微博环境下新冠肺炎疫情事件对网民情绪的影响分析*
2021-03-09刘忠宝赵文娟
刘忠宝 秦 权 赵文娟
(1. 云计算与物联网技术福建省高等学校重点实验室(泉州信息工程学院) 泉州 362000;2.北京语言大学语言智能研究院 北京 100083;3.中北大学软件学院 太原 030051)
0 引 言
自2019年12月底新冠肺炎疫情爆发以来,以微博为代表的社交媒体在传播疫情信息、宣传防控措施等方面发挥了重要作用,并成为央视新闻、人民日报等官方媒体发布疫情信息的重要媒介。随着疫情的不断发展,相关微博新闻和评论的数量持续增长,众多网民对于疫情的情绪反应强烈,导致正常的生活受到明显影响。因此,笔者以新冠肺炎疫情相关的微博新闻及其评论作为研究对象,在建立面向疫情的疫情事件画像以及面向网民的情绪画像的基础上,深入分析疫情期间出现的重点事件对网民情绪的影响,为各级政府准确掌握网络舆论情况,科学高效地做好防控宣传和舆情引导工作提供有力支撑。
1 研究进展
疫情事件画像和网民情绪画像是本文研究的重点,前者主要用到事件抽取方法,后者主要用到文本情感分析方法。本节对上述方法的研究进展进行梳理。
1.1事件抽取方法目前,事件抽取的主要研究方法包括模式匹配、机器学习以及深度学习的方法三类。
基于模式匹配的方法一般通过手工构建各种模式匹配算法用于事件抽取。J. T.Kim等引入WordNet词典,利用短语结构和语义框架,构造了一个并行化的事件匹配模型PALKA[1],该模型一定程度上解决了语料规模较大时手动创建模式费时费力的问题。李章超[2]、许君宁[3]等通过构建模式匹配原则对非结构化文本中的事件抽取问题进行了研究并取得了较好的效果。基于模式匹配的方法在特定领域表现优异,但算法的可移植性差,需要大量的人工规则,且需要领域专家的指导。
机器学习无需领域知识且可以减少人工干预,已经成为事件抽取的主要研究方法。刘振等通过事件触发词与事件特征之间的约束规则,引入WordNet对触发词进行聚类,并引入条件随机场识别事件组成元素[4]。赵妍妍[5]、黄念娥[6]等分别引入最大熵分类器和CRF模型抽取事件。基于机器学习的方法在一定程度上减少了领域专家的依赖,但需要大规模的标准语料,否则在模型训练上容易出现数据稀疏问题,且现阶段的语料规模难以满足应用需求。
基于深度学习的方法将语料转化为特征向量,并通过不同的神经网络模型学习篇章级及跨篇章级的语义信息以提高事件抽取的性能。T.Nguyen等提出一种基于Skip-gram的卷积神经网络模型,该模型能够高效地提取非连续短语的特征,因而能够高效地完成事件抽取任务[7]。徐飞[8]、 Liu[9]等分别引入基于条件随机场的双向长短期记忆网络和注意力机制来学习文本的隐藏特征,进而提高事件抽取效率。
