基于词项和语义融合的地铁信号设备故障文本预处理
2021-03-12胡小溪
胡小溪,牛 儒,唐 涛
(北京交通大学 轨道交通控制与安全国家重点实验室, 北京 100044)
在大数据和人工智能的推动下,基于数据驱动的故障诊断[1-2]得到了较快发展,文本数据驱动是其重要分支之一。文本故障数据大量存在于工业界中,是一种以自然语言描述方式存在的非结构化数据,蕴含大量的故障信息,基于文本数据驱动的故障诊断在近年逐渐发展起来[3-4]。但工业界的故障文本记录仍采取人工记录方式,大量故障记录存在模糊性和不规范性,使故障诊断网络的节点数目造成不必要的增多,网络复杂性增大,直接进行故障诊断可能丢失重要信息,造成正确率下降。因此实现故障的文本预处理具有重要意义。
故障文本预处理包括分词与特征提取[5]。在分词方面,文献[6-7]采用基于词库匹配的分词方法实现了对故障记录的识别,该方法实现相对简单、效率较高,但文本识别过程受词库约束较大,需要耗费大量人力维护词库,且无法彻底解决多词同义现象。在特征提取方面,常见的方法包括词频-逆文档频率[8](Term Frequency-Inverse Document Frequency, TF-IDF)、Chi-square分布检验[9]、信息增益、互信息等,其中TF-IDF和Chi-square分布检验简单有效,应用较为广泛。
针对某线路信号设备故障记录的特点,本文提出了一种基于词项和语义融合的轨道交通信号故障文本自动预处理方法。针对各轨道交通线路设备故障记录的独特性、既有的轨道交通词库的不全面性,采用统计学习方法Viterbi-HMM模型[10-11]学习词语的切分规律,用字与字间的共现概率识别新词,形成线路专用信号故障词库,以简化线路专用词库的人工维护量。针对自然语言的模糊性问题,分别采用K-means算法和LDA算法在词项空间和语义空间上聚类,在保留完整语义信息的前提下将故障记录按照关键词聚合成类。针对故障记录的不规范、冗余信息问题,进一步基于Chi-square分布检验和主题-词项分布分别获取故障记录在词项空间和语义空间的特征信息,去除特征噪声。最后,利用K最近邻算法[12]将故障的词袋形式映射到统一专家模板,实现故障记录的纠错和统一化。以某地铁线信号设备故障记录为例,展示了该方法的处理过程,并基于试验结果讨论本方法的有效性与精度。
1 地铁信号故障记录的特点
