基于点-弧结构的路网单组列车编组计划优化线性0-1规划模型
2021-03-12陈崇双郭孜政左大杰2
陈崇双,赵 军,薛 锋,郭孜政,左大杰2,
(1.西南交通大学 数学学院,四川 成都 611756;2.西南交通大学 综合交通大数据应用技术国家工程实验室,四川 成都 611756; 3.西南交通大学 交通运输与物流学院,四川 成都 611756;4.西南交通大学 综合交通智能化国家地方联合工程实验室,四川 成都 611756)
货物列车编组计划简称编组计划(Train formation Plan, TFP),研究如何将车流组合编挂到各种不同到站和种类的列车之中,其合理编制是提高铁路网车流组织效率和提供优质运输服务的重要保证。
我国车流组织工作根据车流的性质进行分阶段考虑,先确定装车地、空车、班列等直达列车编组计划,然后对未被其吸收的车流向就近的技术站集中,进而编制技术站列车编组计划,最后再确定剩余车流的区段管内列车编组计划[1]。在技术站列车编组计划中,单组列车即列车仅编挂一个编组去向,相比分组列车其构成较为简单。由于我国铁路车站改编能力和调车线不足,以及现场车流组织工作的简便性等因素,货物列车中单组列车的比例较高。
路网单组列车编组计划需确定两类决策:①网络中开行哪些列流,即确定每支列流的始发终到站;②每支列流吸收哪些车流,从车流的角度来说,即确定每支车流在其径路上每个车站的改编情况。单组列车编组计划编制问题中,每支车流的径路事先已知(如采用最短径路、特定径路等),只需要考虑如何经济可行地将车流组合成列流。其中,经济性体现在列流的集结费用和车辆的改编费用;可行性体现在满足车站的改编能力、调车线数限制,以及运输组织上的车流不拆散原则和接续归并原则[1]。值得注意的是,车流径路是编组计划问题的输入参数,在其确定过程中已经考虑了线路区间的通过能力。车流不拆散原则要求同一只车流作为一个整体进行运输,使编组计划问题有别于经典的实数型网络流,而是整数型网络流;接续归并原则要求相同终点车流一旦在同一车站改编之后,它们合而不分,采用相同的改编方案输送至共同的终点站,即同终点车流的改编方案具有树形结构。
目前,国内外许多专家学者就铁路网上单组列车编组计划编制进行长期探索,提出了比较合理的数学模型和有效的求解算法[2]。其中的代表文献大致可以归纳为如下两大类:
