CFPS 面板数据下劳动收入对个人健康影响的实证分析
2021-03-07陈梓森吴钟松
□陈梓森 吴钟松
一、引言
健康被认为是重要的人力资本。不同的收入水平和社会地位对健康资本的投入程度有不同的偏好。良好的健康会提高劳动生产率,使劳动者获得赚取更多收入的能力。2016 年8 月20 日,习近平总书记在全国卫生与健康大会上提出:没有全民健康,就没有全民小康。习近平总书记的重要讲话精神是全党全社会建设“健康中国”的行动指南,更是全方位保障人民健康的行动号令。党的十九届五中全会再次提出了要提高人民收入水平,强化就业优先政策,建设高质量教育体系,健全多层次社会保障体系,全面推进健康中国建设的重要要求。因此,研究个人健康与劳动力市场之间的关系将更好地提高社会效益,从而为完善国民健康政策和制定保护广大劳动者的相关措施提供指导建议。在中国特色社会主义进入了新时代的大背景下,人民群众对经济发展和健康安全两者都有着更高的需求;社会中生产生活的积极性和个人的工作效率都与良好的健康息息相关。只有关注劳动生产者的健康状态,才能为劳动力市场的良性进步提供有利条件。
本文基于Grossman 健康需求理论,研究个人层次劳动收入、社会医疗保险对健康状况的影响。尽管已有文献建立了健康与工作之间的关系,但影响的程度和机理尚未阐明。大部分研究表明,收入越高,就越倾向于拥有越好的健康,但事实上普遍存在过度依赖自我评估的健康报告和未能处理健康与收入之间的相互作用产生的内生性问题等方面的缺陷。另外,中国自2005 年起启动实施第五阶段的医疗保障制度改革,扩大基本医疗保险覆盖面是此阶段的核心内容。一方面,通过评估劳动力市场中劳动者的健康情况,可以了解相关政策是否有效;另一方面,通过增加居民的健康资本存量,可以帮助改善相关的健康和劳动力市场政策,并获得更多的劳动力产出。在全面的数据样本支撑下,从实证分析中能获得更可靠的结果,无偏有效的回归结果的系数量级大小可以用来观察劳动者的健康效应对收入的敏感程度,以及是否除了收入外还受到其他因素(如生活行为、居民身份)的影响。
可能的贡献和创新是:第一,健康指标的创新。本文尝试为生理和心理健康各创建一个健康指数以使健康测量更加客观和涵盖内容更加全面。此外,除了收入和基本个人特征外,在解释变量的选择上还将与健康相关的医保政策和生活行为纳入参考。第二,实证分析中使用了更广泛的面板数据,整理了2010-2018 年共27468 名受访者的样本。在更大的样本量和更长调查时间下可以获得更有效无偏的结果。第三,利用Hausman-Taylor 模型克服因健康-收入交互作用和无法避免的变量遗漏所带来的内生性问题,并通过Hausman 检验和稳健性检验等方式解释实证结果的有效性。
二、文献综述
