基于深度学习的科技论文引用关系分类模型
2021-03-08路永和刘佳鑫袁美璐郑梦慧
路永和 刘佳鑫 袁美璐 郑梦慧


摘 要:[目的/意义]提出HABCM模型,方便科研人员进行论文构思与写作。[方法/过程]首先,基于段落层级结构,分别在词级和句级使用双向GRU对写作需求和参考文献进行语义建模;其次,使用Attention对语义贡献度大的词向量和句向量加权;最后,用先拼接后提取特征的方法计算文本对的相似度,并输出引用关系类别。[结果/结论]该算法在ACL ARC数据集上获得了74.96%的F1值和78.38%的准确率,高于4个对比实验中的模型;证明了“摘要和引言”结构对参考文献主题内容最具代表性。
关键词:深度学习;科技论文;引用分类;语义匹配
DOI:10.3969/j.issn.1008-0821.2021.03.003
〔中图分类号〕TP391;TP183 〔文献标识码〕A 〔文章编号〕1008-0821(2021)03-0029-09
Citation Relationship Classification Model of
Scientific Papers Based on Deep Learning
Lu Yonghe Liu Jiaxin Yuan Meilu Zheng Menghui
(School of Information Management,Sun Yat-Sen University,Guangzhou 510006,China)
Abstract:[Purpose/Significance]The HABCM model was proposed to facilitate scientific researchers in paper conception and writing.[Method/Process]First,based on the paragraph hierarchy,bidirectional GRU was used at the word level and sentence level respectively to model the semantics of writing requirements and references.Secondly,the paper used Attention to weight the word vectors and sentence vectors that contribute a lot to semantics.Finally,the similarity of text pairs was calculated by concatenating firstly and then extracting features,and reference relationship categories were output.[Result/Conclusion]The algorithm achieved 74.96% F1-score and 78.38% accuracy rate on ACL ARC data set,higher than the models in four comparison experiments.It is proved that the structure of“abstract and introduction”is the most representative for the subject content of the reference.
Key words:deep learning;scientific papers;citation classification;semantic matching
引用擬写论文主题相关的科研成果是科研工作者在学术写作中的重要环节。学者进行科技论文写作时,往往需要大量的参考文献来阐述目前的研究背景、研究现状,并佐证所研究问题的前瞻性和创新性。目前,学术文献数量指数增长,每天都有数以万计的学术成果被发表,如何迅速地在海量学术文献中挖掘出合适的科研文献,从而进行高质量的文献综述和学术写作是每一个科研人员面临的问题。
