基于条件随机场和词向量的能源政策领域新词发现
2021-03-09张一帆张军莲汪鸣泉黄永健顾倩荣
张一帆,张军莲,汪鸣泉,吕 正,黄永健,顾倩荣
(1.中国科学院上海高等研究院 碳数据与碳评估研究中心,上海 201210;2.中国科学院大学,北京 100049;3.中国科学院上海高等研究院 中科院低碳转化科学与工程重点试验室,上海 201210)
近几十年,中国的能源生产与消费快速增长,能源事业取得长足发展。同时,全球气候变化正成为全人类共同的挑战。为了不断完善我国的能源体制机制,一大批相关法律、法规、规划和条例等能源政策文件相继出台。这些文本文件往往精准且深刻地反映着我国能源的发展历史、现状以及未来趋势,因此,如何从大量政策文件中提取出准确有效的信息具有非常重要的现实意义,而要实现上述目的,首先需要对政策文本进行分词处理。现有的分词技术存在很多问题,尤其是在面向具体领域时,大量领域内专业新词的存在,使得分词模型的准确率受到严重影响,而这些专业词汇往往对于文本的结构化分析[1]、数据挖掘[2]以及信息检索[3]等应用具有重要影响。因此,领域新词的发现识别至关重要。
针对新词发现问题,主流的有基于规则、基于无监督统计、基于机器学习和深度学习等几类方法。其中,文献[4]基于汉语构词法,通过互斥性和构词规则对结果进行筛选和拼接,在网络语料上进行新词发现,取得了较好的效果。但规则库的构建非常繁琐复杂,同时不同领域的规则差异也较大,这意味着需要高昂的人工成本来适应不同的领域语料。文献[5]将逐点互信息(Pointwise mutual information,PMI)与邻接熵(Branch entropy,BE)相结合,在大规模语料上进行新词发现。这种基于无监督统计的方法有着较强的领域灵活性,但是数据稀疏的问题使得新词发现的准确率不高。文献[6]使用隐马尔科夫模型并结合领域词典的方法,来动态识别和扩充词典。文献[7]和文献[8]整理出多种区分词边界的统计特征,并通过条件随机场(Conditional random field,CRF)充分利用这些特征,在未标注语料集中进行新词的发现试验。相较于基于无监督统计的方法,机器学习的方法能够有效提高新词发现的表现。同时,随着深度学习和神经网络的研究,一些新的技术和模型被提出,如词向量(Word embedding)和长短记忆(Long short term memory,LSTM)神经网络,使得新词发现的性能有了进一步的提高。文献[9]首先提取语料中频繁出现的n-gram片段,随后利用词向量之间的得分来衡量候选词之间的联系,从综合语料中提取新词。文献[10]利用双向长短记忆(Bi-directional long short term memory,Bi-LSTM)神经网络模型,进行古汉语语料的新词发现,试验结果证明了其有效性。但是基于机器学习和深度学习的方法往往是有监督的,其对于训练集的规模和质量较为依赖,人工成本过高,而对于包括能源政策在内的众多细分领域来说,常常很难有一个较高质量的大规模标注训练集。
