酿酒特需高粱真实性无损快速鉴别研究
2021-03-04刘亚超陈小雪韩北忠李永玉
刘亚超,陈小雪,程 伟,周 艳,韩北忠,李永玉*
(1.中国农业大学工学院,国家农产品加工技术装备研发分中心,北京 100083;2.中国农业大学食品科学与营养工程学院,北京 100083;3.四川郎酒集团有限责任公司,四川 泸州 510500)
高粱作为酱香型白酒生产的重要原料,其品质的优劣在酿酒过程中起着决定性的作用,并直接影响成品酒的质量[1-7]。多数酒企为了保证白酒发酵品质,除了特有的酿造工艺和流程,同时还需要符合企业特需的高粱作原料。然而一些中间商为了获取更多利益,将其他品种的高粱混入特需高粱售于酒企,这会对酒品质造成一定的隐患,因此对特需高粱的真实性把控显得尤为重要。目前主要通过感官评价(外观色泽、蒸煮等)来检测高粱是否为所需品种,也有使用限制性片段长度多态性聚合酶链反应(polymerase chain reaction-restriction fragment length polymorphism,PCRRFLP)鉴别需求高粱的真实性[8]。虽然这些方法成熟,但是需要有大量经验的人进行操作,不宜大范围推广。同时这些方法存在主观性、检测速度较慢等问题。因此,如何能够快速、有效的检验特需高粱的真实性是目前酒企急需解决的问题。
近红外光谱是一种快速、有效、绿色的分析方法,主要反映的是物质成分中含氢基团在近红外区域的特性[9]。近红外光谱是一种综合信息,包括物质内部成分和外部信息,其在各领域中的定量或定性分析方面已取得丰富的成果[10-15]。在高粱检测方面,近红外光谱分析主要用于高粱内部成分的定量分析[1,16-19],通常需要将高粱进行粉碎进行测定。基于近红外光谱的特需高粱无损鉴别而言,获取样品池内特需高粱和掺假高粱在内的所有样品的完整信息是保证判别结果准确性的基础。然而,高粱颗粒透光性较差,加上检测器探头有效探测面积有限,难以获取特需高粱和掺假高粱颗粒全部的样品信息。
本实验以实现特需高粱真实性的快速无损鉴别为目的,针对高粱透光性差,近红外探头有效探测面积有限,难以有效获取样品池中特需高粱和掺假高粱的整体样品信息等问题,改良样品杯直径和检测窗口直径的匹配关系,优化样品在样品杯的填充方式,解决无法采集样品池中整体样品信息等问题,有效获取包括掺假高粱颗粒的整体样品信息,并结合化学计量学方法优化模型建立,最终实现特需高粱真实性快速无损实时鉴别,为今后开发便携式特需高粱真实性鉴别设备提供了技术支撑。
1 材料与方法
1.1 高粱样品
特需高粱、红茂粱、金糯粱:由四川郎酒集团有限责任公司品质研究院提供;三种高粱大小较为相似,其中金糯粱与特需高粱无法通过外观直接区分,红茂粱相比特需高粱颜色偏黄。
1.2 仪器与设备
Antaris II傅里叶变换近红外光谱仪(有效探测范围为4 000~10 000 cm-1(1 000~2 500 nm),分辨率为4 cm-1):美国赛默飞公司。
根据前期实验的成果,定制一款符合本研究的环形样品杯,其内径略大于检测窗口直径的2倍,通过上下移动载台,即保证检测器可以有效获取样品信息,又保证了样品量。并且,样品杯还备有上盖,保证光谱采集过程中不受外界光干扰。
1.3 样品制备及填充
1.3.1 方法
由于高粱样品的透光性较差,为了保证采集样品信息的有效性,基于前期实验结果对样品填充方式及样品盘直径进行了优化。将样品平铺于样品杯底部,层数为一层,保证检测器可以采集样品的全部信息。
根据实际高粱混合情况,分别将金糯粱和红茂粱与特需高粱按照不同混合比例一对一混合制备样品(见表1)。掺入样品的量由每次填充样品杯的颗粒数量乘以混合比例决定,需求样品和混合样品总共制备210个样。为了验证实验方案的可行性,从210个样品随机抽取30个样品作为独立验证集,剩余样品为训练集用于建立高粱近红外判别模型。

表1 需求样品和混合样品混合比例Table 1 Mixing ratio of demend sample and mixed sample
1.3.2 数据分析及模型评价
在采集样品光谱数据时,由于受仪器稳定性、环境等因素的影响,光谱数据除了包含样品的有效信息也包括一些噪声,因此需要对光谱数据进行预处理以获取更有效的信息。在本文中使用多元散射校正(multiplicative scatter correction,MSC),标准正态变量变换结合去趋势(standard normal variate transformation+D,SNV+D),一阶卷积求导(1st Der.(S-G))和二阶卷积求导(2nd Der.(S-G))等算法对光谱数据进行预处理[20-21]。预处理后的数据结合偏最小二乘判别算法(partial least squares discriminant analysis,PLS-DA)建立高粱近红外判别模型[22-23]。模型的性能由最终判别结果的准确率决定,准确率越高,模型性能越好,判别准确率可由以下公式计算:

