基于隶属云的安全监测异常数据识别方法研究
2021-03-05朱斯杨,李艳玲,卢祥,刘可心
朱 斯 杨,李 艳 玲,卢 祥,刘 可 心
(1.四川大学 水力学与山区河流开发保护国家重点实验室,四川 成都 610065; 2.四川大学 水利水电学院,四川 成都 610065)
随着监测技术、网络通讯技术和计算机技术的不断发展,工程安全监测的测点个数和观测频次也随之增多,监测数据量增长明显[1],精确识别出监测数据序列中的异常值,提高监测数据的有效性,对科学准确分析工程安全性态具有重要意义[2]。目前应用于异常数据识别的方法很多,包括四分点法[3]、统计学方法[4]等,其中3σ准则因为使用简便而应用较广[5],但由于其识别效果对数据序列正态分布特性依赖严重,因而对工程安全中经常出现的“台阶型”、“振荡型”等含有较多离群点的数据序列极易出现异常识别漏判的问题。毛亚纯[6]和赵键等[7]基于3σ准则提出了数据跳跃法来识别异常数据;许贝贝[8]等将3σ准则与分位数方法结合起来,利用关联分析法分析测点位移空间关系识别异常数据;Li等[9]基于3σ准则采用自学习和平滑处理来识别异常数据,但这些方法均不适用于含离群点较多的数据序列,因此识别精度较低。为此,本文基于隶属云模型,通过逆向隶属云发生器计算每个云滴的期望和带宽,利用3b准则进行初步识别离群严重的数据,以云滴群期望和带宽序列的均值代替3σ准则中的均值和标准差进行构造控制函数进行识别,并将该方法应用于龚嘴水电站不同类型的测点序列,将结果与传统3σ准则对比,结果发现该方法对含离群点较多的“台阶型”和“振荡型”数据序列识别效果很好,对正常数据序列识别效果与传统方法一致。
