基于并行计算的多中心海量空间数据高效查询分析研究
2021-03-11石娟
石娟
身份证号码:4312301991****0328 上海 201801
引言
目前基于传统空间数据库的空间数据管理方法由于存储与计算能力有限,在面对海量空间数据的查询以及邻近分析、插值分析、缓冲区分析、叠加分析等空间分析时存在性能瓶颈,严重制约大数据GIS的发展应用。如何将云计算引入到海量空间数据的处理近年来也成为GIS行业的研究热点。
本文结合空间数据特性,基于hadoop分布式框架,从空间数据分布式存储、二级分布式空间索引、大规模数据调度、并行GIS算法等四个方面展开讨论和研究,提出了跨中心的海量空间数据高效查询与分析的解决方案,并进行了测试,实现了海量空间数据的秒级查询响应、分钟级空间分析。
1 空间数据分布式存储
海量空间数据的存储系统主要有三种形式:集中式的文件系统存储管理、分布式数据库存储管理和分布式文件系统存储管理。但由于空间数据的增长速度非常快,数据存储的体系结构逐渐从集中式向分布式转变,从小规模集群逐渐向大规模集群转变,数据管理技术从依托传统的关系型数据库逐渐转向依托非关系型文件系统转变。本文使用基于hadoop框架的分布式文件系统实现海量空间数据的分布式存储管理。
为方便讨论,本文基于hadoop框架构建了一个集群环境,集群环境由若干存储节点构成,空间数据存储至集群环境中形成大数据资源池;由于跨部门、跨网络的基本情况,集群环境的服务器间采用不同带宽的网络连接,形成多中心现象,中心内部为万兆光纤环境,中心间采用千兆光纤连接;中心内部分别部署管理端,支持集群环境管理,具体如下图所示:

图1 基于集群环境的分中心数据存储
当源数据进入大数据资源池时,按照一定规则完成数据的分块,在不同节点进行存储。可根据集群中节点数和单图层数据量的大小,自定义数据的分块大小(如16M、32M、64M...),并且支持自定义备份策略(如1备2或者1备N等)对块数据进行备份。在数据分块存储过程中,为了不破坏空间数据的拓扑关系,我们以数据记录作为最小分割单元对数据进行逻辑切块,确保任一要素对象不被分割至多个Block中[1]。
为了确保中心内部的计算效率,在数据存储时优先保证其中一份副本存储在该中心对应的集群节点中,其他副本随机分布存储至集群的任意节点。基于上述策略,单中心内部数据计算可基于本中心对应的存储和计算节点完成,避免了因随机分布式存储带来的跨中心数据调度问题,数据与计算资源本地化率达到80%以上。
2 二级分布式空间索引
空间数据索引机制是分布式空间数据处理计算的基础,是衡量分布式空间数据库整体性能优劣的关键。大数据环境下,传统的单机的索引结构已不适用于大规模空间数据的查询问题。本文提出了基于分布式架构的二级分布式空间索引,该索引支持快速构建,并且具有良好的扩展性,有效解决大规模数据分布式存储带来的数据检索问题。
二级分布式空间索引采用两层索引机制,索引全局设置一个主控节点,记录一级索引的节点信息。主控节点采用热备的方式,热备节点可以实时同步主控节点的信息,一旦主控节点掉线或出现问题,热备节点会立即启动,取代主控节点的位置,同时主控节点成为热备节点。在主控节点之下,采用分布式集群索引的方式,根据数据类型、数据规模以及操作模式构建不同的空间数据索引集群,空间数据索引集群是一个逻辑控制节点,记录了此集群中数据存储的节点信息、数据类型、数据分布、元数据信息等。不同的空间数据集群,记录了数据的分块信息及其组装拆分的方式。对于用户来说所有的数据都是图层,但是其内部的构成却各自不同,此图层构成的差异性,全部会在集群索引以及空间数据集中进行屏蔽。
通过构建二级分布式空间索引可实现导入云数据库的空间数据自动生成相应的数据元表,并对数据进行标识,可以快速确定单个图层中各个小块所在的节点,以提高空间数据的查询检索及分析效率。
3 数据调度
目前,对Map Reduce的任务调度算法的研究主要集中在:①任务的数据本地化;②多个用户对hadoop集群的计算资源的共享;③容错调度;④集群资源。本文提出了在跨中心的集群环境中的数据调度策略。
3.1 跨中心的空间数据“本地化”计算
基于数据分布式存储策略,在进行跨中心的海量空间数据计算时,优先选择存储“本地化”的节点参与计算,避免数据的跨中心调度,提高分析应用效率。如下图所示(模拟两个中心场景,下同),模拟中心A数据1与中心B数据2进行叠加分析。该场景涉及跨中心计算,系统优先选择DN1.1(A1、a2),DN2.2(B2、b1)两个节点进行计算,无须跨中心调度数据。

图2 跨中心计算无须数据调度分析示意图
3.2 跨中心的空间数据调度
当参与计算的数据分布存储在不同中心、不同计算节点,数据调度不可避免时,系统采用“就近原则”和“少向多原则”完成数据调度。
“就近原则”:分析时优先在中心机柜内部调度,然后在中心机柜间进行调度,最后进行跨中心数据调度。以DN1.1进行A与a叠加分析为例(下图屏蔽其他Block块),优先通过机柜内部调度a3;当a3不存在时,通过中心内部机柜2调度a2;当a2不存在时,跨中心调度a1。