其一是采用数学规划理论建模。曹家明等[3]设置车流的直达方案、一次改编和多次改编方案为0-1型决策变量,考虑每支车流的方案唯一性约束,建立二次0-1规划模型;同时,巧妙引入独立作业方式来减少变量数目,并利用系数矩阵的稀疏性和分块特点进行线性松弛求解。林柏梁等[4]和Lin等[5]都以车流改编方案和列流方案为0-1型决策变量,考虑方案唯一性约束、改编能力约束、调车线数量约束,构建非线性双层规划模型,上层确定列车始发终到站,下层基于流量平衡思想确定车流改编方案。两者在决策车流改编方案时略有差异,文献[4]基于车流接续最远站法则,即将车流编入车流在始发站的最远去向,以实现无改编运行距离最远;文献[5]是由优化模型计算确定。两者都针对大规模问题设计模拟退火算法。Chen等[6]设置直达列流方案和车流可能的改编方案为0-1型决策变量,考虑方案唯一性约束、改编能力约束、调车线数量约束和接续归并原则,建立线性0-1规划模型,并设计基于树分解的求解算法。
其二是采用网络流思想建模或者求解,即将车流视为流,列流视为弧,列车集结耗费视为弧的固定耗费,改编中转额外耗费视为该弧的长度。李致中等[7]就小规模路网情形建立无约束的网络流模型。史峰等[8]考虑车站改编能力和编组去向数目限制情形建模,并给出逐步添加编组去向的贪婪算法。史峰等[9]提出合并式编组方案的概念,在给定每个站的编组去向方案集的条件下将原问题转化为以各站为终点的普通最短路问题。查伟雄等[10]设置决策变量类似文献[5],考虑车站编组去向数目约束和车流接续归并,建立了非线性(目标函数是高阶多项式)0-1规划模型。该文献将开行直达列车视为新建一个服务,由此将原问题转化为服务系统选址问题,给出逐步减少直达列流方案(即保留有利的编组去向)的启发式算法。
从既有研究可见,铁路网络单组列车编组计划问题,虽然具有多商品网络流问题的特点,但是车流接续归并原则这一独特约束所蕴含的树形结构,使得对其不易建立线性模型和设计有效算法。例如,文献[4-5]采用递推方式设置车流改编变量,导致模型具有非线性结构。史峰等[8-9]刻画接续归并关系也依赖于递推地确定车流改编序列。这两种思路都不便应用强大的商业优化软件以及经典的精确整数规划算法,例如前两者运用模拟退火算法,后两者设计加弧减弧的启发式方法等。同时,Chen等[6]虽然建立了线性0-1规划模型,但是其模型规模随网络扩大呈指数增长,而且树分解算法对于大规模问题的最优间隔(Gap)仍不算很理想。
本文将路网单组列车编组计划优化视为1类具有树形结构的多商品网络流问题,在多商品网络流的点-弧模型的建模框架下,将车流视为商品,引入一组0-1变量刻画每支车流如何选择列流;将直达列流视为服务,引入一组0-1变量刻画网络中开行哪些列流;再引入一类辅助变量保证车流接续归并。基于此,以列流集结耗费和车流改编耗费总和最小为目标,同时考虑车站改编能力和调车线数约束,建立基于多商品网络流点-弧结构的线性0-1规划模型。在合理的求解时间范围内,该模型能够得到高质量的可行解以及紧致的下界。最后采取演示算例和大规模算例,对所构建模型的正确性和有效性进行验证。
