基于遗传算法的共享助力车调度问题研究
2021-03-08王玖河
王玖河,高 辉,刘 欢
(燕山大学 1. 经济管理学院;2.京津冀协同发展管理创新研究中心,河北 秦皇岛 066000)
共享助力车面临用户需求的潮汐性所导致的电子围栏站点之间的数量不平衡问题,并且在顾客使用中会耗费电池电量。因此,共享助力车的调度由两部分组成:1) 单车数量上的平衡;2) 对缺电助力车更换电池。在实际的调度过程中运营方把助力车数量平衡与电池更换分开进行。这种调度方式不仅增加了运营方的调度次数,同时还不利于消费者的消费体验,即会出现站点的助力车的数量足够,个别助力车缺电而无法使用的情况。
有部分学者对公共自行车和有固定停靠点的共享单车进行研究。Mao等[1]通过得到自行车各站点的可视化信息,实时预测进出流量,从而建立了一种新的动态调度方法Tir-G。Xu等[2]采用改进的遗传算法研究了公共自行车的动态调度问题。Zhu等[3]提出了一个全新的公共自行车多媒体交互调度系统,使用遗传算法求解最短的调度路径、最长的调度运输距离和调度车辆数。崔元洋等[4]建立用车谷和用车峰两时期的公共自行车调度模型,使用遗传混合蚁群算法来求解该模型。贾永基等[5]对共享单车的调度问题引入了电子围栏,采用改进变邻域搜索算法求解最优路径。吕畅等[6]提出了一新的站点分块策略,采用双层禁忌搜索算法求解较优解。对于共享电动车的电池配送,冯春等[7]结合软时间窗进行车辆路径规划,采用扫描算法和遗传算法解决共享电动车的电池配送问题。
对于车辆路径问题,陈玉光等[8]首次提出将准时送货和最小耗油相结合,建立多约束VRP模型,利用改进的粒子群算法求出最优解。李嘉等[9]引入了装载量和行驶距离作为影响因素,采用变邻域搜索和模拟退火的混合启发式算法进行求解。张景玲等[10]针对车辆运输中的同时取送货的特性,运用禁忌搜索和模拟退火混合算法进行求解。张明伟等[11]研究车辆碳排放,引入动态负载,提出一种混合蚁群算法,求解出碳排放量最低的配送方案。王涛等[12]针对车辆路径问题提出了改进智能水滴遗传混合算法。
本文将共享助力车的调度与电池的更换同时进行,因当前大多数运营商还是采用燃油车来实行调度,故本文以燃油调度车辆的耗油成本为目标。在考虑到路径和不同载重下车辆的耗油量的不同等综合因素影响下求成本最低,对调度路径进行合理规划。
1 问题描述与模型构建
1.1 问题描述
共享助力车的调度优化问题与共享单车的重平衡问题有着类似的地方,但本文提出的调度方案涉及到助力车的电池更换,因此又与传统的单车调度不同。调度过程如下:调度车辆从起点车库出发,依次经过并服务其调度区域内的电子围栏,并且不会对服务过的电子围栏进行重复访问,且每到一个电子围栏处时,如果助力车的数量超出标准存量,则运走多余的助力车,同时对该点需要更换电池的助力车更换电池;如果该点助力车少于标准存量,则从调度车上卸下相应数量的助力车来进行补充。因为调度车的自身容量和承载重量的限制,每辆调度车所能携带的电池的数量有限,本文在受到里程和载重的双重约束下,寻求一个最优的服务顺序和路径规划。
共享助力车调度过程的简单示例图如图1。其中,有1个车辆起点(终点),5个电子围栏,3个点有装车的需要,2个点有卸车的需要,同时有4个点需要更换电池,1个点不需要更换电池。共享助力车的调度过程具有以下特征。