地铁信号系统复杂,子系统间耦合紧密,服务于司机、综控、调度等多个专业。信号设备的工作状态主要通过这些设备进行反馈并人工记录。通常,需记录下故障现象内容、故障原因和处置措施。但是,不同工种、不同资质的人员对故障的理解和描述习惯不同、故障管理未落实,导致大量记录归类混乱、描述不规范。在故障情况下,由于地铁运营压力较大,设备使用人员需要第一时间先行恢复系统,记录故障的时间有限甚至需要事后补录。因此,故障记录中“故障内容”字段往往偏短、特征信息较少。如表1中展示的某地铁线信号设备部分故障记录(未列出的字段对本研究没有意义),很多“故障内容”明显短于“故障原因”。
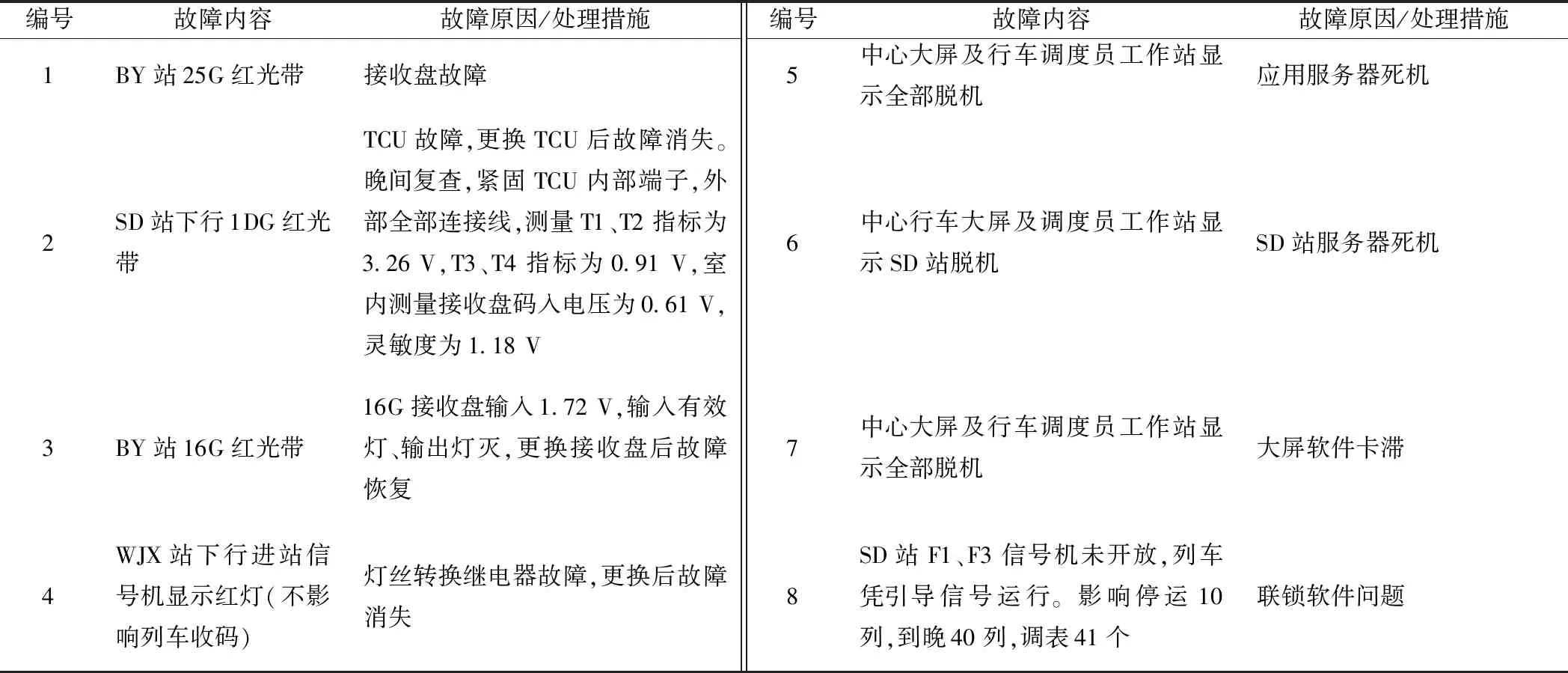
表1 某地铁线信号设备故障记录(部分)
在故障处理过程中,信号人员需要根据现象进行故障定位,因此在“故障原因/处理措施”字段也会包含部分调查过程中的故障现象。例如,表1中的记录3,相比于“故障内容”字段,“故障原因”字段包含更为详细的故障现象。其次,由于存在记录人员的个体差别,“故障原因”字段的文本长度、详细程度、涵盖内容都可能存在较大差异。例如,表1中记录1和记录3属于同一类故障模式,即轨道电路的接收盘故障导致红光带,但“故障原因”字段的文本差异显著。另外,“故障原因”与“处理措施”记录在同一段文本中,而某些处置信息对于故障诊断价值不大。例如,表1中记录2包含晚间复查工作内容及参数数值,规定工序与正常参数值对故障诊断没有作用,需要过滤这些冗余信息。
此外,地铁信号系统采取先进技术设备,其供应商来自不同的国家、不同的厂商,设备命名方式和英文缩写不统一。因此,不同线路的故障记录存在一定的线间差异,包含大量的线路专有信息。再加上自然语言不可避免地存在模糊性、歧义性问题,使得历史故障记录无法直接使用,必须经过预处理,但人工处理不仅工作量巨大而且极易出错。
2 地铁信号设备故障记录预处理
基于词项和语义融合的地铁信号设备故障记录自动预处理见图1,共分为4部分。

图1 基于词项和语义融合的地铁信号设备故障记录自动预处理流程
(1) 构建线路信号专用词库。在轨道交通信号通用词库的基础上,以原始故障文本为输入,识别特定线路设备故障描述的专有词汇,其作为新词与通用词库融合,形成面向线路的信号专用词库。
(2) 词项空间的聚类和特征提取。基于线路信号专用词库完成故障记录的分词,统计得到文档-词项矩阵(Document-Term Matrix, DTM)。再对DTM进行聚类和特征提取,从而形成故障记录的词项类和特征降噪。
