基于能量图谱和孪生网络的导波损伤诊断方法∗
2021-03-03王彬文吕帅帅
王彬文, 吕帅帅, 杨 宇
(中国飞机强度研究所 西安,710065)
引 言
近年来,碳纤维增强复合材料由于具有比强度/比刚度高、性能可设计和易于整体成型等优点,被广泛应用于飞机主承力部件[1]。相比于传统的金属结构,CFRP 的主要缺点是对外来物的冲击敏感,特别是在起降过程中的跑道碎片撞击,或在维护过程中的工具跌落等低速冲击,都会造成层压结构内部大面积分层,结构压缩强度下降40%以上,但结构外观通常并不产生目视可见的损伤[2],这就给飞行安全带来巨大隐患。针对此问题,能够实时甚至在线对结构状态进行监测的结构健康监测(structural health monitoring,简称SHM)技术为上述问题提供了一条潜力巨大的解决途径[3]。基于导波的损伤监测技术在结构中能传播较长距离,且对分层、脱粘和裂纹等损伤敏感[4-5],是目前在航空结构损伤监测领域有前景的一种结构损伤监测方法,已成功应用于商业领域[6]。然而,导波损伤诊断方法对专家经验具有较强的依赖性。导波信号受结构不确定性、边界条件和环境温度等因素的影响较大,损伤诊断的准确性取决于专家水平以及专家对监测对象的先验知识[7]。
深度学习是解决此类问题一个强有力的工具,研究人员利用深度学习开展了基于导波的结构损伤识别[8-10]、定位和定量研究[11-13]。Guo 等[14]设计了一种可以识别金属梁结构裂纹损伤的深度学习模型。模型以各振动模态的波形为输入,使用多尺度卷积神经网络、残差网络和全连接层等结构抑制噪声和数据缺失的影响,并增强模型的收敛性和鲁棒性,其对裂纹长度预测的准确率超过90%。Sbarufatti等[15]开展了基于深度学习的板结构裂纹损伤识别和定量研究,主要工作集中在裂纹损伤数值模拟方法。Xu 等[16]针对由结构不确定性导致的裂纹损伤监测可靠性低的问题,通过对6 个尺寸相同的铝合金耳片进行疲劳实验加载,获取基于真实飞机结构的裂纹损伤导波监测数据。以上2 个深度学习模型的高损伤诊断准确率均是针对验证集,无法代表模型的泛化能力,且模型本身并没有对深度学习技术在结构健康监测领域所面临的限制和挑战提出解决方法。
笔者提出了一种基于能量图谱和孪生卷积神经网络的导波损伤诊断方法,其创新性主要体现在:①使用导波监测网络的能量图谱取代传统的单路径损伤指数作为损伤诊断样本,该方法能够解决单信号作为数据样本时,样本标签质量完全依赖专家水平的问题,同时为深度学习模型提供更加丰富有效的损伤信息;②针对数据样本量较少的问题,设计了孪生卷积神经网络,降低了模型对样本数量的需求,进而在考虑结构不确定性的情况下,实现深度学习模型的高准确率损伤诊断。
1 基于能量图谱和孪生卷积神经网络的深度学习模型
笔者使用的CFRP 加筋壁板采用CCF300/BA9916 CFRP,导波监测网络结构如图1 所示。损伤监测区域位于红框内,分为A,B,C,D4 个位置,其中A,C位于两长桁间的壁板上,B,D位于长桁与壁板粘结处。为了分析导波信号在CFRP 加筋板上的传播特性,在监测区域布置了9 个压电传感器(蓝色圆点),每4 个相邻的压电传感器组成一个矩形网络,包含6 条信号传播路径。通过对24 条路径进行监测,诊断红框区域是否存在损伤以及损伤的具体位置。
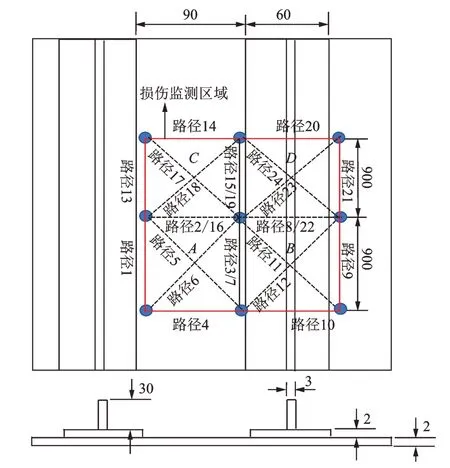
图1 导波监测网络结构图(单位:mm)Fig.1 Structure diagram of Lamb wave monitoring network(unit:mm)
深度学习模型的设计主要分为2 部分:①以压电传感器监测网络为基础,确定深度学习模型的样本形式和样本标注方法,笔者采用压电监测网络的能量图谱作为样本的基本形式,为准确、便捷的样本标注提供基础;②针对样本特征和数据特点,设计语义提取模型和分类模型,笔者采用孪生策略进行模型设计,以减少模型参数的数量,进而降低模型对训练样本数量的需求。
1.1 基于能量图谱的样本设计
基于导波的结构损伤识别,目前广泛采用的是针对单路径,对比分析损伤前后的导波信号特征,采用相应算法计算损伤指数,根据损伤阈值判别[17]损伤。若深度学习模型使用单路径信号作为样本,并采用该方法进行标签标定,则模型的损伤诊断水平会随着专家水平的变化而变化。这是由于深度学习模型的标签质量是模型诊断水平高低的决定性因素,标签标定既可以依赖客观事实,也可以依赖专家经验。但是导波信号易受结构、温湿度、载荷以及路径与损伤间的距离等因素影响,因此专家经验也存在不确定性。
实际上,图1 中区域A,B,C,D内的损伤会对24 条监测路径中的多条信号产生影响,且损伤位置与信号特征存在对应关系[18]。例如,处于区域A内的位置1 或处于区域B内的位置2 产生分成损伤时,24 条监测路径散射信号的电压分布如图2 所示。笔者运用图像处理技术,将监测网络的散射信号电压分布转化为能量灰度图谱,得到24 条监测路径能量分布的灰度图像如图3 所示,并将其作为深度学习模型的样本。该方法的优势主要体现为:①将损伤诊断问题转化为深度学习最善于处理的图像识别问题;②相比单路径信号,基于多路径散射信号的能量图谱包含了更多的结构状态信息,易于区分信号变化是由环境因素还是损伤因素产生;③摆脱依靠专家经验来判断样本标签类型的局限性。
笔者采用监测网络中24 条路径散射信号的能量图谱作为学习样本,样本标签分为0,1,2,3 和4,分别代表监测区域无损伤、损伤位于区域A、区域B、区域C和区域D。
1.2 孪生卷积神经网络
针对CFRP 损伤诊断问题,深度学习模型设计面临的挑战主要有2 个:①模型的训练参数不可过多;②模型能够提取导波监测信号的高层特征。在深度学习领域,网络的深度和宽度越大、结构越复杂,就代表需要更多的学习样本。目前的解决方式是通过数值仿真产生大量的虚拟数据样本[10],但这对模型的仿真程度提出了更高的要求,且产生的样本数量依然有限。因此,用于损伤诊断的深度学习模型需保证结构简洁、参数少。

