面向星上目标提取的卷积神经网络优化技术
2021-03-04孙永岩郑幸飞齐保贵
卢 丹,孙永岩,郑幸飞,齐保贵,师 皓
(1.上海卫星工程研究所,上海 201109;2.北京理工大学 信息与电子学院 雷达技术研究所,北京 100081;3.嵌入式实时信息处理技术北京市重点实验室,北京 100081)
0 引言
随着遥感成像和信息处理技术的发展,在星上实时完成目标检测、场景分类等任务,直接从遥感数据中获取有用信息,具有十分重要的意义。卷积神经网络凭借其强大的特征提取能力,在遥感数据处理任务中可显著提升信息提取的效率和精度,逐渐获得广泛应用[1]。
伴随着性能的提升,卷积神经网络的参数存储量和计算开销也越来越大,在低功耗、计算和存储资源有限的在轨场景中难以移植应用。因此,如何在不降低网络性能的条件下,缩小网络规模,减少计算消耗,成为当前亟待解决的问题。如果能将网络规模小型化,那么将卷积神经网络部署到机载、星载等遥感设备便成为可能,这无疑是从实验室走向应用的关键性进展。
通过模型压缩来降低存储量和计算成本已经有了大量的研究。目前提出的网络压缩方法主要可分为以下几类[2]:参数剪枝、权值量化、低秩分解、紧性卷积核设计和知识蒸馏。参数剪枝法通过对网络进行结构或非结构化的剪枝操作,将模型中冗余的参数进行裁剪,从而降低网络复杂度,并可在一定程度上防止过拟合。20 世纪末,CUN 等[3]和HASSIBI等[4]先后提出最优脑损伤(Optimal Brain Damage,OBD)和最优脑外科(Optimal Brain Surgeon,OBS)的参数剪枝方法,利用网络的二阶导数信息衡量参数的冗余性,从而对网络进行修剪。2015 年,韩松等[5]提出了一种基于低权值连接的剪枝方法,对网络中权值较小的参数进行修剪,将原始的稠密网络变得稀疏。但这种非结构化的剪枝方式不会带来显著的加速,LI 等[6]、LEBEDEV 等[7]通过对冗余滤波器进行裁剪,研究了结构化的参数剪枝方法。2017 年,LIU 等[8]提出了一种网络瘦身(Network Slimming)方法,利用BN 层的缩放因子,结合正则化稀疏约束对网络中不重要的通道进行裁剪。权值量化的主要思想是用较低的比特位表示模型实际的浮点型权值,通过减少网络参数的存储量,实现模型加速和压缩。GUPTA 等[9]使用16 位定点数表示CNN 训练过程中的参数,不仅显著减少了内存使用和浮点运算量,且几乎对分类精度没有损失。
为了进一步压缩权重,二元[10]、三元[11]权值网络被提出,通过在训练过程中学习低比特权值或激活,大幅压缩网络规模。低秩分解法采用张量或矩阵分解技术,将原始卷积核拆解为多个小卷积核的乘积,从而降低网络运算量和参数规模。紧性卷积核设计法从网络结构出发,通过设计更精简的网络模 块,如SqueezeNet[12]、ShuffleNet[13]等,有效减 小模型尺寸。2015 年,HINTON 等[14]提出了知识蒸馏的概念,从高性能复杂网络中学习有用信息来指导简单网络的训练,在保证性能相差不大的情况下实现模型压缩。
上述方法可不同程度地减小原始网络规模,但也带来了精度的下降。为了改善精度损伤的问题,本文提出一种基于知识蒸馏的剪枝压缩改进方法。该方法将参数剪枝与知识蒸馏技术相结合,先对网络进行混合参数剪枝以删除冗余信息,再用剪枝前网络指导剪枝后网络的再训练过程,以提升后者的性能。以遥感图像分类任务为例,在遥感数据集上对VGG-16 网络进行压缩,在网络精度损伤不大的情况下,可实现16~18 倍的压缩效果。
1 基于混合参数剪枝的卷积神经网络压缩方法
1.1 方法介绍
参数剪枝主要有两种途径:一种针对通道剪枝;一种针对权重剪枝。为了降低网络参数的冗余度,可将两种剪枝方法结合应用,其主要技术路线如图1所示[15]。

图1 混合参数剪枝Fig.1 Hybrid parameter pruning
首先对网络进行通道剪枝,实现模型的初步压缩,并对网络再训练以恢复损伤的精度。其次,在通道剪枝的基础上再进行权重剪枝,以进一步压缩网络的参数规模。
1.2 基于通道的参数剪枝
通道剪枝是一种结构化的参数剪枝方式,通过剪去网络中冗余的通道,即对网络贡献度较小的单个滤波器,实现对模型的压缩,如图2 所示。

