表生地球化学数据库及大数据研究进展
2021-03-05许义江李成龙谈昊林盛雪芬
许义江,李成龙,谈昊林,盛雪芬
表生地球化学教育部重点实验室,南京大学 地球科学与工程学院,南京210023
1 前言
随着科学技术的发展,科研数据量飞速增长,传统的计算分析手段和依赖经验的研究范式已经越来越显示出其局限性。大数据可以全方位地、动态地呈现事物的发展过程,探明各种因素间的相关关系,从碎片化的海量数据中恢复事物的全貌,这将促成并推动科学家思维方式从逻辑思维向由数据驱动的关联思维转变(Lynch, 2008; 周永章等,2016; 翟明国等,2018)。大数据正在掀起一场科研革命。
地学大数据是一种时空信息大数据。时空信息是地学数据的一个基本属性,广泛产生于地球物理、地球化学、遥感传感以及原始数据的解析、模拟等地学相关的研究活动中。世界各国的地质调查数据库和专题性的地学数据库以及相应科研工作均提供了海量数据,并且这一数据量仍在与日俱增,但其共享性整体上相对较为薄弱(张颖慧等,2020; 李秋立等,2020; 齐浩等,2020),该现状为开展相应的大数据研究提供了机遇与挑战。
大数据分析技术及其观念在地球科学领域的深入应用越来越得到重视,地学研究与大数据技术的结合已取得了重要的成果。例如Slessarev等(2016)对60291份土壤pH数据进行随机抽样,证实土壤pH存在从酸性向碱性突变的阈值,且该阈值与年降水量和年潜在蒸发量的差值有关,降水和蒸发通过影响成岩矿物(以碳酸钙和三水铝石为主)的溶解、搬运过程进而影响土壤pH; McKenzie等(2016)以碎屑锆石作为岛弧火山活动的指标,发现百万年时间尺度上岛弧火山作用活跃性与冰室—温室气候变化有直接相关性,揭示了地球内部作用与气候的关联性。除了数据量的增加,大数据分析技术、可视化手段也逐渐引入地学研究中,例如和弦图、热图、网状分析等技术应用于矿物共生、共同演化关系的分析(Hazen et al.,2019);Fan等(2020)采用约束优化算法(constrained optimization,CONOP)重建了古生代海洋无脊椎动物物种演化史,将时间精度提高至26±14.9 ka,进一步的相关性分析显示海洋无脊椎动物物种多样性演化与大气CO2分压变化具有一致的长期趋势。
表生地球化学是研究地球表层系统物质的化学组成、化学作用和化学演化的地球化学分支学科。狭义的表生地球化学(Supergene Geochemistry)指表生成矿地球化学,主要研究常温富水环境下岩石的改造和次生矿物的形成、富集;广义的表生地球化学的研究范畴十分广泛,包括从表生地球化学动力学、大陆风化、微生物作用、有机质的演化和早期成岩到气候演变、农业生产、矿床表生演化模式等,涉及自然地理学、土壤学、微生物学、植物学、地质学、环境科学和气象科学等多学科的深度交叉融合(马民涛等,1994; 王瑞廷等,2002)。本文所提的表生地球化学为后者,即将地球作为一个完整的系统,集各个学科之所长,是进一步深入理解地球物质演化、全球气候变化等前沿问题的必要研究领域。表生地球化学所研究的对象及内容可为深时地球科学研究提供“将今论古”的地球化学领域的各类指标以及其理论模型的现代检验,因此也与地层学、古生物学、沉积学等学科有着密切关系,是联结过去—现在—未来的纽带。因此,表生地质作用是地球系统中最复杂、活跃的地质作用过程。其研究范围远超内生地质作用所局限的岩石圈,涉及水圈、大气圈、生物圈和岩石圈之间的相互作用。区别于内生地质作用体系,表生环境具有低压和低而速变的温度、富氧和充足的二氧化碳、开放的过量水、生物和有机质参与、胶体体系发育五大特征(王瑞廷等,2002)。不同因素作用的相互耦合、拮抗构成了表生作用过程复杂的“暗箱”,而地球化学指标则是开启这一“暗箱”的“钥匙”。因此,近年来越来越多的学者开始关注碳循环、氮循环等的深地过程与表生环境变化的关联(Hartmann et al., 2017; Liu et al., 2019; Cannaòa et al., 2020)。
