基于整体序列建模的会话推荐模型
2021-03-09项欣光
闫 昭,项欣光
(南京理工大学 计算机科学与工程学院,江苏 南京 210094)
随着各互联网平台对用户体验的考虑,各类平台均提升匿名访问服务的体验。例如在亚马逊、淘宝、知乎等平台中,用户能够在不登录的情况下,访问平台中的信息。但是,当用户完成当次访问并关闭会话后,平台将失去该用户的身份。因而每次新增会话,均需要重新确立用户偏好。为了能够尽快地确立会话对应用户的喜好,为其提供优质的推荐服务,研究会话推荐任务显得尤其重要。
作为推荐系统的经典解决方案,协同过滤[1,2]利用协同信息推荐用户感兴趣的信息。项目K近邻法(Item K nearest neighbors,Item-KNN)[2-5]和会话K近邻法(Session K nearest neighbors,Session-KNN)[6]是会话推荐中基于记忆的协同过滤方法。Item-KNN忽略会话的历史序列,向用户推荐与最新交互项相似的项目。Session-KNN忽略项目间的时序相关性,利用与当前会话相似的会话中出现的项目对项目评分。矩阵分解法[7-9]基于模型的协同过滤方法,该方法忽略了会话中项目重要性的差异,使用项目隐特征的均值来代替会话表示。
近年来,随着深度学习的快速发展,神经网络方法[10-14]已广泛应用于于各个领域。考虑到会话历史为时序数据,常使用递归神经网络(Recurrent neural network,RNN)[15,16]来构建会话的表示。文献[17]忽略项目在会话中的全局信息,使用RNN获得会话表示。文献[18,19]引入用户的身份信息,使用分级RNN融合用户特征,但由于会话推荐面向匿名用户,因而具有一定的局限性。文献[20]使用了RNN与注意力机制结合的方法,考虑了项目与会话最新交互项目的关系,但忽略了项目所处会话中的位置信息。文献[6]和[21]在当前会话表示中融合相似会话表示,但由于性能的限制,只能融合部分相似会话。文献[22]采取数据增强的方法,没有在方法上进行改进。除了RNN,文献[23]在序列上直接使用卷积神经网络(Convolutional neural network,CNN),文献[24]在序列上直接使用注意力机制,这两种方法均忽略了项目所处序列的全局信息。图神经网络(Graph neural network,GNN)的出现[25-27]为研究工作提供了新的方向。文献[28]根据会话与项目之间的关系,建立图网络分析和生成会话表示,忽视了从整体序列建模分析项目的重要性。
RNN通过迭代的方式保留历史交互信息中的重要内容。随着会话过程的进行,历史序列不断增长,被舍弃的内容的重要性会随之变化,但无法再次找回。本文提出的基于整体序列建模的会话推荐模型(Session-based recommendation model based on overall sequence modeling,SRMOSM)计划采用全局的项目融合策略,同时处理历史序列中的全部项目,避免了RNN类模型中的取舍过程,能够更清晰地描述用户偏好。SRMOSM将选取项目在会话历史中所处的位置,以及项目与会话最新交互项目的关系,作为衡量项目重要性的指标。最后,SRMOSM在3个公开数据集上设计实验来验证其有效性。