1 参数和符号说明
参数及其符号说明见表1。

表1 参数和符号说明
单组列车编组计划建模,涉及一个有向网络G=(V,E),其中节点集合V即车站集合,其元素为技术站和线路交汇的支点站等,有向弧集合E是直接相连的线路区间集合,线路的上下行方向分别对应一条有向边。每支车流(o,d)的径路已知,可以表示为从其始发站o至终到站d沿途经过车站的有序集合。在单组列车编组计划问题中,由于各列流〈i,j〉的编组内容仅为一个组的车流,该列车的运行径路可以视为相同始发终到站的车流(i,j)的径路。
由于车流径路的限制,并非每支车流都可以编组到所有的列流当中。对于车流(o,d)来说,其实际能够编组到的列流可以表示为集合
(1)

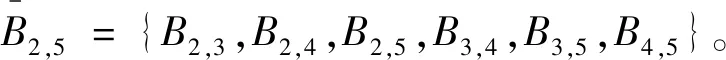
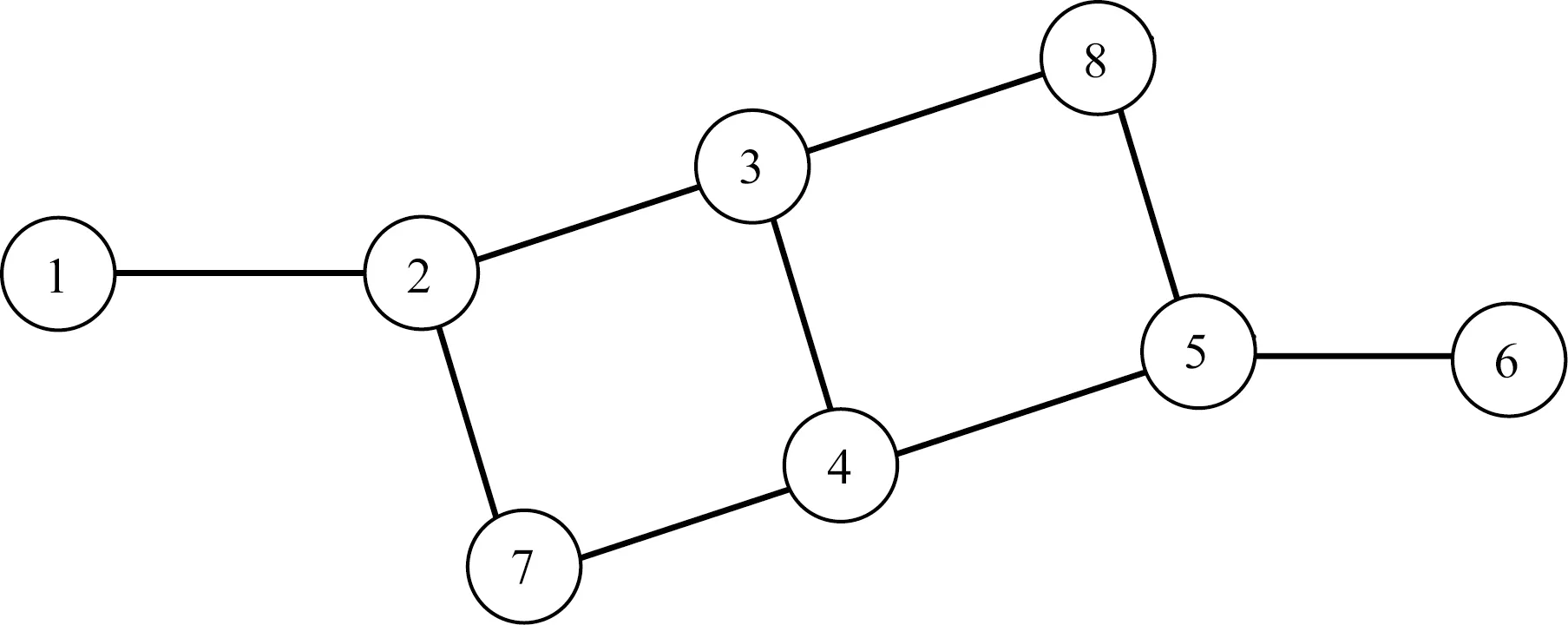
图1 包含8个站的简单路网
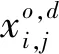

表2 决策变量
2 数学模型
2.1 目标函数
单组列车编组计划问题的目标函数包括两项。第一项为列流的集结耗费,仅与列流设计变量有关,相当于固定费用;另一项是车流在途中车站(不包括始发站和终到站)的改编耗费,与车流改编变量有关,相当于变动费用。目标函数为
(2)
2.2 约束条件
2.2.1 车流流量守恒约束
每支车流都需满足以下的流量守恒约束,即每支车流都沿着其给定径路从其始发站被输送至其终点站。与一般多商品网络流的流量守恒稍有区别的是,该组约束仅考虑各支车流在其给定径路上每个站的流量平衡,而不需要考虑径路之外的车站。其原因在于,车流径路已经事先给定,各支车流只能在其给定径路上沿着从其始发站至其终到站的方向和轨迹流动。
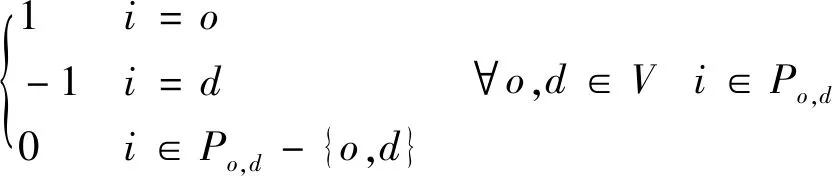
2.2.2 车站改编能力约束
到达某站的车流,包括终到该站的计划车流和在该站进行途中改编的车流,都需要消耗该站的改编能力。在某站改编的总车流量不能超过其可用改编能力,即
(4)
2.2.3 车站调车线数约束
从某站出发的车流,包括从该站始发的计划车流和在该站进行途中改编的车流,都需要占用该站的调车线。从某站出发的总车流量与该站单条调车线的平均容纳能力之比,视为这些车流实际占用的调车线数,不能超过该站可用调车线数的限制,即