式中:A代表判别结果的准确率,N代表样品总数量,Nright代表判别正确的样品数量,Nwrong代表判别错误的样品数量,以上计算均在Matlab(R2014a)中完成。
2 结果与分析
2.1 高粱近红外光谱分析
所有高粱样品的近红外光谱见图1。由图1可知,在1000~2 500 nm波长范围内存在6个吸收峰。根据已有研究[24-25],其中波长1 206 nm附近的吸收峰与-CH3中的C-H键对称拉伸的二级倍频有关,波长1 463 nm附近吸收峰与淀粉O-H键反对称和对称拉伸有关,在波长1 933 nm附近的吸收峰与淀粉的O-H键拉伸和弯曲结合有关,波长2 127 nm附近的吸收峰为N-H伸缩振动与酰胺Ⅲ的组合频有关。波长2 313 nm和2 353 nm处存在弱的吸收峰,均与-CH2中C-H键的伸缩和弯曲振动有关。由此可见,高粱在1 000~2 500 nm之间的近红外光谱信号主要由淀粉、蛋白质及其他碳水化合物的近红外信号组成。除此之外,需求高粱的光谱与混合高粱的光谱没有明显的差异,并且混合高粱的光谱将需求高粱的光谱完全覆盖。

图1 高粱样品近红外光谱图Fig. 1 Near infrared spectroscopy of sorghum samples
2.2 高粱判别模型建立
为减少高粱光谱数据中非目标信息的干扰,提高光谱特征信号的分辨率,对原始光谱进行了不同数据预处理,消除其他因素对图谱信息的影响,预处理结果如图2所示。其中MSC预处理消除光散射对光谱的数据的影响;S-G预处理通过平滑消除光谱数据的噪声;SNV+D主要用于消除颗粒大小,表面散射,基线漂移对光谱的影响;1st Der.(S-G)可以消除基线及其他背景的干扰,分辨重叠峰,提高分辨率;2nd Der.(S-G)在1st Der.(S-G)的基础进行二次求导。需要注意的是,在使用一阶卷积求导和二阶卷积求导预处理时虽然消除了基线和背景的干扰,但同时也会放大某些噪声,这些噪声对模型产生何种影响还需要通过最终的模型结果进行评定。