1 云模型与隶属云异常识别算法
1.1 隶属云基本概念
隶属云是定性概念与定量表示之间相互转化的一种转换模型,它能反映出数据的随机性和模糊性。本文将隶属云应用于大坝安全监测领域,原理如下:设U是一个用精确数值表示的定量论域,F是U上的定性概念。若定量值x∈U,且x是定性概念F的一次随机实现,x对F的确定度CF(x)∈[0,1]是一个具有稳定倾向性的随机数,即:CF(x):U→[0,1],∀x∈X(X⊆U),x→CF(x)。
则X在论域U上的分布称为云,每一个x称为一个云滴[10]。
隶属云通过期望Ex、带宽b和云方差σmax3个数字特征值来表示概念的随机性与模糊性。期望Ex反映了云滴分布的中心位置,是工程安全监测数据信息的中心值;带宽b表示隶属云相对于期望值的离散程度,是对工程安全监测数据结果可行度的一种反映;云方差σmax用来度量带宽的不确定性,是带宽的方差,可以表示监测水平偏离正常的程度,综合反映了监测仪器、监测人员的素质和监测环境等因素对监测水平的影响程度。
在隶属云模型中,根据云滴群对定性概念的贡献度,发现有贡献的云滴主要集中在区间[Ex-3b,Ex+3b]内,该区间外的云滴几乎没有贡献,可表征为异常信息,这被称为隶属云的3b准则[11]。
隶属云发生器是实现数据序列与隶属云相互转化的数学模型,本文提出的方法使用逆向隶属云发生器将监测数据转换为隶属云的数学特征值,具体算法步骤如下[12]:
