面向移动边缘计算基于强化学习的计算卸载算法*
2021-03-11杨戈,张衡
杨 戈 ,张 衡
(1.北京师范大学珠海分校 智能多媒体技术重点实验室,广东 珠海519087;2.北京大学深圳研究生院 深圳物联网智能感知技术工程实验室,广东 深圳518055)
0 引言
随着万物互联趋势不断加深,网络边缘的智能终端设备不断增加[1-10]。 移动边缘计算是为提升移动设备服务质量而提出的一种具有前景的新范式[11-20]。
(1)以降低时延为优化目标
文献[3]将卸载决策归结为两种时间尺度下的随机优化问题, 并采用马尔科夫决策过程来处理这个问题。通过分析每个任务的平均时延和设备的平均能耗,提出了一个能量约束的时延最小化问题,并设计了一个有效的一维搜索算法找到了最优的任务卸载策略。
文献[4]提出了一种低复杂度的渐近最优在线算法,该算法在每个时隙中通过封闭形式或二等分搜索获得最优解,共同决定卸载决策、移动执行的CPU 周期频率和计算卸载的发射功率。
文献[5] 提出了一种基于云的分层车辆边缘计算(VEC)卸载框架,在该框架中引入了附近的备用计算服务器来弥补MEC 服务器的不足计算资源。 基于此框架,文献采用斯塔克尔伯格博弈方法设计了一种最佳的多级卸载方案,该方案可以最大程度地利用车辆和计算服务器的效用。
(2)以降低能耗为优化目标
文献[6]将卸载决策公式化为凸优化问题,用于在边缘云计算能力无限和有限的两种情况以及在计算等待时间的约束下最小化加权和移动能量消耗。 文献[7]对该方案做出了改进,相比前者降低了90%的能耗。
(3)以权衡能耗和时延为目标
文献[8]分析了单用户MEC 系统的能耗延迟权衡问题,提出了一种基于Lyapunov 优化的云卸载计划方案以及云执行输出的下载调度方案。 在文献[9]中扩展到了多用户系统。
文献[10]研究了在多信道无线干扰环境下移动边缘云计算的多用户计算卸载问题。采用博弈论方法以分布式方式实现有效的计算卸载。
1 MEC
本文讨论一个由一个访问接入点(Access Point,AP)和多个移动设备组成的MEC(Mobile Edge Computing)系统。无线AP 可以是小型蜂窝基站,也可以是Wi-Fi AP。除了用作核心网络的常规AP 之外,它还安装了其他计算服务器作为MEC 服务器。 由于移动设备可能没有足够的计算能力或电池容量来完成计算密集型或对延迟敏感的任务,将部分工作分担给AP 可以有效提高服务质量,降低移动设备能耗。
MEC 系统包括2 个模型:任务模型、计算模型。
1.1 任务模型
本文假设计算任务按照泊松过程到达用户设备(User Equipment,UE),其速率为λa。 将时间划分为单位时隙t0,获得一个参数为pa=λat0的伯努利过程[14]。由此,UE 的任务到达时间是独立的随机变量, 服从带参数pa的几何分布。