(3) 语义空间的聚类和特征提取。为了避免丢失语义上的关键词,采用LDA对DTM进行语义聚类与特征提取。通过在词项层和语义层的聚类和特征提取,融合两个空间,获取融合特征作为故障记录的关键词,得到故障记录关键词的词袋形式。
(4) 融合特征与专家模板的匹配。用词项、语义融合关键词代表故障记录,基于KNN算法,匹配专家模板的DTM,对故障记录进行分类,得到故障记录的标准化描述,实现自动化预处理。
2.1 基于HMM的新词识别
HMM是一种特殊的马尔可夫链,它的状态是隐含的(不能直接观测),需要通过观测量序列推测其隐含状态。观测向量在状态变量的影响下表现出某种概率密度分布,因此HMM是一个双重随机过程,被大量应用在模式识别、语音识别等领域。本文将HMM用于新词识别,即识别出句子中的词,并且是既有词库中不存在的词。
故障记录由句子组成,句子由词组成,词由字组成。句子要分割成词,则组成词的字隐含着一个表示其自身在词中位置的不可观测参数,该隐含参数的取值为Begin(起始字),End(结束字),Middle(中间字),Single(单字成词)。可观测值为已知的故障记录(字序列)。因此,可以将句子的生成过程看作是一个隐含参数序列产生的一个可观测参数序列。
HMM在新词识别中被表示成为一个五元组λ={S,W,T,E,π},其状态迁移图见图2。其中,S为状态值集合,内有四个元素S={Begin,End,Middle,Single},分别表示故障记录中的每个字i(1≤i≤M)在词语中的位置si,M为故障记录总字数。W={wj|wj∈W,1≤j≤N}为观测值集合(字集合),wj为记录形成的字集合中的第j个字,字集合的总字数为N。T=(tm,n)4×4为转移概率矩阵,每个元素tm,n=P(si=n|si-1=m)表示状态值由m转移至n的概率。E=(em,j)4×N为混淆矩阵,每个元素em,j=P(wj|si=m)表示由状态值m输出字wj的概率。π=(πm)1×4为初始状态概率分布,每个元素πm=P(s1=m)表示文本记录中首字的状态值为m的概率,以上的m,n=1,2,3,4。
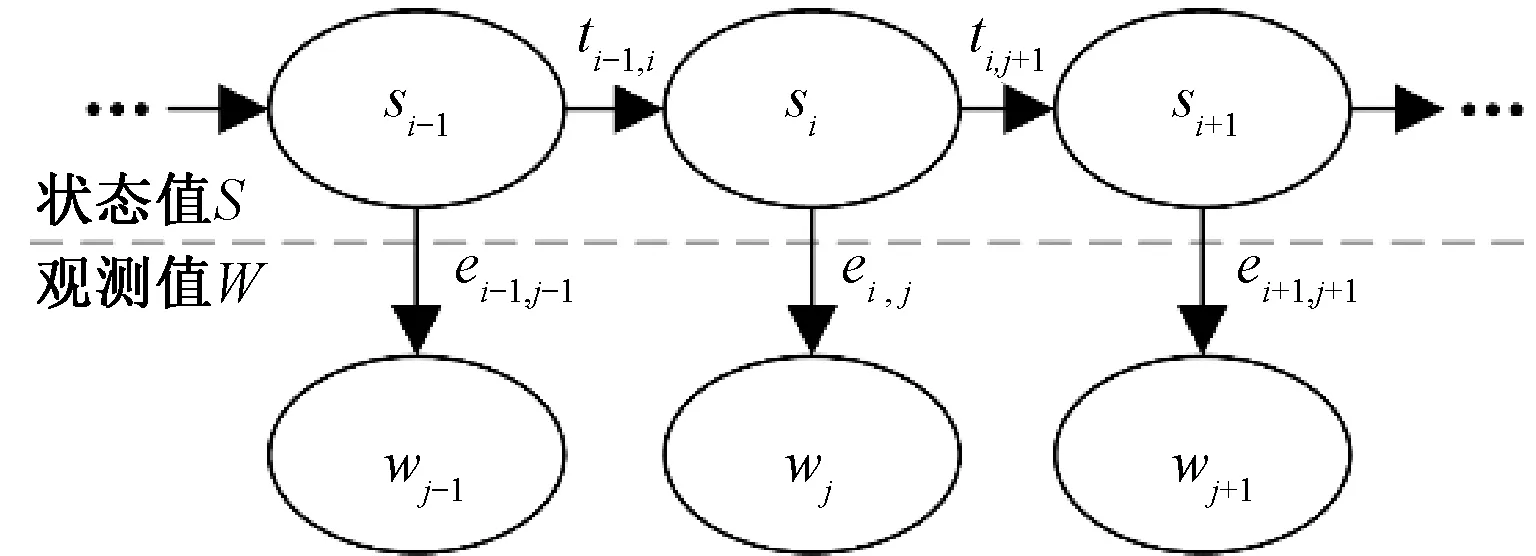
图2 HMM的状态迁移图
基于HMM的新词识别可以看作HMM解码问题:给定W,T,E,π,利用Viterbi算法求解求解S,生成最有可能的状态值序列。再将文本从字状态值为Begin和End处断开,则文本分裂成词。统计词项,去除无意义词项,不存在于既有通用信号词库中的词项为新词,作为线路信号专有词库。