Grossman(1972)最先把个人健康作为人力资本的重要组成部分,并构建了工资率、年龄、教育水平、医疗服务等要素对个人健康资本影响的理论基础[1]。个人健康可被视为两种不同的属性:消费性和投资性。健康需求模型指出,当健康产出的边际成本等于所能提高的健康边际利益时,则为个人健康投资的最优解。该模型为本文对收入和健康的研究提供了理论依据。在实证分析中,需要把健康需求理论转化为可估计的计量经济学模型,测量一系列个人、家庭和社会指标作为积累健康存量的影响因素。我们将检验这些理论预期并根据结果对存在的差异作出解释。
Barnay 等人(2018)运用动态模型下的广义矩估计,解释了劳动收入对健康表现具有积极影响[2-3]。Chetty(2016)等研究了收入与预期寿命之间的联系,以解释美国不同收入水平人群的健康不平等问题[4]。他们认为,健康行为对预期寿命有很大影响,而医疗服务和健康保险支出对此则没有太大影响。
国外大多研究个人层次上收入对健康的影响都运用了面板数据进行实证分析[5-6],但由于受调查数据限制,国内早期的研究大多仅为截面数据,或样本数量较小,年度跨越较短的面板数据。中国家庭追踪调查(CFPS)在近年的不断完善和延伸为我们提供了很好的数据基础。Hausman-Taylor(H-T)模型作为较先进的计量方法,在近些年开始被少量文献运用到解决内生性的问题上。王一兵、张东辉(2008)使用H-T 模型研究了健康人力资本对个人收入的影响。他们通过中国营养状况调查的面板数据证实了H-T 估计量比随机效应或固定效应的估计量更可靠有效[7]。相似地,于大川(2013)运用该模型研究健康对中国农村居民收入的影响时,也认为H-T 估计能减少甚至消除由于健康和收入之间相互作用带来的内生性偏误问题[8]。但目前还没有研究将此运用在我国的个人劳动收入对健康的影响上,本研究将对上述问题作出进一步的拓展与深入。
除了劳动收入外,医疗保险对健康的影响也是重要考察因素。自2007 年起,中国推动了一系列城镇居民基本医疗保险普及政策。健全有效的社会医疗保障体系能降低个人医疗服务成本及降低重大医疗性支出的风险。贺小林(2013)通过对9 个城市的基本医疗保险政策研究指出,从服务利用和负担性来看,低收入人群就诊数目仍然较低,因病致贫的现象还没能得到有效的缓解[9]。丁学娜(2013)则从中国企业职业福利转型的视角考量了职业福利在员工医疗保健方面的补充作用,认为医疗保险的企业缴费比例存在较大的地区性差异[10]。大部分就医疗保险影响的分析都仅为截面数据或选取样本较小,本文希望借助面板数据和较大的个人层次的样本获得更有效的实证结果。
三、数据和研究方法
(一)数据来源
本文数据来源于北京大学开放研究数据平台提供的中国家庭追踪调查(CFPS)。该调查从2010 年起,2年一度连续追踪个人、家庭和社区3 个维度的信息,较全面地反映了中国社会、经济、人口等问题的动态变化,这也是目前调查样本最广泛的连续性追踪数据。本文整理合并了2010-2018 年间5 个截面数据,形成了最终的非平衡面板数据,总共47561 个样本。使用中国家庭追踪调查数据集的优点是:首先,它不仅包含了受访者广泛的个人特征和经济状况信息,还涵盖了全面的健康数据。其次,这是目前涉及个人健康和收入问题样本量最大、时间跨度最广的开放调查数据。最后,该调查的受访者群体广泛,采样覆盖了不同年龄、受教育程度和全国各地区,有利于进行进一步的异质性分析。