图3 跨中心计算“就近原则”数据调度分析示意图
“少向多原则”:由于相同空间范围内,不同数据图层的要素密度及其属性个数不同,其数据量大小存在区别。当采用相同规格进行数据分块时,如以64M为一个Block,其数据分块数量必不同。在进行数据调度时,优先将Block个数较少的数据块调度至Block个数较多的数据块所在的节点中,利用更多节点进行计算,提高计算效率。同时,在调度过程中根据空间范围对调度的数据进行过滤,进一步减少调度的数据量。

图4 跨中心重度计算“少向多原则”数据调度分析示意图
3.3 超大规模数据跨中心分析应用数据调度
超大规模数据进行跨中心分析应用时,数据调度规模巨大。为了避免分析过程中跨中心之间频繁的数据调度,可将超大规模数据的Block副本预先定向备份到某一中心的集群节点中,避免计算过程中数据在中心之间的临时调度,进一步提高服务分析效率。
4 并行GlS算法
基于hadoop分布式架构,空间大数据被均匀分布到可以弹性扩展的各个计算节点上。在进行海量空间数据分析时,需要将分块数据调度到对应计算节点,参与空间分析。
传统的GIS算法主要采用串行计算方式,无法满足分块(Block)后数据的空间分析要求。本文提出通过并行计算的GIS算法,实现算法级的多节点并行计算和分析结果的合并返回。并行计算的GIS算法主要包括两个步骤,首先是任务的分配,任意参与计算的数据节点成为计算节点,利用节点的被分配的计算资源实现分布式的本地化计算;第二是计算结果的合并,如下图所示:

图5 并行计算GlS算法功能示意图
5 实验验证
实验环境说明:三台服务器模拟环境的测试结果,随着硬件资源的增加,速度可以更快。三台服务器集群规格:共十个节点,其中主节点16核64G内存,子节点8核32G内存。
测试结果:
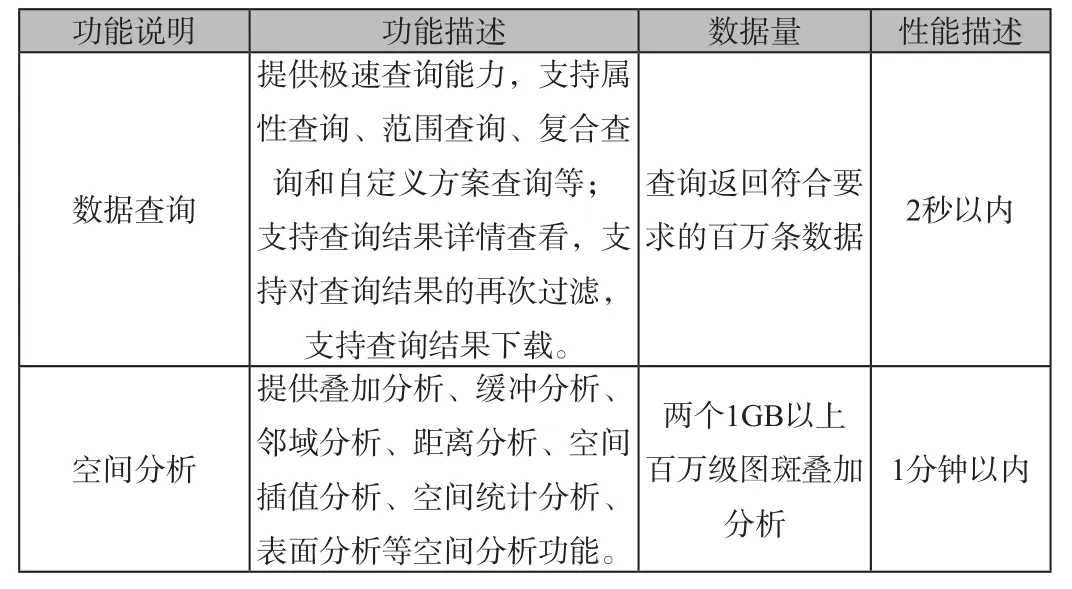
功能说明 功能描述 数据量 性能描述数据查询提供极速查询能力,支持属性查询、范围查询、复合查询和自定义方案查询等;支持查询结果详情查看,支持对查询结果的再次过滤,支持查询结果下载。查询返回符合要求的百万条数据 2秒以内空间分析提供叠加分析、缓冲分析、邻域分析、距离分析、空间插值分析、空间统计分析、表面分析等空间分析功能。两个1GB以上百万级图斑叠加分析1分钟以内
6 结束语
本文提出并验证了采用分布式存储、二级分布式空间索引、数据调度、并行GIS算法等策略可实现基于并行计算的多中心海量空间数据高效查询与分析。较单一的通过数据分布式存储、空间索引或数据调度等策略提高海量空间数据处理性能,本文全面考虑了现实情况中跨部门、跨网络的多中心的海量空间数据分析应用,从不同层次、不同角度提出了完整的解决方案,并通过实验进行了验证。实验表明,基于本文的思路,解决了存储、索引、调度、算法等多方面的问题,可以大幅度提升多中心海量空间数据的查询与分析性能。