2.2 聚类和特征提取
故障记录的聚类可将相似的记录聚集在同一个簇中,生成类标记,使整个文本集的数量降至簇的个数进行处理。故障记录的聚类流程见图3。其中,类1、类2分别表示故障记录在词项空间、语义空间的类别。词项层的聚类采用基于向量空间模型[13](Vector Space Model,VSM)的K-means,语义层的聚类采用Gibbs-LDA。由于故障记录的故障类别不确定,故障类别总数未知,需确定故障类别数目的大致范围,即聚类数目K。
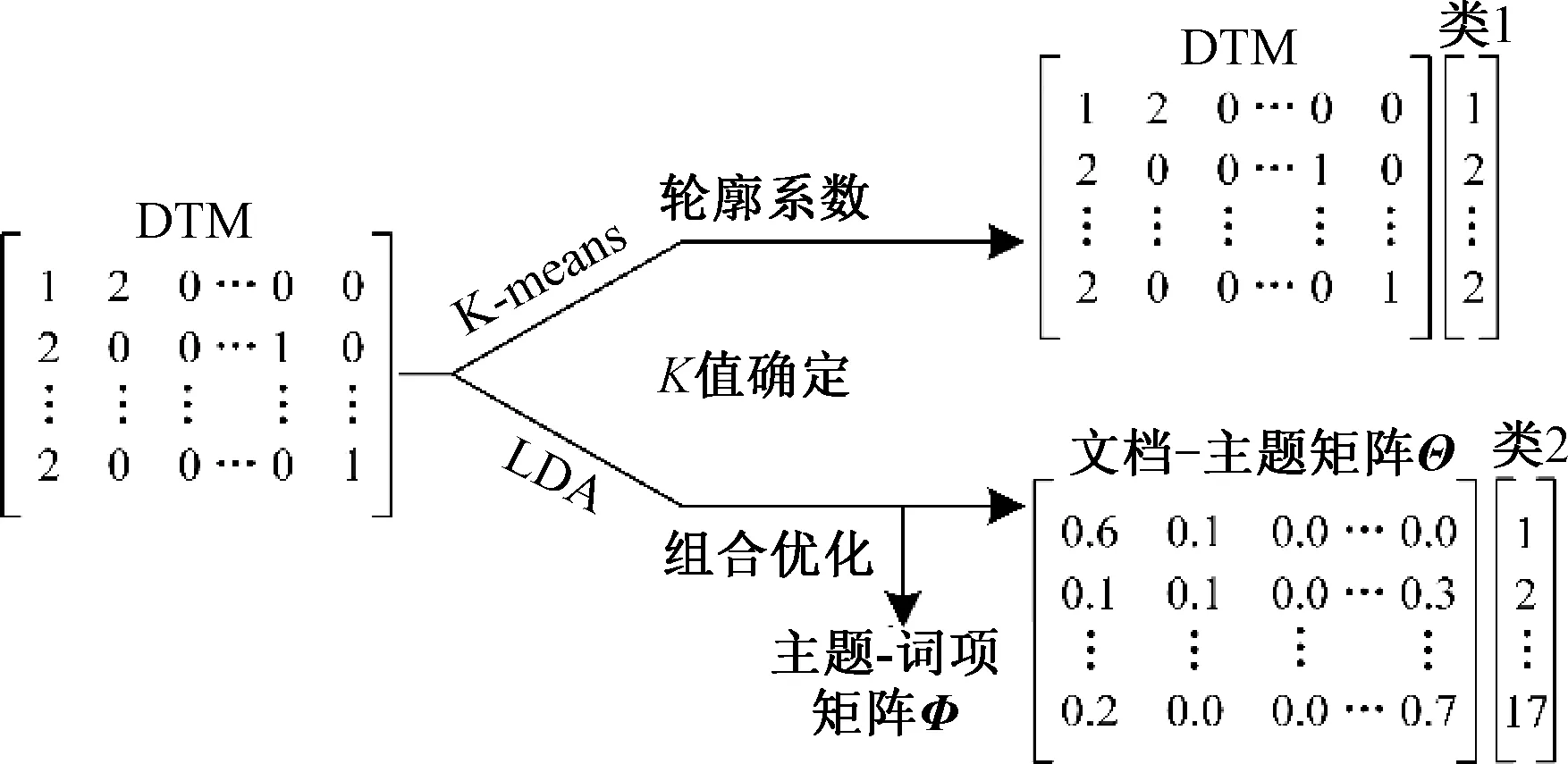
图3 故障记录的聚类
2.2.1 词项空间的聚类和特征提取
K-means是基于距离的硬聚类,采用距离作为基于向量空间的文档-词项向量的相似性评价指标,将相似度高的故障记录聚在一个类中。轮廓系数[14]结合了聚类的内聚度和分离度,因此选取轮廓系数评估聚类的效果,以判断K-means的聚类数目K1。该值处于[-1,1]之间,值越大表示聚类效果越好,计算公式为
(1)
式中:a(k)为第k条故障记录的VSM向量到其他同类别故障记录的VSM向量的距离平均值,反映了故障记录k的类内的内聚度;b(k)为第k条故障记录的VSM向量与任意一个非同类别的类中所有故障记录的VSM向量的距离平均值的最小值,反映了故障记录k的类间分离度;Q为故障记录总数。
在文本处理中,通常利用Chi-square统计判断一个词是否与既定的类别独立[15]。若独立,则说明该词不属于该类;若不独立,则说明该词属于该类。Chi-square值表示各类文档与词库中的每个词的相关程度,计算公式为
(2)
式中:v为特定线路设备词库中的任意词;c为类标记1中类的任意编号;A为类标记1为c且包含词v的故障记录的数量;B为类标记1不为c且包含词v的故障记录的数量;C为类标记1为c且不包含词v的故障记录的数量;D为类标记1不为c且不包含词v的故障记录的数量。
故障记录向量空间模型表示的维度较高,其中含有一些非重要信息。特征提取可以提取表征故障记录类的特征词,以降低故障记录在词项空间上的向量维度,去除次要信息。为了提取故障记录在词项空间上的特征词,采用Chi-square分布检验确定特征词。