图2 24 条监测路径散射信号的电压分布Fig.2 The energy distribution of the scattered wave in 24 monitored paths
具有相同构型的加筋壁板对相同损伤产生的导波散射信号也存在较大差别。在实际工程应用中无法直接在监测对象上设计实验来收集损伤样本,这就要求深度学习模型能够在学习数据中提取对结构不确定性敏度较低的高层损伤特征,进而在结构构型相同的不同监测对象上实现高准确率的损伤诊断。
1.2.1 孪生策略
针对图1 中的加筋壁板和压电传感器网络,导波信号的采样点个数n通常设置为3000~5000,能量图谱的尺寸为24n,属于长宽比失调的图像样本。若采用深度学习领域中传统的图像识别模型,则必须对该类样本进行预处理,即将24n的图片转换为n×n,以方便卷积核对图像进行特征提取。然而,图像尺寸转换的本质是将24 条监测信号沿图像宽度方向直接进行堆叠,未引入新的有效损伤信息,却使图像像素点数扩大了n/24 倍,进而增加了模型的深度和参数数量。图4 为图像尺寸转换原理,其中,xi为图像中第i个像素点的像素值。笔者采用孪生策略开展损伤诊断模型设计,孪生模型工作原理如图5 所示。首先,24 条路径分别通过24 个共享权值的卷积神经网络(即24 个孪生网络)进行语义特征提取;其次,在融合层将提取的所有特征合并;最后,融合特征进入神经网络分类器进行损伤诊断。与传统图像识别模型相比,该模型的优势在于通过24 个语义提取网络共享权值,大幅降低了特征提取网络的参数量,其本质是实现了卷积神经网络对图像像素的逐行扫查和综合诊断。

