二值VGG 卷积神经网络加速器优化设计*
2021-03-11张旭欣李新增
张旭欣,张 嘉,李新增,金 婕
(上海工程技术大学 电子电气工程学院,上海201600)
0 引言
深度卷积神经网络(Convolutional Neural Network,CNN)已经成为了当前计算机视觉系统中最有前景的图像分析方法之一。
近 年 来,随 着Binary-Net、Dorefa-Net、ABC-Net 等[1-3]低精度量化神经网络的深入研究,越来越多的研究集中于在FPGA 硬件中构建定制的加速器结构,实现CNN 的加速[4]。 基于FPGA 的低精度量化神经网络实现主要可分为两类:流架构[5-6]和层架构[7-8]。 其中,由于流架构实现了流水线化,每个阶段都可以独立处理输入且可以针对CNN 逐层设计并优化相应层的加速运算单元, 因此拥有更高的吞吐率和更低的延迟以及内存带宽,但其逻辑资源等消耗也相当可观。 因此,现有的基于流架构实现的二值神经网络加速器研究大多是针对32×32 尺度MNIST 数据集等小尺度的图像输入。 而实际应用中更多使用如448×448 尺度的YOLO、224×224 尺度的VGG 等作为骨干网络,一方面,大尺度输入的网络结构参数量往往较大(以VGG 为例,其参数量大约500 MB),高端FPGA 的片上内存容量也仅32.1 Mb 左右,这对FPGA 实现CNN 加速将是资源瓶颈。 即使采用低精度量化策略,FPGA 有限的片上内存资源仍捉襟见肘。另一方面,虽然各层运算单元可以得到特定优化,然而由于网络拓扑结构限制,往往各层网络很难实现计算周期的匹配,从而造成推断性能难以进一步提高。针对基于流架构的二值卷积神经网络加速器设计存在的资源与性能的瓶颈,本文以224×224 尺度的VGG-11 网络加速器设计为例,重点研究了大尺度的二值卷积神经网络硬件加速器设计、优化及验证,主要工作如下:
(1)针对大尺度流架构的二值VGG 卷积神经网络加速器设计存在的资源与性能瓶颈,提出了网络模型优化和流水线优化的方法。
(2)设计并优化了224×224 尺度的基于流架构的二值VGG 卷积神经网络加速器。实验表明基于FPGA 平台实现了81%的准确率,219.9 FPS 的识别速度,相较于同类型的加速器识别速度最高提升了33 倍。
1 二值卷积神经网络加速器
二值卷积神经网络激活与权值均采用符号函数进行二值化,如式(1)所示:

其中w 为单精度浮点权重,wb为二值权重。 在硬件设计中若以逻辑0 表示-1,逻辑1 表示1,则有:
(1)乘法运算可简化为Xnor 运算和PopCount 累加运算[6]。 因此,对于特征图r 行c 列卷积核大小为(kc,kr)的卷积运算,如式(2)所示:

(2)二值卷积神经网络的批归一化与符号激活函数运算过程如图1 所示。
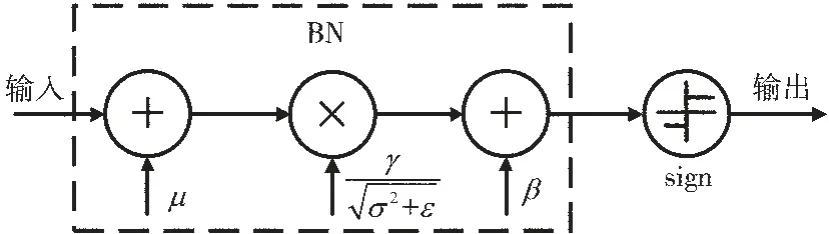
图1 批归一化与激活
若结合归一化与符号激活函数即y=sign (BN(x)),可得:

