基于深度学习的自然场景多方向文本检测与识别
2021-03-07王明宇
王明宇
(格拉斯哥大学 英国苏格兰格拉斯哥 G128QQ)
1 背景介绍
自然场景图像的文本检测与识别技术有助于获取、分析和理解场景内容信息,对提高图像检索能力、工业自动化水平和场景理解能力具有重要意义。它可以应用于自动驾驶、车牌识别和智能机器人等场景,具有很大的实用价值和广阔的研究前景。
与以往用于印刷文本的OCR 技术不同,自然场景中的文本检测和识别任务更加困难。复杂的背景使得许多文本很难从背景物体中区分出来。目前的研究通常将自然场景中的文本识别分为两个步骤:文本检测和文本识别。即用视觉处理技术提取中文文本,用自然语言处理技术获取文本内容。这两个步骤密切相关,文本检测结果的准确性直接影响到最终的文本识别结果。因此,本文开发了一个将检测和识别这两个步骤整合在一起的应用,以提高识别的效率。
本文的研究内容主要包括以下三个方面。
(1)结合目标检测的知识,对SegLink 模型进行了分析和改进。利用连接组件的CNN 网络对检测结果进行过滤,提高检测结果的准确性。
(2)针对自然场景文本识别的不足,设计了结合二维CTC 和注意力机制的适应性强的文本识别模型。本文详细介绍了二维CTC的原理以及连接二维CTC 和注意力机制模型的文字识别全过程,并介绍了Encoder-Decoder 模型的详细改进和操作,进一步提高对不规则和倾斜文本序列的识别精度。
(3)通过整合检测和识别框架,设计并实现了一个端到端的自然场景文本检测和识别系统,并对识别效果进行了验证。结果表明,所提出的模型取得了良好的效果。
2 基于SegLink的文本检测
SegLink 是一个深度神经网络文本检测模型,它将一个文本行视为多个文本片段的集合,这些片段可以是一个字符或文本行的任何部分。这些文本片段被连接在一起,形成一个文本行。在SegLink 的基础上,本文提出通过使用CNN 网络对连接部件进行进一步过滤,以提高检测结果的准确性。如图1所示。

图1:SegLink 的网络结构
SegLink 文本检测网络使用一个前馈CNN 来检测文本。给定尺寸为W1×H1 的图像I,该模型输出固定数量的文本片段和连接,根据置信度对其进行过滤,把过滤后的连接作为边,构造为单词边界框。
该网络使用vGG16 作为特征提取网络,从图像中提取特征,其中vGG16 中的全连接层(FC6,FC7)被卷积层(conv6,conv7)取代。受SSD 网络的启发,SegLink 使用3*3 的卷积层为每层的特征图生成预测内容,围绕方框的文本片段为倾斜方框,用S=(xs,ys,ws,hs,θs)表示。每层卷积预测器产生7 个通道的预测内容,其中两个通道分别代表默认方框为文字/大写的概率,并进行softw=Max 归一化,得到文字置信度。剩下的5 个通道代表默认框的几何偏移内容。特征图中某一位置的坐标为(x,y),预测内容中的五个通道的内容(ΔxS,Δys,ΔwS,Δhs,Δθs)用来表示该位置的文本片段。文本片段几何信息的位置是用以下公式确定的。


常数al控制输出文本片段的大小,它根据第L 层接受域的大小决定。
2.1 层内链路
将一对相邻的文本片段连接起来,表示它们属于同一个词,如图2所示。文本片段之间的连接也是由卷积预测器预测的。每个链接有两个分数,一个是正分数,另一个是负分数。正分用来表示这两个片段是否属于同一个词,应该被连接起来;负分表示它们是否是独立的词,应该被断开。每个片段的链接是一个8×2=16 维的向量。这两个通道的值将进一步被softmax 规范化,以获得连接的置信度。
如图2 部所示,黄色方框的邻居是两个蓝色方框,它们之间有一条连接线(绿线),表明它们属于同一个词。

