某型车载炮作战试验维修保障效能评估
2021-03-05戈洪宇李皆乔刘益东王志文
戈洪宇,李皆乔, 刘益东, 陈 曦, 王志文
( 中国人民解放军63850部队, 吉林 白城 137001)
现代战争已经从单纯的力量对抗转变为体系对抗,体系间相互协作,达到1+1>2的效果,维修保障作为装备体系中重要的一环,是装备恢复状态,持续保持装备战斗力的有效方式[1-2]。现代战争就是在打保障,哪一方能够保障有力,提高装备的可靠性、可用性,持续提供战斗力,那么这一方必然是胜利一方[3]。
作战试验作为检验武器装备作战性能的一种新模式,是通过模拟战场中可能出现的作战背景,以类似实战的方式检验装备真实表现,这样不仅可以检验装备的战斗力,同时也可以给工业部门及装备使用部门提供后续保障的数据支撑。维修保障效能是维修保障系统执行维修保障任务时,达到预期目标的程度,是装备系统效能的重要一环。评估效能时需要全面考虑相关影响因素,有的指标是可以得到直接数据,有的指标不能直接测量或者统计,因此维修保障效能只能通过评估,而不能叫做计算。
目前效能评估方法较多,如ADC法[4-5],系统动力学法[6],层次分析法[7-9]等,但是维修保障效能在作战任务及作战环境不同的情况下,效能评估指标的评价难以量化,且存在模糊不确定的情况,给评估带来了挑战。云模型[10]是一种将定性概念和定量描述相互转换的模型,推动了定性评价向定量评价的发展,能够将评估结果更为直观地展示给研究人员,有助于制定相关决策。本文根据作战试验的实际,在采集到某型车载炮作战试验相关数据的基础上,从评价指标的量化入手,研究在指标评语为定性评价条件下的维修保障效能评估的问题。
1 影响因素分析
维修资源的利用情况是维修保障能力的外在表现,评估维修保障效能,要从影响维修保障能力的维修资源入手,确定维修资源并分析其发挥的能力,以此为根据评估维修保障效能。根据装备维修保障过程中的实际情况,影响装备维修保障能力发挥的维修资源可以概括为四大类,主要分为维修人员,设备设施,备件和技术资料。维修人员主要受维修人员的学历、技能、数量和专业覆盖面影响;设备设施主要受通用性、配套性、设备设施完好性和设备设施的利用率影响;备件主要是由数量、种类、供应和需求预测组成;同时还有相关的技术资料影响装备维修保障效能,主要由数量、种类、适用性和利用率组成。如图1所示。

图1 维修资源构成框图
2 动态权重求解
直觉模糊集(intuitionistic fuzzy set,IFS)是在传统模糊集的基础之上,同时考虑隶属度、非隶属度和犹豫度3个参数,拓展为一种更具有灵活性和实用性的方法,为处理信息的不确定性、不精确性、不完全性、随机性提供一种解决方法。结合某型车载炮的作战试验,根据调查问卷收集到的数据,本文采用文献[11]中的方法,建立直觉模糊集,兼顾评估者的偏好,对指标体系中的各类指标进行权重计算。
2.1 直觉模糊集
设X为一个给定非空论域,集合X上的直觉模糊集(IFS)A有以下的定义:
A={〈x,μA(x),νA(x)〉|x∈X}
(1)
式(1)中:μA∶X→[0,1]和νA∶X→[0,1]表示了隶属函数和非隶属函数;μA(x)是元素x对于A的隶属度函数;νA(x)是元素x对于A的非隶属度函数,且隶属度函数和非隶属度函数满足条件0≤μA(x),νA(x)≤1。那么我们可以认为IFS(X) 为论域X上的全体直觉模糊集。
设在非论域X上的IFS为A={〈x,μA(x),νA(x)〉|x∈X}且πA(x)=1-μA(x)-νA(x)称为元素x在A中的犹豫度;sA(x)=μA(x)-νA(x)称为元素x在A中的分数;hA(x)=μA(x)+νA(x)称为元素x在A中的准确度;θA(x)=1-|μA(x)-νA(x)|称为元素x在A中的模糊度。
2.2 直觉模糊熵
设A∈IFS(X),定义函数:IFS(X)→[0,1],那么称E(A) 为直觉模糊熵,而且E(A)满足以下条件[11-13]:
1)E(A)=0当且仅当∀x∈X,μA(x)=1,μA(x)=0或μA(x)=0,μA(x)=1;
2)E(A)=1当且仅当∀x∈X,μA(x)=0,μA(x)=0。