图3 24 条监测路径能量分布的灰度图像Fig.3 Gray-scale image of the energy distribution of 24 paths monitored
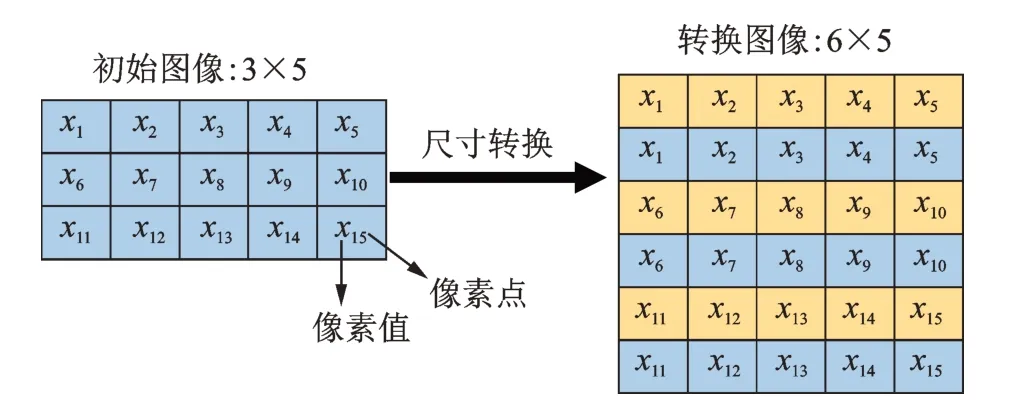
图4 图像尺寸转换原理Fig.4 Principle of image size conversion

图5 孪生模型工作原理Fig.5 Schematic of the twin model
1.2.2 网络结构
笔者针对深度学习模型在结构健康监测领域面临的问题,构建了基于孪生策略的卷积神经网络。该网络主要由语义特征提取模型和分类模型2 部分组成,其基本架构分别如图6,7 所示。

图6 语义特征提取模型的基本架构Fig.6 The basic architecture of the semantic feature extraction model

图7 分类模型的基本架构Fig.7 The basic architecture of the classification model
语义特征提取模型采用分布时序特征提取方法。“分布”指的是将一条路径的监测信号分割成10个数据片段,分别通过同一个CNN 模型来提取局部特征。“时序”指的是在基于“分布”式特征提取之后,将10 个片段的局部特征按时间顺序输入长短记忆网络(long-short term memory,简称LSTM),从而实现各数据片段间的时序趋势特征提取[19]。笔者使用一个包含32 个神经元的全连接层作为特征提取模型的输出。其中,CNN 模型包含3 个卷积层和2 个最大池化层。根据模型设计经验,在深度较小的卷积神经网络中,每个卷积层通常设置32 或64个卷积核,表示从32 或64 个维度对片段信号进行局部特征提取。通过对以上2 种结构的测试,选择诊断效果较好的64 作为卷积核数量。同时,针对导波信号采样频率较高、采样点较多的特点,特征图的像素点需具备较大的感受野,以保证能够提取更多采样点间的关联特征,因此卷积核长度设计为12,近似占每个片段长度的30%。最大池化层采用常用步长2,将特征图尺寸减小为原来的1/2。此外,语义特征提取模型采用“ReLu”作为卷积核的激活函数,以避免在训练过程中出现梯度爆炸和梯度弥散现象。使用L2正则化和“随机丢弃”技术对每一层卷积核的训练参数进行稀疏化处理,增强模型的的泛化能力,降低网络的计算成本。
分类模型由1 个特征融合层和3 个全连接层组成。特征融合层用于合并由语义特征提取模型输出的24 条路径的损伤特征;全连接层用于提取24 条路径的综合高层特征。需要指出的是,前2 个全连接层的激活函数仍采用“ReLu”,最后一个全连接层由于要完成5 种损伤的分类任务,选择了“SoftMax”作为激活函数。该函数可以将最后一层神经元的输出映射到(0,1)内,并根据一定的概率关系确定分类结果,即

其中:S为激活函数的输出向量;Si为S的第i个元素;e 为自然常数;V为全连接层的输出向量,Vi和Vj分别为V中的第i个和第j个元素。
在本模型中,V中共包含5 个元素,模型认为S中最大元素的所在位置即为分类结果。
深度学习模型的损失函数采用交叉熵函数,可表述为