总的来说,现有新词发现方法存在的缺陷,使得对于能源政策文本的结构化分析效果不够理想。本文通过改进新词发现方法,提高中文分词的表现,使其更适用于能源政策文本。针对能源政策领域新词发现问题,本文提出了一种新的基于条件随机场CRF与词向量的识别方法,结合所提出的领域种子词典的概念,探索在无需手工标注训练集的较低人工成本的前提下,进行领域内的新词发现,并通过在真实能源政策文件上的试验结果证明了所提方法的有效性。
1 能源政策新词定义
中文新词发现,又称未登录词(Out of vocabulary)识别,其主要目的就是不断完善现有词典的词汇库,从而更好地进行后续的中文信息处理任务。传统的新词发现有两种主要的定义:文献[11]将新词发现定义为补充现有分词系统或者分词词典中尚不存在的词汇;文献[12]在此基础上,将具有新意义的已存在词汇也定义为新词。而本文定义的新词,除了包括以上两点之外,还有以下两点不同:
(1)本文聚焦于能源政策领域这一特定交叉领域,因而从数据集中发现的新词类型可以分为能源新词We、政策新词Wp以及能源政策新词Wep3类,即新词集合WN此3者的并集。
(2)新词经常被现有分词器错误地拆分为若干个字词,因此本文所指的领域新词,既有可能是一个词汇,也有可能是一个由多个字词组成的词组。在能源政策领域,由多个字词组成的新词往往能够包含更多的信息,更加准确地反映能源行业的政策变迁、政府举措和行业大势等。
表1列出了从能源政策文本中挑选出的4个例句。例句s1、s2、s3和s4分别来自我国的能源产业发展实施方案、电力发展规划以及十三五能源发展规划。

表1 能源政策新词示例
其中“可再生能源”为一种能源种类,属于能源新词We;“西电东送”反映的是我国西部大开发战略中的能源部分,属于能源政策新词Wep;“加快转型升级”为“加快”、“转型”、“升级”3个词语组成的词组,表述我国能源发展面临的形势以及政府施行的举措;“脱贫攻坚”是我国发展的一个重大目标,后两者均属于政策新词Wp。
综上所述,本文的新词发现可形式化定义为:针对能源政策领域D,通过新词发现技术F,识别在某一时刻t0之后收集的文本集合T∈D,获取新词集合WN={We,Wp,Wep}。
2 能源政策领域新词发现设计
2.1 总体框架
本文提出的能源政策领域新词发现方法由数据集自动扩充与标注、CRF模型训练和识别、领域种子词典建立与候选新词收集、词向量筛选新词等部分组成。新词发现的过程如图1所示。

图1 新词发现流程
首先,针对能源政策领域不存在大规模标注数据集的情况,利用无监督统计量对训练集进行领域语料的自动扩充与标注,以提高CRF模型在特定领域的性能;然后,通过分析能源政策文本的特点,提出并构建领域种子词典,并将其与CRF模型标注后的结果相结合,得到候选新词集合;最终,通过词向量之间的评分来对候选新词进行筛选,从而得到能源政策新词。
2.2 数据集扩充与标注