表生地球化学数据大体可划分为两大类,一是对各种地质样品进行直接测量得到的原始数据,主要包括岩石、土壤、水体、生物体和化石等地质载体中的元素、同位素、化合物含量及其它地球化学指标的分布特征;二是与原始数据相对应的解释数据,例如地质体的产状、环境温度、湿度、压力、大气CO2分压、pH值、Eh值及水动力学条件等,以及其相应拟合关系、模拟结果等。地质样品的地球化学特征往往是多要素综合作用的结果,而诸如大气CO2分压、水体氧化—还原条件、温度等环境因素也具有多种基于不同理论假设的地球化学指标体系,这种双向的一对多的映射关系使得地球化学数据呈冗余的结构。此外数据格式上有文本、图像、视频、表格等多种表现形式,而且绝大多数数据目前并不具有统一的质量控制标准,如何组织数据结构、确立怎样的标准将成为表生地化数据库建设的一大难点。
表生地球化学由其研究问题的多样性决定了数据的多元性。丰富的数据来源和庞大的数据量十分适于使用大数据技术进行分析,而其多学科融合的特征在某种意义上也决定了相应学科的大数据研究现状(数据量、质量等)将成为应用大数据解决具体科学问题时的短板。此外,随着新的地球化学技术手段不断发展成熟,例如非传统稳定同位素的测试技术、校正方法的更迭,也给表生地球化学数据的整合研究提出了如何评估数据质量、统一新旧数据等问题。
2 表生地化数据库现状
根据数据结构性特征,表生地球化学数据可分为两大类。一是结构化数据,这些数据大多来自国际性或国家地区研究机构(如各国地调局)的相应科研计划成果,具有高度统一的结构化特征,往往以图层或表格形式呈现,并遵循便于使用、追索、引用的开放策略,数据质量高而被多数研究者引用,是相对成熟的、具有权威性的数据来源;另一部分为长尾数据,主要指分散在海量文献中的半结构化、非结构化数据,数据独立性高。虽然部分数据库对已发表文献数据进行收录、汇总,但不同文献的数据格式不一致,需要进一步的整合、标准化才可应用于大数据分析与信息挖掘中。同时表生地化数据库呈多元化特征,按研究对象可进一步分为海洋地化、环境地化、考古学、全球变化科学等专题(表1),不同的数据库存在不同的研究目的,基于这些目的数据的元数据、数据标准等也存在很大差异,需要进一步识别。
2.1 地球化学标准物质数据库GeoReM
GeoReM 数据库(Max Planck Institute for Chemistry Mainz, Germany, 2020-11)是由马克斯·普朗克研究所(Max Planck Institute)开发和维护,用于存储具有一定地质和环境意义的标准物质的测试值,例如USGS和NIST等机构的岩石粉末、矿物、同位素标准溶液、生物样品、河水和海水等标准样品测试数据,是EarthChem数据库的有机组 成(Jochum et al., 2005;Jochum et al., 2009)。 GeoReM包含来自约11340篇论文3500种标准物质的50410种分析(截至2020年11月;包括主量元素和痕量元素浓度和质量分数,放射性同位素和稳定同位素比等地球化学组成数据),以及有关分析值的重要元数据,例如不确定性、分析方法和测试实验室等,同时还提供标准物质的信息和优选整合的参考值(如图1),是地球化学指标测试和分析的重要参考源。
GeoReM的数据主要来源于已发表文献,由作者录入相关信息并经过审查后收录于数据库中。虽然其数据结构简单,但却抓住了地球化学数据的核心—数据可靠性,围绕这一点设计出简明扼要的数据登录表(http://georem.mpch-mainz.gwdg.de/GeoReM-Example.xls),对测试项目、测试仪器、测试值及不确定性等信息进行收集归纳。除了标准物质测试数据的实际整合需求外,数据库使用、录入的便捷性也是该数据库数据量不断增加的保证。GeoReM的数据结构在地球化学测试的数据库建设中具有一定的实用性。
2.2 地球科学综合数据库:以PANGAEA为例