Google使用Word2vec对谷歌新闻数据集(约1 000亿个单词)进行了预训练,并发布了预训练结果集[18]。该预训练词向量集合共含有300万个单词及短语,每个单词或短语用300维的词向量表示。本文将采用Google预训练的词向量获取写作需求与参考文献文本段中的词向量。
2)使用双向GRU获得词的上下文语义信息
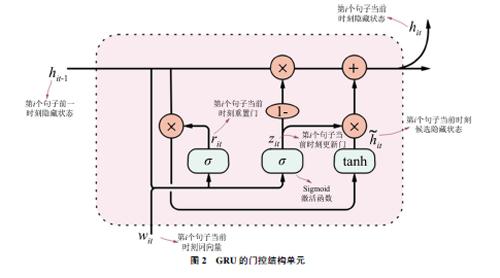
GRU[11]是RNN(循环神经网络)的一个变体,GRU模型在传统RNN的细胞核中加入了门控结构以跟踪输入序列的状态,其门控结构单元如图2所示:每一个门控结构均包括重置门、更新门、候选隐藏状态和隐藏状态。相较于RNN、LSTM模型,其结构特点及计算方式决定了它在进行梯度下降优化时能规避梯度爆炸和梯度消失问题,同时又能保证算法的运行效率,故而更适用于科技论文文本这种较长文本的建模。
图2 GRU的门控结构单元
门控结构单元在t时刻的输入包括:第i个句子中t时刻对应的词在前一个时刻的隐藏状态hi(t-1)和当前时刻的输入wit。更新门zit控制前一时刻有多少信息被写入到当前时刻输出的隐藏状态hit上,其值越小,前一时刻的信息被写入越少,越能捕捉时间序列里短期的依赖关系。重置门rit用于控制当前状态遗忘前一时刻的状态信息的程度,其值越大表示对前一刻的状态信息遗忘越少,越能捕捉时间序列里长期的依赖关系。假设隐藏单元个数为h,重置门和更新门的计算如式(1)、(2)所示:
其中,wit为写作需求中第i个句子中的t时刻对应词的词向量,Wwz、Whz、Wwr、Whr为权重参数,bz、br为偏差参数,σ()为Sigmoid激活函数。
首先,将t时刻的重置门rit与t-1时刻的隐藏状态hi(t-1)做元素乘,如果重置门中元素值接近0,即丢弃t-1时刻的隐藏状态;如果接近1,那么保留t-1时刻的隐藏状态。然后,将元素乘结果与t时刻的输入连接,再通过激活函数tanh的全连接层计算出候选隐藏状态。所有元素值域为[-1,1]。最后,由zt决定t时刻门控结构的最终隐层输出ht,如式(4)所示:
ht=(1-zt)⊙ht-1+zt⊙t, t∈[1,m](4)
在上述循环神经网络中,状态的传输是单向的,然而在句子的语义理解中,当前单词的语义不仅需要根据上文来判断,也依赖下文的内容,这时就需要双向GRU来建模。如图3所示,双向GRU由两个GRU上下叠加而成,在每一个时刻t,输入会被同时提供给这两个相反方向的GRU,而输出则是由这两个单向GRU共同决定。GRU中,每个隐层会输出一个隐藏状态向量,本文需要获取的上下文信息是每个词所在隐层的隐藏状态向量,而不是GRU训练出的最后的向量。
在本文中,t时刻第wit个词考虑了前wi(t-1)个词从左向右的GRU隐层信息上文信息,以及第wit個词从右向左的GRU隐层信息下文信息,如式(5)~(7)所示:
其中,it表示第一个句子的第t个单词wit包含上文信息的隐藏状态向量,it表示包含下文信息的隐藏状态向量,hit为最终包含单词上下文表示的隐藏状态向量。
3)基于Attention机制构建句向量
在句子中,每个单词对句子语义表达的贡献大小不同,因此需要通过Attention机制找出对句子语义贡献较大的词进行加权,从而获得准确的句向量表示。具体来说,首先,将单词的隐藏状态向量hit输入到单层MLP中,提取出hit的某个特征,并用向量表示为uit。然后,将uit和模型生成的随机句向量uw通过Softmax函数计算得到标准化的句子向量的贡献权重ait[19]。最后,将ait与隐藏状态向量hit相乘并累加,得到带有权重的句向量si,如式(8)~(10)所示:
其中,随机句向量uw随机初始化并在训练过程中进行学习。
4)使用双向GRU获得句子的上下句语义信息
与对词向量的双向GRU建模过程类似,对于句子集合中的第i个句子,分别从前往后、从后往前地使用GRU获取其前后句所在隐层的隐藏状态向量i和i,如式(11)和(12)所示。然后将两个隐藏状态向量串联得到第i个句子含有上下文语义表示的隐藏状态向量hi,如式(13)所示:
5)基于Attention机制构建段向量