其中x 为前一层卷积层输出,μ、σ 是批量输入的均值和方差,ε、γ、β 为参数,chin表示输入通道数。
综上所述,二值卷积运算单元(Processing Element,PE)计算流程如下:输入特征图与权值经过同或门与累加器进行卷积运算, 再经阈值比较器实现批归一化与激活函数运算,硬件结构如图2 所示。
卷积层包含了多通道输入与多通道输出。 因此,单层计算引擎通常由PE 阵列构成,如图3 所示,计算引擎从缓冲区读入SIMD 通道特征图,经PE 阵列并行计算得到多个输出到缓冲区。
基于数据流结构的加速器,通过层间流控模块,逐层将二值卷积计算引擎连接起来,整体结构如图4 所示,通过调节各层SIMD 与PE 参数,可以实现性能与逻辑资源的最优化。

图2 二值卷积运算单元
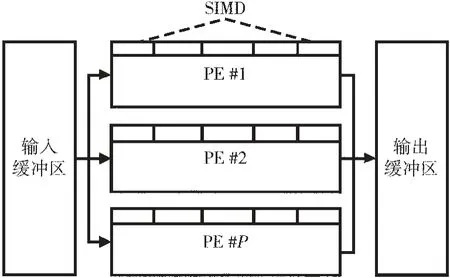
图3 二值卷积计算引擎

图4 数据流架构
2 优化设计
针对二值卷积神经网络加速器存在的资源瓶颈以及性能瓶颈,需要从网络拓扑、流水线运算周期均衡等多方面进行优化设计:
(1)由于硬件资源限制、网络结构以及大量的网络参数,往往造成片上存储资源瓶颈,因此需要首先针对网络结构进行优化。
(2)由于不同网络层运算量各不相同,运算所需周期也不同,因此需要针对流水线进行逐层的运算优化,平衡每层的运算周期。
2.1 网络结构优化