(二)变量说明
个人健康状况是被解释变量,本文创建了由4 个客观健康指标恒定的生理健康指数来克服目前对健康衡量较片面和主观性强的问题。参考Kling,Liebman 和Katz(2007)的方法[5],个人生理健康指数(Indexi)是“两周内病伤程度”“是否确诊慢性疾病”“一年内是否有因病住院”和“医疗总费用”4 个成分的标准分(z-score)的均等加权总和:

每个成分的标准分(z-score)是通过个体数据(xij)减去该成分的平均值(μj),然后将其除以该成分的标准差(σj)得到的。健康指数较小的样本意味着具有较差的健康状况。同时,符合两周内无病伤、无确诊慢性疾病、一年内无因病住院、医疗总费用低于100 元4 个条件的样本被定义为得分最高的样本,共占总样本的5.34%。表1 是健康指数在各个级别的自评健康选项中的平均分,显示了两者具有一定的相关性。
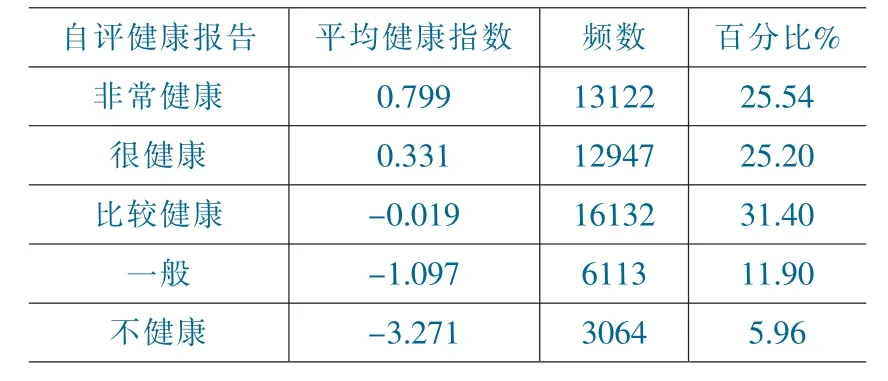
表1 健康指数在各层次自评健康报告中的分布
除了生理健康外,心理健康指数是另一个被解释变量。心理健康的评定选取了调查中的6 个变量:“情绪沮丧、郁闷的频率”“精神紧张的频率”“难以平静的频率”“对未来失去希望的频率”“做任何事都感到困难的频率”“感到生活没有意义的频率”。受访者在5 个频次中作出选择。这6 个变量再按上述标准分(z-score)的算法进行均等加权求和得到心理健康指数,心理健康状况较好的受访者将获得较高的指数。去除极端值后样本心理健康指数介于-17.83 至3.58 之间。
个人收入是主要关注的解释变量。本文只取用18-65 岁就业状态为在业的样本,劳动收入的计算包括工资、奖金、年终奖、第二职业或兼职收入和其他劳动收入之和。为了获得具有经济含义的回归结果,收入进行了取自然对数处理。另一关注的变量是社会医疗保险制度对健康的影响程度。样本中在职人员的医疗保险类型包括:公费医疗、城镇职工医保、城镇居民医保、补充医保和新型农村合作医保。样本若参与任意一项上述医疗保险则在虚拟变量中标记1,参保样本占总样本的74.67%。控制变量中包含了关于个人特征、家庭情况和健康行为的信息变量。表2 报告了计量模型中各变量的描述性统计。

表2 各变量描述性统计
(三)研究方法
劳动收入对个人健康影响的实证分析基准模型设定为:

其中,Hit是生理健康指数或心理健康指数;lninckit是主要观测的解释变量个人劳动收入的自然对数;Xkit是一系列的其他解释变量。随机误差项由(ui+εit)表示,假设εit遵循独立同分布且与εit不相关,其中,ui包含所有影响因变量而不随时间变化的不可观测因素,εit包含所有随个体和时间变化的不可观测因素。基准模型将分别采用普通最小二乘法(OLS)、随机效应和固定效应的计量方法进行回归分析。固定效应回归法能控制无法观测的个体异质效应,从而减少内生性问题;随机效应则能把被固定效应排除在外的不随时间变化的外生变量纳入回归中。