对段向量的建模与句向量建模阶段加入的Attention机制类似。首先,将句的隐藏状态向量hi输入到单层MLP中,提取出hi的一个特征,并用向量表示为ui,如式(14)所示。然后,将ui和随机段向量us通过Softmax函数计算得到标准化的段向量的贡献权重ai,如式(15)所示。最后,将ai与隐藏状态向量hi相乘并累加,得到带有权重的段向量d,如式(16)所示:
2.2 文本对的匹配建模
经过以上建模,引用关系的匹配问题被转化为两个语义向量的匹配问题,如图4所示。具体来说,首先将写作需求的引文上下文语义的段向量与参考文献的结构段的语义向量拼接,接着使用MLP全连接网络获得拼接向量的语义特征,最后通过使用Softmax分类函数输出文本对具有引用关系的概率。
具体步骤如下:
1)拼接语义向量,构建全连接层获得拼接向量的语义特征
将m维的写作需求向量dm与n维的参考文献向量dn拼接,构成维度为m+n的语义向量dm+n。为了逐步压缩dm+n的特征信息,同时避免在相邻层之间突然损失过多语义信息,需要使用MLP将dm+n输入到包含若干隐藏层的人工神经网络进行特征编码。假如人工神经网络共有k个隐藏层,则第k层的输出如式(17)所示:
其中,Ck为第k层的输出向量;wk为第k个隐藏层的权重向量;bk为第k个隐藏层的偏置向量;激活函数为tanh()。
2)使用Softmax函数确定文本对的引用关系
得到第k层的输出后,最后还需要再进入一个Softmax分类层。由于本研究涉及的是二分类问题,因此Softmax层只有两个神经元,它的目标是输出写作需求的引文上下文与参考文献结构文本对是否具有引用关系的概率值。如式(18)和(19)所示:
h=0或1:当h=0时,不存在引用关系;当h=1时,存在引用关系。
其中,zh是具有引用关系1和不具有引用关系0的两个分类结果节点的输出值;Ph则是根据结果节点的输出计算出的文本对是否存在引用关系对应的归一化概率值;wh、bh分别为最后一层的权重向量与偏置向量;最后取最大的概率值对应的标签作为分类结果。
3 实验和结论分析
3.1 数据集及数据预处理
本文采用ACL ARC(Anthology Reference Corpus)[20-21]和AAN(ACL Anthology Network)[22]中的计算机语言学、自然语言处理领域的科技论文作为实验数据集,对于该数据集中的每一篇科技论文都有其全文信息和参考文献的引用信息。
从实验数据集抽取引文关系并删除不存在引用关系的科技论文后,提取科技论文的结构信息:包括写作需求的引文上下文和参考文献的摘要、引言和全文。在此基础上,构建具有引文关系的文本对集合和不具有引文关系的文本对集合。后者的构建逻辑是:若一篇文章有多段引文上下文,则无引用关系的文本对集合由每一段引文上下文和与其无引用关系的科技论文构成。接着对原始语料内容进行清洗,去掉各种与分析内容无关的信息,如乱码、非字符数据、与引用关系无关的文本结构等,并使用WordNet提取词干信息。
由于文本对的引用关系标签分布极度不平衡,具有引用关系的文本对在所有文本对中为0.1%左右,因此需要平衡数据集。欠采样的方法可以规避测试集的过拟合,使梯度下降,降低科技论文引用关系的损失[23]。并且在引用关系的研究中,找出存在引用关系的文档特征比找出不存在引用关系的文档特征更重要,所以本文使用随机欠采样的方法来平衡数据集。
经过数据集预处理,写作需求—参考文献文本对数量统计信息如表1所示:
本文按照文本对的引用关系划分了两个数据集:分别为存在引用关系的数据集和使用随机欠采样方法抽取的相同数量的不存在引用关系的数据集。两者随机合并为1个集合,按照60%、20%、20%的文本对比例划分为训练集、验证集和测试集进行实验。
3.2 评价指标
本文使用F1值来评估模型效果。根据现实应用的需求,找到具有引用关系的文本对比找到没有引用关系的文本对更重要,而F1值能同时兼顾准确率和召回率,可以看作是两者的一种调和平均,它的最大值是1,最小值是0。
在模型的训练上使用早停法,考虑神经网络的浮动性,当验证集的F1值不再提高后再迭代训练3次,若依然无法提高,说明训练集已过拟合,恢复使验证集F1值最高的参数权重作为模型参数。
3.3 对比实验