目前,在部分领域已经存在一些人工标注数据集,例如人民日报RFP(People’s Daily Corpus)数据集、MSRA(Microsoft Research Asia)数据集等。这些语料被公认符合黄金标准(Golden standard),经常被用作模型的训练集和测试集。但在实际应用中,针对特定领域的机器学习模型,通常需要添加该领域的训练集来获得性能上的提升。但人工标注数据集是一项耗时耗力的工作,因此本文使用无监督算法在现有标注数据集的基础上进行训练集的自动扩充。逐点关联时间信息(Pointwise association times information,PATI)[13]作为一种无监督统计量,用于衡量字符串内部联系的紧密程度。相较于共现频次(Co-occurrence frequency)和PMI等经典指标,PATI利用了更多来自文本的统计信息,因而能够挖掘出更多含有实际意义的合理n-gram片段。
对于一个字符总数为N的能源政策文本集C,存在一个长度固定为s的n-gram片段g,字符串a,b是n-gram片段g的任意左、右两部分,即g=concat(a,b),其对应的频率分别为fa、fb和fg,则g的PATI计算如下
PATIg=fg×MP×AT
(1)
MP和AT的定义分别如下
(2)
即给定一个n-gram片段g,总会存在一组特定的左右组合(am,bm)能够取得最小化,从而满足MP。
(3)
rate和AC的公式如下
(3)
(5)
式中:fam*和f*bm分别是以am作为左半部分的n-gram片段集合{am,*}和以bm作为右半部分的n-gram片段集合{*,bm}内的元素频率之和,sizeof代表集合内n-gram元素的个数。
在计算得到n-gram片段的PATI值后,按照大小进行降序排列,并在固定最大长度范围的基础上,抽出一定数量的排名靠前的2-gram,3-gram,…,n-gram片段,由于这些被抽取的n-gram片段均有着较高的PATI值,即意味着其中有许多是具有实际意义的能源政策字符片段。最后将这些片段作为新增数据添加到CRF的训练集中。虽然基于无监督的方法抽取出的n-gram片段会含有一些噪音,但是能在很大程度上丰富模型在特定领域的数据,同时由于后续还有进一步的识别和筛选,所以该方法能够在总体上提高CRF分词模型在特定领域的表现。
本文所采用的是6-tag标注方式,相较于常用的4-tag标注,6-tag包含了词中顺序等更多的信息,文献[14]证明其在CRF模型中有更好的效果。此外,除了词本身,还引入了词性作为分词特征,本文的词性标注参照RFP标注规则,包括基本词类标记、专有名词标记以及语言学标记等,总计40多个标记。
2.3 CRF模型训练和识别
CRF[15]是一种判别式的概率图模型,能够充分利用多种具有交叠性的内外部特征。相较于隐马尔科夫和最大熵模型等,CRF能够摆脱局部性的缺陷,具有表达长距离依赖的能力,并且能够将特征进行全局归一化,进而达到全局最优的目的,较好地解决标注偏置的问题。
CRF模型的训练基于标注语料集,通过充分利用上下文信息和内外部特征信息,学习得到模型的参数。文献[16]发现,与基于词相比,基于字符的CRF模型在表现上均有明显提升。因此,本文采用带有词性的字符序列作为模型的训练输入。在本文中,模型输入数据的观察序列为x={x1,x2,…,xn},其对应的状态序列为y={y1,y2,…,yn}。此时能源政策领域新词发现问题可定义为:在观察序列x已知的情况下,求解状态序列y的条件概率p(y|x)最大时的状态序列,p(y|x)计算方法如下所示