图 1 助力车调度平衡的简单示例Figure 1 A simple example of the dispatching balance of a bicycle
1) 调度车从开始到结束回到调度中心时车上的装载量应为0;
2) 因为调度的目的是为了实现助力车数量平衡,所以每辆车,每条路径都是混合装卸的;
3) 调度过程还要考虑更换电池,所以调度的过程中需要换电池的助力车的数量不能超过调度车所携带的电池数量。
模型假设如下。
1) 假设整个区域内的助力车总数量保持不变,每个调度区域的助力车数量也保持一定,没有助力车被回收,也没有新助力车投入使用,且每一辆车都能被使用。
2) 假设每一辆调度车的型号相同,承载容量相同,最长里程相同。
3) 假设每辆调度车在任何情况下的耗油能力都一致,且都是与路程和载重成线性正相关,不考虑城市的复杂路况和调度车辆自身新旧程度不同所产生的影响。
4) 假设调度车在每次调度过程中出发时都是满油状态,且在整个调度过程中不需要加油。
1.2 模型构建
本文研究不仅考虑路径的长短对燃油调度车油耗的影响,还考虑到不同载重的状态下对燃油调度车辆油耗的影响,从而综合规划路线。目前将车辆油耗当作路径优化目标的研究较少,这主要是因为燃油车辆的耗油影响因素很多,且很难分清楚各个因素对车辆耗油的影响是多少,此类研究的困难之处在于计算路径、载重与耗油量的关系式。当前有一些学者已经对车辆燃油问题进行了一些研究[13-14],建立了不同的模型,提出了不同的计算方法。因本文主要研究路径规划,所以采用已有方法中较为简单的“负载估计法”[15]。该方法认为车辆的行驶距离和载重决定着耗油量,且载重与耗油之间存在线性关系,其关系式如下

在式(1)中, ρ0为车辆空载时的车辆耗油率;ρ∗为满载时的车辆耗油率;p为负载重量。本文以最小耗油成本为研究目标,因此将 ρ0当作车辆仅装载电池时的每公里耗油量, ρ为每增加一辆助力车所要付出的耗油量, µ2为每公里燃油成本。在此基础上,假设pij为i点到j点的助力车数量,dij为i点到j点的距离,从而得出以下车辆从i到j的耗油成本。

在此限制条件下求出的调度路线可能不会是车辆行驶距离最短的路线,但因为成本的限制,会使调度车辆尽可能地在每段运输路线中装载较少的助力车数量,以实现成本最低。符号说明见表1。
考虑耗油成本最小化的调度模型目标函数。

表 1 符号说明Table 1 Symbolic Description
总成本最小函数模型为
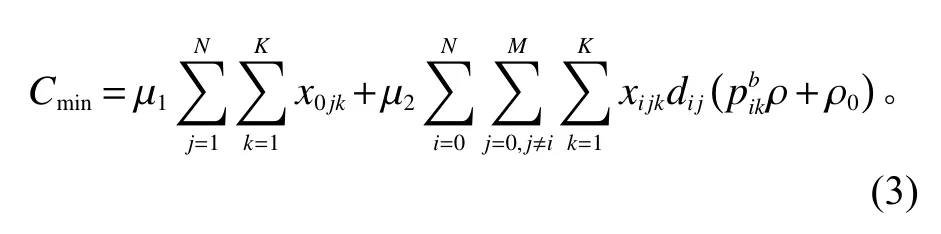
约束条件。
1) 限制了调度车经过且服务一个电子围栏后不会重复访问。

2) 为了实现车辆必须从i点到j点,且最后回到起点,实现闭环运输。
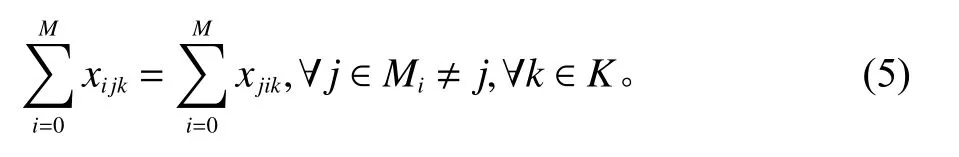
3) 保证运输车从i点到j点的运载量不会发生变化,到达每个服务点时的运载量的变化具有合理性,且确保了运载量不会超出车辆运载容量。