1 基于整体序列建模的会话推荐算法
1.1 会话推荐问题描述
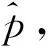

表1 符号
1.2 基于整体序列建模的会话推荐模型框架
图1展示了SRMOSM整体的工作过程。首先,SRMOSM从会话整体建模出发,联合分析项目在会话历史的位置和该项目与会话最新交互项目的关系,提取除最新交互项目外其他项的要素特征,包括该项目的编号、最新交互项目的编号、该项目所处会话中的倒序位置和会话长度。该4种要素通过要素隐特征矩阵生成项目权重。对于项目权重,最新交互项目的权重为手工指定。之后,所有的项目权重经过归一化层再次修正。最后,各项目的隐特征向量与其对应的权重通过加权和生成会话表示。SRMOSM使用交叉熵损失函数和Adam优化器优化模型的所有参数。
SRMOSM联合分析项目与最新交互项目的关系、该项目在会话历史的位置衡量项目的重要性,进而为会话与项目分别设计相应的特征向量。令s∈RD表示某一会话的特征向量,E∈RN×D表示全部N个项目对应的特征向量,那么该会话下一次交互概率为
(1)
式中:E为各项目隐特征向量构成的矩阵,而s对应的会话特征向量,由会话中所有历史交互项目加权构成。对于会话S,其特征向量s的表示为
(2)
式中:⊙表示向量按对应位相乘的结果,ex为项目x的隐特征向量,即E的第x行,wx为项目x在会话中的权重,取决于该项目对于会话的重要性,即
(3)
式中:cx∈RD表示项目x的重要性,除法为向量按位相除的结果。显然,项目重要性的计算方法决定了会话表示的优劣,也直接影响到了预测下一次交互项目的结果。
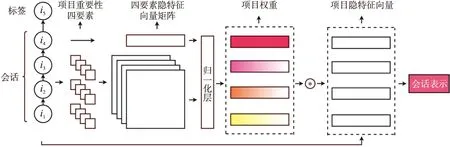
图1 SRMOSM工作框架图
1.3 会话中的项目重要性
对于基于整体序列建模的会话模型,会话中项目重要性的确定至关重要,本节分析如何计算项目的重要性。直观地说,用户下一次的访问与他最新的访问项目相关度最大,与他在会话中访问的其他项目也有一定的关联,而访问时间越近,关联度越大。可以认为,项目的重要性依赖于他在会话中所处的位置,以及他与最新访问项目之关的相关性。因此,本文分析了与这两项内容相关的各种情况,抽出了影响会话S中第i个项目重要性的4种要素,包含项目编号ai,项目ai在序列中的倒数位置L-i,会话中最新交互项目的编号aL,以及会话中项目数量L。这4种要素中,通过L-i与L,可以准确地描述项目前后项目的数量,即其在会话中所处的位置;通过ai与aL,可以得到描述这两个项目的特征向量,从而确定这两个项目之间的关系。
这里以4组会话为例说明4种要素对于整体序列建模的必要性。会话分别为S1=[1,2,3,4],S2=[1,4],S3=[1,3],S4=[2,1,4]。
1.3.1 项目编号