在微博事件抽取研究中,仇培元利用条件随机场对交通事件的微博进行语义标注,引入支持变量机计算事件要素之间的关联强度,该方法在微博交通事件抽取中召回率达到了90%[10]。周鹏[11]、唐晓波[12]分别利用关键词抽取算法和狄利克雷过程事件混合模型对微博事件进行抽取并取得了较好的效果。
1.2文本情感分析常用文本情感分析方法包括基于情感词典的方法、基于机器学习的方法以及基于深度学习的方法。
基于情感词典的方法主要是通过识别词典中的情感词对文本进行分类。Liu等在融入依存句法特征的基础上,利用K-means聚类算法构建情感词典对在线产品评论进行情感分析[13]。Yang[14]、Turney[15]、赵常煜[16]基于传统情感词典,分别引入隐狄利克雷分配(Latent Dirichlet Allocation, LDA)模型、点互信息(Pointwise Mutual Information, PMI)算法对情感词典扩展、文本情感分析等进行研究。基于情感词典的方法对特定领域情感分析表现优异,但该方法很少考虑文本的上下文信息,而且由于网络新词的不断出现,该方法无法及时更新情感词典。
基于机器学习的方法利用支持向量机(Support Vector Machine, SVM)、朴素贝叶斯(Naïve Bayes, NB)、最大熵(Maximum Entropy, ME)等机器学习算法进行文本情感分析。Pang等人工标记电影评论中出现的情感特征词,比较分析SVM、NB、ME等算法在电影评论中进行情感分析效果,实验结果表明SVM分类效果最佳[17]。Wikarsa[18]等利用NB算法对文本进行细粒度的情感分析。基于机器学习的方法基于文本的上下文关系,需要大量的人工标注语料,该方式耗时耗力,且存在标注不一致等问题。
目前,利用卷积神经网络(Convolutional Neural Networks, CNN)、循环神经网络(Recurrent Neural Network, RNN)以及长短记忆神网络(Long Short-Term Memory, LSTM)等深度学习模型已成为文本情感分析领域的热门研究方向。Poria等基于深度卷积神经网络提出一种从短文本中提取情感特征的方法,该方法利用文本、视觉和音频的组合特征来训练基于多核学习的分类器。与现有方法相比,该方法的情感识别准确率提升了14%[19]。吴鹏[20]、涂曼姝[21]等将卷积神经网络应用于文本情感分析,其正确率均达到93%以上。