5) 在每个电子围栏需要更换电池的助力车数量不能大于现有数量。

6) 整个调度过程中每阶段需要更换电池的总数不能大于携带电池的上限。

2 基于AP算法的调度区域与调度中心的确定
共享助力车的调度情况分为小规模和大规模2种,小规模的类型可以直接进行调度的路径规划,但大规模的类型需要多辆调度车进行调度,因此需要提前划分好调度区域,以便更好地实行调度安排,同时也降低了求解问题的难度。本文引入仿射传播聚类算法(affinity propagation,AP算法),流程见图2。对所有的电子围栏进行分类,得出各个调度区域。
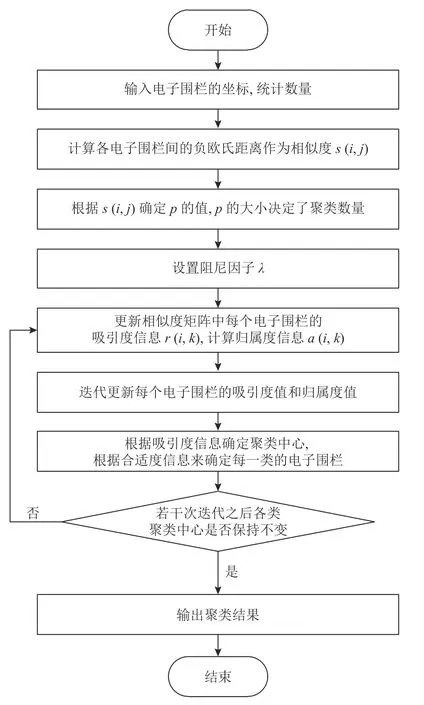
图 2 AP算法流程Figure 2 AP algorithm flow
2.1 AP算法
AP算法是一种依托于数据点之间进行信息传递的聚类算法。该算法的特点在于不用事先确定聚类的个数,并且算法本身会把每一个样本点都当成潜在的聚类中心,并通过不断地迭代吸引度和归属度的数值来调整最佳的聚类中心,再把其他的样本点划分到这些中心点的类中。
本文的算法具有以下优点:1)无需事先指定聚类数量参数;2)明确的质心,样本中的每一个点都有机会成为聚类中心;3)对初始值不敏感,多次聚类的结果是一样的;4)此算法求出的误差平方和比其他的方法得出的都要低;5)与K-Means相比具有更强的鲁棒性和准确度。
2.2 AP算法实施流程
AP聚类算法实施步骤如下。
步骤1计算待聚类的电子围栏集N={N1,N2,···,NN}的相似度矩阵。
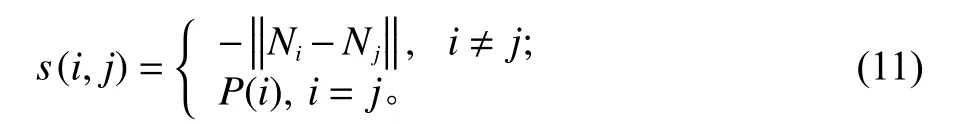
式中,相似度矩阵s(i,j)的值为各个电子围栏之间的欧氏距离的负值,可以理解为点j成为i的聚类中心的合适程度;P为Preference,是指参考度或偏好参数,P值可以取相似矩阵的最小值、中位数或两倍的中位数,其取值大小决定了聚类数量的多少。
步骤2计算并更新k点对于i点的吸引度r(i,k)。

式(13)中, λ为阻尼因子,取值范围在[0,1],其作用是为了让算法快速收敛,此公式为吸引度r(i,j)的更新规则,a(i,k′)表达除k以外的其他点对于i点的归属度值,初始值为0;s(i,k′)表示除k以外的其他点对i点的合适度;r(i,k)表示数据点k成为数据点i聚类中心的累积证明,r(i,k)大于0,则表示k成为聚类中心的能力强。
步骤3计算并更新k点对于i点的归属度a(i,j)。