会话S1中包含4个项目。以其中的项目1与项目2为例,他们代表了用户不同的喜好。在计算他们各自对于会话重要性的时候,需要通过项目编号引入他们各自的特征,才能够体现他们各自不同的贡献。因此,需要引入ai,来获取项目特征,从而更好地描述其重要性。
1.3.2 会话中最新交互项目的编号
对于S2和S3,如果仅考虑ai来计算历史项目1的重要性,会得到相同的重要性。然而,这两个会话的最新交互项目不同,这也意味着这两个用户最后的兴趣点不同。所以项目1对这两个用户的重要性是不同的。引入会话中最新项目的编号即可解决上述问题。
1.3.3 项目在序列中的倒数位置
对于S1和S2,如果仅考虑ai和要素会话中aL来计算项目1的重要性,会发现该项目在不同会话中得到的重要性是相同的。然而,项目1所处不同会话的时序位置是不同的。如果某项目离最新交互项目时间越长,用户兴趣点转移的概率就越大,那么该项目的重要性就越弱。如果引入了项目在序列中的倒数位置,上述问题可以解决。
1.3.4 会话中项目数量
对于S2和S4,如果仅考虑ai、aL和ai在L-i来计算项目1的重要性,这时会发现在这两个会话中得到的重要性是相同的。然而这两个会话的长度不同的,这也意味着用户总的兴趣点分散程度不同,所以项目1对这两个用户的重要性是不同的。引入会话中项目数量可解决该问题。
本文针对影响项目重要性的4种要素,设计了4种隐特征向量矩阵,A∈RN×D,B∈RG×D,C∈RN×D,D∈RG×D,分别描述项目编号、项目在序列中的倒数位置、会话中最新交互项目的编号和会话中项目数量对项目重要性的贡献。其中A和C为项目编号,共有N组隐特征向量。而B和D与会话长度相关,共有G=max|S|组特征向量。项目的重要性可以由下列函数得到
φ(ai,L-i,aL,L)=σ(Aai+BL-i+CaL+DL+b)
(4)
式中:A、B、C和D的下标代表取该矩阵中的对应行,b为偏置向量。σ为激活函数。考虑到最新交互项目是重要性计算的一项指标,因而其重要性直接被设为常量向量{gσ}D,其中g为随激活函数变化的常量。总的来说,会话S中第i个项目的重要性ci的计算公式如下
(5)
1.4 基于整体序列建模的会话推荐模型训练
(6)


1.5 基于整体序列建模的会话推荐模型算法描述
基于整体序列建模的会话推荐模型的算法描述见表2。算法主要包含两个循环。外层循环首先选取一个会话序列,然后根据内层循环得到的项目重要性生成会话特征向量,最后生成会话下一次交互各项目的预测概率,从而执行Top-k推荐。内层循环根据项目的编号、最新交互项目的编号、该项目所处会话中的倒数位置和会话项目数量这四种要素,计算会话中每一项的项目重要性。在训练过程中,算法根据预测概率和式(6),执行反向传播,更新模型的所有参数。

表2 基于整体序列建模的会话推荐算法(前向传播)
2 实验与结果分析
2.1 实验环境和评价指标
2.1.1 数据集
本文在3个公开数据集上设计实验,包括Diginetica数据集、Yoochoose数据集和LastFM数据集。表3列出了数据集的详细统计结果。
Diginetica是2016年CIKM挑战赛的数据集。本文使用了与文献[28]相同的数据预处理方法。该方法仅使用交互文件,首先过滤掉长度为1的会话和交互次数小于5的项目,然后选择了最后7天的会话作为测试集,其余会话作为训练集。