图2 不同预处理方法的高粱样品近红外光谱Fig. 2 Near infrared spectroscopy of sorghum samples with different pretreatment methods
在建立模型前,先将训练集数据按照3∶1分为校正集和预测集,使用不同预处理数据结合PLS-DA建立的高粱鉴别模型结果如表2所示。
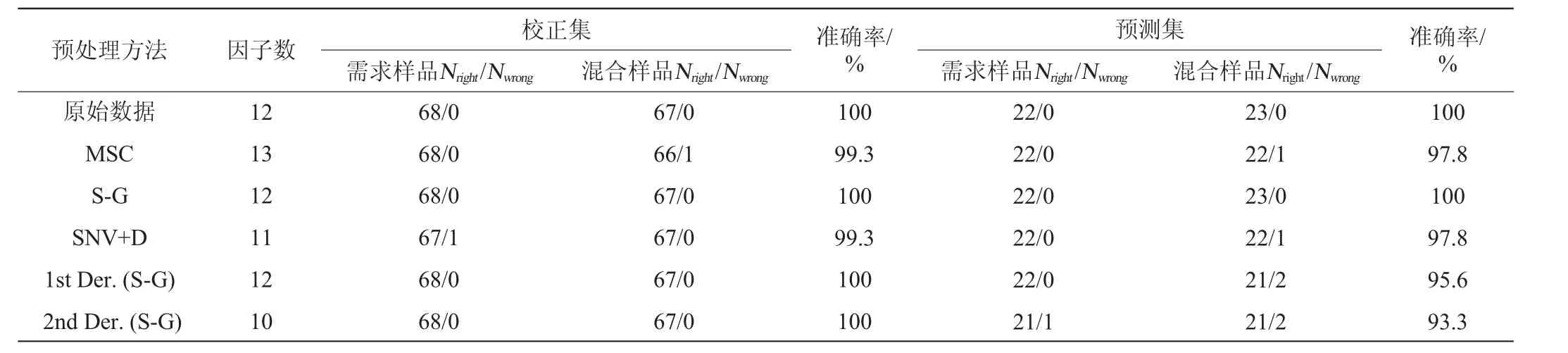
表2 不同预处理方法的高粱样品鉴别近红外光谱模型结果Table 2 Near infrared spectroscopy model results for identification of sorghum samples with different pretreatment methods
从表2可以看出,使用原始光谱和经S-G预处理后的光谱分别建立的高粱近红外判别模型性能较好,校正集和预测集的判别结果均为100%,使用其他预处理方法建立模型的判别准确率略低于前者。使用其他预处理建立模型的校正集判别结果准确率均在99.3%,然而使用1st Der.(S-G)和2nd Der.(S-G)预处理建立的模型预测集判别结果较差,分别为95.6%和93.3%。正如前面所述,使用导数预处理虽然可以提高光谱分辨率和消除基线漂移,但是在预处理过程也放大了某些噪声,表2中的结果证明了这些噪声对模型的性能产生负面影响。
基于表2的结果,本研究提出的实验方案是可行,其中使用原始光谱和S-G预处理后的光谱建立的模型判别结果均为100%。
2.3 高粱判别模型验证
为了进一步验证模型的可行性,将随机抽取的30个样品用于外部独立验证,对光谱数据按照相同的流程进行预处理并导入对应的模型进行验证,结果如表3所示。
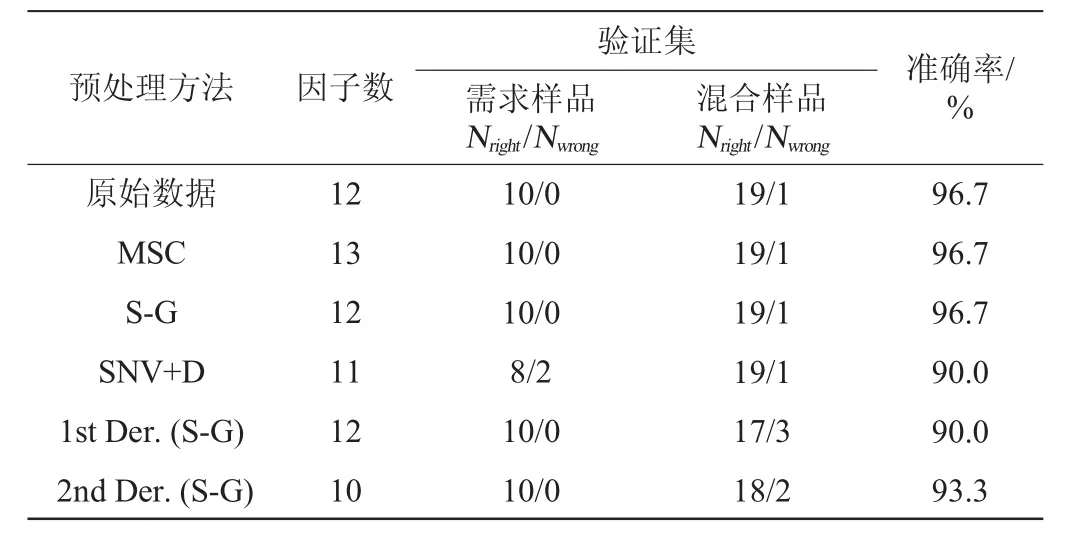
表3 不同预处理方法的高粱样品鉴别近红外光谱模型验证结果Table 3 Near infrared spectroscopy model validation results for identification of sorghum samples with different pretreatment methods
从表3可以看出,其中原始数据、MSC预处理、S-G预处理的验证集判别准确率均为96.7%,其判错的样品混合比例为10%(特需高粱-红茂粱),其余预处理的验证集判别结果准确率均高于90%,这再次表明本文提出的实验方案是具有可行的,可以用于鉴别需求高粱的真实性。需要注意的是,经SNV+D预处理的验证集判错两个真实样品和一个混合样品,结合表2结果,表明该预处理方法不适用于高粱鉴别判别。
2.4 结果分析
基于表2和表3的结果,使用原始数据和S-G预处理建立的模型性能最好,两者的判别结果见图3。由图3可知,两者的判别结果相同,校正集、预测集和验证集的判别准确率分别为100%、100%和96.7%。
从图3可以发现,使用原始数据和S-G预处理数据分别建立的模型结果非常相似,这主要是因为S-G处理只是对光谱数据进行平滑,并没有明显改变光谱特征(图2)。虽然结果相似,但实际预测的结果还是存在微小差异,如图3C和图3F中同一样品的预测结果分别为0.522 7和0.524 7。使用其他预处理的校正集结果虽然与图3中的结果相差不大,但预测集和验证集的判别结果却不如图3中对应集合的判别结果。这主要是因为预处理虽然可以消除大量的噪声,改善光谱的分辨率,但是不恰当的预处理反而会降低模型的性能,如1st Der.(S-G)和2nd Der.(S-G)(表3)。

图3 高粱样品鉴别近红外光谱模型校正集、预测集、验证集判别结果Fig. 3 Discrimination results of NIR model calibration set, prediction set, validation set for sorghum samples identification
3 结论
本实验将近红外光谱分析技术首次用于特需酿酒高粱真实性鉴别,弥补了该方面研究的空白。通过优化样品填充方式,改良样品杯与检测窗口的匹配度,确保了检测器可以采集更多的样品有效信息,从而解决了近红外光谱技术在鉴别特需高粱方面存在的问题。在样品光谱采集后,将光谱数据与化学计量学结合建立高粱近红外鉴别模型,其结果表明使用原始数据和S-G预处理建立的模型性能最好,且两者的判别结果相同,校正集、预测集和验证集的判别准确率分别为100%、100%和96.7%。基于实验结果,表明了近红外光谱技术结合化学计量学可以实现快速、无损的鉴别高粱的真实性。同时,也为今后开发便携式特需酿酒高粱真实性鉴别仪提供了数据参考。