(6)
式中:f为特征函数,其取值只有两种,若序列符合该特征,则f输出为1;若不符合,则为0。θ为函数f的权重参数;yt为文本当前的输出状态,yt-1为上一步输出状态;xt为当前的输入序列;Z(x)为全局归一化因子,其计算方法为
(7)
在训练得到CRF分词模型之后,在独立的新词发现试验语料集上进行序列标注,通过解码算法输出一个最优的带有6-tag标注的字符序列组合。
2.4 领域种子词典与候选新词收集
虽然新词的种类和数量纷繁复杂,但是每个细分领域的新词都有其特点。通过对能源政策领域的文本进行分析,发现该领域的文本表述较为正式,绝大多数的新词在组成上都可以由能源词汇或政策词汇在句子中前后扩展得来,而这些词汇基本为常见的一字词和二字词,易于收集和整理。因此,本文提出“能源政策领域种子词典”的概念。首先使用TextRank[17]算法对能源政策文本进行关键词提取,将提取的一字词和二字词作为候选种子,随后对这些候选词汇是否属于能源或政策范围进行判断,并辅以人工补充和完善,最终形成能源政策领域种子词典。部分种子词汇及其对应新词示例如表2所示。

表2 种子词典及对应新词示例
在领域种子词典构建之后,将其与CRF模型序列标注的结果结合,结合的方式有两种:(1)若分词结果属于领域种子词典,则以此词汇为基础,对其所在的句子进行前向和后向扩展,扩展的长度为预设的窗口大小,扩展后形成的词汇组合即可加入到候选新词集合;(2)若分词结果的子字符串属于领域种子词典,则不进行扩展,直接将该词加入到候选新词集中。
2.5 词向量新词筛选
词向量通常有两种表示方式:离散表示(One-hot representation)和分布式表示(Distributed representation)。离散表示由于不能表达词语词之间的关系以及维度爆炸的缺陷,逐渐被分布式表示所取代。文献[18]通过训练连续词袋模型(Continuous bag-of-word model,CBOW)和Skip-gram模型,得到对文本字词的分布式表示,能够有效地捕捉词语丰富的语义含义。其中,CBOW通过输入固定窗口大小的词的前后上下文,来预测目标词语出现的概率,进而得到词向量。而Skip-gram的训练目标则是通过输入单个词,来预测该词的上下文。
由于2.4节生成的候选新词集合有着固定的窗口大小,因而词组中会存在一定的噪音词汇,需要进一步的筛选。候选新词集合中的一个词组如果能成为一个新词,那么这个词组中的词汇通常会出现在相似的上下文环境中,即这些词汇之间存在着较为紧密的语义关系。而词向量已经被证明能够捕捉隐藏于语料中的信息,因此通过计算词向量之间的评分,能够得到词汇之间的联系强弱判断。例如,对于能源政策候选新词集合中的一个词组{自主,创新,取得,重大},“自主”与“创新”对应的词向量之间的余弦相似度为0.54,而“创新”与“取得”之间为0.13,“取得”与“重大”之间为0.12。这表明“自主创新”相较于“自主创新取得”、“自主创新取得重大”等组合,更有可能成为一个合理的能源政策新词。对于候选新词集,基于词向量的候选新词筛选具体算法如下:
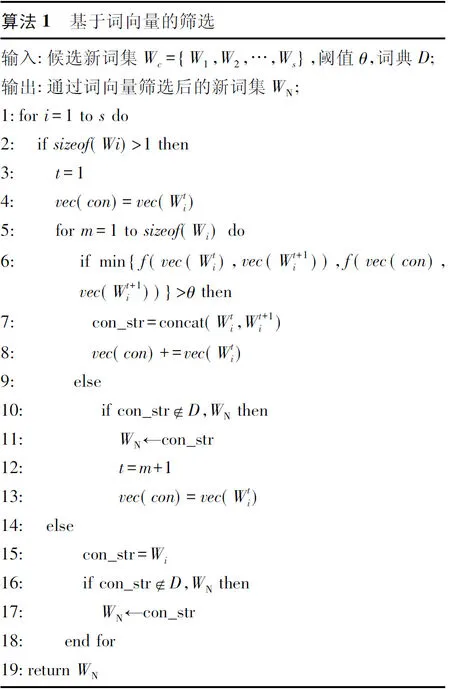
3 试验及分析
3.1 试验数据
本文的试验数据集可以分为两类,第一类是现在已有的人工标注数据集,本文选择使用1998年版人民日报RFP数据作为CRF训练的基础数据集,约180万字;第二类是由爬虫程序从某能源信息网站抓取得到,范围是21世纪以来全国各地的能源政策公开文件,包括政策规划、实施细则、通知批复、政策解读等。将第二类数据分为4部分,首先随机抽出部分政策文件作为模型验证集、新词发现测试集、分词效果测试集,以上3部分数据之间不存在重叠,然后将其余文件作为CRF训练集扩充来源、种子词典生成数据集以及词向量训练数据集。对于新词发现试验数据集进行细致的6-tag人工标注和检查,将标注结果与jieba词典进行比照,将人工标注新词作为试验的黄金标准。
3.2 试验设计
为了证明本文所提方法的有效性,本文进行了如下3个部分试验。
(1)验证通过无监督统计量扩充训练集,对CRF模型性能的提升。如2.2节所述,首先计算PATI统计量并排序,然后抽取排名靠前的n-gram片段作为新增CRF训练集。随后使用训练得到的CRF模型在验证集上进行分词,并将结果与第三方分词器jieba、Thulac作对比。为了试验不同规模的数据扩充产生的影响,本部分试验通过采取逐步扩大训练集的方式,进行了多次试验,当试验结果的F值浮动率不超过1%时,即认为模型趋于稳定。
(2)能源政策新词发现试验。在训练得到CRF模型之后,首先使用jieba分词工具对语料集进行分词,随后计算TextRank统计量,设定固定的阈值,并结合少量人工筛选和补充的方式,构建能源政策领域种子词典。然后根据种子词典收集候选新词,并使用word2vec进行词向量的训练。最后对候选新词中的词组进行词向量的余弦相似度评分筛选,从而得到能源政策新词。由于词向量模型与生成向量的维度以及评分的阈值是新词发现中两个较为重要的变量,该部分试验将首先在验证集上分析这两个因素对于新词发现的影响。随后在新词发现测试集上采用准确率Precision、召回率Recall以及F1值作为结果评价指标。
(3)新词发现结果对于分词性能的提升对比试验。由于本工作的背景是通过新词发现来改进对能源政策文本分词的表现,故分别将第二部分试验以及其他新词发现baselines方法的新词发现结果添加到分词工具中,并在分词效果测试集上进行评估和对比。
3.3 试验结果与分析
(1)CRF模型的训练。
由于PATI统计量可以用来筛选任意长度的n-gram片段,因此在本文试验中,首先需要设定n-gram的最大长度。通过结合文献[19]以及对能源政策文本的分析,将n-gram的最大长度设定为6。对于不同长度的n-gram片段,按照表3的数量比例,进行抽取。
随后,根据RFP词性标注规则,进行自动化标注,然后作为新增训练集加入到CRF模型基础训练集中,增加的方式为逐步递增。将训练得到的CRF模型在新词发现数据集进行分词试验,并将分词结果与第三方分词器jieba、Thulac作对比,使用分词的精确率、召回率和F1值3个指标来衡量模型分词的性能,具体结果如表4所示。