以PANGAEA为代表的综合性地学数据库的发展,多经历从单一专题数据库逐渐壮大的历程,其一般起步早,发展力量较为雄厚,涵盖的数据量丰富,数据库扩展功能完善,在数据标准、运行模式等方面有着丰富的建设经验。
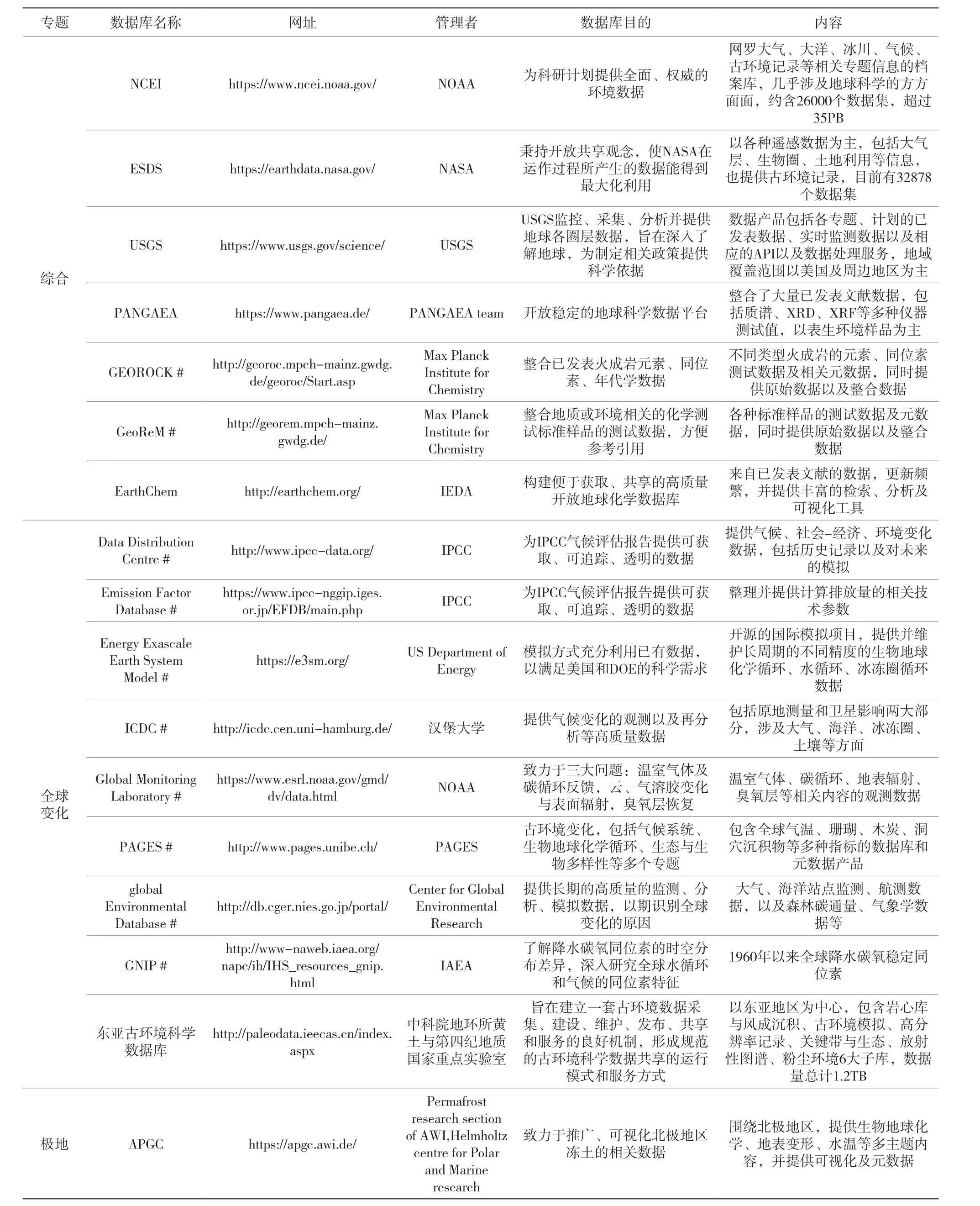
表1 部分表生地化数据库简要信息表(#指代结构化)Table 1 Brief information of several Surficial Geochemistry database (# represents owing structured identity here)
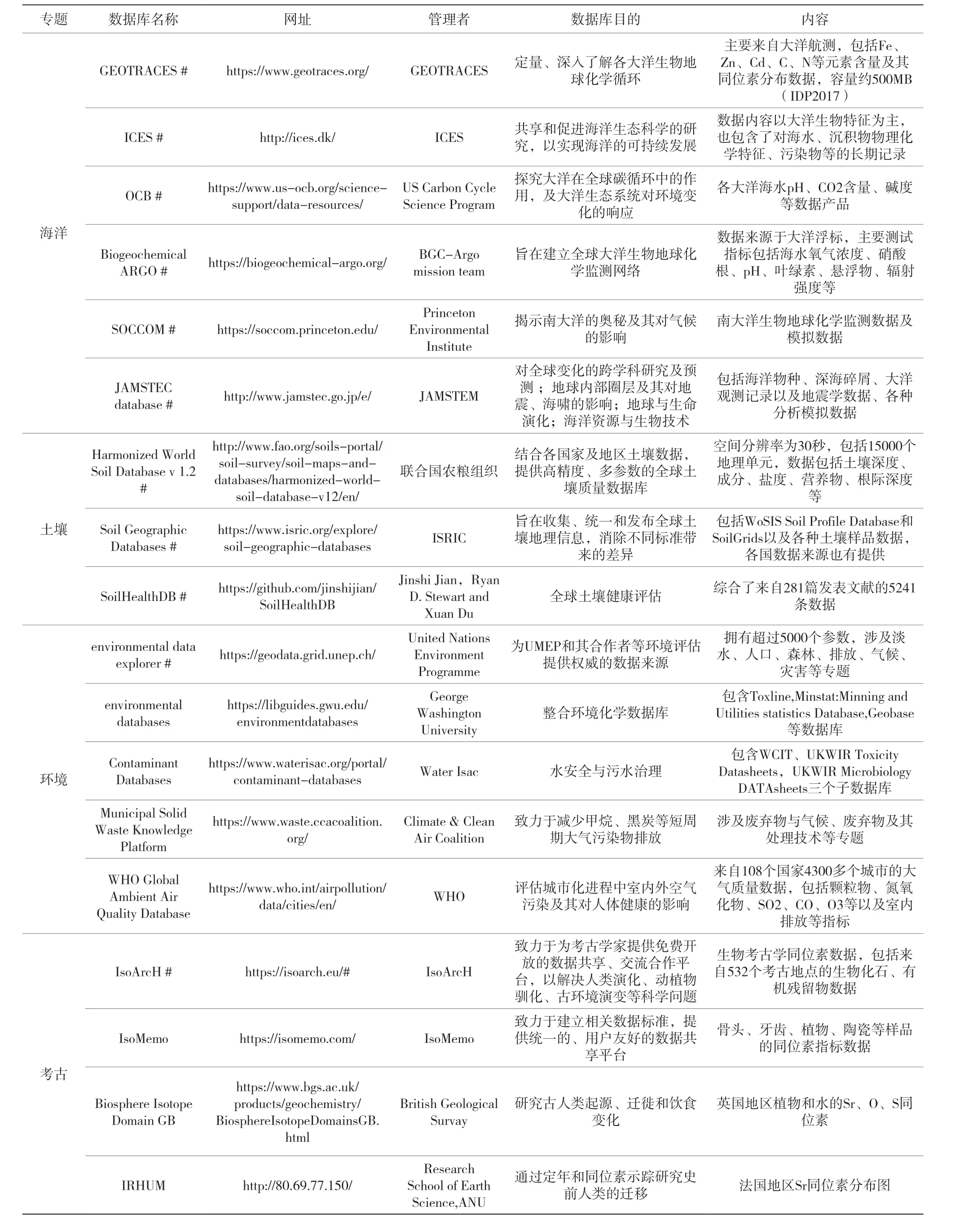
续表1
PANGAEA(Alfred Wagener Institute and Centre for Marine Environmental Sciences,University of Bremen,2020-11)信息系统是一个对任何组织和个人开放并保证长期运行的地球科学数据库,旨在归档、发布和分发地球系统研究的相关数据(Grobe et al, 2006)。只要遵守数据集中的许可条款,就可以在登录后免费下载并使用数据集,每个数据集的描述始终可见,并支持以数字对象标识符(DOI)来标识、共享、发布和引用所需数据。PANGAEA还允许将数据作为科学文章的附件(示例),或者与ESSD、Geoscience Data Journal、Scientific Data等数据期刊相结合,作为可引用的数据集进行发布。

图1 GeoReM数据库中BHVO-2标样数据展示(以Fe为例)示例图(Klaus,2006)Fig. 1 Search result for analytical data (specifically Fe) in the USGS reference sample BHVO-2
目前PANGAEA收录有来自477个研究计划、399283个数据集、超过170亿条测试数据(https://www.pangaea.de/about/, 截至2020年11月),涵盖化学、海洋、岩石圈、生物分类、大气、古生物、生态学、生物圈、地表环境、地球物理、冰冻圈、湖泊与河水、人类活动等专题,并支持根据作者、发布时间、具体项目、测试方法、地理位置等参数对数据进行筛选。为了对数据进行标准化,PANGAEA设计了一个基于采样流程的关系型数据结构,通过将原始数据划分为项目信息、采样行动信息、实地测量数据以及样品分析数据四个层次分别录入相关信息,以便于数据的管理、更新和使用(Grobe et al., 2006)。但由于该数据库注重于数据共享,并没有进一步整合,数据内容相对较为分散和多样。
PANGAEA数据库可确保数据的完整性和真实性以及高可用性。归档的数据可供机器读取,并镜像到其数据仓库(data warehouse)中,从而提高数据编译速度。PANGAEA提供了多种数据处理工具,其中数据仓库可用于高级检索,实现对整个数据连续体中任何测量参数上的时间片或表面数据矩阵进行高效的检索和编译,并开放相应API;提供了基于Python 3和R语言的数据、元数据检索和分析工具pangaeapy(https://github.com/pangaea-data-publisher/pangaeapy) 和pangaear(https://github.com/ropensci/pangaear)作为开源库和插件,以实现PANGAEA无法直接满足的数据处理需求;以及与PANGAEA信息系统相结合的数据可视化工 具BSRN toolbox(Baseline Surface Radiation Project;Holger et al., 2019)。
2.3 海洋地球化学数据库:以GEOTRACES为例