由于文档-词项向量是故障记录在词项空间上的表示,维度高,所以K-means聚类粒度较细,但无法表示语义。因此在词项空间聚类的基础上,结合语义聚类,采取LDA进行语义聚类,识别故障记录的语义。
2.2.2 语义空间的聚类和特征提取
LDA是在潜在语义索引[16](Probabilistic Latent Semantic Indexing, PLSI)中引入贝叶斯先验概率形成的主题模型,可用于语义识别。基于Gibbs采样求解的LDA能解决基于EM算法求解的PLSI的过拟合问题。本文采用Gibbs-LDA训练故障记录集,得到文档-主题矩阵与主题-词项矩阵。从输入输出形式上,LDA可以看作是一种矩阵分解,输入DTM,输出文档-主题矩阵与主题-词项矩阵,识别隐含的主题变量,见图4,其中T为词库词项总数,文档-主题分布可以看作是故障记录的软聚类,主题-词项矩阵能给出文档在语义空间上的特征词,其作为词项空间的特征词在语义上的补充。
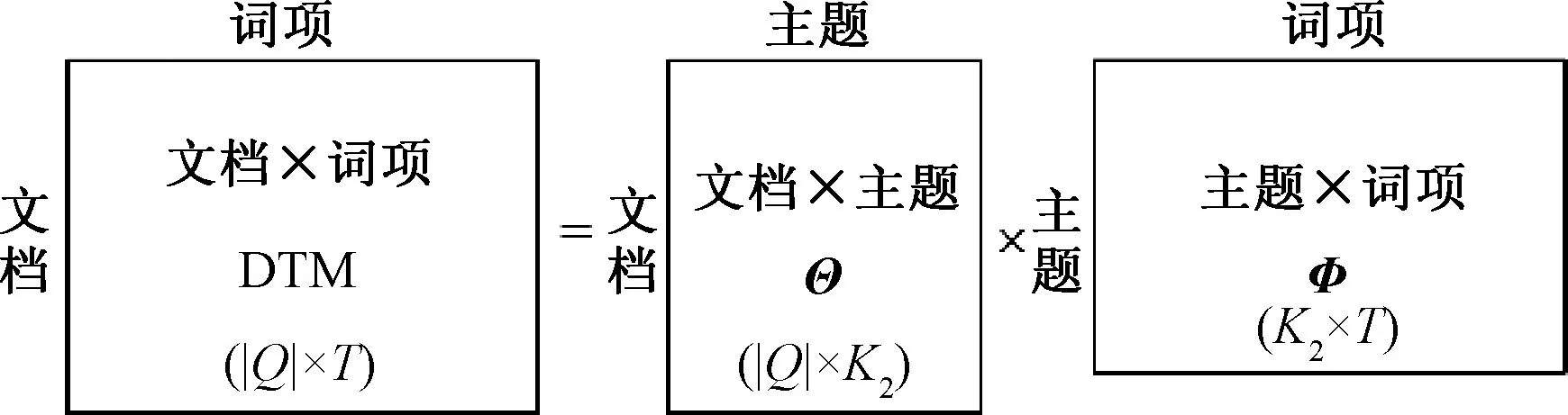
图4 LDA的矩阵分解形式
在LDA主题模型中,主题数K2需要确定重要输入参数,Rajkumar Arun等[17]提出了基于SVD与KL-Divergence的LDA最优主题数确定方法,文献[18]提出了最大化P(Q|K2)最优主题数确定方法,均可以进行主题数的确定。其中,需要最大化Griffiths2004指标[18],最小化Arun2010的指标[17]。
在语义空间中,主题-词项矩阵反映了故障记录集主题的词项概率分布,词项的概率值表征了词项在主题内的重要程度。清除主题内词项概率与主题内最大词项概率相差10倍及以上的词项,得到清除次要特征词项的主题-词项矩阵,其作为语义层上的特征词,完成语义空间的特征值提取。
2.3 特征词融合及基于专家模板的KNN分类
类标记1反映了故障记录在词项空间上相似记录的集群,类标记2反映故障记录在语义空间上相似记录的集群。融合两个空间上的类标记和特征词,得到故障记录在词项-语义融合空间上相似记录的集群(类标记3)和词袋形式的特征词。当且仅当两个故障记录的两个类标记相等,这两个故障记录在融合空间上才属于同一个集群。将专家给出的故障描述模板进行分词,作为KNN的既有邻近数据,进行故障记录的分类,得到致因的统一化描述,流程见图5。
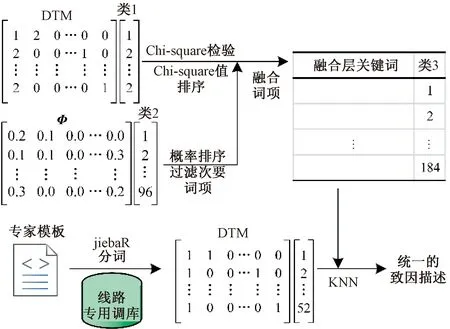
图5 特征词融合及KNN流程
3 案例应用与分析