图2:层内链路和跨层链路
邻居的归一化定义为公式(6)。
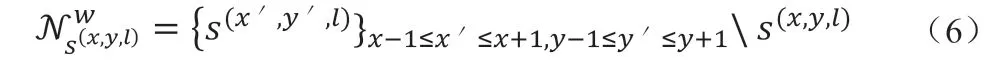
2.2 跨层链路
在这个网络中,同一个词可能在不同的层被检测到,每个卷积层在一定的尺度范围内智能处理词。为了解决重复检测的冗余问题,引入跨层连接。跨层连接可以将在两个特征层检测到的具有关联性的文本片段连接起来。该公式定义如下。

每个文本片段都有4 个跨层连接,这是由两层特征图像之间的长度、宽度和倍数关系保证的。同样,跨层连接也是由卷积预测器预测的,它输出8 个通道的值,用于预测当前文本片段和4 个跨层连接段之间的连接关系。对每2 个通道进行Softmax 归一化,以产生置信度分数。
跨层连接允许连接并合并不同大小的文本片段。与传统的非最大抑制算法相比,跨层连接提供了一种可训练的冗余连接方式。
图3 展示了卷积预测器的输出通道,它由一个卷积层和一个Softmax 层实现。

图3:卷积预测器的输出通道
2.3 结合Segments和Links
如图4所示,测试网络最终会产生一系列的文本片段和链接,按照置信度进行排序和过滤,α 和β 分别代表片段和链接的阈值(通过网格搜索发现这两个值是最优的)。将每个片段视为节点,链接视为边,建立图模型,然后用DFS(深度优先搜索)来寻找连接成分,每个连接成分就是一个词。然后再把输出的词一起融合在box 中。

图4
算法1 实际上是一个平均化的过程。首先,计算出所有片段的平均θ,作为词的θ。然后,以得到的θ 为给定条件,找到最有可能通过每段的线(线段)。以线段的中点作为Word 的中心点(x,y)。用所有线段的平均高度作为字的高度。
2.4 Char-CNN
SegLink 在窗口层面对图像进行操作,但是在文本链接组件层面没有特征约束。因此提取的候选文本对象不一定完全是文本,有时可能是一些具有类似整体文本特征的非文本区域。在此基础上,我们通过对提取的文本候选区域使用基于CNN 的字符级过滤算法来改进SegLink 网络,进一步排除非文本候选区域,从而提高图像中文本检测的准确性。
具体来说,首先对SegLink 提取的字级文本进行MSER 区域检测,并将检测到的MSER 区域的最大边界框作为字符的边界框,从而将字分割为字符级的候选文本。然后,将分割好的候选字统一调整大小,作为CNN 分类器的输入,并进行评分,得到每个候选字的字符文本置信度。在此之后,对同一单词分割得到的所有候选字符使用非最大抑制算法,得到一个单词中所有字符的平均得分,作为该单词的文本置信度,并将置信度低于一个阈值的词过滤掉。如图5所示。

图5:Char-CNN 结构
3 基于连接二维CTC和注意力机制的文本识别
与A4 纸上的印刷文字不同,自然场景中的文字多为空间排列不规则、噪声较大的文字。虽然CRNN+CTC 的收敛速度较快,但CRNN 存在解码信息缺失的问题,并且CTC 模型要求的特征序列高度为限制了识别能力。基于Attention 机制的sequence to sequence模型收敛速度慢,但准确率比CRNN+CTC 模型高,但它也有缺陷。基于注意力机制的序列到序列模型在一定程度上对自然场景中的英语有较高的识别率。但对自然场景中的中文的识别效果并不理想。为了解决上述问题,本文提出了一种基于连接二维CTC 的序列和注意力机制的文字识别模型。
3.1 2D CTC
二维CTC 消除了背景噪音的影响,可以自适应地关注空间信息。它还可以处理各种形式的文本实例(水平、定向和弯曲),同时给出更多的中间预测。对于二维CTC,在路径搜索中增加了一个额外的维度:除了时间步长(预测长度)之外,还保留了高概率分布。它确保所有可能的高路径都得到考虑,不同的路径选择仍可能导致相同的目标顺序。
二维CTC 也需要在高度维度上进行归一化。一个单独的SoftMax 层产生了一个额外的形状为H×W 的预测路径转换图。概率分布和路径转换被用于损失计算和序列解码。二维CTC 继承了CTC 的对齐概念。与一维CTC 相比,二维CTC 实质上是将高度转化为大小,从而缓解了信息丢失或连接的问题,为CTC 解码提供了更多的路径。
3.2 连接二维CTC和注意力序列机制的模型
基于二维CTC和注意力机制的文本序列识别框架分为两部分。编码部分由一个卷积神经网络和一个多层双向LSTM 组成,负责将图像转换为特征序列。解码部分由一个结合了二维CTC 和注意力机制的序列-顺序模型组成。在基于注意力机制的序列-顺序解码中,所有的特征都以语义C 为中心,并为每个特征计算出注意力权重。解码过程的计算方法如下。