图2 通道剪枝前后Fig.2 Before and after channel pruning
该方法可分为3 个步骤:训练网络→裁剪冗余的通道→网络再训练。
如图3 所示,Xi为第i卷积层的输入特征图,Xi+1为输出特征图,每个卷积层有ni×ni+1个二维的卷积核Fi,j,其中,ni和ni+1分别表示输入、输出特征图的维度。

图3 修剪一个滤波器会导致在下一层中删除其相应的特征图和相关的内核Fig.3 Trimming a filter causes its corresponding feature map and associated kernel to be deleted in the next layer
首先评估通道的重要性,通过计算单个滤波器的L1范数,即其绝对权重之和来衡量每个层中滤波器的相对重要性。与层中其他滤波器相比,具有较小内核权重和的滤波器倾向于产生具有弱激活的特征映射。从第i个卷积层中修剪m个滤波器的步骤如下:
步骤1对于每个滤波器Fi,j,计算其权重绝对值的总和。
步骤2按sj对滤波器进行排序。
步骤3剪去具有最小和值的m个滤波器及其对应的特征映射,下一个卷积层中与被修剪的特征映射相对应的内核也被删除。
步骤4第i层和第i+1 层创建新的内核矩阵,并将剩余的内核权重复制到新模型。
网络中不同卷积层对修剪的敏感度不同,通过逐层修剪并在测试集上评估剪枝网络的精度,可以判断各层对剪枝的敏感性,并确定每一卷积层通道剪枝的比例。
1.3 基于权重的参数剪枝
对网络进行通道剪枝后,得到较小规模的新网络,再训练使其恢复精度。将小规模新网络的参数按照权值大小进行排序,权重越小代表其对网络的最终贡献越小。
通过删除权重小于指定阈值的连接,减少模型的参数量,如图4 所示。
图4 权重剪枝前后,网络由稠密变得稀疏Fig.4 Before and after weight pruning,the network becomes sparse from dense
该方法仍然遵循“训练网络→剪枝→再训练”的3 个步骤,剪枝的具体操作是将低于某一阈值的参数置零,再训练过程中已经被剪掉的参数将保持零值,不再进行参数更新。网络中不同层参数对剪枝的敏感度是不同的。由于网络的计算量主要集中在卷积层,通常卷积层比全连接层对参数剪枝更敏感。基于此,应仔细衡量每一层参数的剪枝比例,以获得最优的压缩效果。
2 基于知识蒸馏的剪枝压缩改进方法
由于上述混合参数剪枝方法会带来精度下降,因此本文提出了一种基于知识蒸馏的剪枝压缩改进方法,将知识蒸馏技术融合到混合参数剪枝中,通过再训练过程中的知识传递可以减少剪枝后的精度损失。具体步骤如图5 所示。
知识蒸馏法的主要思想是用大型复杂模型学习到的知识指导简单网络的训练,从而提升后者的表现。此时,复杂模型可以看作是“教师”,待训练的简单模型为“学生”。通过网络间的知识传递,使简单模型重现复杂模型的输出结果,达到规模压缩的目的。
神经网络学到的知识将输入数据映射为输出结果,对于处理分类任务的网络,其训练目标是将正确输出结果的概率最大化。但这种训练方式为每个错误结果也分配了概率,这些错误概率展示了网络进行分类判断的“思路”。神经网络通常使用Softmax 输出层得到分类概率,函数定义如下:

图5 基于知识蒸馏的剪枝压缩改进方法Fig.5 Improved pruning compression method based on knowledge distillation

式中:zi为复杂模型分类结果的输出值;i为类别索引;j为类别总数;qi为由Softmax 函数计算得到的分类概率;T为温度,是一个可调节的超参数,通常为1,T值越大,类别的概率分布就越“软”,即更加均匀平和。
知识蒸馏法通过调整网络再训练过程中的损失函数,进行网络间的知识传递。训练小模型时,损失函数由两部分组成:第1 项是包含“软目标”的交叉熵函数,其目的是使小模型向经过蒸馏的复杂模型的输出结果优化;第2 项是由小模型输出的结果与正确标签的差值计算得出的交叉熵函数,这与传统的训练过程相同,目的是使小模型向真实的标签值进行优化。损失函数的公式[16]为