(1) 计算数据样本期望Ex,二阶中心距c2和四阶中心距c4。
(1)
(2)
(3)
(2) 再计算样本数据的带宽b和云方差σmax。
(4)
(5)
1.2 监测数据的隶属云异常识别算法
传统的3σ准则是以均值和标准差构造控制函数来判断测值是否异常,当数据序列中出现较多离群点,使其不再服从正态分布时,其均值和标准差将会严重偏离实际情况,使其出现漏判现象。
隶属云异常识别算法的第一步是依次将待测数据序列X中的前j(j=1,2,3,…,n)个测值输入到逆向云发生器中,得到每个测值对应的数字特征期望Exj和带宽bj,之后利用隶属云的3b准则对每个测值进行初次筛选,对筛选出的异常测值进行修正,消除一些明显的离群点的不利影响。第二步是将初筛后的云期望序列Ex的均值M作为总体尺度参数,初筛后的带宽序列b的均值B作为总体位置参数构造控制函数进行异常识别,加强了正常数据的权重影响,使计算所得的控制限更加符合实际情况。
隶属云异常识别算法的实现流程如图1所示。
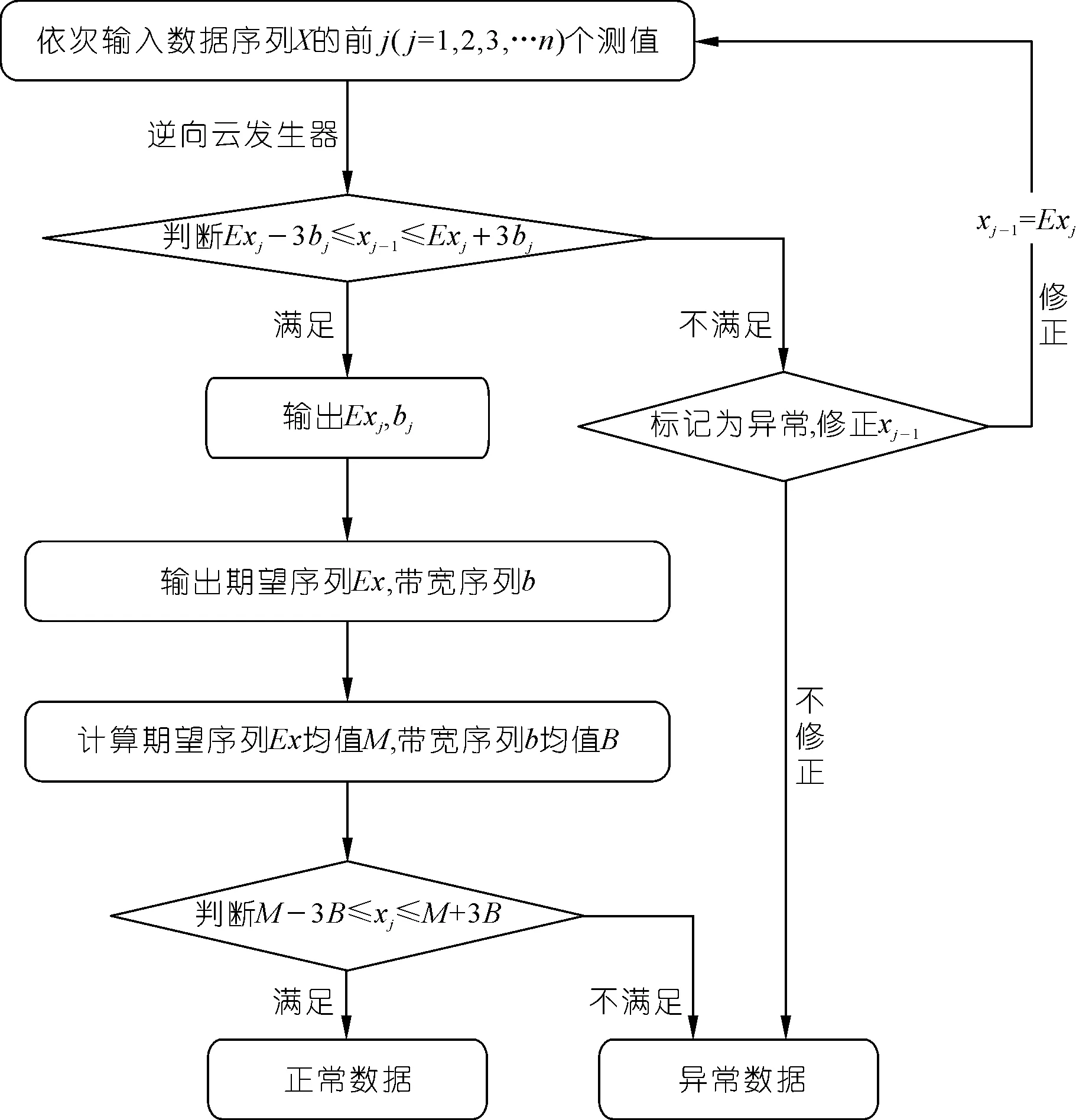
图1 隶属云异常识别算法流程Fig.1 Anomaly recognition algorithm flow of membership clouds
2 工程应用