本文采用某地铁线2015—2017年的地面信号设备365条故障记录为例,对所提出方法进行验证试验。
3.1 某地铁线信号故障记录自动预处理
Step1生成该线路的信号专用词库并结构化故障记录。图6展示了新词识别、该线路信号专用词库的生成和故障记录分词结构化的流程。例如,信号通用词库中对轨道电路的发送、接收设备仅有“发送器”“接收器”的表述名词,对车站级的列车自动监控系统仅有“车站ATS分机”这些通用的术语表述。通过HMM可以识别出该线路的故障记录中专有名词术语“发送盘”“接收盘”“RPU”等。利用得到该线路的信号专用词库进行分词,统计每条记录中词库各词出现的频数,形成DTM矩阵,并进行TF-IDF权重加权。其中,需要过滤的冗余信息不加入词库。
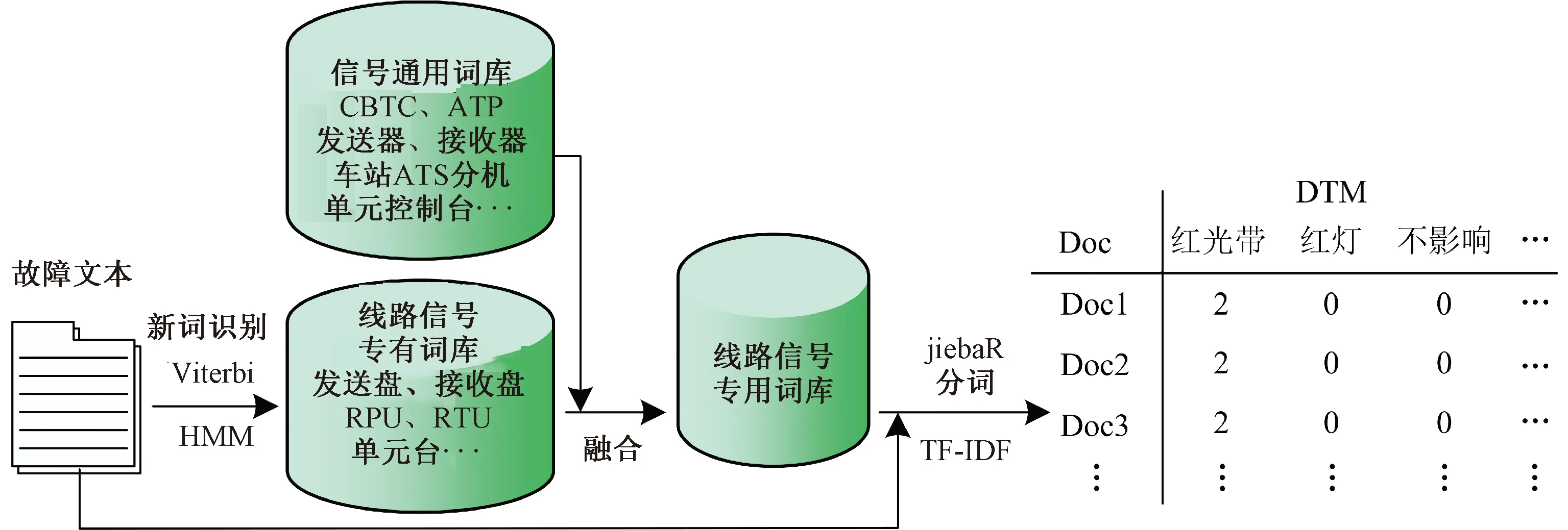
图6 新词识别、该线路信号专用词库的生成和故障记录分词结构化的流程
Step2词项空间的聚类和特征提取。按照式(1),计算轮廓系数与词项空间聚类数目K1的关系,见图7。轮廓系数越大表示聚类效果越好,因此取轮廓系数最大值对应的聚类数目K1=159。以表1展示的故障记录为例,使用Chi-square分布检验提取故障记录的词项层的特征。表2展示了由词项层K-means聚类获取的类标记1和通过Chi-square检验提取的词项层特征词项(按Chi-square值降序排列,未列出的词的Chi-square值过小)。其中,词项层的第3类和第68类故障记录与接收盘故障导致的红光带相关,词项层的第37类故障记录与信号机灯丝转换继电器故障相关。
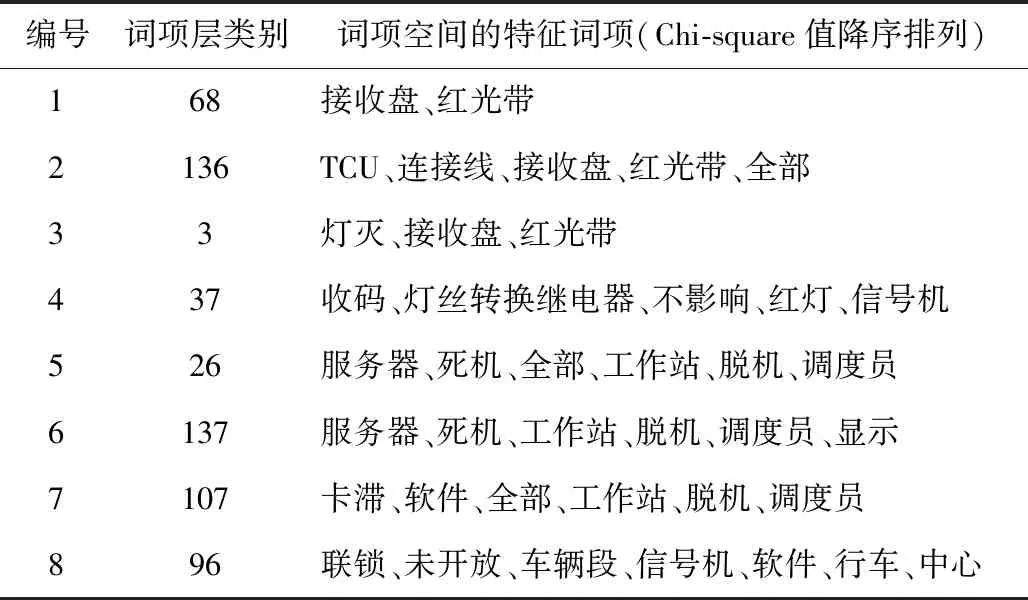
表2 词项层聚类的文本类别及特征词
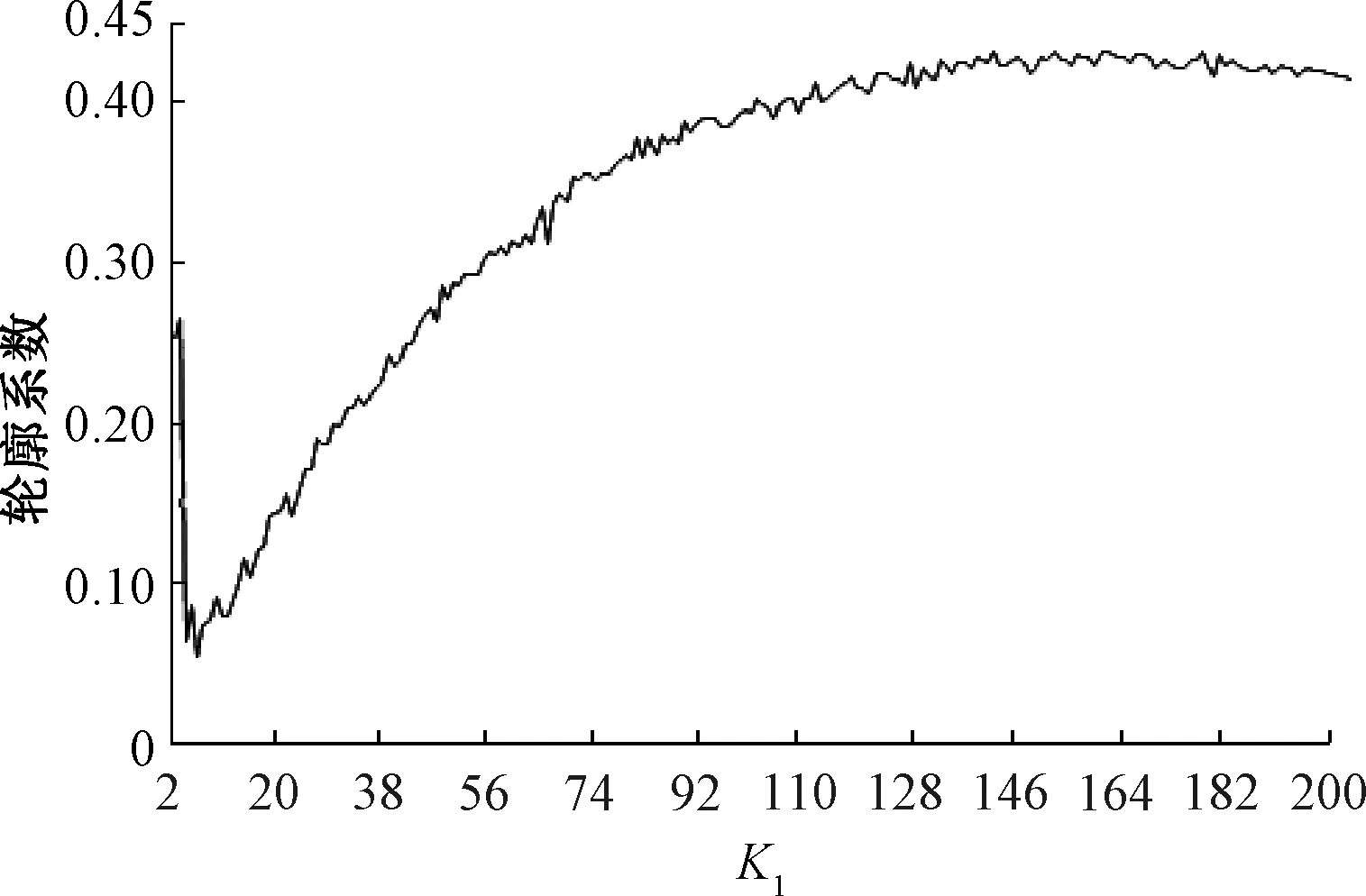
图7 轮廓系数与聚类数目的曲线
Step3语义空间的聚类和特征提取。语义空间的聚类数目K2(主题数)与两种优化判断指标的关系如见图8,G-A为Griffith2004指标与Arun2010的差值。为了使Griffiths2004指标最大化且Arun2010的指标最小化,取G-A最大值时的K2作为最优主题个数,故K2=96。
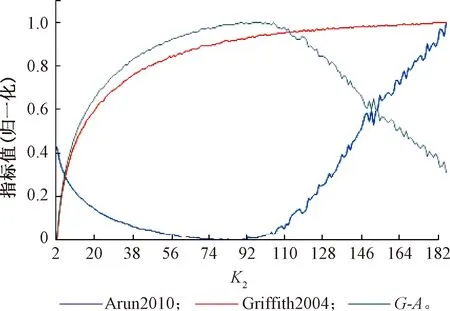
图8 主题个数K2与2种优化方法的判断指标关系