表3 n-gram片段抽取数量比例
可以看出,在未扩充的基础数据集上训练得到的CRF模型(CRF-0),在能源政策语料上的分词效果与第三方分词器相比,差距较大。主要原因是基础训练集主要是新闻语料,规模有限,在此基础上训练的模型无法很好地识别能源政策文本中的词汇,尤其是能源政策新词。第三方分词器由于其本身的训练语料的规模较大,领域覆盖面更广,尤其对于通用词汇的识别效果较好,因而有着相对较高的F1值。例如Thulac基础版的分词模型的训练集规模约为1 200万字,更复杂的联合标注模型的人工标注训练集约则为5 800万字。而将PATI值较高的n-gram片段作为训练集加入到CRF的基础训练集之后,模型的分词性能有了较明显的提升,这主要是由于新模型的领域适应性得到了增强,从而能够发现许多无法被现有分词系统识别出的能源政策领域新词。在新增训练集规模达到105 000后,模型(CRF-105000)F1值达到0.689,此后当训练集继续扩大,模型的性能基本趋于稳定,整体表现也与第三方分词器相差不大。而当新增数据集规模达到210 000时,模型(CRF-210000)的性能较之前有了一定的下降,这是由于新增数据中出现了较多没有实际意义的噪音片段,对于模型的训练造成了影响。同时,为了在CRF模型性能和统计量计算效率之间达到平衡,本文在后续试验中,将新增数据集规模固定为105 000。
(2)新词发现试验。
在训练得到CRF模型之后,需要生成能源政策领域种子词典。首先将种子词典生成数据集划分为20个部分,将种子词汇的最大长度固定为2,通过计算TextRank,从每部分数据中抽出50个评分靠前的词汇,通过去重操作后,得到270个不重复的关键词,随后通过人工对于这些词汇是否属于能源政策领域进行筛选,并补充部分政策常用术语和能源种类术语,最终形成能源政策领域的种子词典,总计253个单字词和二字词。然后将种子词典与CRF模型的识别结果按照2.4节所述的方式进行结合,设定窗口大小为5,以含有种子词典的词汇为窗口中心,收集候选新词集合。候选新词收集完成之后,使用word2vec模型在分词后的语料集上进行词向量训练。最后通过计算词汇之间的评分,来筛选候选新词。在设定相同阈值的情况下,词向量模型的选择以及词向量的维数在验证集上,对新词发现试验的影响如图2所示。
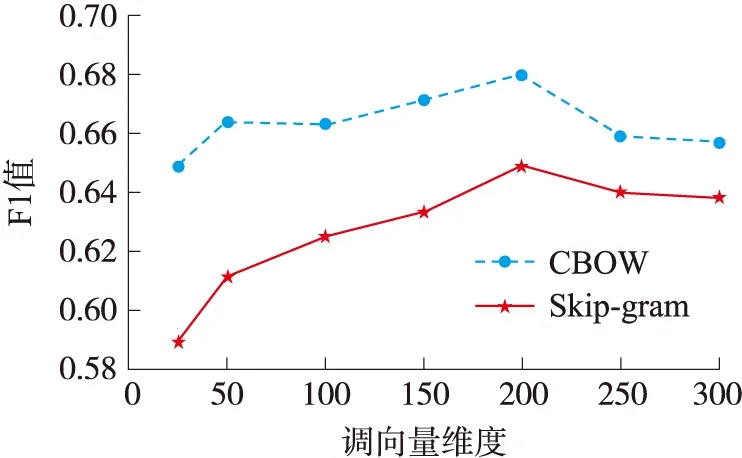
图2 不同词向量模型与维数时的新词识别性能
可以看出,在本试验中,基于CBOW模型的能源政策新词发现性能整体稍好于Skip-gram模型,并且在词向量维数从25增长到200再到300的变化过程中,新词发现试验的F1值均大致呈现出先上升,后保持平稳甚至下降的趋势。这主要是因为词向量的维度代表了词语的特征,前期词向量维数的增加,能够更丰富地表示词语的语义信息,从而更好地实现词语的区分,后续的词向量评分也能更好统计出具有紧密联系的词语集合。但词向量的维度如果过高,也会使得词语之间的关系被过分淡化。除此之外,由于本文试验中的词向量训练数据集属于能源政策这一细分领域,规模有限,过高的词向量维度也会导致过拟合。因此,在后续试验中,选择CBOW模型作为词向量训练模型,将词向量的维度固定为200维。