在微博情感分析研究中,张海涛等利用微博数据,以复杂网络理论为基础,基于评论词语之间的共现关系,构建子事件网络,以动态地跟踪网民意见以及情绪波动[22]。张柳[23]、曾子明[24]等分别引入多尺度卷积神经网络和Bi-LSTM模型对微博评论文本进行情感分析。在疫情背景下微博情感分析研究中,安璐等基于微博用户转发关系构建疫情相关者的情感网络图谱,并根据舆情话题分析相关者的情感演化趋势[25]。周红磊等依据态势感知理论构建面向疫情的话题-情感演化模型,探寻疫情话题背后的网民情感变化情况[26]。
2 数据来源与研究方法
2.1数据来源爬取2019年12月01日到2020年4月30日之间与新冠肺炎疫情相关的微博新闻26 478条以及对应评论30万条,利用哈工大语言技术平台(Language Technology Platform,LTP)对语料进行分句、分词以及词性标注处理。通过去除新闻文本中含有的URL链接、标点符号、特殊字符以及少于10个字符的新闻文本,得到新闻语料集;通过去除评论中的英文、数字以及英文符号,得到评论语料集。本文借鉴国家金融与发展实验室将疫情演化分为爆发高峰期、全面蔓延期、控制恢复期等三个阶段[27],同时按照上述三个阶段分析疫情事件对网民情绪的影响,其中2019年12月01日至2020年1月27日为爆发高峰期、2020年1月27日至2020年3月1日为全面蔓延期、2020年3月1日至2020年4月30日为控制恢复期。
2.2研究方法
2.2.1 研究框架 图1给出了微博环境下疫情事件对网民情绪的研究框架。该框架包括疫情事件画像、网民情绪画像以及疫情事件对网民情绪的影响分析三部分。在疫情事件画像中,首先依据OpenKG发布的新冠肺炎热点事件图谱,将新闻语料集划分为捐资、防控、英雄和临床四类事件主题[28],并在此基础上人工筛选出包含四类事件主题的触发词,接着根据触发词对新闻语料集使用条件随机场(Conditional Random Fields, CRF)[29]模型进行疫情事件抽取,同时使用该模型识别疫情事件的组成元素。在网民情绪画像中,首先,根据大连理工大学情感词汇本体库DUTIR[30]对网民情绪进行分类;接着,根据疫情事件的触发词以及组成元素对评论语料集进行划分,得到疫情事件所对应的评论文本;然后,对评论文本进行情绪强度计算,并使用双向长短期记忆网络(Bidirectional Long Short Term Memory, Bi-LSTM)模型[31]对评论文本进行情绪分析;最后,得到不同疫情事件下网民的情绪画像。在疫情事件对网络情绪的影响分析中,使用基于自注意力机制的双向长短期记忆网络Att-BiLSTM模型对疫情事件与网民情绪进行关联分析,得到疫情事件影响下网民的情绪分布。
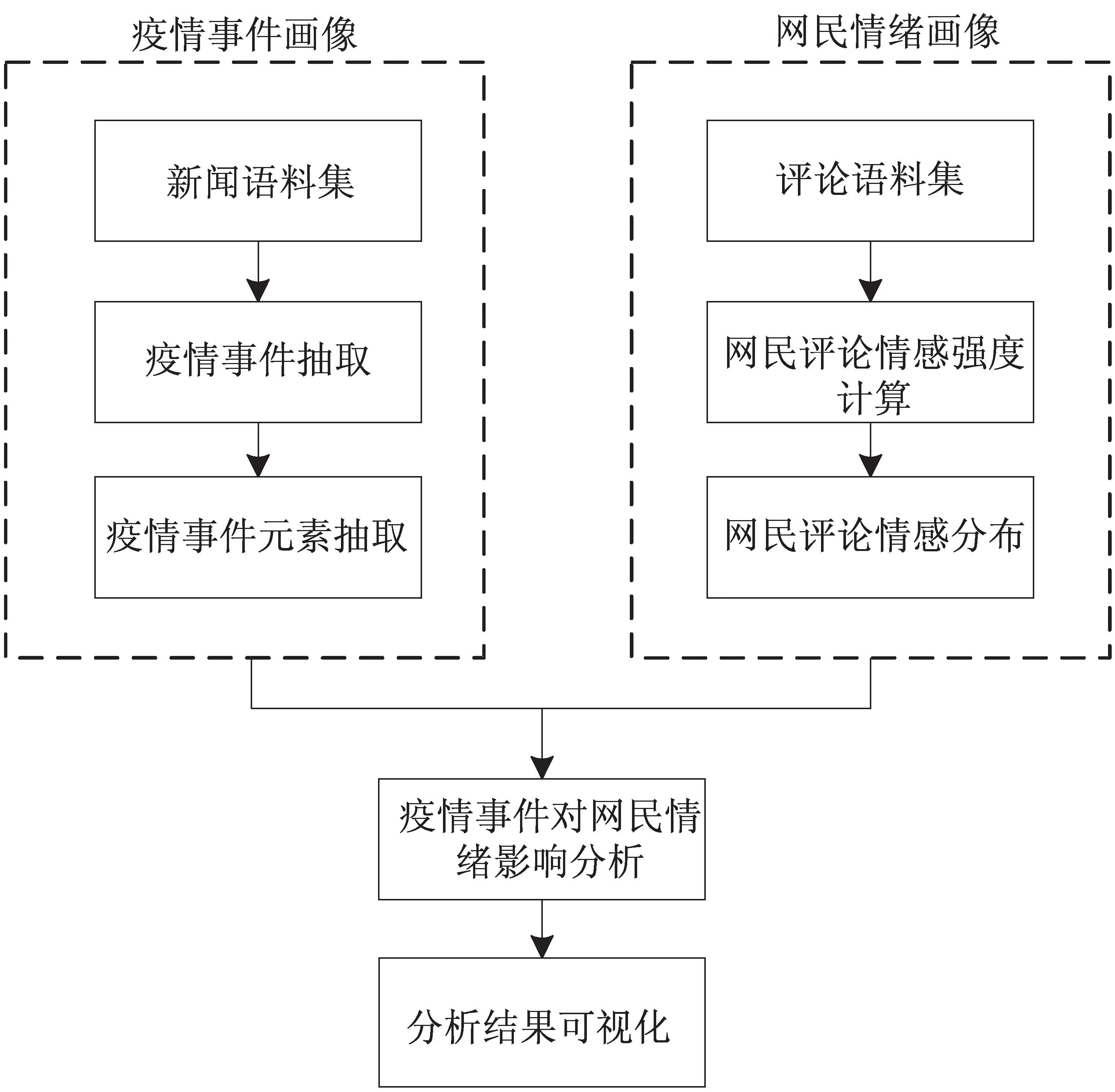
图1 研究框架