健康-收入研究中的内生性问题主要有两个原因:一是模型中不可避免地会有部分与健康相关的变量无法包括;二是健康和收入之间存在交互作用关系。使用普通最小二乘法(OLS)估计可能会存在偏差,目前被认为最有效克服内生性问题的方法是寻找合适的工具变量。但合格的工具变量应同时满足强相关性和充分外生性的条件,较难获得[11]。作为替代方案,笔者在面板数据上使用以工具变量法为思路的Hausman-Taylor 模型来消除偏差。Hausman-Taylor 模型借助随时间变化的外生变量的平均值作为工具变量。通过两阶段最小二乘估计,可以使估计结果更加有效。该公式可表示为:

其中,X 表示所有时变变量,Z 表示所有非时变变量。具体地,X1包括年龄、城乡分类、婚姻状况和医疗保险,X2包括个人收入、人均家庭纯收入、家庭医疗保健支出和健康行为;Z1表示性别,Z2表示受教育程度。ui抓取了不可观测的个体异质性,eit是随个体和时间变化的误差项。X1,it和Z1,i作为外生变量与ui不相关,而X2,it和Z2,i作为内生变量与ui相关。HT 模型基于工具变量估计法的原理以自带的变量转化为工具变量:(X2,it-)用作内生变量X2,it的工具变量,时变的外生变量的平均值则用作内生变量Z2,i的工具变量。该回归模型在不必寻找外部工具变量下不但能克服健康-收入间相互的作用引起的内生性偏差,还能把被固定效应排除在外的非时变变量归入模型中。
四、实证分析
(一)健康状况的影响结果
将Grossman 健康需求理论应用到实证分析中,构建以健康状况为被解释变量,作自然对数处理后的个人劳动收入为解释变量的半对数函数。首先,是个人劳动收入对生理健康指数的影响,表3 报告了其OLS、随机效应、固定效应和H-T 模型估计的回归结果。
OLS 和随机效应在各系数上普遍存在被高估的系数,H-T 模型估计量与固定效应估计量较为接近。随机效应与固定效应的Hausman 检验结果为:χ2(13)=35.05,拒绝原假设,证明了随机效应不是一致性的估计量,固定效应估计量更具无偏性。比较各系数的标准误差发现,固定效应的标准误差在这4 种模型中相对较高,而OLS、随机效应和H-T 模型各系数的标准误差相仿。H-T 模型除了具备无偏性,系数估计量还有更好的有效性。因此,实证结果将以固定效应和H-T 模型估计量作为主要参考。