文档-主题矩阵将故障记录转换至主题空间,取文档-主题矩阵各行的最大值对应的主题为相应的故障记录在语义空间的类别。将清除次要特征词项的主题-词项矩阵作为语义层上的特征词,表3展示了表1中故障记录的语义层类别及特征词项。由表3可知,语义层的第21类故障记录与接收盘故障导致的红光带相关,语义层的第19类故障记录与信号机红灯故障相关。

表3 语义层聚类的文本类别及特征词
Step4融合特征与专家模板的匹配。结合表2和表3,融合词项和语义空间上的特征词,得到表1中的故障记录在融合空间上的关键词的词袋形式。结合专家模板进行KNN分类,得到致因的统一化描述如表4所示。
表1中故障记录的试验过程和结果展示见表2~表4。其中,故障记录1和记录3被统一成相同的致因描述,去除了致因描述中的冗余信息,解决了致因记录的不规范和模糊性问题。对于,故障记录5和记录6,其融合空间上的关键词仅相差“全部”词项,导致故障5和故障6被统一精确地归类成不同的致因描述。

表4 故障文本的词项空间、语义空间、融合空间上的类编号、关键词及统一的故障原因描述
对于故障记录7,在提取词项空间的特征时,“大屏”的Chi-square值较低,被认为无法表征该故障记录所在的类。若仅用词项空间的特征词作为新的观测进行KNN分类,则由于丢失了“大屏”一词,进行分类后,被归类成“中心调度员工作站软件卡滞”,错误地表达了故障记录的原意。在语义空间上提取特征时,LDA产生的主题-词项分布内“大屏”一词概率较高,“大屏”词项被认为可以表征该故障记录所在的类。融合两个空间的特征词,获取更为全面的特征词,可以不丢失故障记录的原意,得到融合空间中关键词的词袋形式“卡滞、软件、大屏、全部、工作站、脱机、调度员、显示”。在自动化预处理中,只要故障记录在融合空间的关键词的词袋形式相同,即被认为是相同的故障记录,具有相同的故障原因。结合专家模板进行分词,作KNN分类,词袋形式被统一为“中心大屏软件卡滞/死机”。
3.2 试验效果与分析
文本预处理的效果通常采用精确率P(查准率,Precision)、召回率R(查全率,Recall)、综合分类率F1(F1测试值,F1-score)指标[19-21]进行衡量,计算公式为
(3)
(4)
(5)
式中:ρ=P/R为精确率和召回率的重要性加权系数。在本试验中,精确率和召回率同等重要,即ρ=1。
由于F1是P和R的综合反映,本文通过F1值说明该方法的有效性和准确性,F1值越大表明效果越好。按照式(3)~式(5)计算相应指标,同时,为了验证所提出方法的有效性,利用AN-BP计算在3种特征空间下的预处理F1,见图9。