式中:Lsoft、Lhard分别为优化方向为“软目标”和正确标签的交叉熵函数;α为损失函数的权重系数,α=0 时对应于不使用知识蒸馏法进行训练的情况。
以混合参数剪枝前的网络为“教师”,剪枝后的网络为“学生”,采用知识蒸馏法对网络进行再训练。相比于传统再训练方式,知识蒸馏法能获得更优的再训练效果,改善网络性能。
3 实验验证
3.1 基于混合参数剪枝的卷积神经网络压缩方法
以遥感图像分类任务为例,分别在两个公开的遥感数据集NWPU-RESISC45 和UC Merced Land-Use 上对VGG-16 网络进行压缩实验。NW⁃PU-RESISC45 数据集由西北工业大学研究团队于2017 年提出,包含飞机、港口、教堂等45 个不同的场景类别,每个场景中分别有700 幅256×256 的RGB图像,大部分测试图像的空间分辨率能达到每个像素0.2 m。UC Merced Land-Use 数据集是由美国国家地质调查局航空拍摄的正射影像,包含棒球场、海滩、十字路口等21 个不同的场景类别,每个场景包含100 幅256×256 的RGB 图像,图像的空间分辨率为每个像素0.3 m。实验时选取数据集中20%的图像作为训练集,剩余图像作为测试集,观察剪枝前后VGG-16 网络的分类表现。
首先对VGG-16 网络进行基于通道的参数剪枝,由于每一卷积层对剪枝的敏感性不同,需要先对单层修剪滤波器以判断每个卷积层对修剪的敏感度,从而设置恰当的通道剪枝比例。实验结果如图6 和图7 所示。由实验结果可知,在不同的数据集上,卷积层对通道剪枝的敏感性是相似的。第7卷积层对剪枝最敏感,第1 卷积层对剪枝最不敏感。在本次实验中,对训练好的VGG-16 网络的第7 卷积层剪去25%的滤波器,对剩余卷积层均剪去50%的滤波器。

图6 在NWPU-RESISC45 数据集上,不同卷积层对通道剪枝的敏感性Fig.6 Sensitivity of different convolutional layers to channel pruning on the NWPU-RESISC45 dataset

图7 在UC Merced Land-Use 数据集上,不同卷积层对通道剪枝的敏感性Fig.7 Sensitivity of different convolutional layers to channel pruning on the UC Merced Land-Use dataset
对通道剪枝后的网络进行再训练,使其恢复精度。接下来对网络进行基于权重的参数剪枝,以进一步减少冗余参数。首先对全连接层90%的参数进行剪枝,经过再训练,网络分类精度损伤不大,这说明剪掉的90%全连接层参数中大部分是冗余的。在此基础上,对卷积层参数进行剪枝,并逐渐增大卷积层参数的剪枝比例。在遥感数据集上对VGG-16 网络进行混合参数剪枝,实验结果见表1。
由表1 数据可知,对VGG-16 网络进行混合剪枝,网络精度下降1%左右时,能移除93%左右的参数。这说明通过合理调整卷积层通道剪枝比例和通道剪枝后网络的权重剪枝比例,可以裁剪掉网络中的大部分冗余参数。

表1 混合参数剪枝前后网络对比Tab.1 Network comparison before and after hybrid parameter pruning
3.2 基于知识蒸馏的剪枝压缩改进方法
在NWPU-RESISC45 数据集上,参数剪枝前VGG-16 网络的分类精度为89.69%。经混合参数剪枝剪去网络中93.92%的参数后,按普通方式对网络进行再训练,最终分类精度为88.53%,相比于剪枝前,性能下降了1.16%。为了使再训练后网络性能损失不超过1%,使用知识蒸馏方式学习剪枝前网络的有用信息。
通过调整Softmax 函数中参数α、T的值,可获得不同的知识蒸馏效果。网络再训练后的分类精度见表2。由表2 可见,采用知识蒸馏法训练的网络比普通训练方式得到的网络性能更好,这说明原始网络的分类结果对小网络的训练起到了正向的指导作用,提升了小网络的表现。当α=0.8、T=5 时,对剪枝后的VGG-16 网络重新训练,其精度可达到89.63%;相比于剪枝前,性能只下降了0.06%。
如图8 所示,绘制剪枝后网络再训练过程中的精度变化曲线,红线代表α=0.8、T=5 时使用知识蒸馏方法训练,蓝线代表普通训练方式。由曲线趋势可见,在相同迭代次数时,知识蒸馏法训练的网络性能有微弱的优势,最终分类精度比普通训练方式提升了1 个百分点。
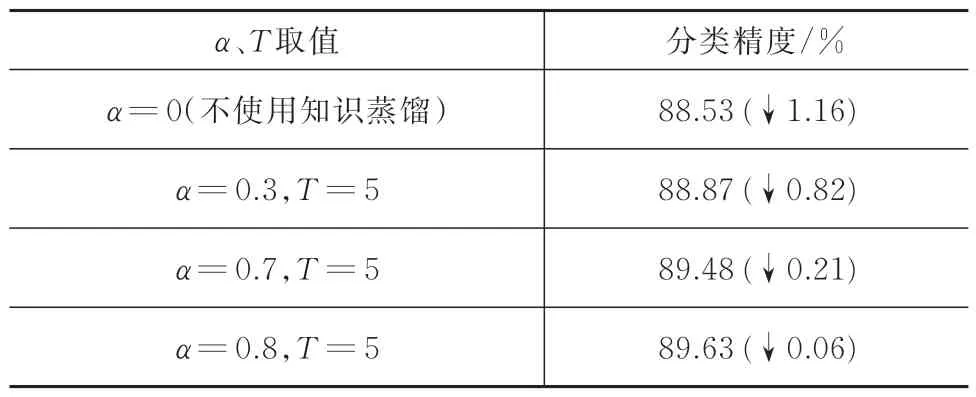
表2 在NWPU-RESISC45 数据集上,剪枝93.92%的参数,知识蒸馏效果Tab.2 Knowledge distillation effect on the NWPURESISC45 dataset,pruning 93.92% of the parameters