龚嘴水电站坝址位于四川省乐山市沙湾区与峨边县交界处的大渡河中游下段,拦河坝为混凝土重力坝,其监测项目主要包括扬压力监测、渗流监测、变形监测、环境量监测等,于2005年已实现自动化观测。变形监测数据变化平稳、周期性规律好,故本文选取规律性稍差、含离群点较多的扬压渗流典型测点LSY03(振荡型)、LSY12(振荡型)、YY10101(台阶型)和位移测点JGBX15(正常序列)为例进行对比分析,各测点基本信息如表1所示。

表1 典型测点基本信息Tab.1 Basic information of typical measuring points
用本文方法计算上述典型测点的控制限,并将其与传统的3σ准则控制限对比,进行异常识别,各测点实测值和控制限过程线如图2~5所示。
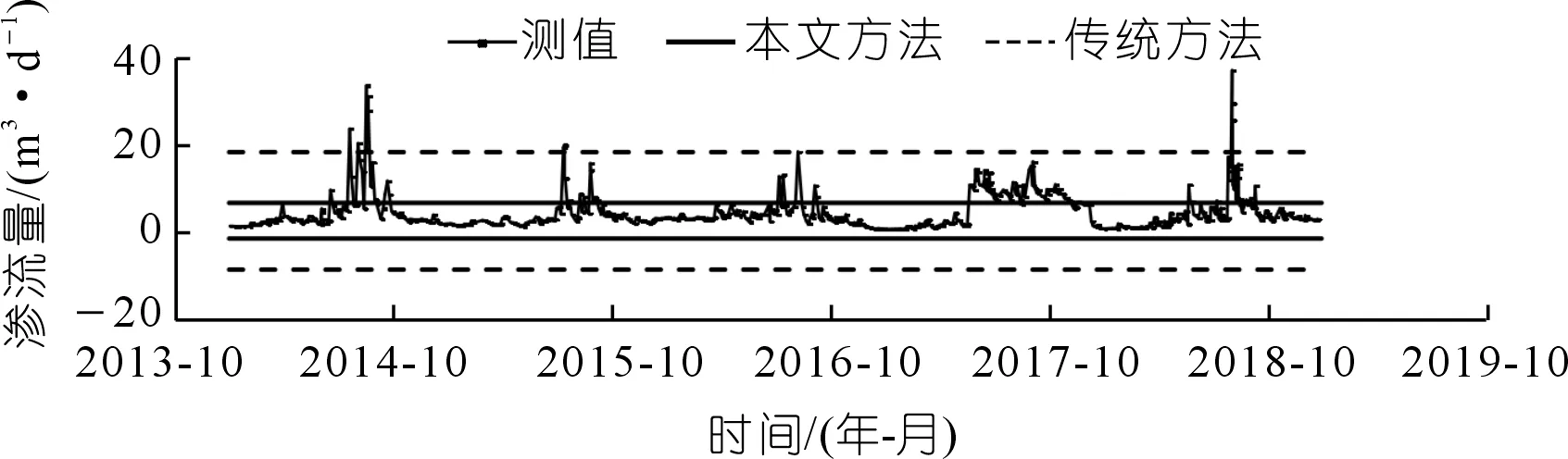
图2 LSY03测值过程线及控制限对比(振荡型)Fig.2 Comparision of measured data process line and the control limit LSY03(oscillatory type)
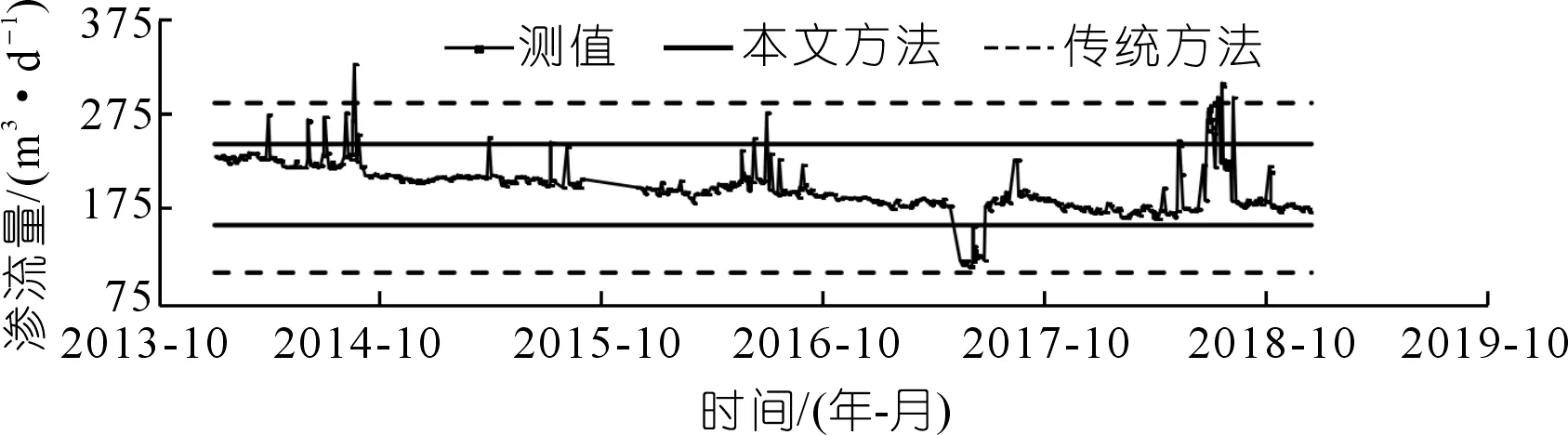
图3 LSY12测值过程线及控制限对比(振荡型)Fig.3 Comparision of measured data process line and the control limit LSY12(oscillatory type)
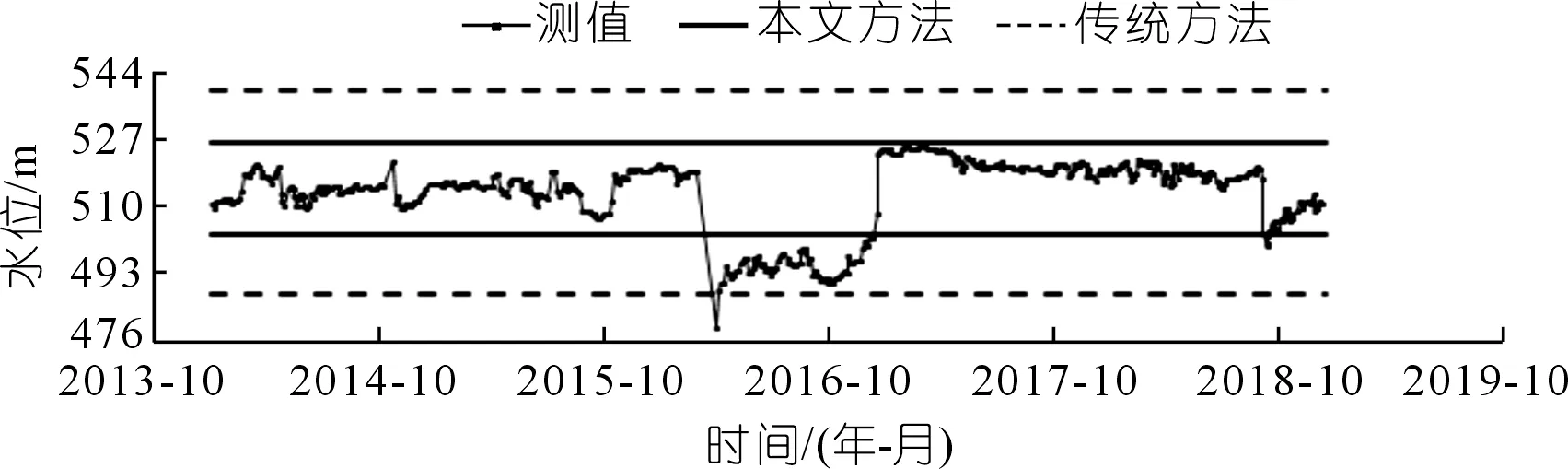