海洋科学研究领域是科研全球化的一个典型代表,围绕国际联合科学考察计划产生了一系列优质的海洋地球化学数据及其数据库,如国际大洋钻探(鲁铮博等,2020)、GEOTRACES、Biochemical Argo等,这些数据库通过长期的观测以及样品资料,不断推进对海洋物质循环的认识。
GEOTRACES(Scientific Committee on Ocean Research, The International GEOTRACES Programme, 2020-12)是一个专攻海洋生物地球化学的国际性研究计划,旨在揭示关键痕量元素及其同位素在海洋的分布、循环过程,主要指标参数包括Fe、Zn、Cd、Cu等营养元素,Al、Mn、δ15N等指示现代过程的指标,易受人类活动影响的污染物元素如Pb,以及231Pa、230Th、Nd同位素等古环境重建指标,极大地填补了海洋生物地球化学循环领域的数据空白。约有来自35个国家的科学家加入了这一计划,他们计划将在未来十年初步探明全球所有大洋盆地,并在大洋水气及水岩界面反应及通量、大洋内循环、全球变化指标三大领域研究中取得突破。除了相应科研成果的展示,GEOTRACES团队在社交平台twitter上也保持着频繁的更新,利于科学影响力传播。
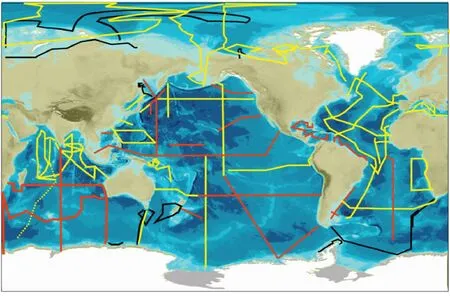
图2 GEOTRACES数据截面分布: 红色代表计划中,黄色代表已完成,黑色代表GEOTRACES对IPY(International Polar Year)的贡献(https://www.geotraces.org/about-geotraces/)Fig. 2 GEOTRACES sections: red-planned sections, yellow-completed sections, black-completed as GEOTRACES contribution to the IPY (International Polar Year)
GEOTRACES数据主要来自遍布全球的航测(图2)以及对水样的多种指标测试,最终以四年更新一次的intermediate data product(IDP)形式产出。IDP主要包含两大部分,一是原始电子数据(https://webodv.awi.de/geotraces),包含来自超过39次航测、1800个站台的测试结果,基本覆盖全球大洋,其中大西洋数据点密度最高,并提 供ASCII、Excel、NetCDF和ODV(Ocean Data View software)4种格式进行下载,同时提供数据来源、测试方法、发布文献等相关信息的查询;二是数据可视化工具eGEOTRACES Electronic Atlas(http://www.egeotraces.org/)可提供基于相关数据制作的各项化学指标分布图、3D动画。目前GEOTRACES已公布IDP2014(Mawji et al., 2015)、 IDP2017(Schlitzer et al.,2018)两款数据产品,并计划于2020年12月15日发布IDP2021。其中第二版数据产品IDP2017内容上囊括了2014版原有数据,并添加了太平洋和南大洋的相关元素、同位素数据,并首次提供相应的生物数据。此外GEOTRACES还鼓励上传共享数据(DOoR Portal),并规范了相应的数据标准、测试方法等内容(https://geotracesold.sedoo.fr/Cookbook.pdf)。
2.4 全球变化科学数据库:以PAGES为例
全球变化是研究地球系统整体行为的一门科学,通过探索地球系统的过去、现在和将来的变化规律及其控制因素,从而建立全球变化预测的科学基础,并为地球系统的管理提供科学依据,与人类文明发展息息相关。近年来全球变化科学数据量与日俱增,仅“全球变化科学研究数据出版系统”2019年出版数据文件就达71.72 GB,下载量达553.43 GB(石瑞香等,2020),但同时这种大规模数据录入也带来了数据质量控制、知识产权、数据共享积极性等问题。