(2)
2.3 动态属性权重的计算
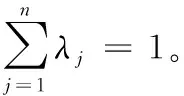
Aij={〈x,μij(x),νij(x)〉|x∈Y}
(3)
式(3)中:μij(x)表示Yi满足Gj的隶属度;νij(x)表示Yi不满足Gj的非隶属度。
指标Yi在专家集Gj下的评估信息的直觉模糊熵为EGij,EGij能够反映Yi在Gj下评估信息的模糊度和不确定度,如果EGij越大,则说明模糊程度和不确定度越高,即评估时该属性的权重值越小[12-15]。
设指标Yi在Gj下评估信息的偏差度为:dGij=1-EGij,i=1,2,…,n,j=1,2,…,m,则指标Yi在属性Gj下动态的权重为:
(4)
为了能够兼顾评估者的个人偏好和习惯,依据评估者的已知主观权重λ={λ1,λ2,…,λn},修正属性权重为:
(5)
3 云理论分析
云模型[10]是一种在概率论和模糊集的基础之上形成的方法,主要是通过建立一种定性和定量之间的转换规则,从而解决了定性评价中的定量处理问题。
定义1:假设U是用精确的数值来表示的定量论域U={u},如果对于任意一个定性的概念A中的一个随机值u∈U,都可以有一个有稳定分布特性的随机数μA(u)∈[0,1],则可以称μA(u)为元素u对概念的隶属度,将所有的隶属度的集合称为隶属云(简称云),即μA(u)∶U→[0,1],∀u∈U,u→μA(u)。
云一般有3个数字特征:① 期望Ex,是定性概念转为定量后的量化均值; ② 熵En是定性概念的粒度的量; ③ 超熵He是对熵的不确定性的度量,是体现指标的稳定性的量,即云模型中云滴的密集度。
云发生器一共分为正向和逆向,正向发生器的主要功能是将定性的指标进行定量的转化,即输入Ex、En和He以及云滴的数量,能够给出N个云滴的数值和隶属度2个量;另一种是逆向发生器,逆向发生器是能够将定量的指标转化为定性评价,通过输入若干的符合正态分布的云滴就能够得到Ex、En和He这3个云滴的数字特征。
本文采用了很差、差、一般、良和优5个等级的评价标准(定性)来对维修保障效能进行评估,评估,主要将结果控制在0~1区间之内。根据实际情况,我们可知维修保障效能等级区间不是均等的,所以按照实际情况,并考虑专家、部队的意见,将定性语言和分布的区间确定如表1所示。

表1 维修保障效能评估标准
对应的云模型为Cloud优(0.95,0.017,0.005),Cloud良(0.85,0.017,0.005),Cloud一般(0.7,0.033,0.005),Cloud差(0.5,0.033,0.005),Cloud很差(0.2,0.067,0.005)。相应的云模型标准如图2所示。
由各层的指标权重和相应的云数字特征可以计算得到上一级的云数字特征。计算公式为:
(6)
式(6)中:m为指标的数量;ωi为第i个指标的权重值。
根据上述公式可以求解上一级的云数字特征,并继续向上级计算直至得到最终效能的云数字特征,并与评估标准云进行对比,得到效能评估结果。

图2 云模型评价标准曲线
4 算例分析
本文在Microsoft Windows7系统操作下运行,基本配置为:Intel Core(TM)i5CPU,4G内存,软件为MATLAB2014a,采用直觉模糊熵的方法确定各指标权重,并采用云模型方法对装备维修保障效能进行评估。
4.1 评价数据采集和转换
数据来源于调查问卷,数据经过转换的结果如表2所示,表2中一些指标是可以是量化的,也可以定性的,为保证一致,全部采用定性评价方法,计算其经过云发生器后的云特征数字。

表2 指标调查评语表
4.2 权重确定
结合4位维修班成员的意见得到相关指标的直觉模糊集,并根据式(3)、式(4)计算主观权重,如表3所示。

表3 主观权重表
综合调查人员意见,使用式(5)对主观权重进行修正。得到各指标的修正权重如表4所示。

表4 修正权重表
4.3 云数字特征计算
在表2的基础上,根据计算式(6),计算二级指标的云数字特征得到表5。

表5 二级指标的云数字特征
再根据二级指标的权重,使用式(6)计算得到维修保障效能的云数字特征为(0.847 3,0.022 7,0.005),通过云发生器得到维修保障效能的云图,并与标准云图对比,云模型图如图3所示。

图3 评估结果曲线
从图3可以看出,维修保障综合效能的评价云介于“良”和“一般”对应的标准云之间,说明综合评价云与“良”“一般”的相似度高于其他标准云,而在“良”和“一般”之间比较,综合评价云更接近于“良”且基本与cloud良重合,说明维修保障效能整体趋于良的评价。但是从图3可以看出综合评价值的云跨度要大于cloud良,且从数据上可以看出综合评价的熵为0.022 7,大于cloud良的熵0.017,说明综合评价有较大的随机性和模糊性。
5 结论
采用了基于云模型的效能评估方法,该方法通过云模型将不确定性的指标转化为定量的云数字特征,并采用直觉模糊集的方法计算指标权重,运用综合云理论评估维修保障效能,得到综合评价云,并与标准云进行对比,以此估计出维修保障综合效能,通过案例证明了本文方法的可行性,为维修保障效能评估提供了可行的解决思路。
但本文方法还是存在一些问题:① 云模型存在的问题,当He>En/3时,即评价的超熵较大时,云图呈现雾化状态,此时云图模糊不清,很难得到评估结果;② 直觉模糊集在一定程度上涵盖了评价者的主观因素,没有完全达到客观获取权重的目的;③ 标准云的设定同样存在一定主观因素,不同的标准云评估的结果不同,如果经过长期的试验总结,得到标准的界限之后,评估结果将更具有普遍性。
目前作战试验的效能评估属于起步阶段,缺乏相关的标准和指导性文件,在以下2个方面可以进一步研究:① 作战试验数据量大,结构复杂,如何找到合理的数据分析方法需要进一步研究;② 目前各种效能评估方法大多不适合作战试验的评估工作,研究合理高效的评估方法对作战试验和性能试验等相关工作的评估有较大的推进作用。
