. Evaluation of Item-based Top-N Recommendation Algorithms [C]//CIKM ‘01:Proceedings of the tenth international conference on Information and knowledge management.New York:Association for Computing Machinery,2001:247-254.
[3] FOUSS F,ALAIN P,RENDERS J M,et al. Random-Walk Computation of Similarities between Nodes of a Graph with Application to Collaborative Recommendation [J].IEEE Transactions on Knowledge and Data Engineering,2007,19(3):355-369.
[4] 金迪,马衍民.PageRank算法的分析及实现 [J].经济技术协作信息期刊,2009,18(1001):118.
[5] 项亮.推荐系统实战 [M].北京:人民邮电出版社,2012:74.
作者简介:李维(1993.05—),男,汉族,湖北荆州人,开发工程师,本科,研究方向:个性化推荐系统。
3273500338281