2.2.2 疫情事件画像 依据OpenKG发布的新冠肺炎热点事件图谱,将新闻语料集划分为包含捐资、防控、英雄和临床四类主题。捐资主题包括各地对疫区进行捐款捐物的新闻。本文结合上述各类主题下的新冠肺炎新闻的语句结构,人工筛选各类主题下疫情事件的触发词,利用CRF模型抽取疫情事件及其组成元素。以疫情事件为例,给出CRF模型的工作流程。首先,用预先定义好的标记规则对新闻语料集进行人工标注;然后,将标注好的语料输入模型;最后,学习疫情事件标签之间的约束规则,进而得到疫情事件抽取结果。
2.2.3 网民情绪画像 根据大连理工大学情感词汇本体库DUTIR,本文将网民情绪分为“乐观、美好、愤怒、悲哀、畏惧、厌恶、惊吓”七类,并引入情绪强度计算完成以上七类的网民评论情绪的标注。在引入DUTIR和修饰词词典的基础上,对与疫情相关的评论语料进行情绪强度计算,DUTIR将情感分为7大类,20小类,其中包含27 466个情感词,情感词的情绪强度值分为1、3、5、7、9五档,9表示情感强度最大,1表示情感强度最小,表1和表2分别列出了部分情感词和情感强度。情绪强度计算需要考虑否定词和程度副词共同出现时的情绪影响。情感词的情绪强度计算如式(1)所示。
Ei=(-1)οiαiρim
(1)
其中,Ei表示组合后的情绪强度,oi表示组合中否定词的个数,αi表示程度副词的情绪强度,ρi表示情感词的情绪强度,m表示不同组合的权重值。
网民情绪画像的基本流程是:首先,输入与疫情相关的评论语料集;接着,对输入语料进行向量化表示;然后,利用BiLSTM模型从正、反两个方向提取输入语料的语义特征;最后,得到网民对疫情事件的情绪分布。
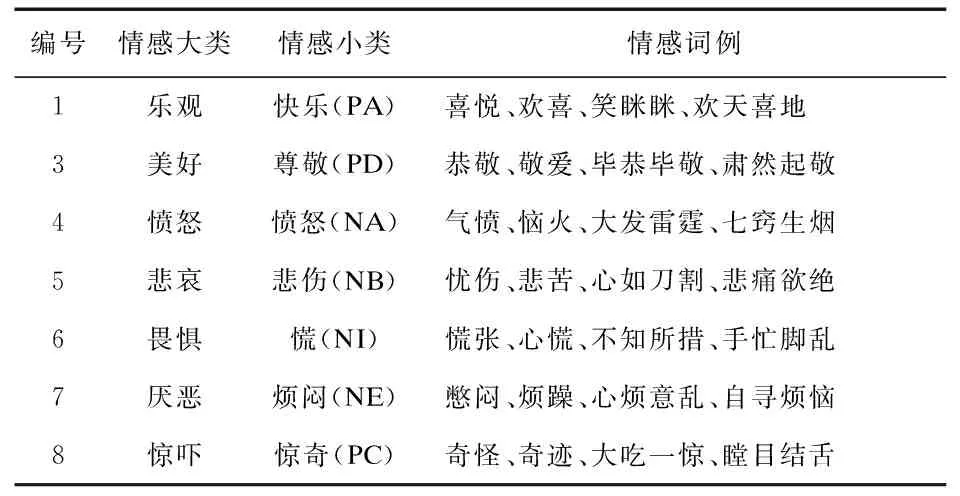
表1 部分情感词

表2 部分情感词的情感强度
2.2.4 影响分析 本文采用基于自注意力机制的双向长短期记忆网络Att-BiLSTM[31]模型进行疫情事件对网络情绪的影响分析。注意力机制通过对信息进行加权,得到信息的重要程度,以捕获更多的有用信息。Att-BiLSTM模型在BiLSTM模型的基础上增加了注意力机制层,该层对BiLSTM的输出进行加权计算。该过程首先将BiLSTM模型不同时刻的输出映射到(-1, 1)区间;接着,与权重参数相乘,经softmax函数映射到(0, 1)区间后得到注意力分布向量;最后,将该分布向量分别乘以BiLSTM模型不同时刻的输出即可得到分析结果。该模型融合了注意力机制和BiLSTM模型的优势,突出了对分析结果有利的语义特征,提升了模型的分析能力。图2给出了研究框架。首先,将疫情事件经Word2Vec向量化表示后输入模型;接着,利用Bi-LSTM模型挖掘疫情事件中的语义特征;然后,引入自注意力机制对语义特征赋予不同权重,以突出部分重要的语义特征;最后,经Softmax激活函数处理后,得到疫情事件影响下的网民情绪分布y。