(5)
注意,文献[4-5]采用分段线性函数刻画车流占用的调车线数,本文采用线性度量策略。
2.2.4 车流接续归并约束
车流接续归并要求到达相同终点的车流,一旦在同一个站改编之后,必须采用相同的改编方案从改编站输送至终点站,即同终点车流的改编方案具有树形结构。本文用约束式(6)、式(7)共同刻画车流接续归并要求。
(6)
(7)
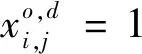
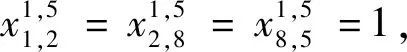
2.2.5 变量关联约束
(8)
约束式(8)包含两种情形:
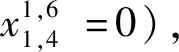
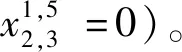
2.3 优化模型
综上,从多商品网络流角度将路网单组列车编组计划问题构建为
∀o,d∈Vi∈Po,d
yi,j∈{0,1} ∀i,j∈V
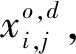
其二,同样由于车流径路的原因,车流流量守恒约束式(3)只要求每支车流在其给定径路上每个车站成立,而非要求在网络中的全部车站;同时,变量关联约束式(8)确保每支车流的径路与其选择列流的径路具有一致性。
其三,为满足特殊的车流接续归并要求,本文所构建的模型额外引入了约束式(6)和式(7),保证同终点车流的改编方案具有树形结构。可见,本文模型中的车流改编变量比一般的多商品网络流模型具有更严格的要求。
3 与既有模型的对比分析
文献[5-6]是最近路网单组列车编组计划优化领域的两篇典型文献,二者的建模思路和求解算法也各具特点。本节从决策变量表达形式、模型规模和模型特点3个方面,将这两篇文献的模型与本文模型进行较为详细的对比分析。
3.1 决策变量对比
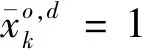
车流改编变量的3种表达形式可以相互转化,下表3以直线单方向上4个车站为例进行说明。表3中,第1列是车流改编方案的序号,第2列是对应的列流方案,第3~5列分别是3种表达方式的车流改编变量的取值。注意,表中省略了直达车流的改编变量。例如,第10种方案中,每支车流都是直达,没有车流采用改编,故非直达车流的改编变量为空。
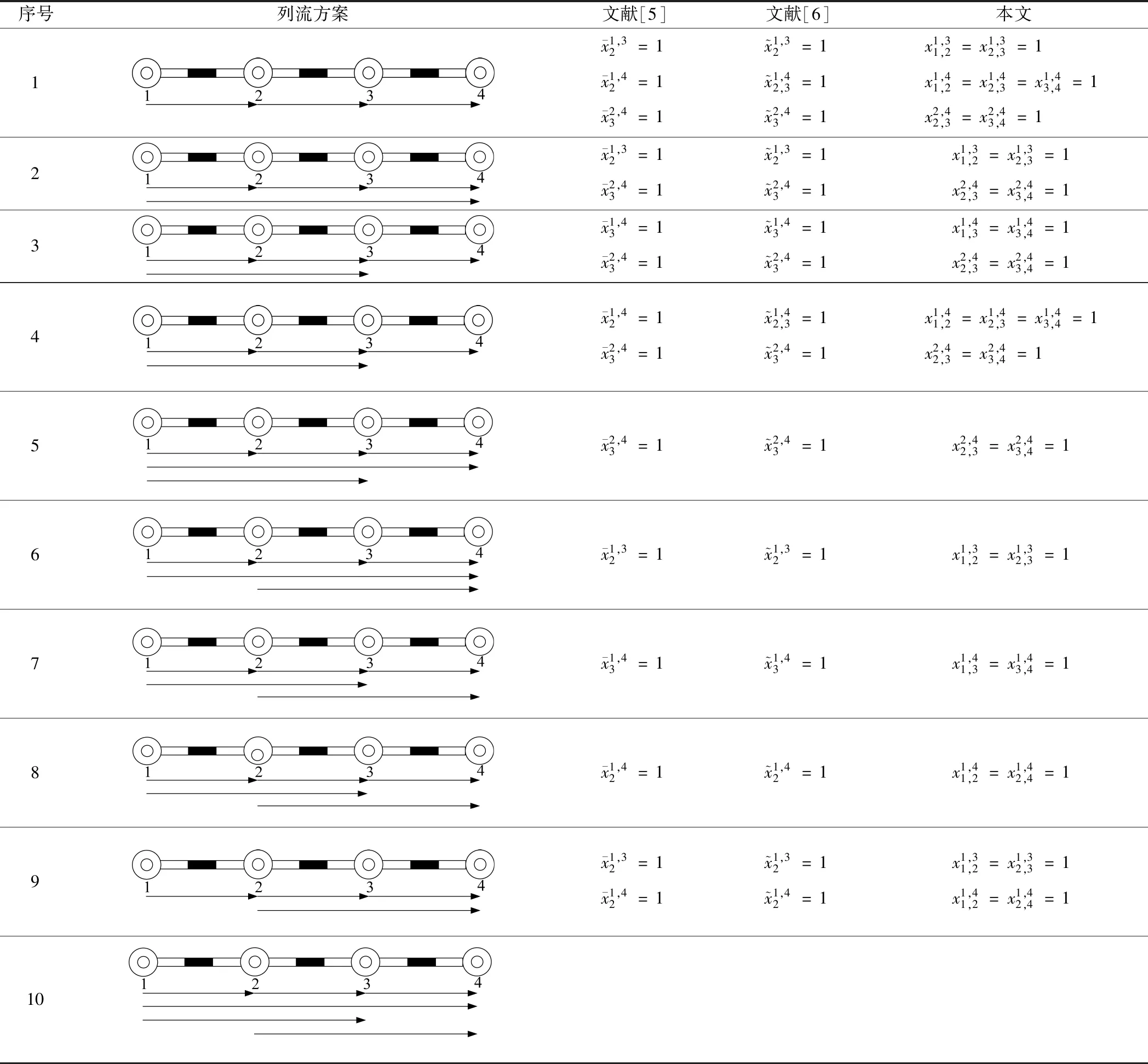
表3 3种车流改编变量表达形式的相互转化
3.2 模型规模对比
