GAN网络混合编码的行人再识别
2021-03-02张玉霞
杨 琦, 车 进*, 张 良, 张玉霞
(1. 宁夏大学 物理与电子电气工程学院,宁夏 银川 750021; 2. 宁夏沙漠信息智能感知重点实验室,宁夏 银川 750021)
1 引 言
行人再识别[1](Person ReID)可以看作是一个跨摄像机视角的人物检索问题,旨在建立多个摄像机图像之间的身份对应关系。由于拍摄角度、光照、姿势、视角、图像分辨率、相机设置、遮挡和背景杂波的影响,会导致同一行人的不同图像可能会有显著不同,造成较大的类内差异,这使得行人再识别仍然是一项充满挑战性的任务。
随着深度学习在行人再识别任务中的广泛应用,卷积神经网络由于其强大的特征表达能力以及学习不变的特征嵌入,近年来涌现出各种各样的深度学习算法,尤其在GAN网络方面取得不错的进展。生成对抗网络最初是由Goodfellow等人[2]提出,被描述为一个通过对抗训练生成模型的过程。GAN由生成图像的生成器(G)和鉴别器(D)组成,这两个组件在极小极大值之间进行博弈。文献[3]提出将GAN扩展到CNN领域,使得利用GAN获取的训练样本更加可控,进一步说明了GAN网络在计算机视觉任务中的可行性。
众所周知,深度学习的发展得益于大数据的发展,而在如今行人再识别课题中,面临着数据不足与类内差异明显等问题。作为GAN网络的先行者,文献[4]提出一种标签平滑的方法,利用生成的数据扩充原始数据集,一定程度上提高了行人再识别的精度。不同于文献[4]采用标签平滑对生成图像的标签采用平均的策略,文献[5]采用伪标签的策略,对生成图像采用最大概率预测为其分配身份,作为具备真实标签的数据使用。文献[6]提出一种识别模型与GAN中的判别器共享权重进行联合优化。文献[7]基于不同摄像机类内差异,生成不同相机风格的行人图像。此外,最近的一些研究学者开始将姿态估计应用到GAN网络中。文献[8]为减小姿态不同对行人外表的影响,使用PN-GAN将数据中的所有行人归一化到8个姿态中,将真实数据中提取到的行人特征和生成数据中提取到的行人特征融合之后做ReID匹配。文献[9]提出一种基于姿态迁移的 ReID 框架,通过引入姿态样本库,进而生成多姿态标签样本。文献[10]利用姿态引导的 GAN 网络,学习与身份相关且与姿态无关的特征,使得生成的行人图像与姿态特征无关。不同于上述算法,也有学者将不同特征进行融合得到新的特征表示。文献[11]提出一种多尺度残差网络模型,融合不同的特征得到最终的特征表示。文献[12]提出一种融合了全局特征、局部特征以及人体结构特征的行人再识别算法,该算法无需引入任何人体框架先验知识,并采用多级监督机制优化网络。文献[13]提出一种利用姿态迁移来生成行人图片,并利用两种不同的独立卷积神经网络提取图像特征,融合两种特征得到最后的特征表示。
不同于上述GAN 网络,本文提出一种基于外观特征和姿态特征混合编码的行人再识别网络,生成模型通过切换外观特征以及姿态特征,结合两幅图像中的特征混合编码生成高质量图像,进一步降低了类内差异造成的影响。网络采用外观损失、姿态损失、对比损失、判别损失等多损失函数对生成的图像进行监督,进一步提高生成图像的质量。利用扩充数据集对网络进行训练,使得网络模型更加健壮。
2 网络架构
网络架构如图1所示。将原数据集中的人物图像输入到生成对抗网络,利用输入图像的姿态特征以及外观特征进行自图像以及互图像生成,将生成的人物图像结合原数据集中的人物图像共同输入到卷积神经网络,对网络进行训练,一方面扩充了原数据集中图像不足的问题,另一方面利用这种自图像与互图像生成模式进一步挖掘了图像的细粒度特征,使得训练的模型更加鲁棒。
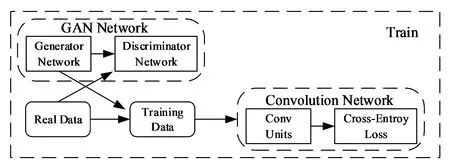
图1 网络架构
2.1 生成网络
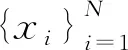
2.1.1 自生成网络

.