选择“写作需求引文上下文—参考文献摘要”的结构对模型参数调优。SVM使用五折交叉验证选择参数。为防止模型过拟合深度学习模型CNN、RNN以及HABCM使用早停法,并使用交叉熵作为模型的损失函数,调优后的神经网络模型参数及其对应的F1值和准确率如表3所示:
其中,CNN参数指卷积核大小,RNN和HABCM参数指神经元个数。
3.4 参考文献结构选择
为探究科技论文的不同结构对科技论文主题内容的代表程度及对引文推荐的影响,本研究选择“摘要”“摘要和引言”“科技论文的全文”3种结构代表参考文献。各模型参数均为经过上节实验调整得出的最优参数,通过不同的对比实验验证参考文献结构对匹配结果的影响,其F1值和准确率如表4所示。
构更好,“Word2vec+RNN”中“摘要”准确率略高于“摘要和引言”,属于可忽略的差异。在HABCM模型中,由于加入了层次Attention的双向GRU模型在较长文本上的表示效果较好,所以全文的准确率要高于摘要,但从F1值的表现上来看,“摘要和引言”结构更高,所以也从侧面反映了在考虑正向文本召回的情况下,还是“摘要和引言”结构使模型的分类表现性能更加均衡。故而本文选择“摘要和引言”的结构来表示参考文献。
3.5 实验结果
综上,选择所有模型最优参数以及“摘要和引言”的参考文献结构进行实验,实验参数及结果如表5所示:
首先,本文提出的模型较4种对比实验取得了最高的F1值,说明在同时考虑准确率和召回率的情况下,本模型優于对比实验模型。其次,在准确率方面,HABCM模型明显高于“TF-IDF+SVM”“Word2vec+SVM”和“Word2vec+CNN”模型,仅低于“Word2vec+RNN”模型0.93%,究其原因可能在于科技文献在引用参考文献时具有较为复杂的引用动机:从情感分类上说,引用文献不仅是表达对引文内容的认可,也包括对引文的批判;从引文原因上说,引用文献包括介绍方法、理论等与参考文献主题是语义相关性较强的原因,也包括基于致敬同行、追溯术语概念来源等较为片面、与参考文献主题语义相关性较弱的原因。由于存在主题关联度不强的引用动机,导致给模型训练带来噪声[24]。最后,从应用角度来看,该模型在准确率上的微小误差并不影响应用效果。
4 结 论
本文针对目前科技论文数量指数增加、获取与科研主题相关文献越发困难的情况,提出了HABCM模型。该模型能根据科研人员的写作需求推荐与其研究主题相关的参考文献,辅助科研人员进行学术写作。
本文的主要结论包括:其一,提出了HABCM模型,该模型使用“层次Attention+双向GRU”来表示文本对,通过先拼接后提取特征的方式来匹配文本对,在ACL ARC数据集上获得了74.96%的F1值和78.38%的准确率,取得了预期效果。其二,本文考虑了参考文献的“摘要”“摘要和引言”“全文”结构对引文推荐效果的影响,并通过实验证明使用“摘要和引言”的结构来代表参考文献比仅使用“摘要”或“科技论文全文”的效果更优。
与此同时,本文也存在一定的局限:其一,实验数据集的领域较为单一。本文使用的数据集仅来自计算机语言学、自然语言处理领域,所以无法评估模型在科技论文其他主题领域的效果。其二,仅考虑使用引文关系进行推荐,未考虑其他因素,如科研人员兴趣、作者权威性、引文功能等因素。其三,未剔除与写作需求引文上下文主题相关性较弱的参考文献。在数据集处理阶段,未根据作者的引用动机剔除非主题相关的参考文献:如致敬同行、追溯术语概念来源等间接引用,导致训练数据集中存在大量弱主题相关的文本对,影响模型效果。
未来的研究可以考虑以下两个方向:第一,构建基于科技论文作者的合著信息、曾发表论文等信息的模型,实现引文推荐的个性化。第二,构建更细粒度的引用关系分类方法:如强引用、中引用、弱引用,从而获得文本对之间更精确的引用关系,以辅助科研人员进行更精准的参考文献选择。
参考文献
[1]Strohman T,Croft W B,Jensen D,et al.Recommending Citations for Academic Papers[C]//International Acm Sigir Conference on Research and Development in Information Retrieval,2007:705-706.