而PAGES(University of Bern, Switzerland, 2020-11)数据库在解决这些数据问题、推进全球变化研究上,迈出了关键一步。PAGES是由瑞士科学院和中国科学院联合资助的国际合作项目,旨在协调和促进全球变化研究,深入了解地球过去环境变化,以更好地对未来气候和环境进行预测,为可持续性发展提供战略科学依据,其研究范围包括从上新世到近千年的不同时间尺度上的气候系统、生物地球化学循环、生态系统过程、生物多样性和人类活动影响等诸多方面。PAGES的科学结构将地球系统的关键带中的科学问题划分为气候,环境和人类活动三大主题,而三者之间又存在4个主要联合内容:数据管理、全球变暖、阈值与极端事件(http://pastglobalchanges.org/science/intro)。这一科学结构主要依赖工作组机制维持。工作组为具有共同研究方向的科学家提供了跨领域交流合作的平台,并以解决单一力量难以解决的具体科学问题为目标,制定和执行以3年为周期的研究方案。PAGES欢迎并鼓励更多专家学者加入,并组建相应工作组(图3)。
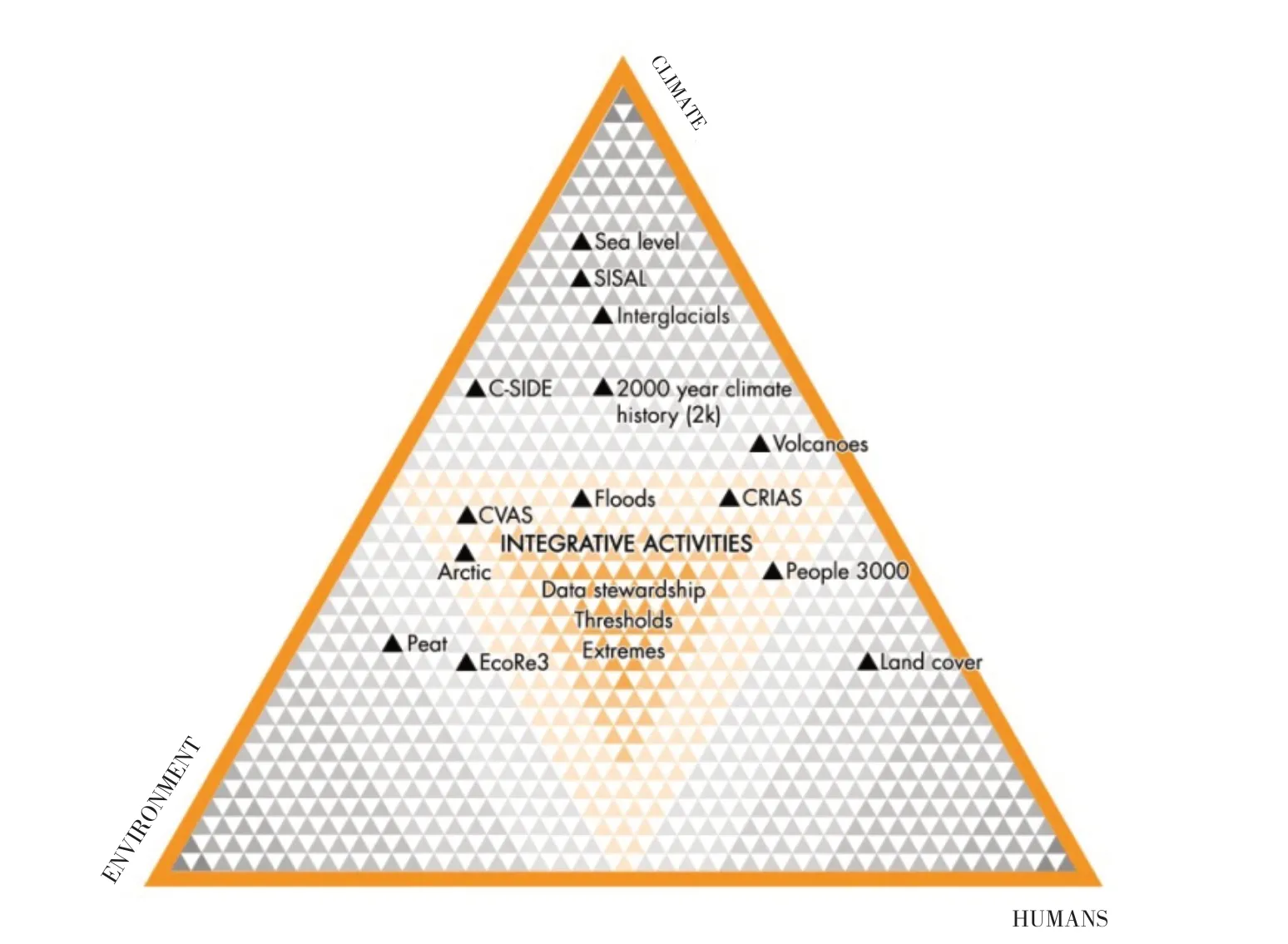
图3 PAGES的科学结构:由气候—环境—人类三大主题组成,及各主题交叉融合背景下的各个工作组(表2)(http://pastglobalchanges.org/science/intro)Fig. 3 Science structure of PAGES, which is composed of climate-environment-human, and the interactive working groups (Table 2)
作为一个活跃的科研团体,PAGES成果卓著,在全球变化科学领域积累了大量数据,数据主要来自所属工作组发表的文献、会议报告和宣传材料等成果,更新频率很高(University of Bern, Switzerland, 2020-11)。其中还有一些专题工作组致力于整合构建大型数据库,其中包括不同时期全球及地区气候参数如温度、降水,不同地质载体的元素、同位素组成等(表2)。其中SISAL工作组实现了洞穴次生碳酸盐碳氧同位素数据从非结构化向结构化的转变,具体将在后文介绍。

表2 PAGES所属工作组大型数据库成果(http://www.pages.unibe.ch/data/databases)Table 2 List of larger data-compilation of PAGES working groups(http://www.pages.unibe.ch/data/databases)
3 表生地球化学结构化数据库建设经验:以SISAL洞穴次生碳酸盐数据库为例
表生地化结构化数据库以GEOTRACES为代表,所涵盖的数据一般是大型科研项目的成果,来源集中,数据标准统一,元数据完整,并有较为丰富的扩展功能,但一般更新较慢。而更新迅速的、相对小型、独立的科研成果占有很大比重。即使有一些数据库如PANGAEA、USGS、东亚古环境科学数据库等进行了收录,但由于不同数据来自不同仪器分析、不同模型拟合,缺乏统一的比对标准或者缺少相应标准所需的元数据,数据之间的不相容性、独立性,阻碍了数据资源的再利用。因此将这些长尾数据统一整合为结构化专题数据库将是表生地球化学大数据建设的重点。以下重点介绍全球变化领域数据库建设比较完善的洞穴次生碳酸盐结构化数据库的建设经验。
3.1 洞穴次生碳酸盐数据
洞穴次生碳酸盐主要包括石笋和钟乳石等,是由自然界水体中的碳酸盐在地下洞穴系统迁移过程中饱和而不断沉积堆积形成的碳酸钙沉积物,常见于喀斯特地貌区。由于其形成往往具有成层性并且适宜U系定年,是研究古气候变化、重建古降水、古大气循环尤其是高精度、短周期气候事件的天然优质地质载体。在洞穴次生碳酸盐各项地球化学指标中,碳氧稳定同位素的应用最为常见,其中石笋氧同位素组成往往与降水量、降水氧同位素或者温度相关(McDermott, 2004; 汪永进等, 2016; 程海等, 2019)。