其中h I 和j 代表第i 个关系中JTH h 的编码特征向量,代表由平滑归一化函数处理的权重参数,e代表注意力的权重,g代表h I,j和的线性变换。最后,生成下一个状态s 和下一个标签y。

在这一点上,注意力损失函数的计算公式为:

其中y*t-1 是第一个t-1 标签序列。
该模型的思路是在多任务学习框架下,用二维CTC 目标函数作为辅助任务来训练注意力模型编码器。与注意力模型不同的是,CTC 的前向-后向算法可以实现语音和标签序列的单调对齐,而且CTC 要求的特征序列高度为1,不能考虑空间信息,而二维CTC可以考虑文本的空间信息。模型的损失函数的计算方法是:
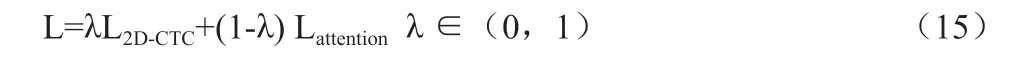
4 自然场景文本检测与识别系统
该系统使用Python 语言开发,实现了基于SegLink 改进和二维CTC 连接关注机制的端到端文本检测和识别。
自然场景图像文本识别模型的处理流程包括文本检测、文本处理和文本识别。系统检测到图像输入后,首先检测文字区域并画出文字框,然后切出文字区域进行水平统一处理,并将其转换成灰度图像。然后,将校正后的文本图像输入到文本识别网络模型中进行识别,最后输出识别结果。
该系统的主界面如图6所示。系统的各个功能模块都可以在主页上直观地找到。通过网络交互,系统简单明了。通过系统的界面,直接选择要上传的图片。系统的文字识别功能模块如图7所示,对文字区域进行检测和识别,并在右侧输出结果。图6 是没有上传图像时的系统主界面。图7 展示了识别结果的例子。