个人劳动收入的系数在各个回归中都具有显著的正效应,显著性水平在OLS 和随机效应中的1%变成了在H-T 模型中的10%。系数估计值为0.016 表示当个人劳动收入提高10%时,生理健康指数将提高0.16个标准差。医疗保险在健康上表现了1%水平下显著性的积极作用,享有社会医疗保险的个人比尚未获得的个人指数增加0.085 个标准差,这也反映了医疗保险能通过降低医疗服务费用而对健康形成正面效应。关于个人特征的变量中,受教育程度的系数量级最大。以文盲/半文盲和小学教育程度的人群为基准,拥有初高中、中专技校学历的人群健康指数增加0.26 个标准差,在1%显著性水平下显著,而拥有大专、本科和研究生学历的人群则增加达0.31 个标准差。这一结果与Grossman 健康需求理论中强调受教育年限对健康投资有重要的正效应的论述十分契合。健康效应也存在显著的性别差异,样本中男性健康指数比女性增加0.20 个标准差,系数量级仅次于受教育程度的系数。关于生活行为的变量中,锻炼频数每周增加一个单位,健康指数将提高0.019 个标准差,在1%显著性水平下显著。抽烟系数尽管呈现了对健康的负效应,但没有达到显著性水平。另外,以未婚者为基准的婚姻状况变量以及以城市居民为基准的城市农村居民身份变量在该模型中对健康没有表现出显著性影响。
表4 报告了收入对心理健康指数的回归结果。Hausman 检验显示:χ2(12)=33.92,拒绝原假设,同样是固定效应比随机效应回归更具无偏性。收入对心理健康的影响比生理健康更大,在1%显著性水平下,收入提高1%时,心理健康指数将提高0.14 个标准差。相应地,医疗保险也有着显著且较高的系数,享有社会医保的人比无医保的人指数增加0.29 个标准差。相较于上面对生理指数的影响,心理指数变化更敏感的原因:一是人们的心理状态反映在指数上的差异比生理健康更大;二是个人收入的心理感知往往比生理感知更直接和迅速。但意外地,在教育的虚拟变量中系数没有显著性水平。关于个人特征变量,性别仍存在显著的差异,男性的指数比女性增加0.74 个标准差。另外,城市户口居民心理健康指数比农村居民增加0.36 个标准差,在1%显著性水平下显著。关于生活行为的变量,除了锻炼依然有显著的正向效应外,高频的饮酒行为在对心理健康的影响中也表现了显著的负向效应。

表3 个人劳动收入对生理健康的影响
(二)稳健性检验
我们已知自评健康报告与健康指数存在相关性,为了确保实证结果的可靠性,本文采用自评健康报告的变量作为被解释变量进行稳健性检验。自评健康分为五个等级:“非常健康”为5 分,“很健康”为4 分,“比较健康”为3 分,“一般”为2 分,“不健康”为1 分。另外,除了以上4 种回归模型外,在稳健性检验中还加入了Amemiya-MaCurdy(A-M)估计模型。Amemiya-MaCurdy 模型仅能在严格平衡面板数据上使用,原数据中共有1192 个样本适用于该回归模型。它将,作为工具变量来代替原H-T 模型中的工具变量X1,i,以增加估计的效率。表5 报告了稳健性检验的回归结果。前4 列各变量的系数与主要回归分析的系数相比普遍较小,但效应的方向基本一致,且在劳动收入和社会医保的变量中都有显著性水平的正效应。A-M 估计模型系数的效应与H-T 模型相似,但除了劳动收入、年龄、性别和教育外,其他都不具显著性水平,且显示了较大的标准差,这主要是样本量有限所导致的。综合以上5 种稳健性检验结果,可以确定主要回归模型的结果是稳健的。