3种模型的规模估计见表4。可以看出,本文模型的决策变量和约束条件的阶数都为O(N4),多于文献[5],但是远少于文献[6],后者呈指数增长。主要原因在于文献[6]采用全枚举的方式设置车流改编变量,同时对每个车流改编变量提供一个约束保证接续归并。此外,虽然文献[5]的模型规模最小,但是由递推的车流改编变量显式表达车站的改编负荷和改编费用时,将出现决策变量的乘积项。即使可以引入新的变量和约束消除乘积项进行线性化,然而一方面网络情形的表达将会非常复杂,另一方面也导致模型规模迅速增长。

表4 模型规模估计
3.3 模型特点对比
三种模型的特点总结见表5。可见,在车流改编变量设置上,文献[5]采用隐式递推方式,使得模型具有非线性的结构。尽管文献[6]和本文都建立了线性的0-1规划模型,但结构也有差异。文献[6]的车流改编变量,列举了车流从始发站至终到站全过程的所有可能改编方案,而本文的车流改编变量仅确定车流对单支列流编挂与否。因而前者构建的是多商品网络流的弧-路模型,而本文建立的是点-弧模型。其次,在车流接续归并实现手段上,三者迥异。文献[5]基于递推方式设置的车流改编变量,每支车流改编方案的唯一性实现了接续归并。文献[6]以全枚举方式呈现每支车流的全部改编方案,直接比较同终点车流的改编方案的一致性,以判断接续归并原则是否满足。而本文通过巧妙引入辅助变量和线性约束条件,正确刻画车流改编方案之间的树形关系。

表5 模型特点对比
4 算例分析
采用1个演示算例和1组大规模算例,对所构建模型的正确性和有效性进行分析。采用Matab 2016a编程,并调用CPLEX 12.6求解优化模型。为了公平比较,所有计算都在CPU为E5-2620 2.10 GHz、内存为128 GB的64位GPU上运行。如果没有特别说明,CPLEX的参数都为默认配置。
4.1 演示算例
以文献[5]中的小规模算例,测试本文模型的正确性。该算例的路网是我国哈尔滨局路网的简化,共包含19个支点站,23条边,314支车流。所有车流的径路都按最短径路设置。文献[5]中车站的可用改编能力,是已经扣除了终到车流消耗的结果。为了让本文的计算结果具有可比性,这里将约束式(4)调整为
(9)
对于这个算例,本文的点-弧模型式(2)、式(3)和式(5)~式(9)包含5 066个决策变量,8 926个约束。设置CPLEX的收敛mipgap为0时,0.59 s获得最优解,最优目标值为45 421车·h,与文献[5]以及文献[6]弧-路模型的最优目标值完全相同。