洞穴次生碳酸盐分布广泛,研究工作开展较早,尤其是近年来高精度U-Th定年技术以及高分辨率采样手段的发展,研究工作日益细致,积累了超过700多篇文献的相关数据,使得在不同地域、不同时间尺度上探究洞穴次生碳酸盐的形成机制及其反演的气候变化信息成为可能(Wong et al., 2015)。但由于已发表的文献数据并不具有相同的、标准化的表述形式以及完整准确的元数据,即不具有结构化特征,因而无法直接从更大时空尺度上进一步发掘这些数据中的信息。NOAA(National Oceanic and Atmospheric Administration)世界数据中心的古气候计划曾对196份洞穴同位素数据进行整合统计,并在较长一段时间内作为相关研究的数据源,但由于缺少判断数据不确定度的元数据或关键数据,难以保证数据质量,阻碍了进一步的数据筛选、分析研究(Comas-Bru et al.,2019)。
3.2 SISAL概况
SISAL(Speleothem Isotope Systhesis and Analysis)成立于2017年,是PAGES所资助的国际性工作组(University of Reading, University College Dublin, 2020-11),负责整合已发表的洞穴次生碳酸盐的碳氧稳定同位素组成记录、年代学记录等相关数据,为气候重建和模型评估提供准确可靠的数据。在经过版权所有者授权或者加盟后,SISAL工作组对已发表数据进行整合标准化,补足了缺失的关键数据以及元数据,并分别于2018年和2020年发布了两版数据库(Atsawawaranunt et al., 2018;Comas-Bru et al., 2020)。2020版(SISALv2)数据库相比于2018版(SISALv1),除了增加数据实体的量,纠正之前存在的一些数据错误,还为现有数据实体补充了如洞穴海拔等有助于深入研究的信息,并且新增、补充了503个记录中原先缺失的年龄—深度模型,使得不同的洞穴次生碳酸盐可在同一年代学体系下进行对比。SISALv2包含了来自673份独立的洞穴次生碳酸盐记录以及18份来自293个洞穴拼合的样品数据,具有不同时间分辨率,共计35396条氧同位素数据、200613条碳同位素数据,基本覆盖了除南极洲外各大洲,但地区分布差异较大,具体表现为亚洲、中东地区的数据分别仅涵盖64.8%和42.3%的已发表数据;而时间跨度上包含了末次冰期、冰消期、全新世、近2000年等不同时间段,且普遍定年精度在100至1000年之间。
3.3 质量控制模式
SISAL对数据质量控制由构建严格完善的数据录入流程以及全面完整、可追溯的数据库结构双重机制共同保证。数据由原作者或相关方面的专家经原作者确认后整合录入,录入人会登记在实体表中以便日后追索更正;每条数据都有专人审查是否符合统一规范,并在入库前由Python小程序检查每一项是否符合录入格式要求;SISAL通过预先设定录入格式和相关名词列表以消除数据的歧义性;审查阶段同时会核实空值数据是否为原数据缺失导致。录入流程保证了数据结构的统一以及内容的可溯源性。
SISAL数据库按不同的洞穴系统进行划分(Atsawawaranunt et al., 2018; Comas-Bru et al., 2020),以15张数据表为基本组成单位,不同数据表通过相应的ID进行链接,并以主体表为核心分别对地点、样品信息、定年信息、纹层定年信息、沉积间断、不同石笋的拼合信息、原始年代学数据、标准化年代学数据、δ13C、δ18O、数据来源、联结关系、附注等进行准确地描述(数据结构如图4所示),表格的每一项内容都有严格的描述、格式要求。诸如洞穴形状、样品距入口距离等反应周围环境信息也得到归类记录,这些信息在衡量洞穴温度是受空气对流还是基岩热扩散控制有着重要参考价值;同样洞穴次生碳酸盐样品的地球化学、矿物相等指标也是判断U-Th数据可靠性的重要参数,因而得到准确核实记录。