图6:系统主界面
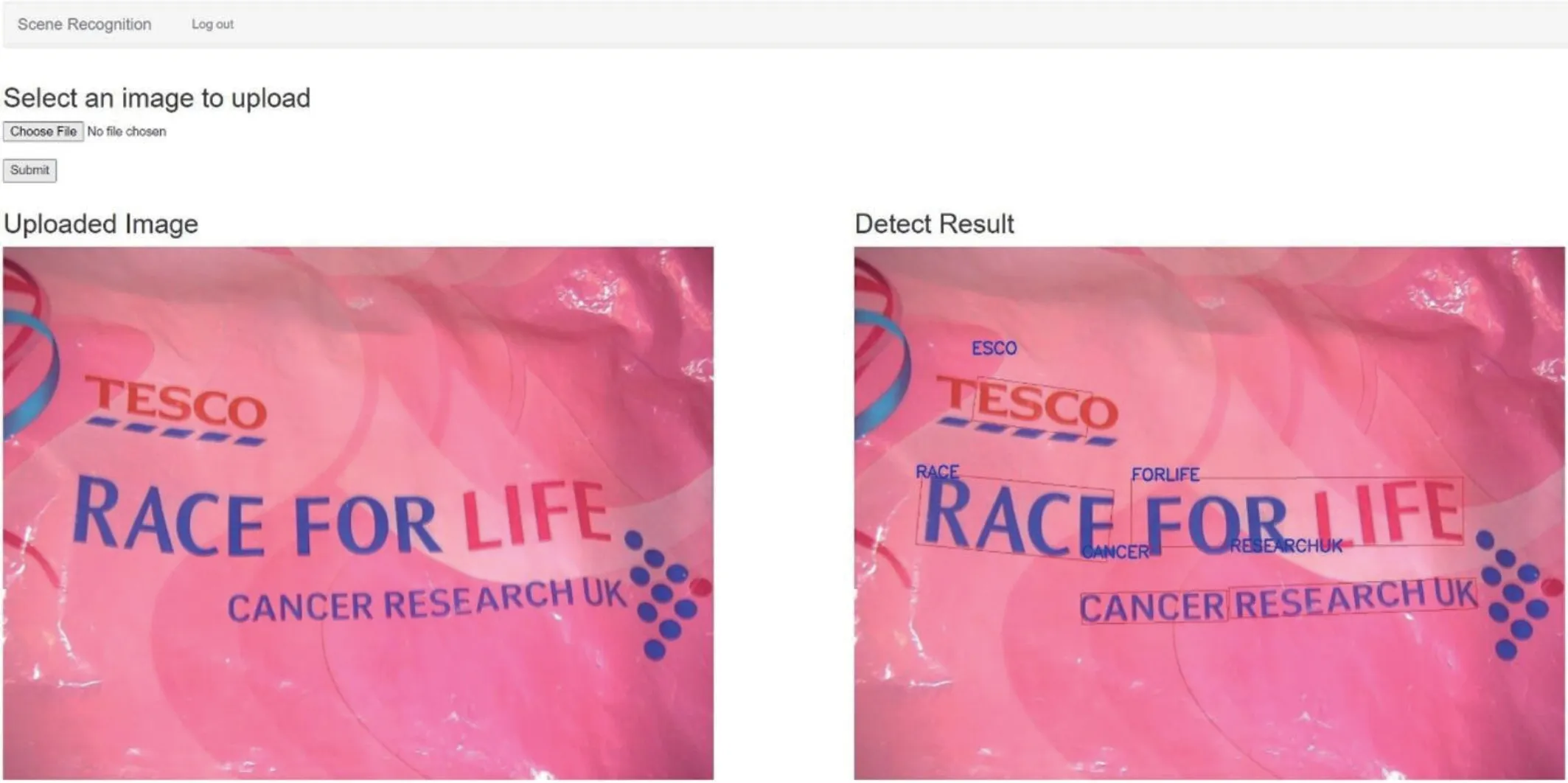
图7:识别结果界面
5 结论
在文字检测方面,通过增加CNN 网络的连接部件的滤波器,改进了SegLink 模型,提高了检测结果的准确性。在文字识别方面,针对自然场景文字识别的不足,设计了一个结合二维注意力机制和CTC 的文字识别模型,具有较强的适应性,进一步提高了不规则和倾斜文字的识别精度。结合上述两项相关工作,将该框架整合并扩展为一个端到端的识别系统。该系统的实现简单高效,在水平和多方向的文本数据集上有很好的表现。目前的文本检测和识别只能达到识别和感知。对于场景文本识别,基于深度学习的文本检测和识别的最终目标是排版、存储和分析图像文本内容。由于本人在自然场景文本检测和识别的技术领域的研究和学习还不够深入,有很多需要改进的地方,因此提出了两点建议供大家进一步参考。
(1)本文提出了一个统一的检测和识别系统,对倾斜和弯曲的文本取得了良好的效果。但是,自然场景中仍然存在较大的噪声和相对变形的形状。今后将对文字弯曲变形的检测进行改进。
(2)虽然本文提出的端到端识别模型具有良好的效果,但由于计算机配置有限,识别时间较长,今后将进一步开展工作,缩短检测和识别时间。