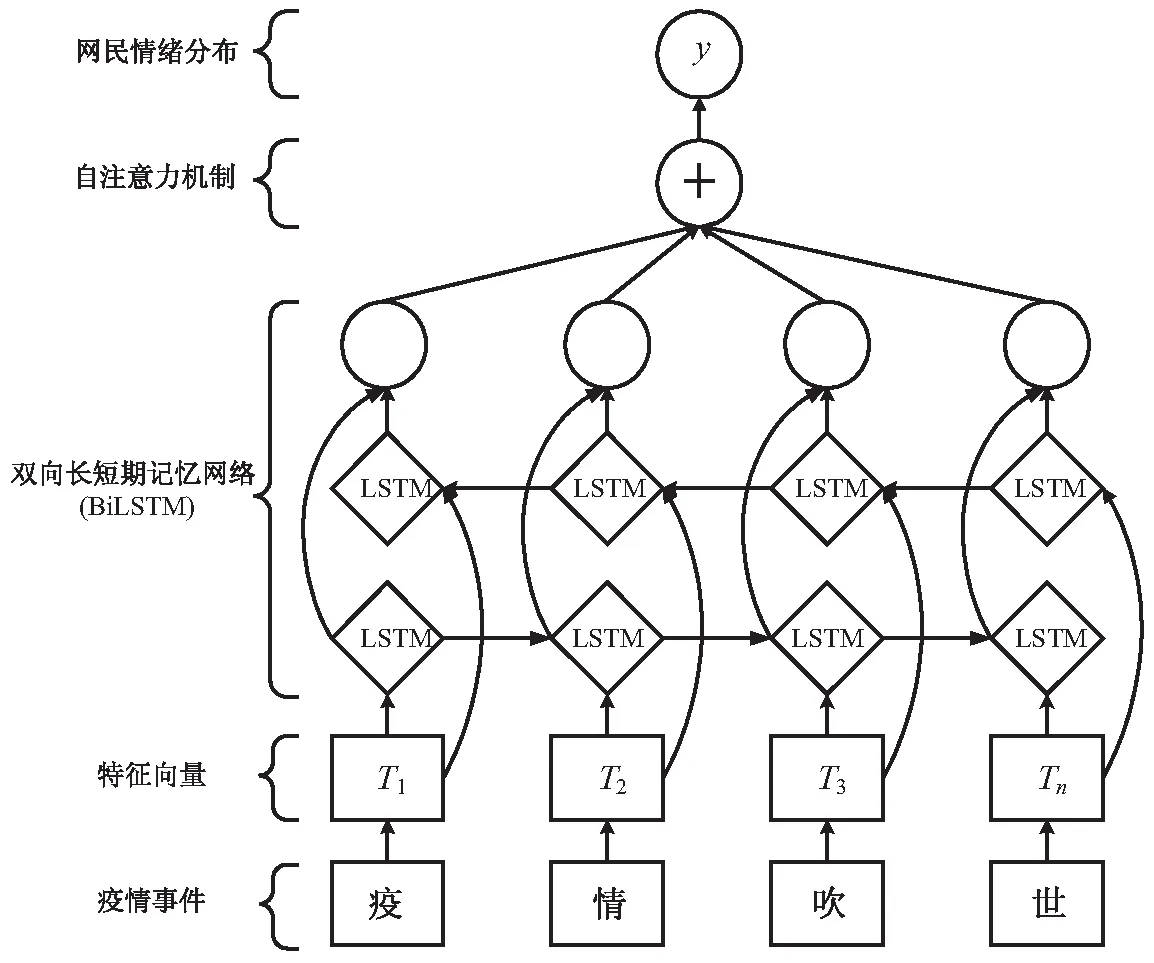
图2 关联分析模型图
3 实验分析
3.1新闻语料集标注疫情事件抽取包括触发词识别和事件元素抽取。根据新闻主题,给出如表3所示的疫情事件触发词表和表4所示的触发词标注集。

表3 疫情事件触发词表

表4 触发词标注集
在抽取疫情事件元素时,根据主题语料集的特点,将疫情事件元素分为时间、地点、人物。采用“BIESO”标注方式对主题语料集中的疫情事件进行事件元素标注。疫情事件元素标注集如表5所示。
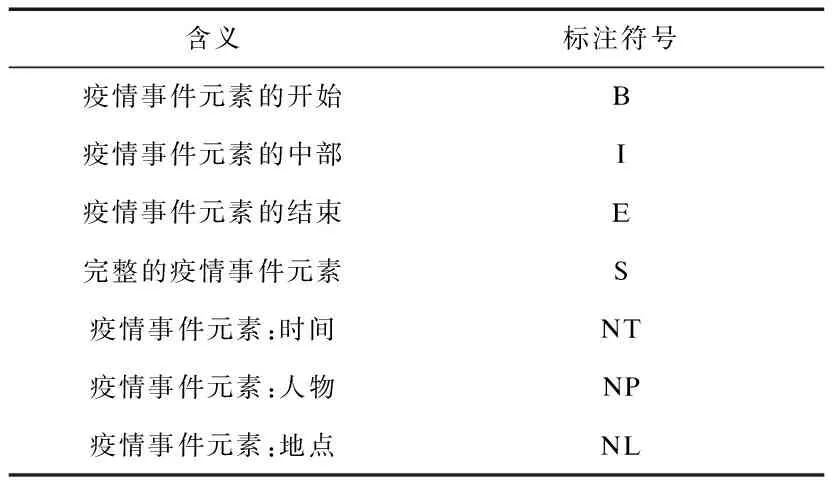
表5 疫情事件元素标注集
3.2评价指标利用准确率P(Precision)、召回率R(Recall)、F值(F-value)等评价指标对实验结果进行评价。准确率指正确识别疫情事件数与已识别疫情事件数的比值,或正确识别网民情绪数与已识别网民情绪数的比值,用于衡量所用方法的查准率。召回率指正确识别疫情事件数与所有正确识别疫情事件数的比值,或正确识别网民情绪数与所有正确识别网民情绪数的比值,用于衡量所用方法的查全率。F值综合了准确率和召回率两大评估指标,用于衡量所用方法的整体性能。上述指标的计算公式如下:
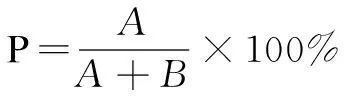
(2)
(3)
(4)
其中,A、B、C在不同画像中的含义不同。在疫情事件画像中,A、B、C分别表示正确识别、错误识别、无法识别的疫情事件数;在网民情绪画像中,A、B、C分别表示正确识别、错误识别、无法识别的网民情绪数;在影响分析中,A、B、C表示正确识别、错误识别、无法识别的疫情事件对网民情绪分布。
3.3实验参数设置目前比较流行的CRF模型处理工具有CRF++、Flexcrf、GRMM等。选用CRF++-0.58作为建模工具用以进行疫情事件抽取。Bi-LSTM模型用于网民情绪识别,随机选取30%的实验语料集作为参数设置语料集,将该语料集的70%用于模型训练,剩下的30%用于参数验证。利用网格搜索法来确定该模型的参数。batch_size在网格[4, 8, 16, 32, 64, 128]中搜索选取,epoch在网格[10, 20, 30, 40, 50]中搜索选取,dropout在网格[0.1, 0.3, 0.5, 0.7]中搜索选取,learning_rate在网格[0.0001, 0.001, 0.01]中搜索选取,num_nodes在网格[32, 64, 128, 256]中搜索选取,max_length在网格[10, 50, 100, 150, 200]中搜索选取,其中batch_size表示训练一次输入的评论数,epoch表示全部评论的训练次数,dropout表示解决神经网络过拟合问题的参数值,learning_rate表示学习率,num_nodes表示隐层神经单元个数,max_length表示时间步长。Bi-LSTM模型的参数设置如表6所示。