其中:损失函数L由交叉熵和L2正则化2 部分组成;m为批处理样本的个数;K为样本标签种类数;y(i)为第i个样本标签的真值;1{y(i)=k}表示样本标签真值为k时,系数为1,其他情况系数为0;λ为正则化系数,是该模型的超参数,在[0.001,0.015]内通过网格搜索法确定;w为深度学习网络的权重矩阵。
深度学习采用“Adam”优化器更新网络权值,该优化器可对优化过程中梯度的一阶和二阶估计进行综合考虑,进而计算出合理的更新步长,增强优化过程的稳定性、避免梯度弥散。
2 实验设计与模型训练
为使深度学习模型从数据样本中提取对结构不确定性敏感度较低的高层特征,并在结构相同的不同实验件上测试模型的泛化能力,笔者使用6 块结构构型和材料完全相同的加筋壁板(S1~S6)进行实验,其尺寸和压电传感器网络布置如图1 所示。其中,S1~S4和S5~S6分别用于模型训练和测试。
应用在实验件表面粘帖专用胶泥的方法来模拟损伤[18],损伤面积从8mm×8mm~15mm×15mm不 等。将 实 验 件 分 为S1和S2,S3和S4,S5和S63 组,先对第1 组进行损伤模拟实验,再对第2 和第3 组重复第1 组的实验。分组进行模拟实验的目的是引入环境变化(温度、传感器状态等)对监测信号的影响,丰富样本的多样性。采集样本的具体方法为:①在2 个实验件的相同位置粘帖尺寸相近的胶泥,同时采集监测信号并将其作为损伤信号,然后随机更改损伤位置和胶泥尺寸,重复以上操作;②每采集10条损伤信号后,采集一次无损伤的基线信号。S1~S6上共收集损伤数据2614 个,基线数据270 个,每个数据包含24 条路径,各路径的采样频率均为120 Hz,采样点个数均为4000,其中,0~600 采样点信号为电磁串扰,不参与数据分析。数据收集过程历时21 d,最大温度变化为3°,期间更换压电传感器4 个,更换过程对实验件的敲击引起一定的信号变化。在每个实验件采集的数据中随机抽取一个损伤数据和一个基线数据,将其相减得到的散射数据作为一个样本,通过该方法共生成训练样本5592 条,测试样本319 条,S1~S6的采集数据数量和生成样本数量如表1 所示。

表1 S1~S6的采集数据数量和生成样本数量Tab.1 The number of collected data and generated samples of S1~S6
需要指出的是,为避免压电传感器性能、采集设备参数设置(增益、激励幅值等)和传感器粘贴工艺的差异对散射信号能量分布的影响,能量图谱中的像素值为散射信号的归一化电压,即为每条路径的散射信号与其基线信号最大电压的比值。
从5592 条训练样本中随机选择592 条作为验证集,其余5000 条作为训练集,对笔者设计的深度学习模型进行训练。每训练128 个样本模型更新一次网络参数,训练完成5000 个样本为一个循环,训练过程共经历80 个循环。在第60 个循环后,验证集的损失函数明显增大,说明模型开始出现严重的过拟合现象[19]。因此,选择第60 个循环的模型参数作为最终结果,此时验证集损伤识别和损伤定位的准确率分别为94%和93%。
3 测试结果与分析
3.1 模型泛化能力测试
深度学习模型对测试数据集的损伤识别结果和损伤定位结果如表2 和表3 所示。
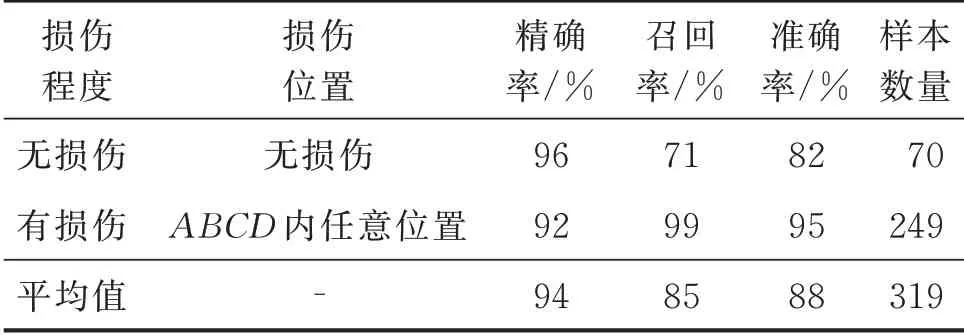
表2 测试数据集的损伤识别结果Tab.2 The damage identification results of test dataset