原始VGG-11 的网络拓扑中的首个全连接Fc1 层参数量显著高于其余各层,约占网络整体参数量79%。由于其参数量过大,既造成了片上内存资源瓶颈又导致计算量过大,与其余各层计算周期严重不均衡,使流水线阻塞造成性能瓶颈。针对上述问题,对VGG-11 网络结构的瓶颈层进行优化:
(1)对原始浮点卷积VGG-11 进行二值化,以有效降低内存占用以及逻辑资源数量。
(2)在卷积层与Fc1 层之间添加全局最大池化层,将卷积层输出特征图从7×7 池化到1×1。
优化后的二值VGG-11 网络拓扑如表1 所示,添加全局最大池化层(Global Max Pool)后,Fc1 层参数量降低了约49 倍,同时由于对网络进行了二值化,整体网络参数所占内存空间从511.3 MB 降低到3.66 MB,因而有效地从网络结构层面降低了内存资源瓶颈。
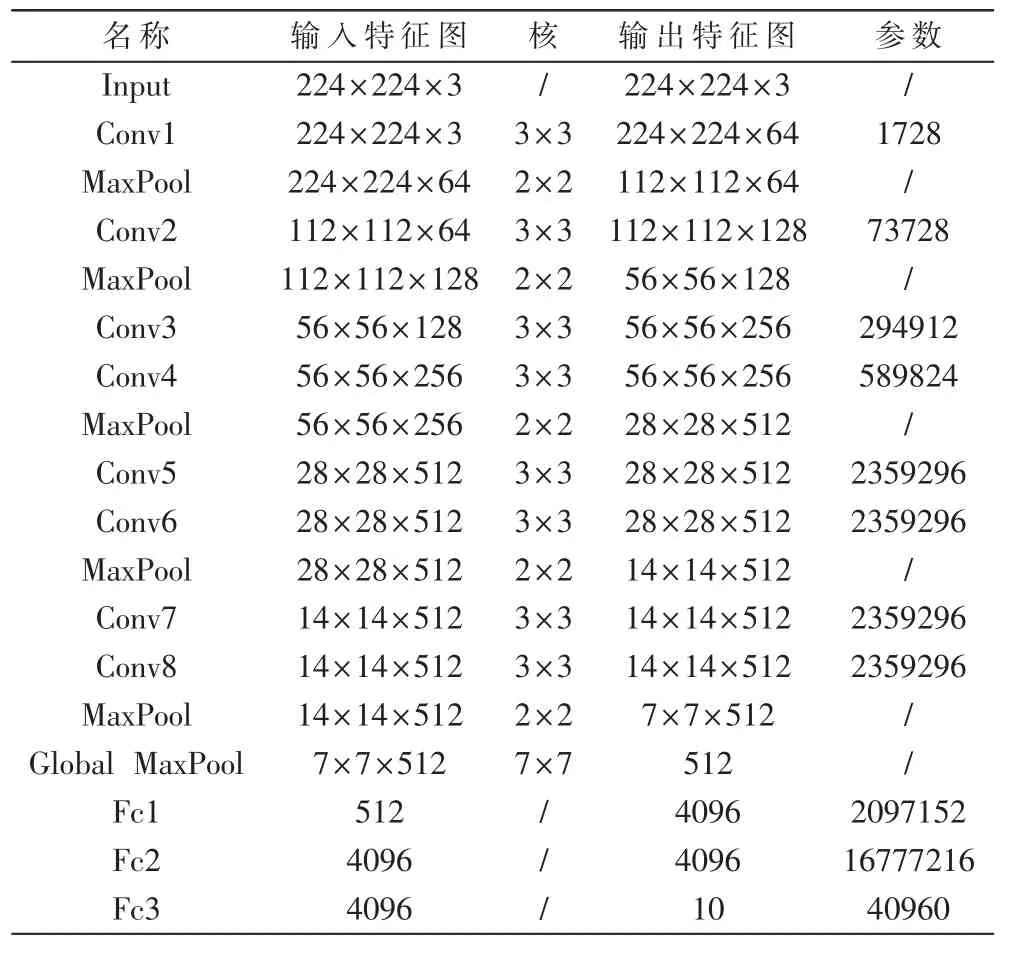
表1 二值VGG-11 网络拓扑
2.2 流水线优化
基于数据流架构示意图如图5 所示,Initiation Interval为两个任务间的时间间隔,Latency 为整体任务完成的延迟。 由于采用数据流架构,网络加速器的吞吐率可以采用Fclk/IImax来进行估算。 计算延迟最慢的网络层会导致任务间的时间间隔最大为IImax,从而决定了网络的吞吐率。