到达的任务用二元组(La,μa)描述,其中La表示每个任务卸载到AP 所需上传数据 (例如输入数据和程序代码)的平均大小,μa表示完成一项工作所需的平均CPU周期。 任务到达后UE 根据本地状态、MEC 服务器状态和信道状态进行卸载决策(即选择以x 的概率卸载其任务)。 决策结果表示为Ak∈{0,1},其中Ak=0 表示第k 个UE 选择本地执行任务,Ak=1 表示第k 个UE 选择卸载任务到AP 执行。
本文主要关注的是多用户共享的MEC 服务器的计算卸载决策问题,简化了无线通信部分,考虑了用户在正交信道上工作的情况[15]。 因此用户彼此之间不会受到多用户干扰,这是目前LTE(Long Term Evolution)等通信系统中常见的情况。
由于传输任务数据的信道状态会随时间变化,当任务到达并且信道太差而无法进行数据传输时,UE 应选择本地计算,而不是等待有利的信道条件。
设hk为第k 个UE 到AP 的小尺度信道增益,k=1,2,…,N,式(1)通过香农定理(Shannon theorem)[16]计算得出信道的可靠传输速率Rk:
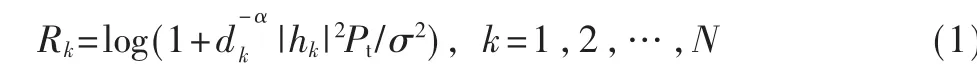

1.2 计算模型
根据卸载策略,已卸载到AP 的任务将被推送到AP缓冲区中等待计算。 否则,任务将被推送到本地缓冲区中等待本地计算。接下来将讨论本地计算模型与卸载计算模型。
1.2.1 本地计算模型
任务在本地计算时,UE 使用自己的计算能力来执行作业。到达且为执行的任务将排列在本地计算缓冲区中。本地计算单元的工作状态通过本地计算缓冲区中待执行的任务还需要几个时隙才能完成来描述,表示为:
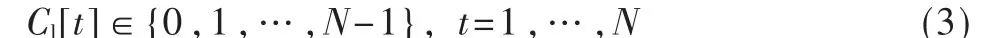
fm(cycles/s)表示UE 的计算能力,UE 本地的计算服务速 率为μm=fm/μa(jobs/s)。 由此,对 于每个任务,系统所花费的时间(包括计算执行时间和在任务队列中的等待时间)可以由式(4)得出:

(2)卸载到达AP 的任务需要一些时间才能在执行后离开AP。 这些任务将被推送到AP 缓冲区中等待计算。AP 计算单元的工作状态通过待执行的任务完成所需时隙来描述,表示为:

与许多现有的研究(如文献[8]、[12]、[13])类似,本文忽略了边缘计算的能耗,因为AP 通常不存在能量不足的问题。
(3)任务在AP 完成计算,AP 将计算结果返回UE。类似于文献[11]-[14]等许多其他相关工作,本文忽略了MEC 服务器将计算结果发送回UE 的时间开销,假设在下行链路方向上保证了计算结果的顺利传输。 因为对于许多应用程序(例如人脸识别)而言,计算结果的大小一般远小于计算输入数据的大小。 则组合式(8)、式(9)、式(11),可以通过式(12)来计算任务卸载的总加权成本:
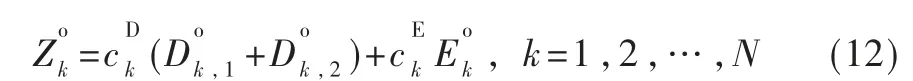
2 ODRL 算法
本文通过计算分析MEC 系统的延迟及功耗计算系统总成本,将MEC 系统的卸载决策看作一个以降低MEC 系统加权总成本为优化目标的随机优化问题,并采用强化学习方法求解最优卸载策略。