在确定了词向量模型及其维度之后,不同的相似度阈值对于能源政策新词发现的试验结果的影响如表5所示。
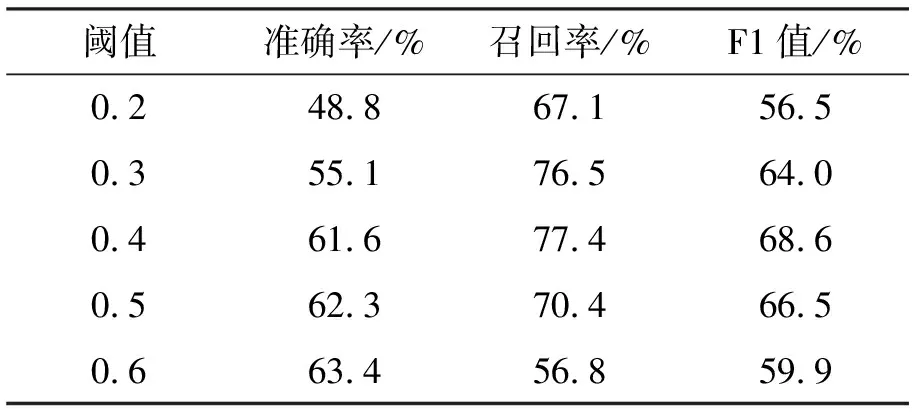
表5 新词发现结果
从表5可以看出,阈值的选择对于新词识别的效果有着一定的影响。随着阈值的增大,识别的准确率持续上升,上升速度由快到缓,而召回率却经历了先平稳上升,后又快速下降的过程,模型的整体效果在阈值θ=0.4时取得最优,达到0.686。
(3)分词对比试验。
为了进一步验证和对比所提方法的有效性,本文将文献[5]以及2.3节的方法作为baselines,将3种新词发现方法的结果加入到jieba、Thulac分词工具中,在分词效果测试集上进行评估,采用准确率、召回率和F1值作为评价指标,结果如表6所示。其中jieba、Thulac为未添加新词的原始分词工具,PMI+BE+jieba、PMI+BE+Thulac为文献[5]方法与jieba、Thulac相结合的分词模型,PATI+CRF+jieba、PATI+CRF+Thulac为2.3节方法与分词工具相结合的分词模型,CEPWD+jieba、CEPWD+Thulac为本文所提新词发现方法与分词工具相结合的分词模型。
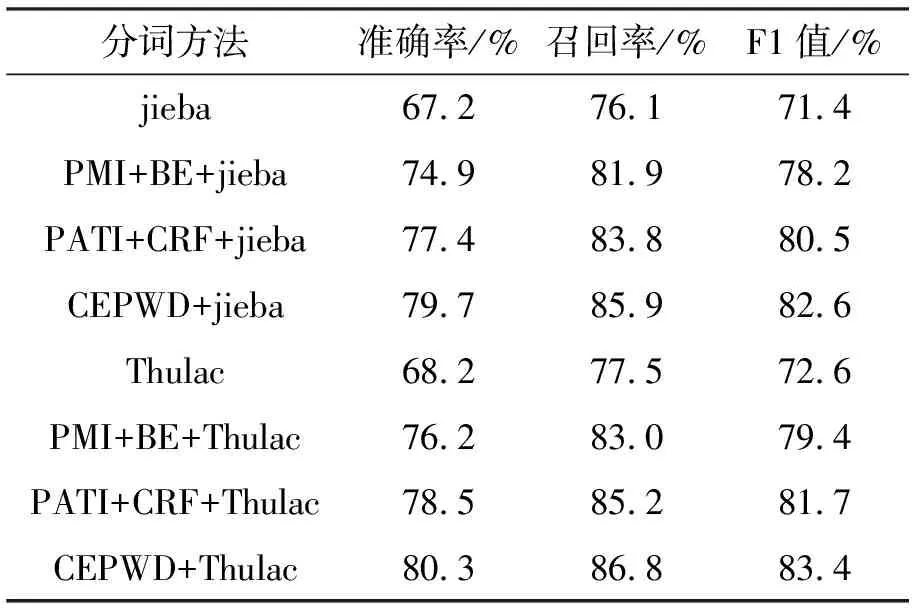
表6 各分词模型对比
从表中可以看出,本文所提的方法CEPWD在分词效果提升方面最为显著,相较于jieba和Thulac,F1值分别提高了11.2%和10.8%,这是由于该方法相对于PMI+BE这种完全依靠无监督统计的方法,能够在新词发现上能够取得更高的准确率。而相较于PATI+CRF来说,CEPWD增加了词向量筛选候选新词这一环节,因而能够取得更高的新词发现表现,进而提升能源政策文本的分词效果。
4 结束语
本文针对能源政策领域新词识别问题,提出一种基于条件随机场和词向量的发现方法,通过无监督算法PATI扩充CRF模型的训练集,避免了耗时耗力的人工标注步骤并改善了CRF模型在特定领域的表现,充分考虑了数据集的领域特性和语义特性,提出了领域种子词典的概念,在少量人工成本的情况下,利用词向量的评分筛选,实现了新词的有效识别。试验结果表明,该方法能够取得良好的新词识别效果,在模型整体性能与人工成本之间达到了有效平衡,相对于其他新词发现baselines方法,能够更加显著地提高中文分词在能源政策文本上的表现。同时,试验发现数据集扩充规模、词向量模型以及词向量评分阈值也会对新词识别的结果有一定影响。最近几年,基于注意力机制的深度学习模型,例如GPT-2、BERT等,在自然语言处理的多项任务上取得了相当好的效果。将预训练模型和迁移学习技术结合起来,通过主动学习和不完全学习等弱监督的方式,充分利用本研究的新词发现结果,在尽可能低的人工成本下,提高模型在专业领域的新词发现性能,将会是下一步需要解决的问题。