表3 测试数据集的损伤定位结果Tab.3 The damage location results of test dataset
由表2 和表3 可知,在考虑结构不确定性的情况下,深度学习模型损伤识别和损伤定位的平均准确率分别为88%和85%;相较于基于专家经验的传统方法具有较大优势,但与验证集结果相比分别产生了6%和8%的退化,说明模型依旧存在一定的过拟合现象。损伤定位结果中第1,2 类样本的诊断准确率最高,仅有一个样本判断错误;但第0,3 类样本的召回率、第4 类样本的精确率均较低。分析发现,这是由于模型将0,3 类中大多数的错误样本诊断为第4 类,直接导致第4 类样本的精确率大幅降低,而其召回率为100%,说明模型向第4 类样本严重偏斜。导致该现象的根本原因是第4 类训练样本的数量过少,仅占样本总数的9%,样本数量无法准确描述第4 类损伤特征的分布状态,干扰了模型对其他类样本的分析诊断。该问题可以通过增加训练样本数量得到改善。
3.2 深度学习与传统方法受结构不确定性影响的比较
为了说明深度学习方法与传统专家经验方法相比,不易受结构不确定性的影响,针对S5和S6的相同损伤,分别使用2 种方法计算导波监测网络特征矩阵的相似度,并进行比较。
笔者以特征矩阵间的欧几里得距离表征特征相似度。其中:传统方法的特征矩阵由24 条导波监测路径的8 种损伤指数构成[16],包括互相关值、空间相位差、频谱损失、中央频谱损失、微分曲线能量、归一化相关动量、微分信号能量和均方根偏差。传统方法 对S5和S6提 取 的 特 征 矩 阵 分 别 记 为X5,24×8和X6,24×8,则其相似度为
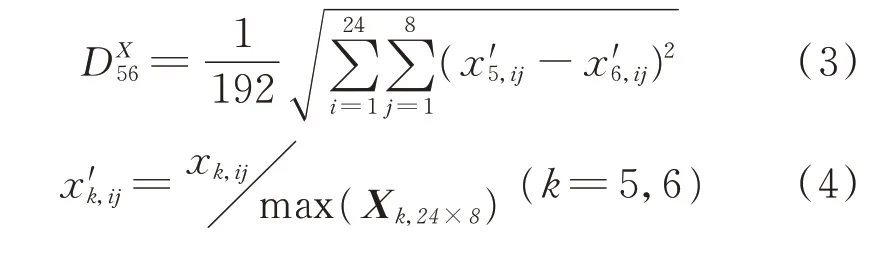
其中:xk,ij为Xk,24×8中第i行第j列的元素。
深度学习方法的特征矩阵为分类模型中第2 个全连接层的输出,对S5和S6提取的特征矩阵分别记为Y5,1×128和Y6,1×128,则深度学习方法的特征相似度可表示为

其中:yk,i为Yk,1×128中的第i个元素。
针对10 组S5和S6上的相同损伤,分别计算和并求得平均值=0.0108,=0.0070。这说明在考虑结构不确定时,深度学习方法的诊断结果比传统方法具有更高的可靠性,且随着样本数量的增加和种类的丰富,可靠性会不断提高。
3.3 特征的可视化与讨论
深度学习模型提取损伤特征的可视化分析如图8 所示。图8(a)为样本能量分布图,图8(b)为第1 个卷积层中64 个叠加特征,图8(c)~(e)为第1 个卷积层的3 个独立特征。可以看出:第1 个卷积层的作用是选择合适的阈值抑制低梯度像素点;由于图8(c)~(e)的阈值依次升高,所以图像中像素值为0 的区域逐渐增大;图8(b)可理解为该卷积层根据平均阈值对原始图像进行处理的结果。深度学习模型训练的作用是确定像素梯度的具体计算方法并调整64 个独立阈值。随着网络的加深,模型提取特征的可解释性逐渐降低。由第3 个卷积层的特征图(图8(f)~(h))可知,虽然图像在样本的高灰度区域依旧保持较高的特征水平,但无法解释其细微变化以及其他区域特征分布的物理意义。图8(i)为LSTM 层的输出特征,其中样本高灰度区域的曲面存在明显波动,而其他区域的变化相对平滑。

图8 深度学习模型提取损伤特征的可视化分析Fig.8 Visualization of damage characteristics of deep learning model
4 结 论
1)针对深度学习损伤识别技术,相较于单路径,基于多路径监测信号能量图谱的样本设计方法优势明显,能够借助图像识别领域的设计经验开发模型新架构,为深度学习模型提供更加丰富有效的学习信息,同时摆脱样本标注方法对专家经验的依赖。
2)深度学习模型能够提取导波信号的高层特征,且该特征受结构不确定性的影响较小,但是实现该技术工程应用的最大限制是样本数量不足。因此,需开展复合材料损伤的数值模拟技术研究和小数据驱动的深度学习模型设计技术研究。
3)借助特征可视化技术,能够对深度学习网络提取的损伤特征进行直观分析,但是目前深层网络提取特征的可解释性较低,后续需进一步结合专家经验分析高层特征的物理意义,为解释导波信号的变化规律和神经网络的工作机制提供基础。