每支车流的最优改编策略见表6,构成19×19的矩阵。在该表中,第i行第j列的单元格中元素k表示车流(i,j)在站k首次改编。特别地当k=j时,表示开行直达列流〈i,j〉。车流的完整改编方案可以由该表递推得出。以车流(7,2)为例进行说明,由表6,该车流先在站5改编后编组到列流〈5,3〉,在站3再次改编后编组到列流〈3,2〉运送至终点站,因而车流(7,2)的改编站为5和3。该表与文献[6]的弧-路模型的最优解并不完全相同,表7列出了改编方案不相同的三支车流。由于它们的车流量均是0,故对于目标函数值不影响。
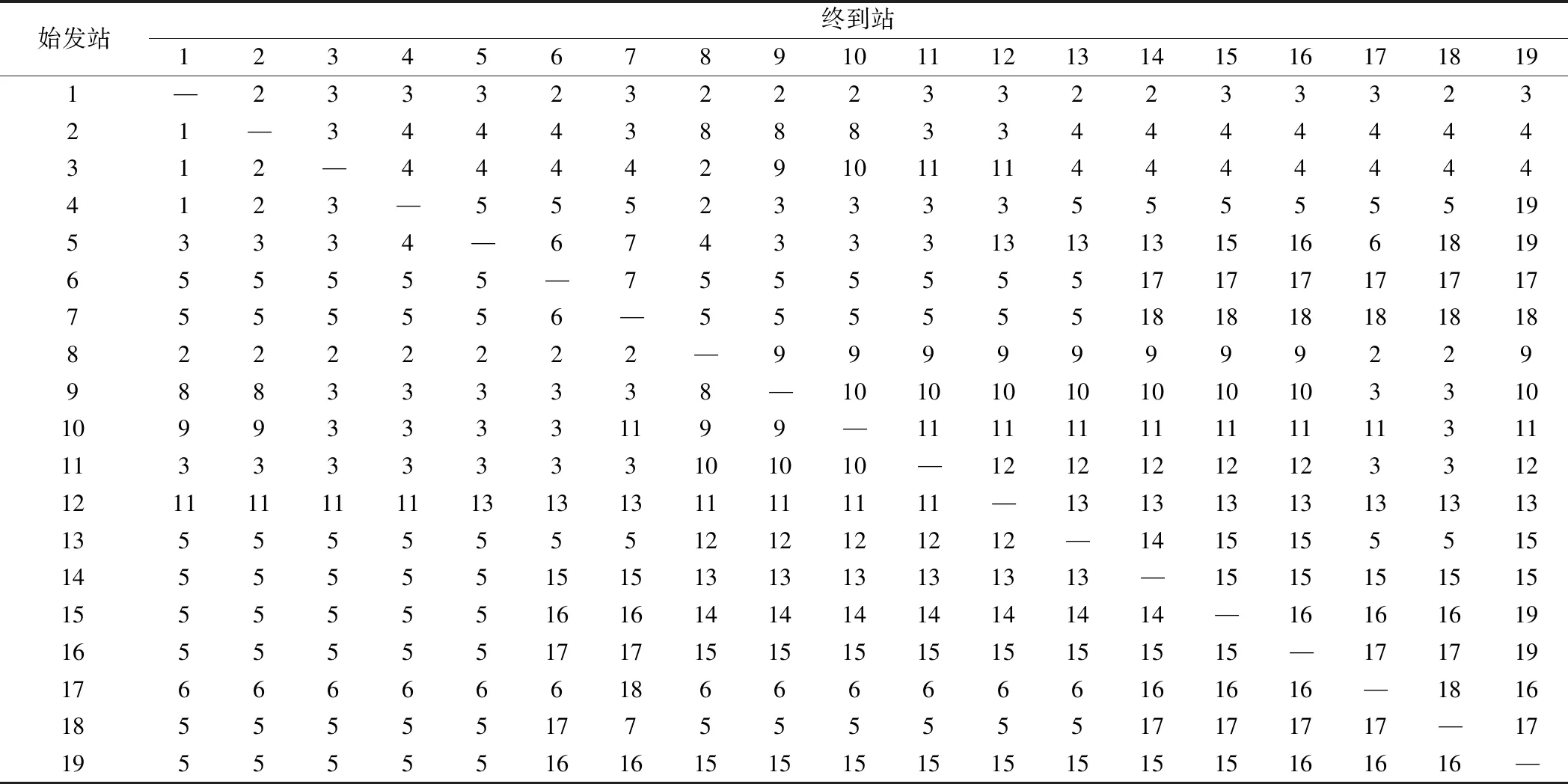
表6 最优车流改编方案

表7 点-弧模型与弧-路模型最优解的不同
接下来分析本文点-弧模型对于车流接续归并原则的正确性。由问题定义,车流接续归并原则规定,如果同终点的两支车流都在某站改编,那么从该改编站至终点站的输送过程中,它们将采用相同的改编方案。本质上,车流接续归并原则强制约束同终点车流的改编方案具有树形结构。为了直观反映这种特殊关系,以终点为站2的18支车流为例进行说明。车流的径路见图2(a)。注意,本算例设定所有车流的径路都取为其最短路,因此,由最短性原则,终点为站2的车流的最短路构成一颗无向树,根节点即为站2。车流的最优改编方案,见图2(b)。可见,除了站2之外,其他站都只有唯一一条出弧,即最优改编方案是以站2为根节点的一棵有向树。对比图2(a)和图2(b)可知,如果车流采用直达方案,无所谓改编;如果采用改编方案,则改编站都限制在其给定车流径路上。例如,对于车流(6,2),其车流径路P6,2={6,5,4,3,2},途中改编车站为5和4均在其车流径路上。
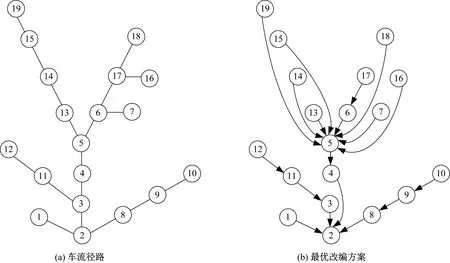
图2 终点为站2的18支车流
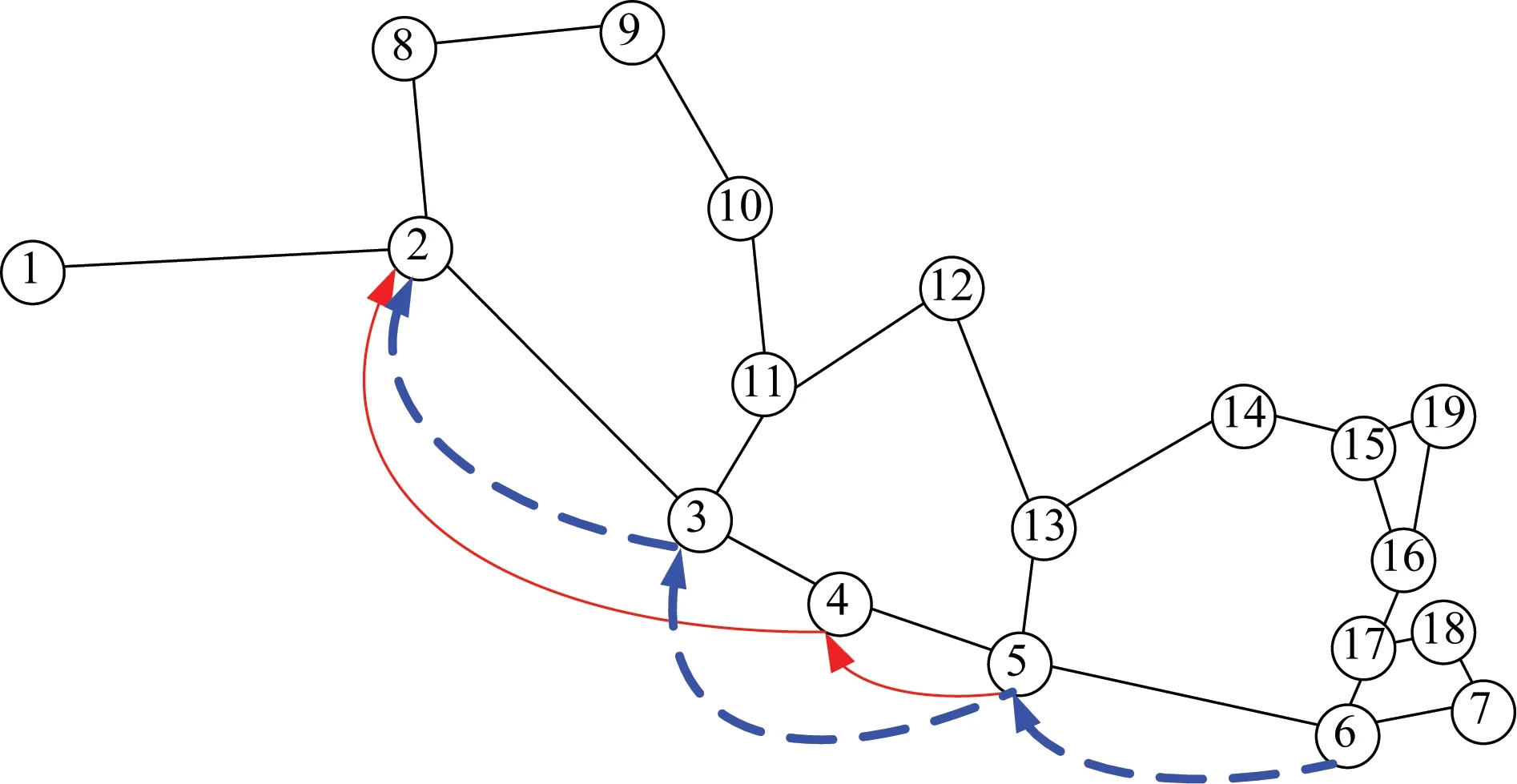
图3 松弛接续归并约束后车流(5,2)和(6,2)的改编方案
4.2 大规模算例
以文献[6]中的10个大规模算例,验证所提出方法的有效性。这些算例的路网是我国铁路货运网络的简化,包括83个车站,158条边,平均约5 700支车流,所有车流的径路都给定为最短径路。由于文献[5]采用分段线性函数刻画车站调车线数约束,而且具有非线性结构,故本文点-弧模型仅与文献[6]的弧-路模型以及树分解算法进行对比。
文献[6]的弧-路模型和本文的点-弧模型,规模对比见表8。本文模型的决策变量数和约束条件数都仅相当于文献[6]的3%,而且系数矩阵非常稀疏,非零元仅占1.39×10-5。

表8 大规模算例模型规模对比