图4 YY10101测值过程线及控制限对比(台阶型)Fig.4 Camparision of measured data process line and the control limit YY10101(step type)
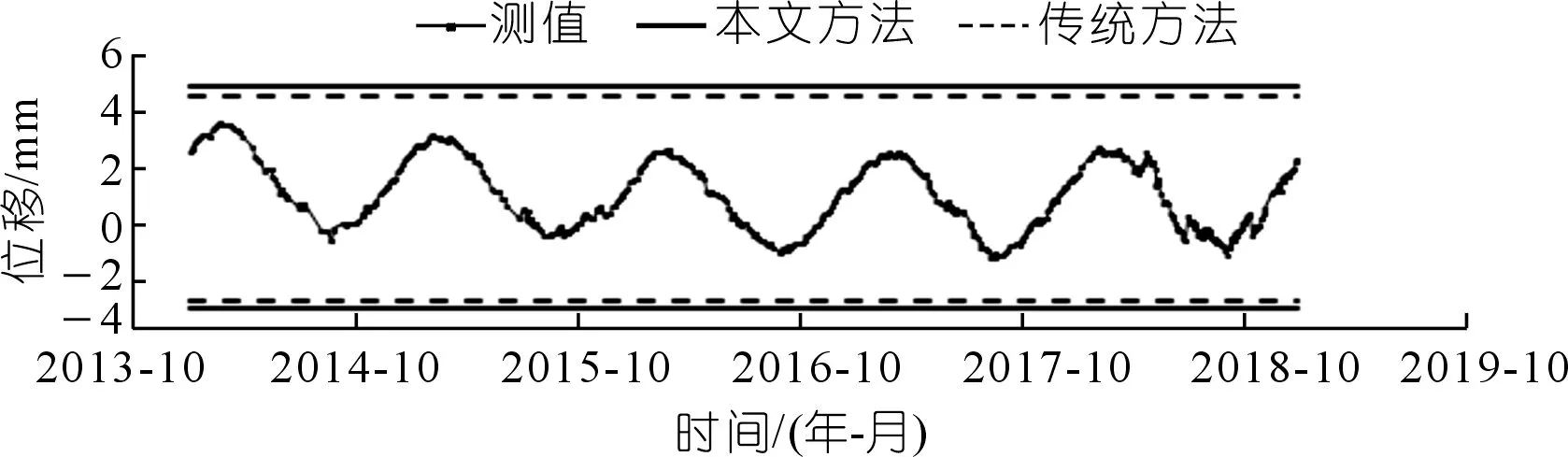
图5 JGBX15实测值过程线及控制限对比(正常数据)Fig.5 Comparision of measured data process line and the control limit JGBX15(normal sequence)
可以看出:当监测数据序列中离群点较多时,数据序列不再符合正态或近似正态分布,根据传统3σ准则计算所得的控制上下限将被拉向离群点而偏离正常范围,使得传统3σ准则不能准确识别异常,出现漏判问题。如测点LSY03在2016年7月7日出现的测值14.10,测点LSY12在2018年9月25日出现的测值275.59以及测点YY10101在2018年9月25日出现的测值500.31,采用传统的3σ准则时均为被识别为正常点,而采用本文提出的方法首先通过初筛消除了离数据序列中心较远的离群点影响,用初筛后的云期望序列Ex的均值作为总体尺度参数,初筛后的云带宽序列b的均值作为总体位置参数构造控制函数,加强了正常数据在计算控制限的影响,消减了离群点的不利影响,使其计算的控制限更加符合实际情况,提高了异常识别的精度,计算结果如表2所示。而对于不含离群点的正常数据序列,两种方法计算所得的异常控制限差异很小,识别结果相同。