正是这些数据的追加使得相应数据的筛选和分析更加精确可靠,避免在应用过程中由于数据选择的偏差而得出错误结论。数据格式有两种,分别为关系型MySQL数据库格式文件以及包含15个CSV数据表格的压缩包文件,两者都可以实现基于R或Python语言的程序对数据进行进一步刷选、加工、分析,保障数据关系及其可扩展性。由于定年手段、年龄模型的差异以及原始文献年代学数据不确定度的数据缺失,大大减小了SISAL数据库的可靠性和应用价值。为了解决这一问题,SISAL工作组在补充原始数据元数据的基础上开发和评估了linear interpolation、linear regression、Bchron、Bacon、OxCal、COPRA、StalAge这7种基于不同假设前提的时间—深度模型(Comas-Bru et al., 2020),为数据整合提供了统一的年代学标尺。

图4 SISALv2数据库结构(Comas-Bru et al, 2020)Fig. 4 The structure of the SISAL database version 2
SISAL数据库的建成和完善离不开工作组有关专家的研究热情和努力。SISAL工作组由负责统筹规划的核心领导小组和负责不同地区工作的区域联系人两部分组成,并向任何对相关研究感兴趣的学者开放。来自20多个国家的超过100名成员通过定期(线上和线下)会议参与数据库建设,交流并推进洞穴次生碳酸盐同位素研究蓝图式发展。在阶段I(2017~2019年)完成了对洞穴次生碳酸盐同位素数据的初步整合及年代学数据的标准化,并利用相关数据取得了丰硕的研究成果(http://www.pages.unibe.ch/science/wg/sisal/products)。而在阶段II(2020~2023年)除了对数据库的补充完善,SISAL工作组还将针对洞穴环境监控长期数据(cavemonitoring.org)、痕量元素等指标的潜在应用以及基于洞穴次生碳酸盐数据的气候重建模型三个方面开展下一步工作,深入了解洞穴小环境与地球系统的耦合关系。以此来看,正是研究需求推动着SISAL数据库的发展完善。
3.4 应用
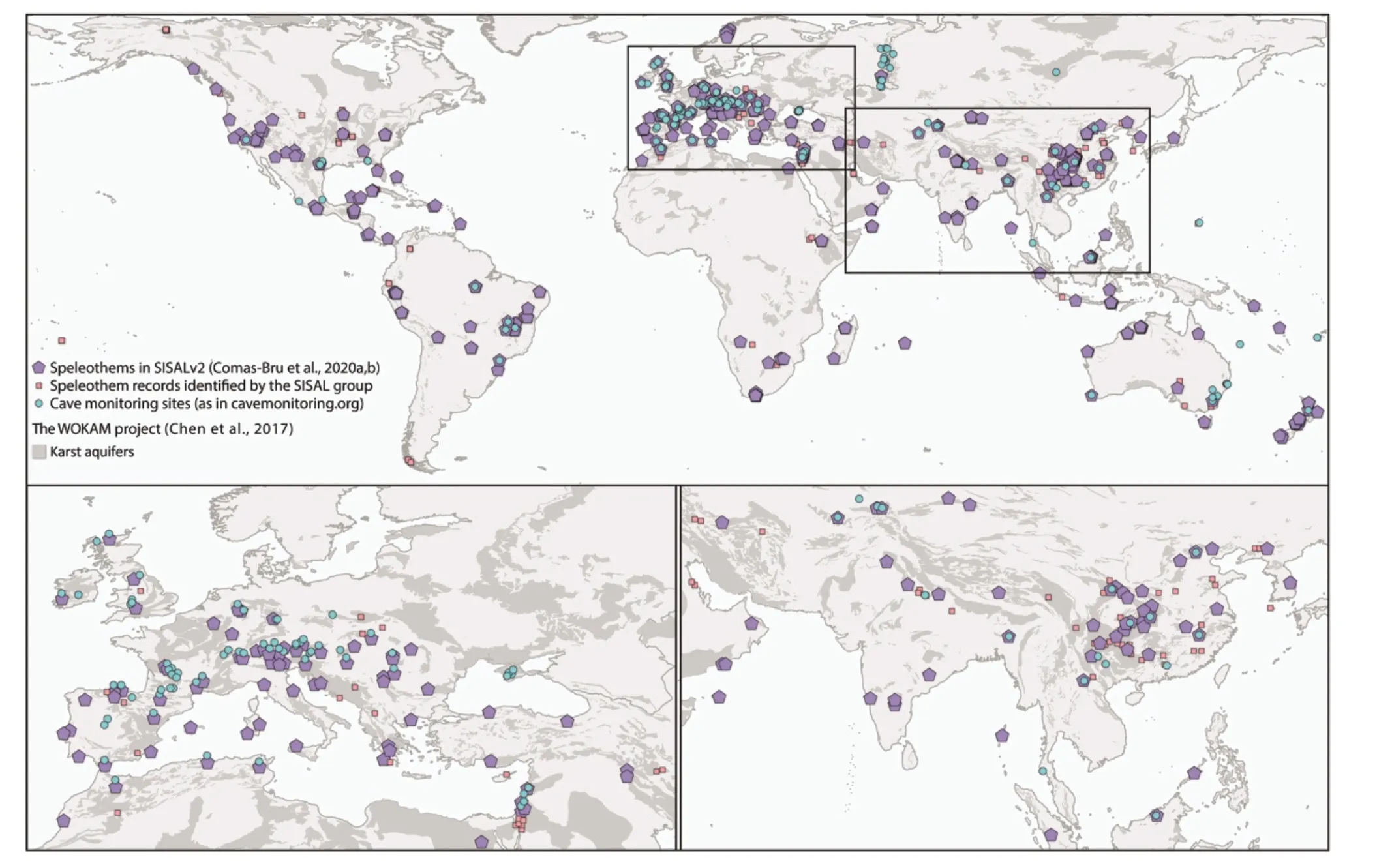
图5 SISALv2包含数据点(五边形)、已识别数据点(正方形)及cavemonitoring.org数据库洞穴监测点(圆形)分布图(http://www.pages.unibe.ch/science/wg/sisal/intro)Fig. 5 Speleothem records available (pentagon) and which are identified (square) by SISAL working group and cave monitoring sites (circle) from cavemonitoring.org database
SISAL直接展示了洞穴次生碳酸盐记录的时空分布,这种时空分布差异能够揭示洞穴次生碳酸盐的形成背景及环境信息,可用于古气候变化历史的重建以及气候模型的验证(图5)。数据点的存在与否还可用于评估样本量、样本分布对结论的影响,推测潜在的研究区域。例如欧洲西部是洞穴次生碳酸盐同位素数据分布最为密集的区域,基于SISALv1(2018)数据库的统计分析显示,该地区洞穴次生碳酸盐氧同位素随地区分布的变化与当地降水氧同位素组成(Global Network of Isotopes in Precipitation, GNIP站点数据)有很好的映射关系(Lechleitner et al.,2018),并且在末次冰期中呈现一致的小冰期—小间冰期旋回信号,这种信号在高纬山地地区尤为显著;而全新世的数据由于较低的信噪比,这种趋势并不那么明显,研究认为这种差异受控于温度的变化。