表6 Bi-LSTM参数设置
3.4实验设计
3.4.1 疫情事件画像实验结果 利用CRF模型抽取疫情事件及其组成元素,本文将标注后的新闻语料集按照8:2的比例分为训练集和测试集。实验结果如表7和表8所示。
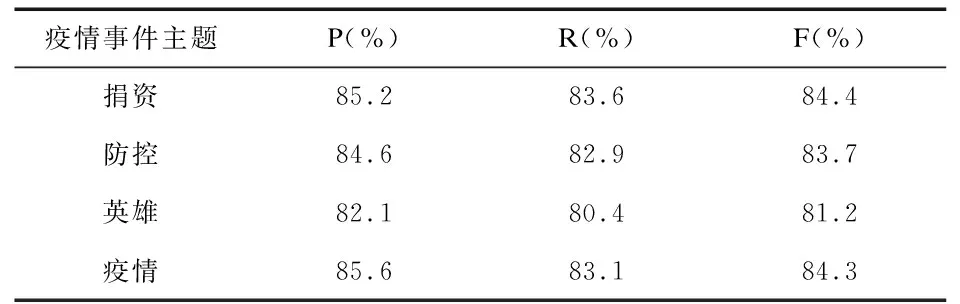
表7 不同主题下疫情事件抽取实验结果
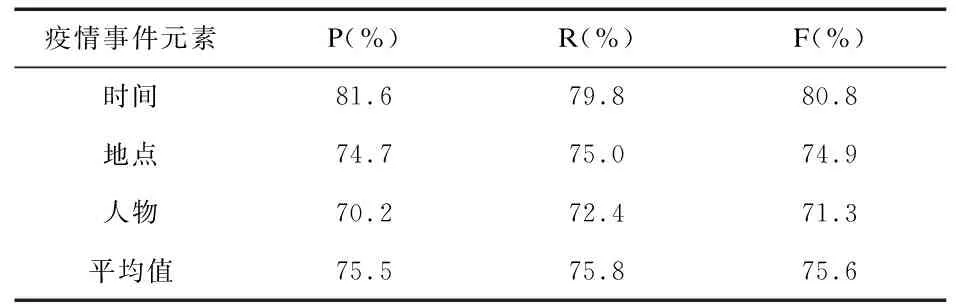
表8 疫情事件元素抽取实验结果
由表7可以看出,CRF模型在疫情事件抽取的召回率较低,其主要原因是中文不同的字词在上下文中表达的含义不同,部分“假的”事件触发词无法通过语义进行消除。四类主题疫情事件下的准确率、召回率、F值均达到80%以上,其中英雄事件由于语料限制,模型学习到的约束规则较少,模型准确率相比于其他三类疫情事件较低。由表8可以看出该模型在抽取时间、地点、人物等疫情事件元素时表现较为良好,准确率、召回率和F值都在70%以上,其中时间的F值较高,达到了80.8%,其原因是在疫情事件元素中,时间元素的句法结构单一,且人工标注准确率较高,因此,该模型的时间元素识别效果较优。由于疫情事件中含有的人物语料较少,模型识别效果较低。实验结果表明,CRF模型能够较好地完成疫情事件画像任务。
3.4.2 网民情绪画像实验结果 将评论语料集按照8:2的比例分为训练语料集和测试语料集,经过训练后得到的实验结果如表9所示。
由表9可以看出,捐资、防控、临床以及英雄四种主题中的网民评论中对“美好”的情绪识别中,F值均达到了90%以上,主要原因是在疫情防控过程中,政府及企业对疫情防控大力支持,网民评论整体多为积极。而该模型的召回率较低,主要原因是网民表达情绪的方式多样化,评论语料集中含有大量噪声,增加了模型识别情感特征的难度。BiLSTM模型在网民评论的情绪识别任务中,各主题下的情绪识别效果良好,这表明该模型能够充分挖掘评论语料集中网民的情绪分布,能够较好地完成网民情绪画像任务。
3.4.3 影响分析实验结果 为了验证本文所提Att-BiLSTM模型的有效性,本文设置了三组对比实验分别是:RNN、LSTM、BiLSTM。以上方法在四种主题疫情事件的实验结果如表10所示。

表9 评论语料集实验结果
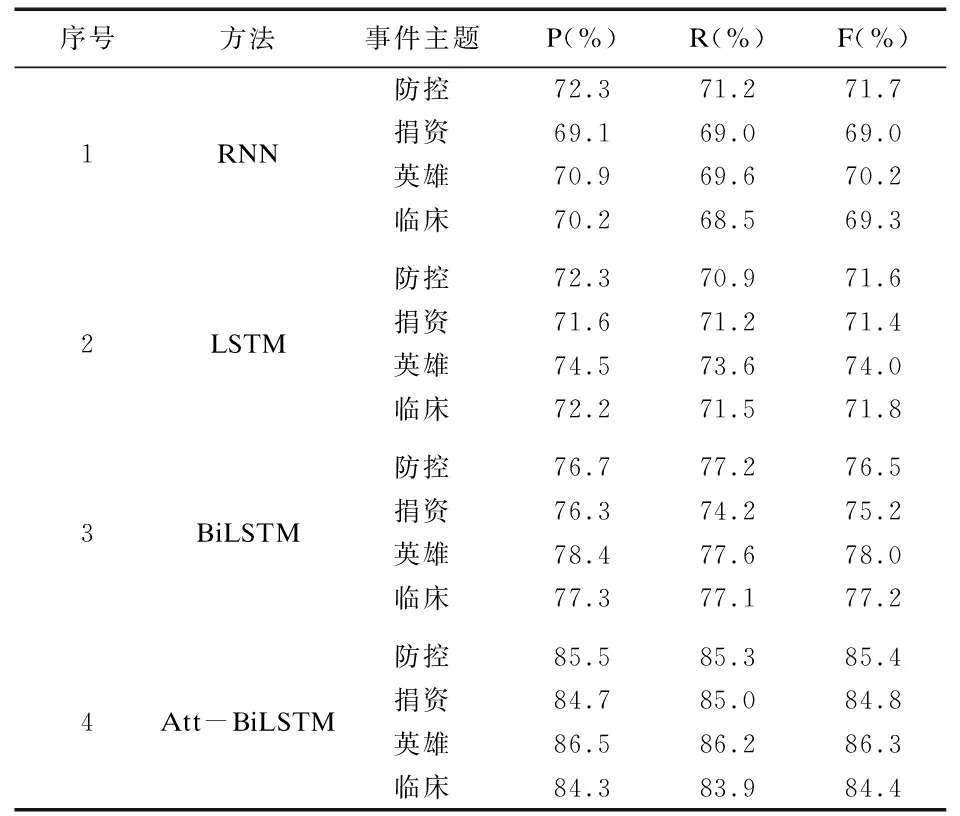
表10 影响分析实验结果