LastFM是音乐推荐数据集。本文使用了与文献[21]相同的数据预处理方法。该方法过滤掉长度为1的会话和交互次数少于50的项目,然后随机选择269 847个会话作为训练集,5 771个会话作为测试集。
Yoochoose[31]是2015年RecSys挑战赛的数据集。本文使用了与文献[28]相同的数据预处理方法。该方法首先过滤掉会话长度为1的会话和交互次数少于5的项目,然后使用最后一天的会话作为测试集,倒数1/64会话时间切片作为训练集。

表3 数据集统计
2.1.2 对比模型
本节介绍文中使用的基准方法。流行度(POP)算法是所有推荐方法的参考基准,它只推荐训练集中最流行的项目。会话流行度(S-POP)算法推荐当前会话进行时最流行的项目,该项目随着会话的不同而变化。Item-KNN[2]算法根据项目之间的相似度进行推荐,相似度的大小用余弦值衡量。贝叶斯个性化排序(BPR-MF)[8]算法使用随机梯度下降方法优化成对目标函数。个性化马尔可夫链分解(FPMC)[7]算法使用了矩阵分解和马尔可夫链的混合方法。基于递归神经网络的会话推荐(GRU4REC)[17]算法是一种基于RNN的方法。基于神经注意力机制的会话推荐(NARM)[20]算法是一种基于RNN和注意力机制的方法。基于图神经网络的会话推荐(SR-GNN)[28]算法是一种基于门控的图神经网络和注意力机制的方法。基于协同会话带有并行内存模块的会话推荐(CSRM)[21]算法是一种RNN和内存网络的混合方法。
2.1.3 评价指标
本文使用两个评价指标来评估推荐效果,召回率(Recall)和平均倒数排名(Mean reciprocal rank,MRR)。Recall计算会话下一次点击的项目是否出现在推荐列表之中,如果会话的标签出现在推荐列表中,则此会话标记为1;反之为0。该指标不考虑标签出现在推荐列表中的位置。MRR用来评价标签所处推荐列表的位置。如果会话的标签未出现在推荐列表中,记为0;否则为标签所在位置的倒数。
2.1.4 基于整体序列建模的会话推荐模型的参数设置
本文使用Pytorch框架构建模型并进行训练。显卡是TeslaV100,具有32G显存。根据经验,本文设置隐特征维度D为150,学习率为0.001,参数的正则化项系数为0,训练每批次中样本数为1 024。
2.2 实验结果与分析
2.2.1 SRMOSM与对比模型的性能对比
展示了本文模型与各对比模型的实验结果。可以从中观察到现象如下现象,SRMOSM在Recall@20和MRR@20这两个评价指标上获得了最优效果。