[2]He Q,Pei J,Kifer D,et al.Context-aware Citation Recommendation[C]//The Web Conference,2010:421-430.
[3]Tang J,Zhang J.A Discriminative Approach to Topic-Based Citation Recommendation[C]//Knowledge Discovery and Data Mining,2009:572-579.
[4]Yang L,Zheng Y,Cai X,et al.A LSTM Based Model for Personalized Context-Aware Citation Recommendation[J].IEEE Access,2018,(6):59618-59627.
[5]Ebesu T,Fang Y.Neural Citation Network for Context-Aware Citation Recommendation[C]//International Acm Sigir Conference on Research and Development in Information Retrieval,2017:1093-1096.
[6]Mikolov T,Le Q V,Sutskever I.Exploiting Similarities Among Languages for Machine Translation[J].arXiv:Computation and Language,2013.
[7]Mikolov T,Chen K,Corrado G S,et al.Efficient Estimation of Word Representations in Vector Space[C]//2013.
[8]Peghoty.Word2vec中的數学原理详解[EB/OL].http://www.cnblogs.com/peghoty/p/3857839.html,2018-02-18.
[9]Lai S,Xu L,Liu K,et al.Recurrent Convolutional Neural Networks for Text Classification[C]//National Conference on Artificial Intelligence,2015:2267-2273.
[10]Bahdanau D,Cho K,Bengio Y.Neural Machine Translation By Jointly Learning to Align and Translate[J].arXiv preprint arXiv:1409.0473,2014.
[11]Yang Z,Yang D,Dyer C,et al.Hierarchical Attention Networks for Document Classification[C]//Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,2017:1481489.
[12]Cheng J,Dong L,Lapata M.Long Short-Term Memory-Networks for Machine Reading[J].arXiv Preprint arXiv:1601.06733,2016.
[13]Huang P S,He X,Gao J,et al.Learning Deep Structured Semantic Models for Web Search Using Clickthrough Data[C]//Proceedings of the 22nd ACM International Conference on Information & Knowledge Management.ACM,2013:2333-2338.
[14]Shen Y,He X,Gao J,et al.Learning Semantic Representations Using Convolutional Neural Networks for Web Search[C]//Proceedings of the 23rd International Conference on World Wide Web.ACM,2014:373-374..
[15]Yin W,Schütze H.Multigrancnn:An Architecture for General Matching of Text Chunks on Multiple Levels of Granularity[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing(Volume 1:Long Papers),2015,(1):63-73.
[16]Tai K S,Socher R,Manning C D.Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing(Volume1:Long Papers),2015,(1):1556-1566.
[17]Lu Y,Xiong X,Zhang W,et al.Research on Classification and Similarity of Patent Citation Based on Deep Learning[J].Scientometrics,2020,123.
[18]Google.Word2vec[EB/OL].https://code.google.com/archive/p/Word2vec/,2018-12-15.
[19]Yang Z,Yang D,Dyer C,et al.Hierarchical Attention Networks for Document Classification[C]//Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,2017:1481489.
[20]ACL Anthology Reference Corpus[EB/OL].http://acl-arc.comp.nus.edu.sg, 2019-04-11.
[21]ACL Anthology[EB/OL].https://aclanthology.info, 2019-04-11.
[22]ACL Anthology Network[EB/OL].http://tangra.cs.yale.edu/newaan/, 2019-04-11.
[23]Punlumjeak W,Rugtanom S,Jantarat S,et al.Improving Classification of Imbalanced Student Dataset Using Ensemble Method of Voting,Bagging,and Adaboost with Under-sampling Technique[M].IT Convergence and Security 2017.Springer,Singapore,2018:27-34.
[24]Bornmann L,Daniel H D.What Do Citation Counts Measure?A Review of Studies on Citing Behavior[J].Journal of Documentation,2008,64(1):45-80.
(責任编辑:郭沫含)