式(14)、(15)为归属度a(i,j)的更新公式,a(i,k)表示i点选择k点作为聚类中心的合适程度。K为所有k的集合。
步骤4确定聚类中心。

式(17)表示i点对于自身的吸引度和归属度大于0时选择对应的顶点作为聚类中心。
步骤5划分数据点与聚类中心的隶属关系。

选择与当前顶点i吸引度与归属度之和最大的顶点j作为其聚类中心,即把点i归为j类中。
根据以上步骤最终可以确定各地区的共享助力车可以划分为多少个调度区域,并且确定在空间位置上最优的调度中心,使其到其所属区域所有电子围栏的直线距离最短。
3 遗传算法
本文模型所要求解的过程复杂度较高,且随着调度区域数量的增加,求解的难度和复杂度将会呈几何式增长。因此,本文采用遗传算法(genetic algorithm)进行求解,该算法是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法,遗传算法流程见图3。此算法的优点在于原理、操作较为简单,鲁棒性强,不易受限制条件的约束,还具有一定的隐含并行性和较强的全局寻优能力,在解决组合优化问题中得到广泛的应用。
3.1 算法实现步骤
3.1.1 构造初始可行解
在各个不同的调度区域分别进行初始解的构造,具体步骤如下。
步骤1设置一条初始调度路径,其上节点为空。
步骤2将原有的电子围栏节点顺序打乱,根据约束条件(7)对该集合进行一次提取,符合条件的电子围栏节点提取出来放到新的集合里,并将原始集合里的该节点删除;不断重复该操作,直到将原始集合里的所有节点都提取到新的初始解集合中。车辆行驶路线初始解见图4。
图4(a)为此次样本数据集,包含一个调度中心,为编号1,编号2~10为电子围栏,需求量总数为零,每个电子围栏的标准存量为20,调度车的电池载量为20,助力车载量为15。图4(b)表示受到装载量的限制,形成的初始解中调度车的装载量每次都不会超过15。
步骤3对步骤2形成的初始解进行检验,判断其更换电池的总数是否不超过调度车辆所携带的电池数量,即若在点i处首次出现更换电池的数量超过车辆携带量,则在该点之前插入调度中心,并将所有电池更新为满电状态;从i点开始重新统计剩下节点的需换电池的数量,以同样的原则插入调度中心,直到整条路线满足条件(9),形成最终的初始解。插入调度中心见图5。图5对图4 (b)的初始解进行调度中心插入,两个调度中心之间的换电量不超过20。

图 3 遗传算法流程Figure 3 genetic algorithms flow

图 4 车辆行驶路线初始解Figure 4 Initial solution of vehicle route

图 5 插入调度中心Figure 5 Insert dispatch center
3.1.2 遗传算法操作步骤
步骤1设置初始解集Xcs;
步骤2构造初始可行解;
步骤3在初始可行解中进行选择,挑选出新的解集Xgx;
步骤4对新的解集Xgx进行交叉与变异操作,与初始可行解Xcs合并,保留最优解集Xyj;
步骤5返回步骤3重复求解,直到满足最大迭代次数,输出最优解Xbest。
4 算例仿真分析
4.1 算例设计
本文模型采用Matlab R2018a编写程序,计算机操作系统为Windows 8.1 64位操作系统,CPU为Intel(R) Core(TM) i5-3337U,内存为4.00 GB。
本文使用算例验证算法的可行性,并且构造10组算例,每组算例拥有的电子围栏的数量为200,电子围栏在[0, 400]的区间内随机生成坐标,每个电子围栏的标准停放量为20辆,且每个站点的助力车需求量在[-20, 20]之间随机生成,换电池数量在不超过单车数量的范围内随机生成。燃油调度车的参数根据设置:助力车的装载量为Q1=30,电池的携带量为Q2=50,车辆固定使用成本为µ1=300元,仅装载电池时的单位里程耗油成本µ2ρ0=0.6元/km,每增加一辆助力车的每公里耗油成本µ2ρ=0.005元/km。单独进行电池配送的成本为200元。
本文经过多次聚类调整后确定在P=2*median(s),即2倍的相似矩阵中位数,s为相似度矩阵。 λ=0.5时得到的聚类结果相似度最大,为最优结果。设置遗传算法初始种群为200,遗传代数为1 000。
4.2 算例结果
本文模型结果如表2所示,在调度过程中总的更新电池的次数不超过35次,最少的为28次,平均每个小区域的更新次数为4~5次。与原调度模式相比调度成本显著降低,图6为SL1的聚类分区结果。算例测试结果证明本文设立的模型能有效降低助力车的调度成本。

表 2 算例求解结果Table 2 Solution results of numerical examples

图 6 SL1的聚类分区图Figure 6 Cluster partition diagram of SL1
5 总结
本文将共享助力车的电池配送与助力车的调度相结合同时进行,并且考虑载重对燃油调度车耗油的影响。利用AP算法对一个大范围的服务区域进行聚类,实现电子围栏的归属划分,确定助力车的服务范围,并确定各个区域的调度中心,利用遗传算法对各区域进行调度路线的求解。本文所构建的模型和提出的调度方案有效地降低了运营方的调度成本,减少了调度所要花费的时间,并且最终能更好地服务于顾客,提升顾客的消费体验。
未来还可以研究的方向如下:1) 个别助力车停放在电子围栏以外区域的调度问题;2) 寻找更好的算法解决本文的调度方案;3) 当共享单车也引入电子围栏后单车和助力车共同调度的问题。