而在中东地区,更新世以来的洞穴次生碳酸盐氧同位素组成据则显示百年尺度变化指示降水量的变化(Burstyn et al.,2019),但受限于数据点有限,并不能分离水汽源区的影响。南美洲的相关数据的分布呈杠铃形,巴西中部地区氧同位素值偏负,这种特征被解释为热带辐合带上升流加强导致输送过来的水汽偏负,而非降水量效应的影响(Deininger et al., 2019)。Comas-Bru等(2019)结合ECHAM5-wiso大气循环模型模拟降水氧同位素比值和现代观测值,与SISAL数据相比较,结果均呈良好的一致性,进一步证实SISAL数据可用于检验气候模型的模拟数据,作者同时也指出洞穴次生碳酸盐数据的筛选,如矿物相、时间尺度、年代学特征、沉积连续性等差异,都可能影响模型检验的结果。
SISAL的实践建立了一套合理的、国际公认的洞穴次生碳酸盐碳氧同位素数据元数据标准(http://www.mdpi.com/2571-550X/2/1/7/s1), 符合大数据可查询、可获取、可交互、可重复使用(FAIR)准则,使得新老数据得以在统一平台共享共通,数据更具有生命力。进一步结合GNIP数据库、洞穴监测数据库以及大数据分析技术,SISAL数据库将在揭示洞穴次生碳酸盐氧同位素组成变化机制、重建区域气候变化历史上有很大发挥空间。
4 表生地球化学大数据建设展望
以上调研结果表明,尽管表生地球化学领域并不缺相关数据库,但由于研究对象复杂,研究范围广,而数据整体呈现多元化、跨学科的特征,不同专题数据内容差异大,数据库发展不平衡,数据标准不完善,同时还缺乏部分具有针对性和专业性的数据库。深时数字地球(DDE)国际大科学计划将建设开放共享的大数据平台,从大数据的角度、用大数据方法解决地学问题,推动地球科学研究向数据密集型科学转变(Cheng et al., 2020)。已有数据库基本满足其建立的原始目的,并遵循数据FAIR原则,但可能仍需进一步整合、标准化,这些数据库的成功实践也可以为DDE未来工作提供具体经验和参考(表3)。在DDE的推进和发展引领下,表生地球化学领域的数据库建设应从传统学科导向调整为重大问题导向,强化学科融合与领域整合。

表3 本文介绍的主要数据库的优缺点及数据库建设启示Table 3 Advantages, disadvantages and related inspiration of 5 databases mentioned here
表生地球化学领域现阶段数据库建设主要存在两大难题—已有数据、数据库的数据标准化以及大量非结构化数据的结构化。为解决这些问题,表生地球化学工作组需要借鉴和学习已经成熟的中大型数据库,如USGS、GEOTRACSES、PAGES等的建设和管理经验,并以此为基石,组建针对性的专题科研团体,以科研问题和实际需求为导向,制定元数据标准,有效整合已有数据库和长尾数据,建成互联互通的表生地球化学数据共享平台。
数据结构上可以借鉴SISAL数据库和GeoReM数据库,将数据内容按不同测试项目、样品描述、解释数据等划分为若干个相关联的数据集,以减少数据冗余度,后期对数据的修正、更新则可以通过对相应数据集的增删实现,保证了数据的可溯源性和新老数据可对比性。对于数据量足以支撑大数据分析研究的研究专题,如黄土第四季研究及其大量非结构化数据,则理应建立对应的专题数据库,以期进一步扩展开发对应的分析工具,深入发掘数据背后的知识;而对于数据量稍小的研究专题或者说数据库建设处于早期阶段,表生地球化学大数据平台应该履行综合性数据库的职能,在收集、整合数据的基础上,确立数据的标准和共享原则以及便于操作的录入和引用流程,继而随着数据量增大,从中蜕变出更具有指向性的专题数据库。
一枝独秀不是春,百花齐放春满园,表生地球化学作为地质学与其它科学的高度交叉与交融的综合性研究学科,必能在百花齐放的大数据时代迎来又一轮春天!
致谢:本文系“深时数字地球”(Deep-time Diyital Earth)大科学计划系列成果之一。