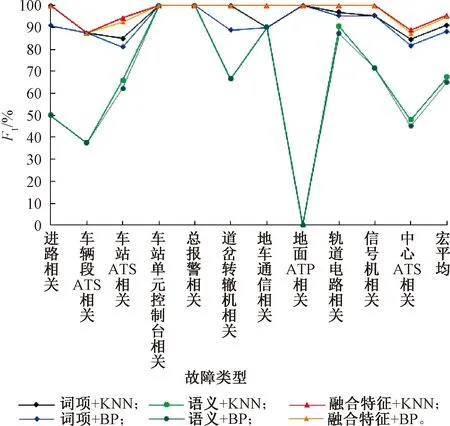
图9 预处理F1指标统计
由图9可知,第一,针对相同的分类器,单独采用词项空间的特征作预处理的效果比单独采用语义空间的特征效果好,采用融合空间作预处理的效果比仅使用一种空间的特征效果好。原因可以从图7、图8和表2、表3中得出:K-means的聚类粒度比LDA的聚类粒度细。由于K-means是基于词项向量的聚类,词项向量的每个维度均为词项属性。信号领域内同义词较多,如同种设备名称的术语、缩写、别称。再加上故障记录描述的模糊性,相同含义的词项占据多个维度,使故障记录类别数K1无意义地增大。因此词项空间中每个簇的故障记录数目较少,使得词项空间的Chi-square特征提取较全面。但词项空间特征无法描述故障记录的语义,在一些故障记录中无法较好地提取特征。LDA是语义空间的聚类,通过评估词项间的共现,将共现频率高的词项聚合,以识别故障记录集的主题和主题的词项,同时可以识别多义词和同义词。导致LDA的聚类粒度粗于K-means,从而使故障记录集进行更有效的降维。这使得在提取语义空间每个类的特征时,主题-词项分布中故障现象词项的概率偏高、致因词项的概率偏低,因此仅以语义空间特征的效果不如词项空间特征的效果好。但是由于LDA的语义识别优势,LDA弥补了故障记录在词项空间上部分簇不能很好地提取特征词项的缺点。第二,相比BP,KNN略微提高了车站ATS相关故障和中心ATS相关故障的诊断准确率。以上两点反映了在分类问题中,通常采用更好的算法提高特征提取的性能,使特征提取的信息更能表征原始数据,而非通过使用更优的分类器去提高分类准确率。因此采取融合特征可以更好地进行故障记录预处理。
4 结束语
本文以某地铁线信号设备故障记录为数据,提出了基于词项和语义融合的地铁信号设备故障记录处理方法。本文采用HMM识别特定线路设备故障描述的专有词汇,以解决基于字符串匹配的分词的缺陷。针对故障原因描述的模糊性,通过细粒度聚类K-means与Chi-square分布提取词项层的特征词。结合粗粒度聚类LDA提取语义层的特征词,以获得融合层的故障记录的词袋描述。结合专家模板和KNN分类,将故障记录进行归类,以获取故障致因的统一描述,实现故障记录的自动化预处理。应用该方法对该某地铁线路地面信号故障记录进行了预处理,宏平均F1值达95.56%,说明了该方法的有效性与准确性。