由表10可以看出,RNN、LSTM相较于BiLSTM,其F值最高仅达到了74%,主要原因是RNN与LSTM无法学习疫情事件之间的关联关系,因而在网民情绪的影响分析的实验中效果一般;BiLSTM可以联系疫情事件的上下文中对网民情绪影响的情感特征,因此实验效果较好,在“英雄”主题的事件的F值达到了78%。本文所提方法在疫情事件对网民情绪的影响分析中表现最好,其准确率、召回率、F值均达到了83%以上,其中对“英雄”主题事件的F值达到了86%,这是因为在“英雄”主题所包含的事件中,“去世”、“牺牲”等相较与其他词具有鲜明的情绪特征。根据疫情的不同发展阶段,围绕防控、捐资、英雄、临床四种主题,分析疫情事件对网民情绪的影响。实验结果如表11-表14所示。
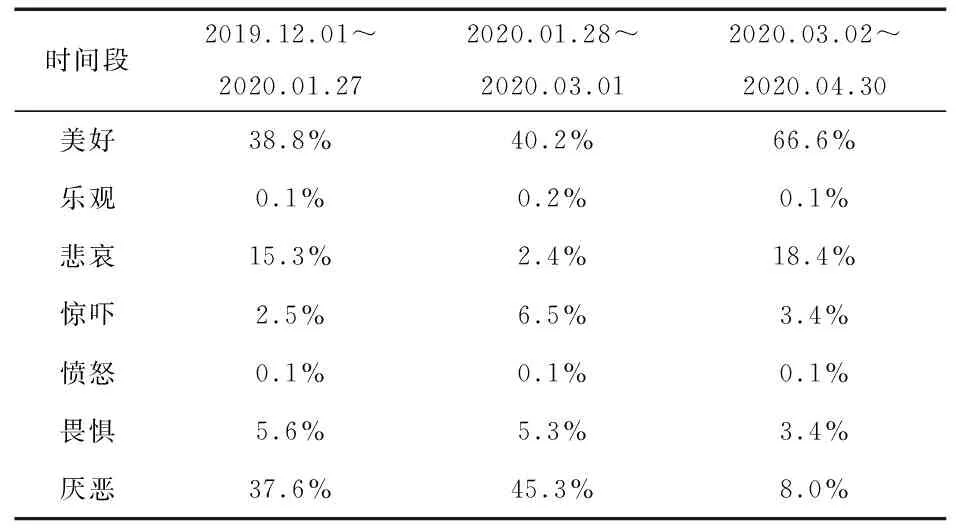
表11 英雄主题网民情绪分布表
由表11可以看出,在抗击新冠肺炎疫情过程中,不断涌现出如钟南山、李兰娟等医疗工作者日夜奋战在救援一线、公务人员在工作岗位上为抗击疫情劳累致死等事件,因此,网民“美好”的情绪占比较大。

表12 防控主题网民情绪分布表
由表12可以看出,疫情防控中的情绪变化较为复杂,其中“美好”的情绪占比较大,随着时间的推移,呈现先减后增的趋势,这种变化的缘由是多方面的,如对小区实行封闭管理,经过长时间的居家封禁,网民的正向情绪有所减少,但随着疫情趋于平稳,网民情绪变缓,心中充满希望。国家出台的一系列有效的防控措施,疫情大幅减缓,网民的恐惧也随之减少。受疫情影响,学生推迟开学、各种大型考试延迟等,在一定程度上也使得网民感到失落。
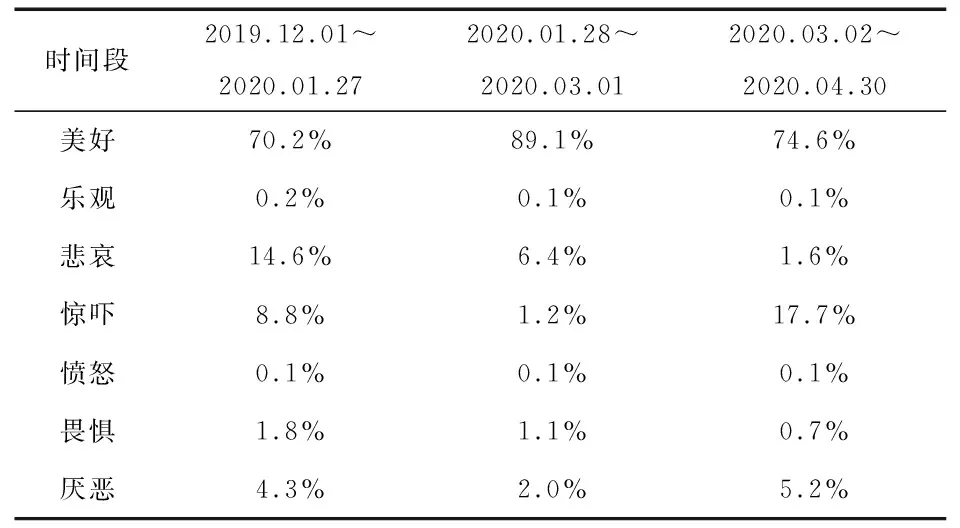
表13 临床主题网民情绪分布表
由表13可以看出,在12月1日至1月27日时间段,临床治疗还未见成效,使得网民感到恐惧、难过;随着临床研究取得进展,恐惧慢慢减少,同时,出于对医护人员自身安危的担忧,网民的“悲哀”的情绪仍占一定比重。随着临床的深入研究,治愈率升高,负向情绪尤其是“厌恶”的情绪占比减少。相比于其余两个时间段,在1月28日至3月1日,“惊吓”的情绪在大规模爆发阶段的占比最大,表明网民对疫情增长速度之快的担忧。但从总体上看,由于钟南山和李兰娟院士的研究团队在临床研究上取得显著的治疗效果,网民相信在政府部门领导帮助下能成功度过此次危机的情绪逐渐增加。
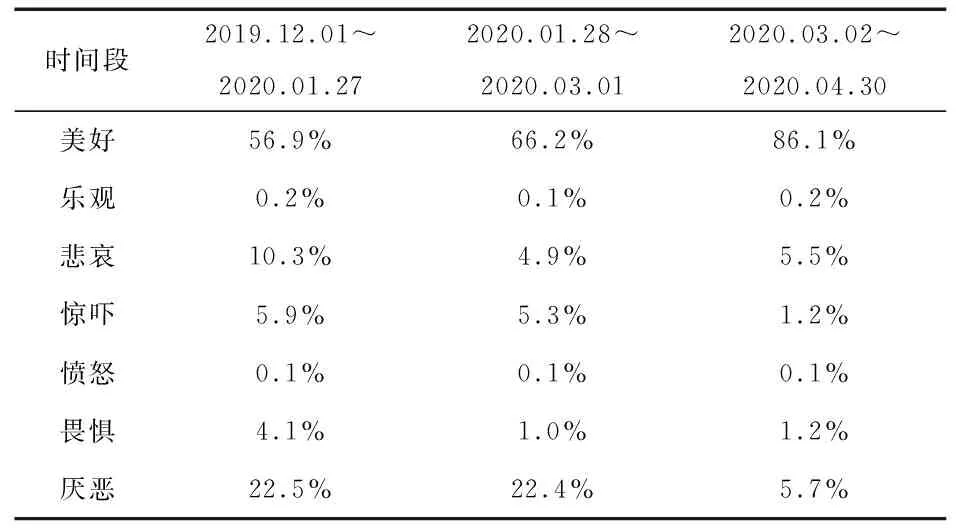
表14 捐资主题网民情绪分布表
由表14可以看出,自新冠肺炎疫情爆发以来,由于医疗物资供不应求,以及防控带来的资源调度不便,导致网民产生“悲哀”“恐惧”等负向情绪。为了解决疫情重灾区武汉市物资严重短缺的问题,全国人民团结一心,社会各界捐资捐物,正能量广泛传递,网民表现出的“美好”的情绪不断增加,“悲哀”和“恐惧”的情绪也随之减少。随着政府部门对物资的督查监管力度不断加大,物资分配不合理等情况大幅改善,网民的“厌恶”的情绪比例也随之降低。由于捐赠物资日益增多,同时,医疗物资加快生产,网民的担忧、恐惧等情绪得到了一定缓和。