强化学习中有状态(state)、动作(action)、奖赏(reward)这3 个要素。 智能体(Agent,指MEC 系统)会根据当前状态来采取动作,并记录被反馈的奖赏,以便下次再到相同状态时能采取更优的动作。 接下来将具体到上文提出的系统模型中介绍。
状态:系统状态由一个二元组τ[t]=(Cl[t],Co[t])描述。 其中,Cl[t]为本地计算单元的工作状态,Co[t]为AP计算单元的工作状态。
动作:根据上述决策方案,UE 将选择以x 的概率卸载其任务,设动作集为A={xi,i=1,2,…,N},分别为UE的n 种不同的卸载决策。

本文采用基于贪婪策略的Q-learning 方法求解优化问题。Q-learning 是一个基于值的强化学习算法,其核心为Q 表(Q-table)。 Q-table 的行和列分别为状态集S 的各个状态和动作集A 的各个动作。 Q-table 的值Q(s,a)记录每个状态所对应的各个动作的效用值,即在某一时刻的s(s∈S)状态下,采取动作a(a∈A)能够获得奖赏的期望。
训练过程中环境会根据智能体的动作反馈相应的奖赏,所以算法的主要思想就是将状态集与动作集构建成一张Q 表来存储Q 值,然后根据Q 值来选取能够获得最大的奖赏的动作。
强化学习的训练目标是最大化其(未来)总奖赏。 在算法训练的过程中,使用式(13)去更新Q-table:
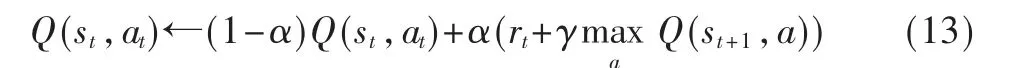
其中,st表示当前状态,at表示当前动作,st+1表示下一状态;rt表示即时奖赏;α 表示学习速率,且0<α<1,其取值大小影响价值函数的收敛速度;γ 表示折扣因子,且0<γ<1。
为避免算法陷入局部最优,本文采用ε-greedy 策略权衡强化学习的开发与探索。即智能体在已知的(s,a)二元组分布之外,以概率ε 选择探索其他未知的动作。
3 仿真结果
3.1 实验环境
本文采用Python 编程实现仿真实验,表1 给出了程序实现的具体环境。

表1 实验环境
ODRL 中的训练参数包括外循环次数e、折扣因子γ、学习速率α、贪婪策略ε。
一次外循环(episode)指智能体在环境里面根据某个策略执行一系列动作到结束的这一过程,算法通过多次外循环不断更新Q 表得到一个最优的计算卸载策略。外循环次数e 一般要足够大,但是如果过大,则会导致邻域搜索时间过长,从而影响算法的性能。 经过实验(如图1 所示)发现,100 次外循环后Q 函数收敛速度放慢,奖赏提升趋势不大,因此可以设置e≥100。
由于学习速率α(0<α<1)影响Q 函数的收敛速度,本文使用指数减缓(exponential decay)方法调整学习率,即学习率按训练轮数增长指数差值递减,如式(14)所示:

其中,α′表示下一轮外循环的学习速率,α 表示当前外循环的学习速率,e 为当前外循环次数。