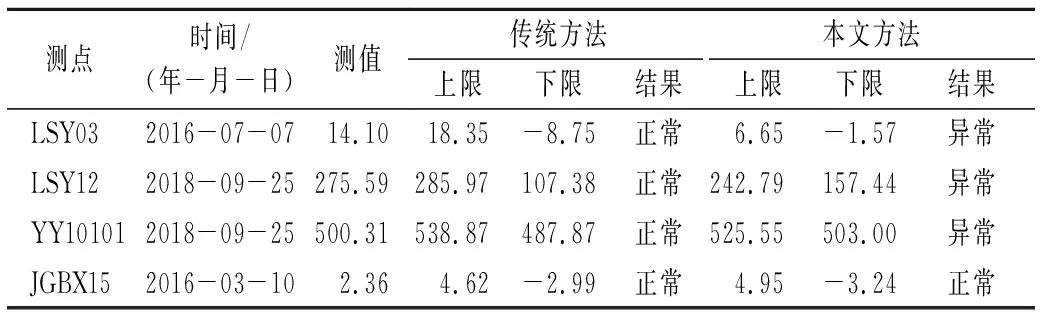
表2 异常识别效果对比Tab.2 Comparison of abnormal identification effect
为进一步验证数据异常识别的效果,将该方法应用于龚嘴水电站所有位移及渗流测点,发现对于周期性好、变化平稳的位移测点,结果一致;而对于周期性差,含离群点的扬压渗流测点,本文方法的漏判率较传统方法下降明显,结果如表3所示。

表3 异常识别效果对比结果Tab.3 Comparison results of abnormal recognition effect
综上所述,本文方法能有效抵抗离群点的干扰,解决了传统方法无法识别“台阶型”和“振荡型”数据中离群点的问题,识别精度显著提高,同时也适用于正常数据序列,适用性强。
3 结 论
本文针对传统3σ准则无法准确识别工程安全监测中“台阶型”和“振荡型”序列中离群点的漏判问题进行了研究,通过对隶属云模型的应用,为安全监测数据异常识别提供了一种简单高效的方法,将其应用于龚嘴水电站,得到如下结论。
(1) 基于隶属云的识别算法通过初筛消除了部分明显的离群点对数据序列分布特征的不利影响;利用隶属云期望序列和隶属云带宽序列的均值构建控制函数,加强了正常数据的权重影响,使得控制限设置更加符合实际情况。
(2) 通过对比分析两种方法对龚嘴水电站监测测点的异常识别效果发现,本文方法能有效减少因实际监测数据序列含离群点较多时偏离正态分布时异常值漏判的问题;对于正常监测数据,两种方法识别结果相同。