在所有传统方法中,Item-KNN算法和FPMC算法取得了较好的效果,而POP算法的性能最差。POP算法仅仅考虑数据集中项目的流行程度,因而很难抓住不同会话的偏好差异。Item-KNN算法的实验结果证明了对于会话推荐,最新交互项目对预测用户的当前偏好有很大的影响。FPMC算法融合了马尔可夫链,因此FPMC算法能够抓住会话的局部偏好,这同时也证明了会话推荐需要分析序列的时序特性。整体上,神经网络方法相较于传统方法具有明显优势,均取得了良好的效果。GRU4REC算法仅使用RNN生成会话表示。RNN采用多次迭代的方式保留会话历史的重要信息,在每次迭代中选取局部最优解,这使它无法从全局角度考虑会话记录中各项目的重要性。NARM算法在RNN的基础上使用注意力机制融合了会话的局部序列,进而生成会话表示。会话的局部序列仍然通过RNN迭代生成,这使它同样无法从全局角度分析会话中项目的重要性。CSRM算法的会话表示生成过程与NARM算法相同,它在当前会话表示中融合了相似会话表示。因为相似会话与当前会话存在着协同信息,因而效果上有一定的提升。但本质上它没有解决从全局角度分析项目重要性的问题。SR-GNN算法使用门控图神经网路提取项目特征,并通过项目与最新交互项目的关系和注意力机制融合会话中的项目,最终生成会话表示。SR-GNN算法从全局角度分析各会话记录的重要性,但是一方面,它忽视了项目在会话历史中的位置信息对项目重要性的影响;另一方面,它的项目重要性为常量,这使它很难抓住项目特征分量对会话表示的贡献差异。
所以,基于整体序列建模,联合分析项目与最新交互项目的关系和该项目在会话历史的位置可以更好地抓住会话中各项目的重要性差异,另外使用向量级的重要性可以更好地区分项目特征分量的贡献差异,因而SRMOSM能够生成更为有效的会话表示。
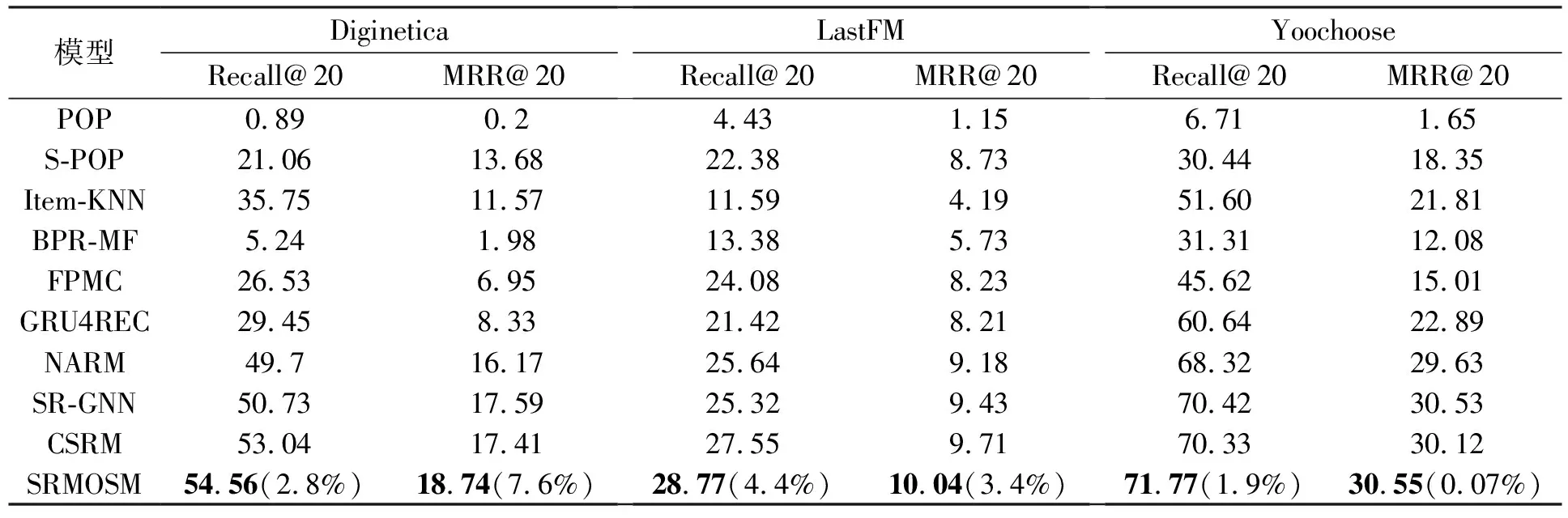
表4 SRMOSM与对比模型的性能对比
2.2.2 会话长度对推荐效果的影响
会话的最后几个项目对用户当前偏好的影响更大,因而,本节需要观察会话长度如何影响推荐效果。从图2可以看出,当会话长度小于10时,评价指标随着长度的增加而增加。该现象的原因是,当获得更多的用户点击信息后,SRMOSM可以更好地分析用户偏好,准确生成会话表示。当会话长度大于10时,评价指标趋于稳定。该现象的原因是,一方面,大部分会话的实际长度很短,增加会话长度对于这些短会话实际上并没有影响,因而评价指标趋于稳定;另一方面,这时候增加的点击项目大都是用户很长时间以前点击过的项目,这些项目的增加对于当前时刻用户的偏好影响并不大。
2.2.3 激活函数对基于整体序列建模的会话推荐模型影响
在计算项目重要性时,本文使用了不同的激活函数。本节分析不同激活函数对推荐效果的影响。对于激活函数Sigmoid,它的值域在0到1之间。考虑到最新交互项目的重要性,本文采用1作为gσ的值。对于激活函数ReLU6,它的值域在0到6之间,同理,本文采用6作为gσ的值。对于激活函数ReLU,它的值域是0到正无穷,因为没有上界,所以本文采用1作为gσ的值。从表5可以看出,不同激活函数对评价指标影响不大。SRMOSM可以较好适用于不同的激活函数,至少Sigmoid、ReLU和ReLU6均可以在SRMOSM中使用。激活函数的不同不会使网络出现梯度爆炸,进而发生梯度消失现象使网络失效。
2.2.4 基于整体序列建模的4种要素必要性