对比弧-路模型和点-弧模型的解质量,设置CPLEX最长运行时间为3 h,结果对比见表9。由表9可得,在3 h限制时间下,一方面,弧-路模型的下界都比点-弧模型小,甚至该模型对算例1、4、5和6的下界为0。另一方面,弧-路模型的上界都比点弧模型大。由于这两方面的原因,弧-路模型的平均最优间隔(Gap)高达63.65%,而点-弧模型平均Gap为9.03%。由于点-弧模型对于算例9和10的Gap较高,为此延长CPLEX最长运行时间为10 h,两个模型的结果对比见表10。延长运行时间后,弧-路模型的下界和上界稍有改善,但平均Gap仍高达60.79%。然而点-弧模型的平均Gap为1.55%,全部Gap低于5%。
对比表9和表10还可发现,当计算时间从3 h延长至10 h,点-弧模型对于算例9和算例10的Gap显著减少。为此,进一步分别设置运行时间为4、5、7 h,应用点-弧模型再次求解这两个算例。算例9和算例10的求解质量与计算时间的关系见图4,观察可知,这两个算例的下界随着计算时间的变化不明显,但其上界在计算时间为3~4 h范围存在陡降,从而使得Gap显著减小,随着计算时间的继续增加,上界和Gap均趋于稳定。可见,计算时间对于点-弧模型的求解性能具有影响,在实际应用时,可取多组不同的计算时间进行尝试,从而对点-弧模型获得求解质量和计算时间的有效折中。
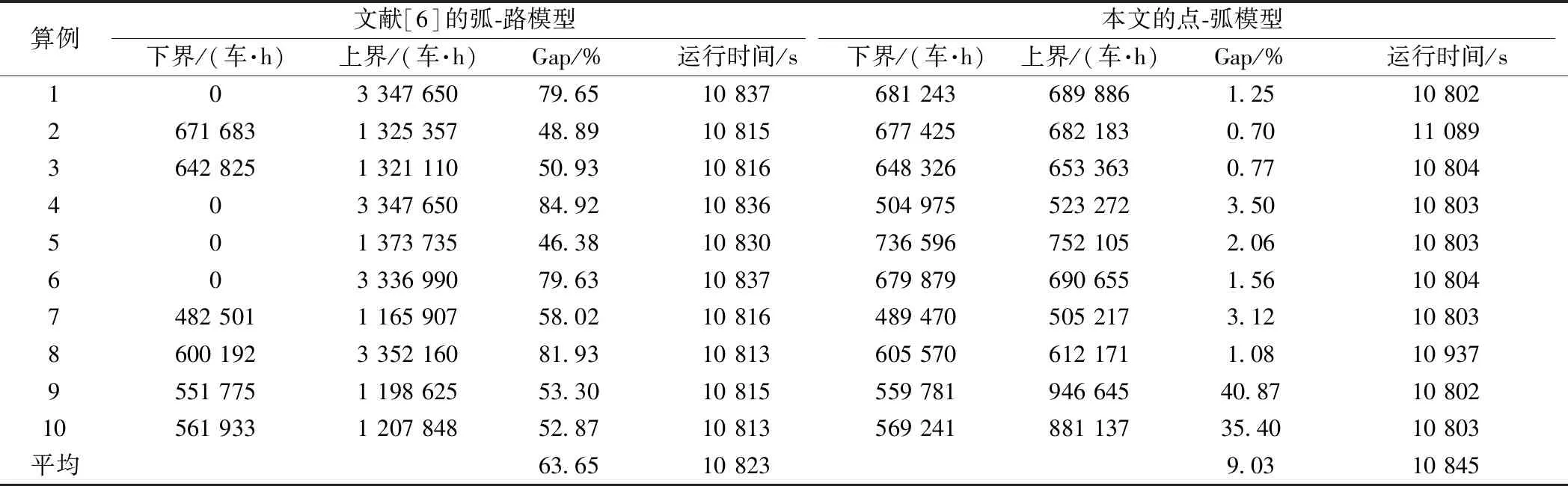
表9 弧-路模型与点-弧模型对比(运行3 h)
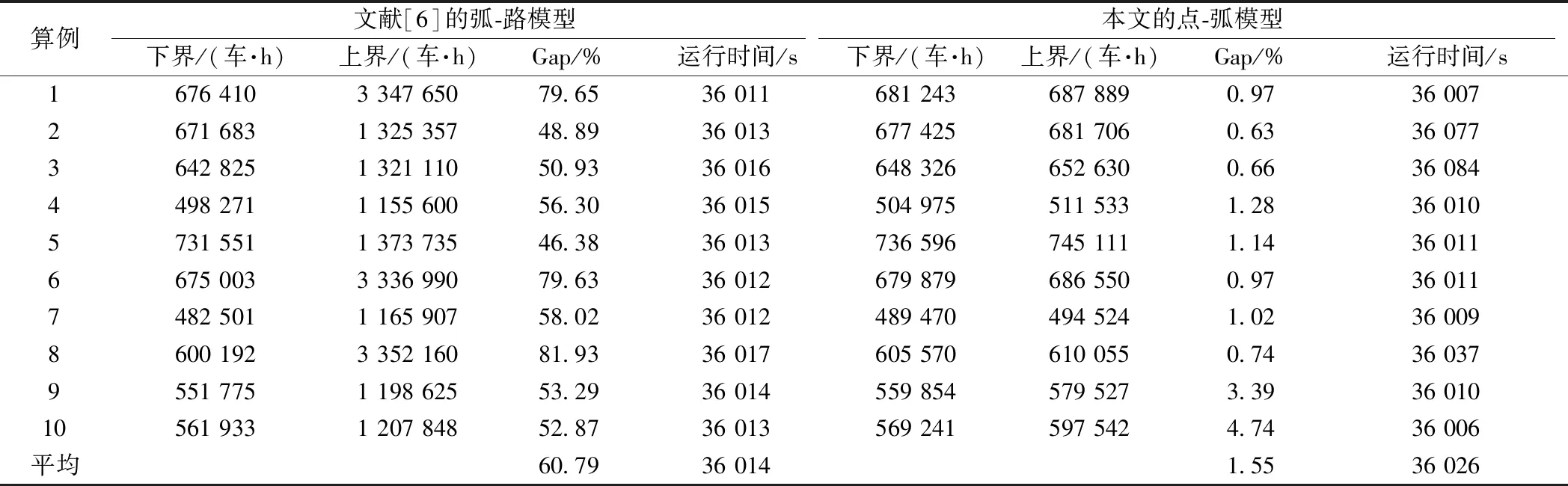
表10 弧-路模型与点-弧模型对比(运行10 h)
考察弧-路模型和点-弧模型线性松弛的定界效果。将模型中所有决策变量松弛为[0,1]的实数,限定运行时间为3 h。表11对比两个模型线性松弛的目标函数值和求解时间。结果表明,相比弧-路模型,点-弧模型线性松弛的目标函数值平均提高3.15%,最高达7.92%(第9个算例)。同时结合表9,两个模型在分支定界过程中的最优下界,相比它们的线性松弛改善都不明显,分别仅增加3.99%和0.10%。在求解时间方面,点-弧模型线性松弛平均14 min就能求到最优,但弧-路模型线性松弛在3 h内都不能求出最优解。可见,相比于弧-路模型,点-弧模型能够在较短时间内提供更紧的下界。
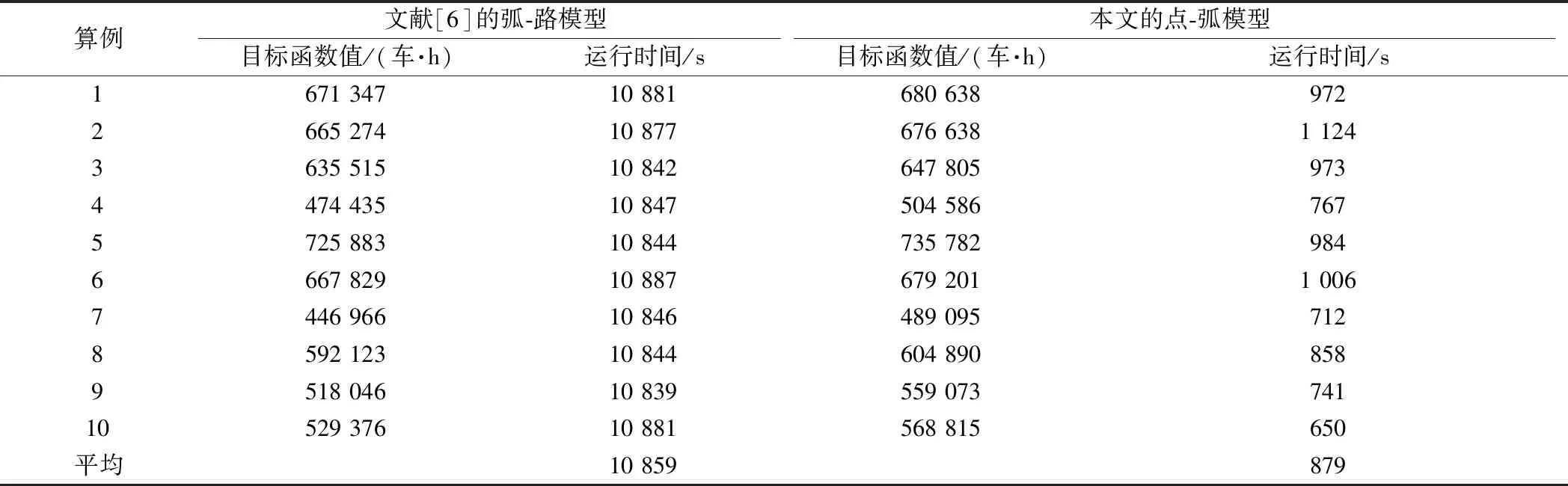
表11 弧-路模型与点-弧模型线性松弛对比