对上述实验结果进行归纳可知:围绕防控、捐资、英雄、临床四种主题,网民在疫情演化的三个阶段“美好”情绪均占比最高,特别是在控制恢复期的英雄主题、爆发高峰期的防控主题、全面蔓延期的临床主题以及控制恢复期的捐资主题达到峰值,这表明我国在应对新冠疫情做法得力,得到广大网民的认可,与此同时,疫情信息的发布和监管也较为到位,避免虚假、不实信息对网民情绪的影响。作为一种强烈的心理刺激源,新冠肺炎疫情的爆发容易引起网民负向情绪。在疫情演化的三个阶段“厌恶”情绪占比较高,并在全面蔓延期的英雄主题、爆发高峰期的防控主题、控制恢复期的临床主题以及爆发高峰期的捐资主题达到峰值,这与疫情演化期间发生的一系列负面事件相关。在此情形下,网民心态要摆正,理性看待负面事件,就事论事,不发表太情绪化的言论,不转发未经证实的信息,通过合理合法的方式发泄负向情绪。在不同的主题中,网民负向情绪分布差异较大。英雄主题主要是“悲哀”情绪,并在控制恢复期达到峰值18.4%,这表明网民对抗疫英雄的崇敬与惋惜。网民应化悲痛为动力,在平时的工作和学习中践行英雄们坚持不懈、埋头苦干的精神,早日从“悲哀”情绪中走出来。防控主题主要是“悲哀”情绪,并在爆发高峰期达到峰值14.1%,这表明部分网民认为防控工作有待于进一步完善。网民应科学看待防疫工作的艰巨性和复杂性,给予防疫部门和广大医护工作者更多的理解和支持。临床主题主要是“惊吓”情绪,并在控制恢复期达到峰值17.7%,这表明网民出乎意料疫情发展速度之快。网民应不依赖自己的直觉,听从专业人士的建议,避免强迫性的自我清洁,尽量让生活正常化,不要让惊吓支配日常生活。捐资主题主要是“悲哀”情绪,并在爆发高峰期达到峰值10.3%,这体现了部分网民对疫情物资准备不足的忧虑。网民应充分认识到疫情的突发性给各级政府带来的挑战,也应树立战胜疫情的信心和决心。
4 总 结
本文对微博环境下疫情事件对网民情绪的影响进行了分析,试图为各级政府准确掌握网络舆论情况,科学高效地做好防控宣传和舆情引导工作提供有力支撑。首先从微博上爬取与新冠肺炎相关的新闻26 478条及评论30万条,经数据预处理,得到新闻语料集和评论语料集,利用CRF模型围绕捐资、防控、临床、英雄等四类主题抽取疫情事件及其组成元素。然后,在引入情感词典和修饰词词典的基础上,对情感强度进行计算,利用BiLSTM模型得到网民的情绪分布。最后,基于自注意力机制的BiLSTM模型得到疫情事件对网民情绪的影响程度。本研究亦存在一定不足,如本文用到的情感词典尚不完善,势必影响分析结果,在后续研究中着重探讨情感词典的完备性问题以及其他情感分析方法。