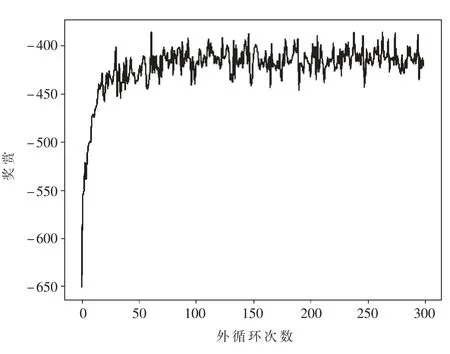
图1 奖赏随外循环次数增加的变化
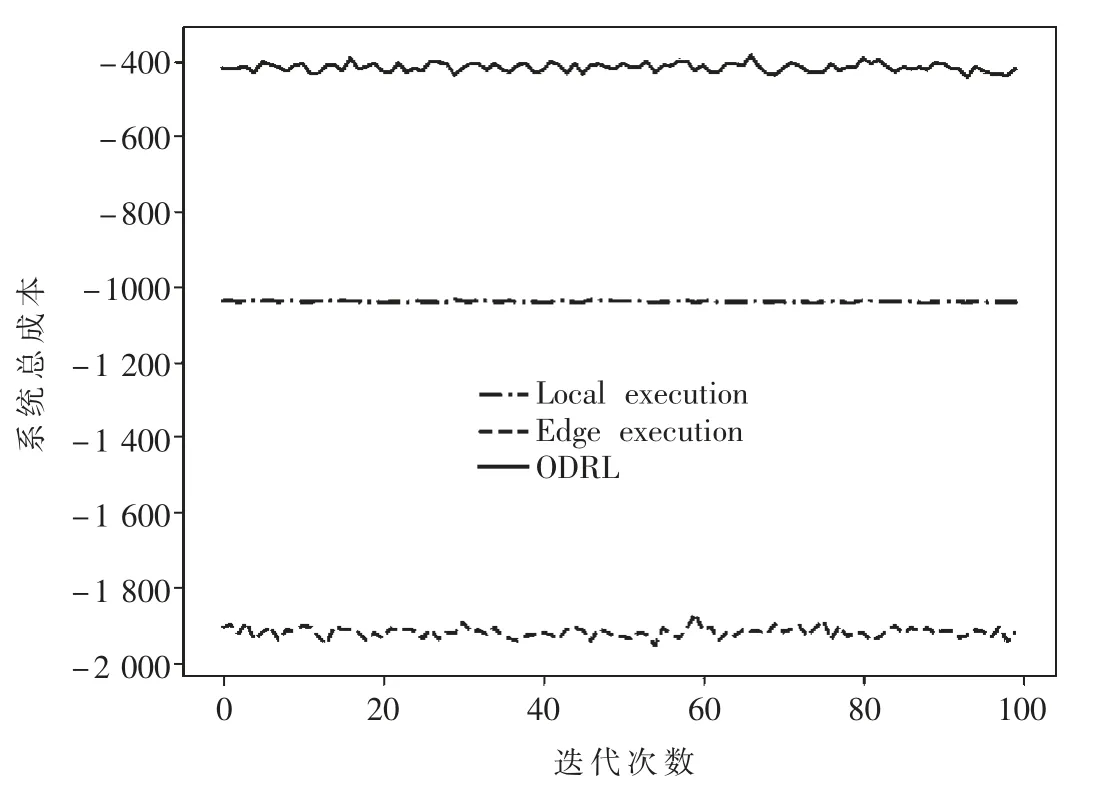
图2 3 种决策方法在100 次仿真实验中的系统总成本
折扣因子γ 的取值范围为0 ≤γ<1,γ=0 表示重视即时奖赏,γ 趋于1 表示重视将来奖赏。γ 决定时间的远近对奖赏的影响程度,即牺牲当前收益来换取长远收益的程度。 本文在实验中设置γ=0.5。
贪婪策略ε 表示每个状态探索新动作的概率,ε 较大时学习过程可以快速收敛,但容易陷入局部最优,通常取值为0.1。
本文考虑由一个AP 和多个移动设备组成的MEC系统。200 个UE 均匀地随机分布在一个以AP 为中心且半径为0≤dk≤75(单位:m)的环上。参考相关工作,本文设置了各项环境参数,如表2 所示[17-18]。其中,W 是取决于设备芯片架构的能耗系数,Pt表示完成一项工作所需的平均CPU 周期,σ2表示每个任务卸载到AP 所需上传数据(例如输入数据和程序代码)的平均大小,α 表示任务按照泊松过程到达用户设备速率,fB表示本地计算所花费时间的权重,fm表示本地计算能耗的权重。
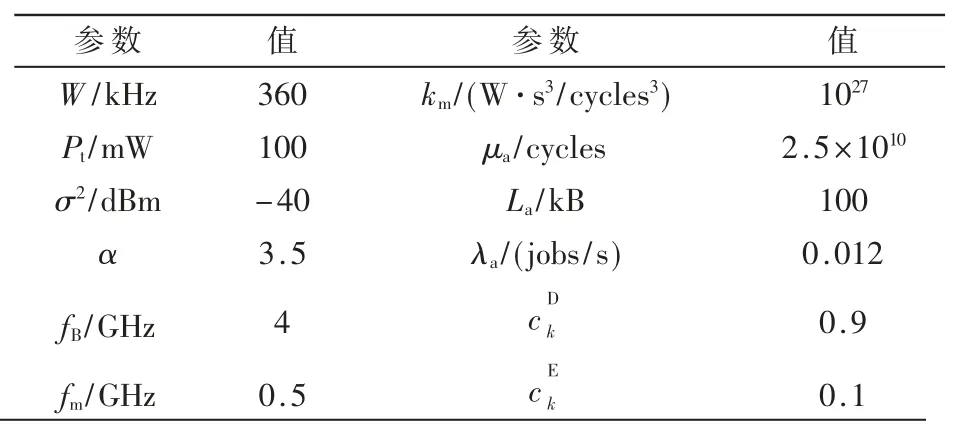
表2 环境参数
3.2 对比试验
为了验证本文所提出的ODRL 在求解MEC 计算卸载的卸载决策问题的有效性,将所提出算法与两种基线策略进行了对比实验。
图2 中给出了100 次仿真实验中3 种决策方法的系统总成本,Local execution 表示任务到达时所有UE 都选择在本地执行任务,Edge execution 表示所有UE 都选择将到达的任务卸载到MEC 节点执行。可以看出ODRL的平均表现优于两种对比策略,使得系统总成本大幅度降低。
在图3 中,将ODRL 与两种基线策略在MEC 服务器性能不断提升的条件下各进行100 次仿真实验,得出不同MEC 服务器性能下系统总成本的平均值。 从实验结果中可看出,ODRL 的系统总能耗最低,可以达到最好的效果。 随着MEC 服务器性能的提升,被卸载任务的执行时间缩短,ODRL 与全卸载策略产生的平均系统总成本降低。 当本地执行策略的总成本曲线并没有随着MEC 服务器性能提升而变化。 fB>5 GHz/s 时系统总成本下降较慢,且ODRL 与全卸载策略产生的平均系统总成本趋近。 则当MEC 服务器性能过强时,系统总成本主要受传输信道条件制约。
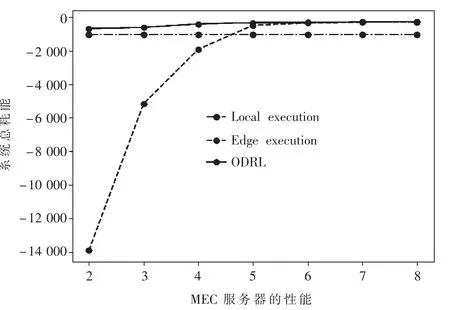
图3 系统总耗能随着MEC 服务器性能的变化
4 结论
本文通过分析移动设备的时延和功耗,提出了一种基于强化学习的计算卸载决策算法ODRL。 与两种基准策略相比,ODRL 在仿真实验中达到了最小系统总成本,可以有效地提高服务质量。在未来研究中,会进一步考虑将算法拓展到多接入边缘计算的场景中。