图5 流水线时序图
根据上述分析可知,消耗时钟周期数最多的计算引擎会成为整体性能的瓶颈,从而会造成其他层资源的浪费和性能的下降。因此,针对流水线优化,需要针对不同的计算引擎之间进行整体的计算周期均衡,尽可能地保证各层的计算周期相近。
为了有效提高加速器的性能与资源利用率,本文设计了不同的PE 阵列参数配置,以验证不同的PE 和SIMD 配置对分类效率的影响,表2 中给出的计算阵列结 构 参 数,A 是 最 低 速 的 配 置,B、C、D、E 依 次 增 加 了PE 以及SIMD,E 是根据调整得到的最好的结果。

表2 PE 阵列配置
如表3 所示,根据表2 中SIMD 及PE 参数所对应的各网络层计算周期,通过尽可能将各网络层运算周期均衡调整,从而可以在相应的资源占用率下实现最大化加速器推断速率。
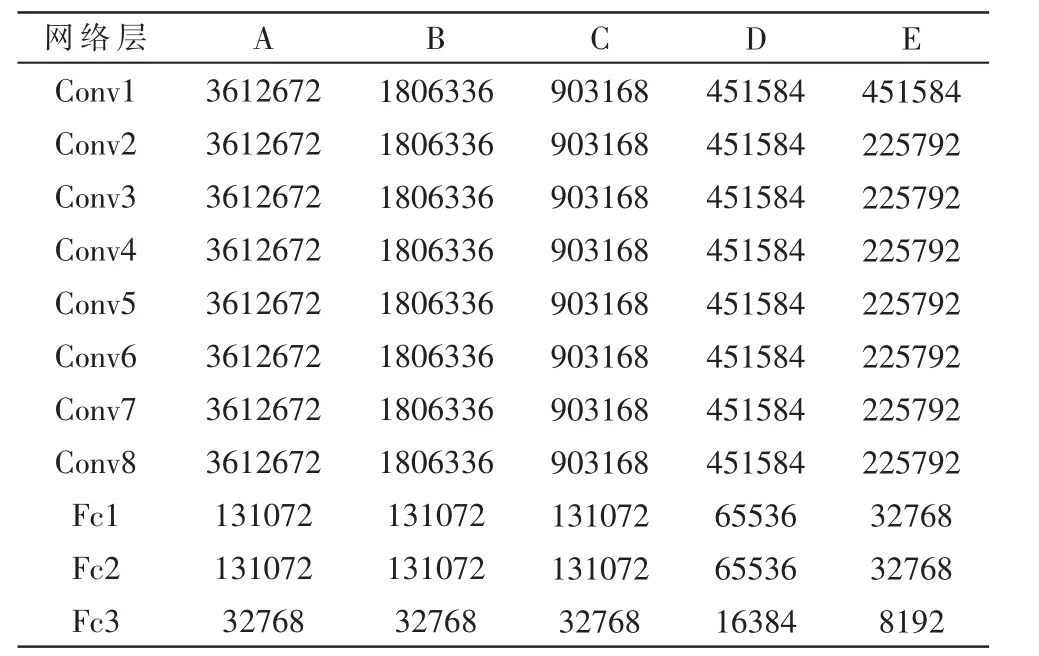
表3 运算周期
3 结果
在Ubuntu16.04 操作系统下,基于Pytorch 深度学习框架训练二值VGG-11 卷积神经网络,实验基于CIFAR-10数据集验证,将数据集图像尺寸放大到224×224 作为网络输入,数据训练利用NVIDIA Quadro P2000 GPU 实现加速。 基于流架构二值VGG-11 加速器硬件系统开发基于ZCU102 开发板,最终硬件系统实现了81%的识别率,推断速率、资源占用率等如表4 所示,最高实现了219.9 FPS。

表4 资源利用率对比
通过实验对比可得出如下结论:
(1)逐渐增加PE 或SIMD 的数量能提高深度神经网络加速器的推断速率,但会占用更多逻辑资源,反之也可以通过降低推断速率来换取逻辑资源占用面积的缩减。
(2)比较方案E 和方案D,除Conv1 卷积层外,其余各层均提高了SIMD 和PE 数量以及缩减了计算周期,然而对比实现结果,可以发现逻辑资源占用率有了大幅增长,而推断速度却并没有得到大幅提升。 这验证了针对于流水线结构的深度卷积神经网络加速器来说,计算周期延迟最大的计算引擎对网络整体性能有较大的影响,在设计中对各层运算单元计算周期进行均衡尤为重要。
(3)对比FPGA 片上资源LUT、FF 以及BRAM 等资源,片上内存数量是限制进一步提高神经网络层数以及提高推断速度的资源瓶颈。
与国内外相关基于FPGA 的VGG 网络加速器实现进行比较,如表5 所示。通过优化设计,实现了相较于其他VGG 加速器最高33 倍推断加速,相比基于层架构的同类型二值VGG 网络加速器[8]提高了7 倍。

表5 基于FPGA 的VGG 加速器对比
4 结论
本文通过从网络结构、流水线均衡等多方面优化设计,实现了输入尺度更大的二值VGG-11 卷积神经网络加速器,并验证了优化方法的有效性,为更大尺度、更深层次的卷积神经网络加速器提供了设计优化思路。