现将文献[6]的树分解算法和本文的点-弧模型进行对比。为了对比的公平性,将点-弧模型的求解时间限制为树分解算法的运行时间。表12列出了两种方法的上界、Gap和运行时间。可看出,树分解算法平均需要1.05 h,最长运行2.15 h,平均Gap为12.51%。而点-弧模型在相同运行时间下,平均Gap为51.98%,其中有3个算例的Gap低于树分解算法。同时结合表10可知,当点-弧模型运行时间延长至10 h时,Gap都将显著降低(全部低于5%)。
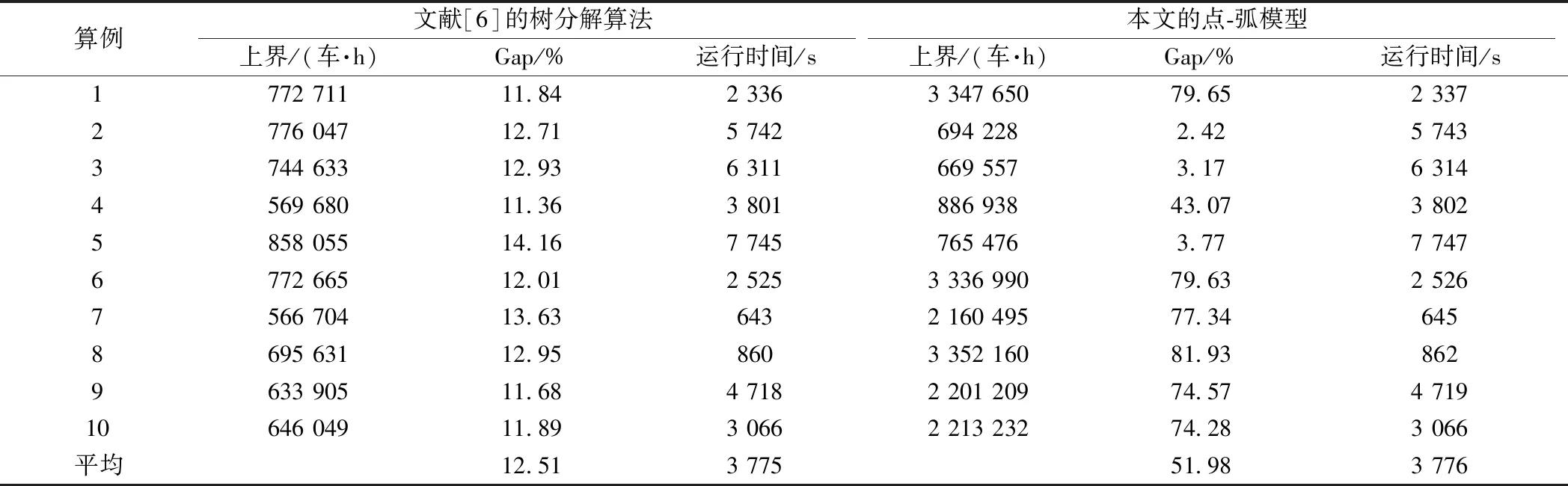
表12 树分解算法与点-弧模型对比
5 结论
本文基于多商品网络流理论研究了铁路网上单组列车编组计划优化问题,借助于多商品网络流点-弧模型的建模框架,建立一个新的线性0-1规划模型。得到如下结论:
(1)将车流视为商品、列流视为服务、车流的改编耗费作为商品的变动费用、列流的集结耗费作为服务的固定费用,同时将车流不拆散和接续归并原则、车站改编能力和调车线限制视为边界约束,则路网单组列车编组计划问题可转换为1类多商品网络流问题。
(2)采用点-弧方式设置车流改编变量,尽管不同于既有模型,但可以相互转化。本文的模型在形式上更紧凑,模型的决策变量数和约束条件数都比文献[6]的弧-路模型显著减少,尽管该模型的规模比文献[5]的模型稍多,但后者是一个非线性模型。
(3)车流接续归并要求使得同终点车流的改编方案具有树形结构,利用这一特点,在多商品网络流的建模框架下,通过引入辅助变量和约束可巧妙刻画这一要求。小规模算例的计算结果表明,本文所提出的基于辅助变量的建模策略,能够精确表达车流接续归并原则。
(4)大规模算例的测试结果表明,本文的点-弧模型相较于文献[6]的弧-路模型在相同时间限制下均可得到质量更高的解。同时,点-弧模型的线性松弛容易求到最优(约14 min),而弧-路模型的线性松弛求解仍很困难。
(5)在相同的时间限制下,本文点-弧模型的可行解逊于文献[6]的树分解算法,但仍有3/10个算例的Gap优于树分解算法。适当延长运行时间(至10 h),点-弧模型的可行解将显著提高(全部小于5%),均优于文献[6]的树分解算法。
本文研究可作进一步拓展。首先,下一步可利用所构建点-弧模型的较优良的数学性质和较高效计算性能,开发有效求解算法,以更好地求解更大规模问题。其次,单组列车编组计划的质量受给定车流径路的影响,未来有价值研究两者综合优化问题,考虑车流不拆散和接续归并两大原则,建立多项式规模的线性模型并设计求解算法。另外,列流设计方案与车流改编方案受到车流量、车站的集结与改编时间参数、改编能力及调车线数等参数的影响,后者的波动性将会影响到铁路货物运输服务的质量与效率,因而研究车站集结与改编时间参数等不确定性下的路网单组列车编组计划优化问题,也将是下一阶段的方向。