本文使用4种要素描述会话的序列特性,从而对会话进行整体序列建模。但是,是否每一个要素都有必要存在。本节进行了一系列实验验证每一个要素存在的必要性。从表6可以看出,随着每次消除要素,评价指标会相应的降低,但降低的幅度并不大。这与预期相似,因为本文使用4种要素描述会话的序列特性,每次消除都导致部分特性的丢失,导致对会话当前偏好的分析能力减弱。但是,此情况在不同的数据集上表现有些差异,这是因为不同的数据集可能对于会话的序列特性信息的需要不同。由于本文不可能对现在所有的会话任务数据进行实验,只能通过这几个有代表性的数据集大致评估方法的有效性。基于这种考虑,为了使SRMOSM具有更强的适应性,需要每一个要素去描述会话相应的序列特性。
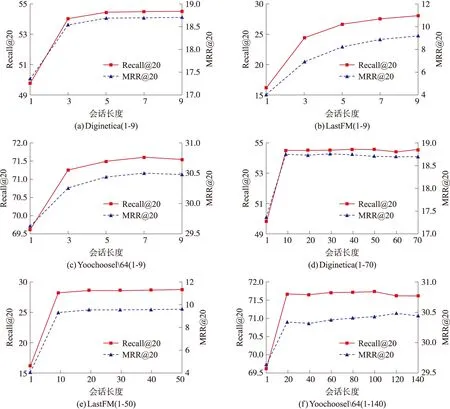
图2 不同会话长度效果对比
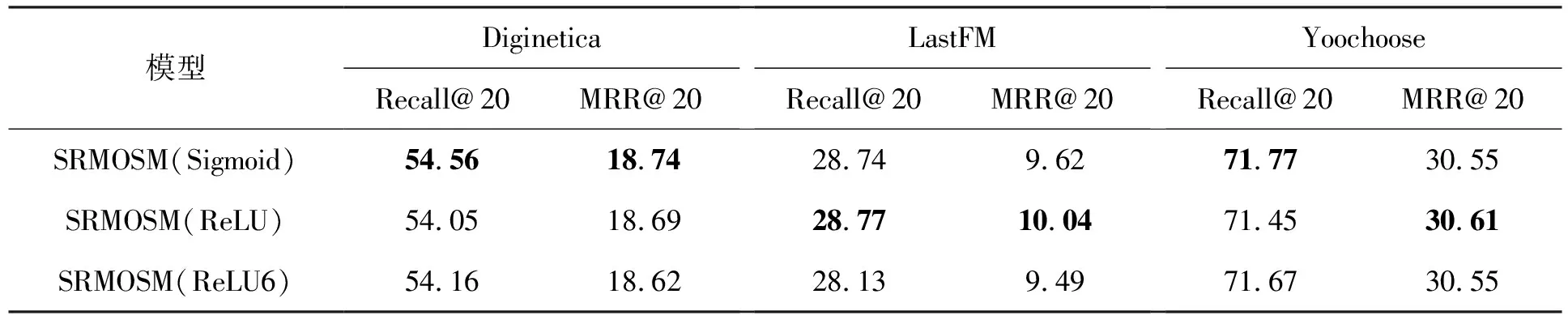
表5 激活函数性能对比

表6 要素必要性分析
2.2.5 项目隐特征维度分析
本节分析项目隐特征向量维度对推荐效果的影响。项目隐特征向量维度设置为50、100、150和200,其他参数设置为该数据集上的最优参数,并保持不变。从表7可以看出,随着项目隐特征向量维度的增加,评价指标会随之增加。但是,在Yoochoose数据集上,当项目隐特征向量维度从150提升到200时,评价指标略有下降,这说明了不同数据集对应的最优隐特征维度不同。在一定的范围内,增加维度对推荐效果有所提升,继续增加获得的收益较小,还可能导致过拟合,加大模型难度。综合考虑性能和计算代价之间的均衡,本文设置隐特征维度为150。
2.2.6 会话推荐算法的计算效率对比
本节对比了文中所有神经网络模型的计算效率。为了进行公平对比,本文使用训练一次数据集的平均时间和测试的时间作为评价指标,即:时间/训练集、时间/测试集,时间单位为s。从表8可以看出,NARM达到了最优的计算效率,SRMOSM计算效率略显逊色,但强于其他模型。除NARM和SRMOSM之外,其他模型的计算时间较长。GRU4REC使用项目的一位有效编码作为项目特征,一位有效编码的维度是数据集中项目的数量,其数值远远大于项目隐特征向量维度。SR-GNN使用门控图神经网络生成项目特征,相比于直接使用项目隐特征向量作为项目特征,增加了计算过程。CSRM在当前会话表示中融合了相似会话表示,同样增加了计算过程。综合考虑性能和效率,本文提出的方法取得了最优的效果。
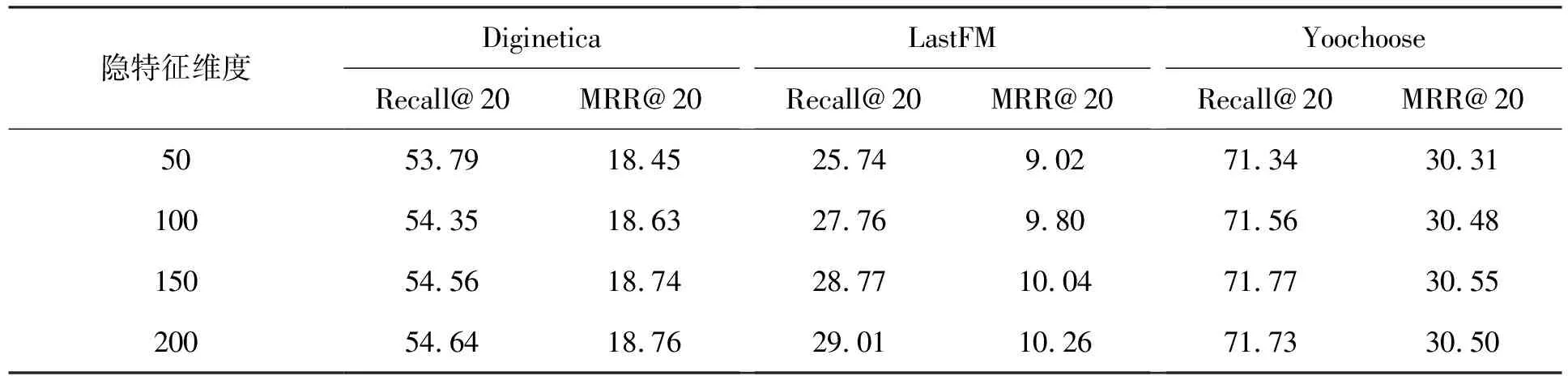
表7 项目隐特征维度分析

表8 算法计算效率比较结果
3 结论
本文提出一种基于整体序列建模的会话推荐模型SRMOSM。SRMOSM采用全局的项目融合策略综合考虑会话涉及的交互项目,通过考查该项目在会话历史中所处的位置、该项目与会话中最新交互项目的关系,衡量该项目在会话中的权重,计算出各项目对会话表示的重要性,生成更为有效的会话表示。在未来的工作中,可进一步考虑融合相似会话的特征。对比RNN-KNN和CSRM两项工作可知,融合邻居会话信息对于会话预测具有积极影响,能够更容易地找到存在于会话之间的协同信号,有利于分析用户当前偏好。