图8 在NWPU-RESISC45 数据集上,网络再训练过程中精度变化曲线Fig.8 Accuracy curves during network retraining on the NWPU-RESISC45 dataset
在UC Merced Land-Use 数据集上,参数剪枝前VGG-16 网络的分类精度为87.86%。经混合剪枝,剪去网络中93.78%的参数后,网络性能下降,经普通方式再训练精度可恢复到86.25%,相比于剪枝前,精度下降了1.61%。
采用知识蒸馏方式进行对剪枝后的网络进行再训练,训练结果见表3。
由实验结果可知,采用知识蒸馏方法再训练的网络有了更好的性能。当α=0.7、T=8 时,重新训练后网络的最佳分类精度可达到87.86%,与剪枝前网络的精度相同。当α=0.7、T=5 时,再训练后网络的最佳精度达到88.21%,优于剪枝前的性能。这表明剪枝后的网络接收到了原始模型学到的“知识”,在“教师”网络和有标签数据集的共同指导下,呈现出了更好的表现。

表3 在UC Merced Land-Use 数据集上,剪枝93.78%的参数,知识蒸馏效果Tab.3 Knowledge distillation effect on the UC Merced Land-Use dataset,pruning 93.78% of the parameters
如图9 所示,绘制在UC Merced Land-Use 数据集上,剪枝后网络再训练过程中的精度变化曲线。图9 中,红线代表α=0.7、T=5 时使用知识蒸馏方法训练,蓝线代表普通训练方式。由图可知,在相同迭代次数时,知识蒸馏法训练的网络性能优于普通训练方式,在训练20 个epoch 后,知识蒸馏法训练的网络就达到了最高精度,所需迭代次数更少。

图9 在UC Merced Land-Use 数据集上,网络再训练过程中精度变化曲线Fig.9 Accuracy curves during network retraining on the UC Merced Land-Use dataset
由以上实验结果可知,在遥感数据集上对VGG-16 网络进行实验,基于知识蒸馏的剪枝压缩改进方法可在网络精度下降不到1%的条件下,移除93%~94% 的参数量,实现16~18 倍的压缩效果。在知识蒸馏过程中,当选择恰当的参数值时,剪枝后网络还可能获得优于原始网络的性能。
3.3 网络压缩前后性能对比
在NWPU-RESISC45 数据集上训练VGG-16网络,比较网络压缩前后的性能变化,结果如图10所示。其中,Network Slimming 是LIU 等[8]于2017年提出的基于正则化和BN 层缩放因子的通道剪枝方法。取剪枝并再训练后网络精度下降不足1%的模型,对其参数量、浮点运算数(FLOPs)、内存读写开销三个维度进行比较。可以看出经剪枝后,Net⁃work Slimming 方法的FLOPs 显著下降,而本文方法在减少参数量和内存读写开销上更有优势。这是由于网络运算量主要集中在卷积层,参数量集中在全连接层。对比模型中,Network Slimming 减去了约70%的卷积层,而本文方法只减去不足50%的冗余通道。通过多次进行剪枝和微调,本文方法有望进一步减少冗余通道数和FLOPs。

图10 网络压缩前后性能变化Fig.10 Performance changes before and after network compression
4 结束语
本文针对卷积神经网络规模庞大、难以在轨应用的问题,对深度神经网络压缩方法进行研究,提出了一种基于知识蒸馏的剪枝压缩改进方法。在遥感图像分类任务中,该方法对VGG-16 网络实现了16~18 倍的压缩效果,并带来了运算量、内存读写开销的下降,且精度损失不到1%。本文提出的方法可扩展到其他深度神经网络上,如残差网络、Inception 网络等,但在进行混合参数剪枝时需要根据网络的结构调整剪枝策略,以获得理想的压缩效果。此外,由于参数剪枝引入了不规则稀疏性,在网络计算过程中不会带来显著的加速。因此,后续可进行稀疏网络运算加速方面的研究,以满足实时性要求。