表4 个人劳动收入对心理健康的影响
五、结论与建议
本文主要研究了个人劳动收入和社会医疗保障对健康状况的影响。生理、心理健康指数和自评健康报告均证实了较高的劳动收入对健康状况有正面效应。享有社会医疗保险的劳动者在生理和心理健康方面也均表现出显著的正效应。受教育程度的不同是造成健康差异量级最大的因素;其次,男女性别中的健康情况也呈现较大的显著性差异。生活行为上锻炼频数增加在生理、心理健康方面都有显著的正效应;而城市/农村的居民身份在生理健康方面无显著差异,但在心理健康方面中城市居民表现优于农村居民。计量方法的改进和样本量的扩大,能进一步修正过往文献中存在的选择性偏差和内生性问题。通过整合2010-2018 年间的5个CFPS 数据,形成了覆盖全国的在职劳动者面板数据。使用普通最小二乘法和随机效应往往会高估解释变量的系数,而固定效应的估计结果往往伴随较大的标准差。把Hausman-Taylor 模型运用到实证分析中,可以有效解决健康-收入相互作用下的内生效应,并在回归中保留如性别等的重要非时变变量。
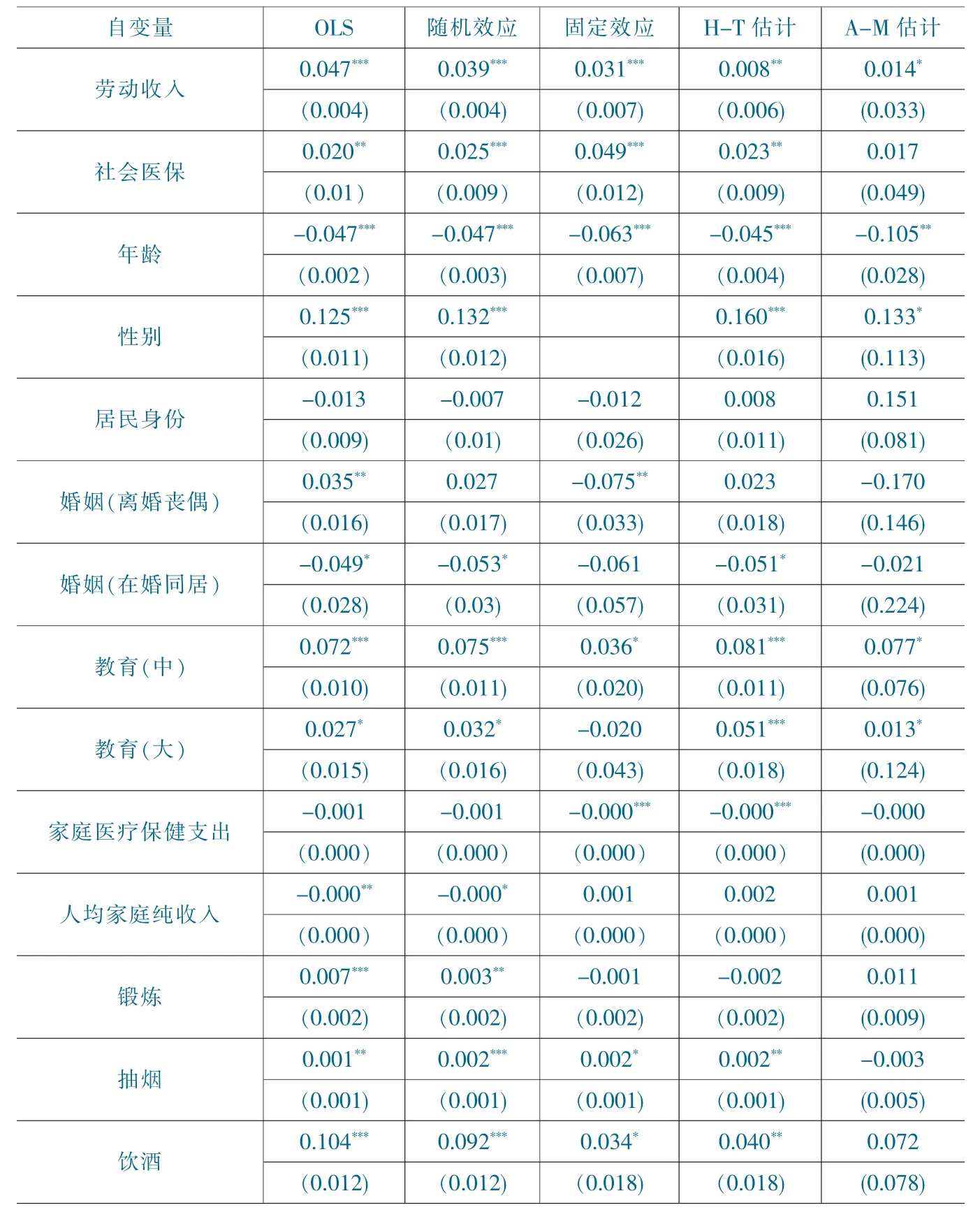
表5 稳健性检验
在新冠肺炎疫情席卷全球的大背景下,个人健康问题再一次引起了社会大众的普遍重视,本文的研究结论具有一定的实践指导意义。为进一步提高社会劳动效率,本文结合个人和社会两个方面给出以下几点建议:
(一)加强社会医保福利的覆盖率
本文研究结果表明,社会医保福利对个人身心健康有显著积极作用。企业应加强自身社会责任意识,确保劳动者能享有社会医保类型中的至少一种医保福利,政府也应在其中对企业加强监督。应把参与医保作为劳动者的基本权益纳入劳动合同中,对未遵守相关规定的企业予以处罚和强制整改[12]。
(二)着重改善低收入者健康状况
健康状况与收入存在显著的相互作用,个体间健康水平的差异会进一步拉大社会贫富差距。政府应充分发挥再分配职能,对经济发展水平较低地区加大财政补贴。通过精准扶贫等一系列政策改善低收入家庭尤其是儿童群体的营养供给[13]。另外,低收入者往往伴随着较消极的生活行为方式[14],公共决策部门应利用各种社会媒介平台,倡导积极健康的生活方式,重视建立精神文化生活,从根源上改变低收入者的健康行为和观念。
(三)提高农村居民的心理健康认知
城市/农村居民身份的收入效应在生理健康上无显著差异体现了农村医疗系统的日益成熟,而心理健康则仍需加以重视。在当今经济的飞速发展下,农村人口,尤其是年轻一代有着较大的流动性,农村社会结构也因此发生了显著的变化[15]。我们需要进一步关注农村居民的心理健康,增强他们对自身价值的认同感,鼓励他们在工作中获得自尊、效能感和自我整合的机会。应加大教育资源的投入,特别是关注农村教育的全方位性。通过提高居民受教育水平,能从根本上改善居民对心理健康的认知,修正讳疾忌医的陈旧思想。