(1)
考虑到yi=yj,即为同一行人的不同图像, 行人图像的外观特征是相近的,因此提出一种利用同一行人的不同图像来生成图像的方法。即采用图像xi的姿态特征,仅采用图像xj的外观特征。由于外观特征是相似的,所以基于同一行人的图像生成应该无限接近于原输入图像xi,因此仍然采用像素级的L1损失对其进行训练,损失函数为:
(2)
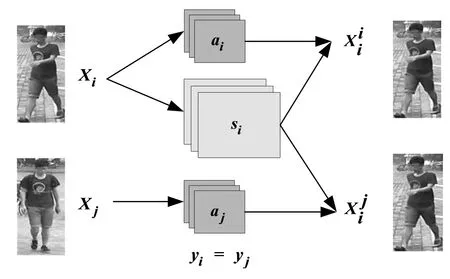
图2 自生成网络

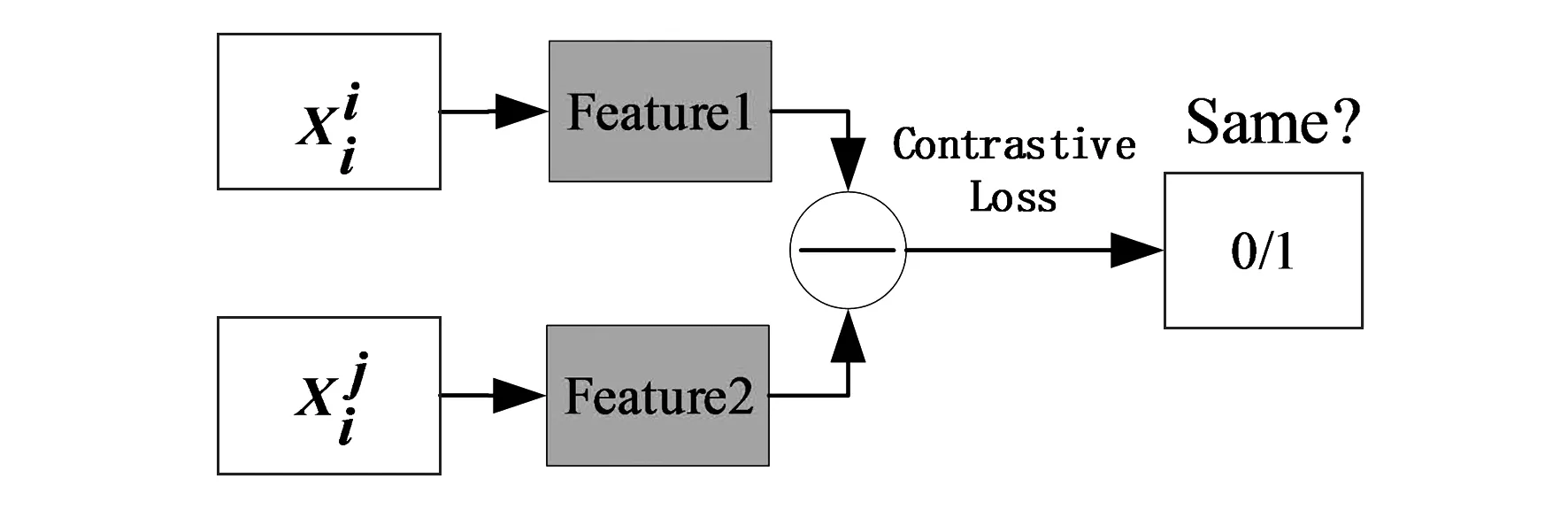
图3 验证网络
d=‖f1-f2‖2
.
(3)
采用对比损失[15]优化网络具体公式如下:
(4)
式中,d表示两个样本特征的二范数,y为两个样本是否匹配的标签,y=1表示匹配,m为设定的阈值,N为样本的个数。
2.1.2 互生成网络
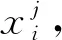
(5)
.
(6)
利用混合编码对原始数据进行图像生成,使得生成的图像更加逼真,一方面,有效扩充了数据集。另一方面,有效减缓了类内差异的影响。采用多损失优化网络进一步提高了图像的真实性,有效解决了行人不够真实、图像模糊、背景不真实等问题。
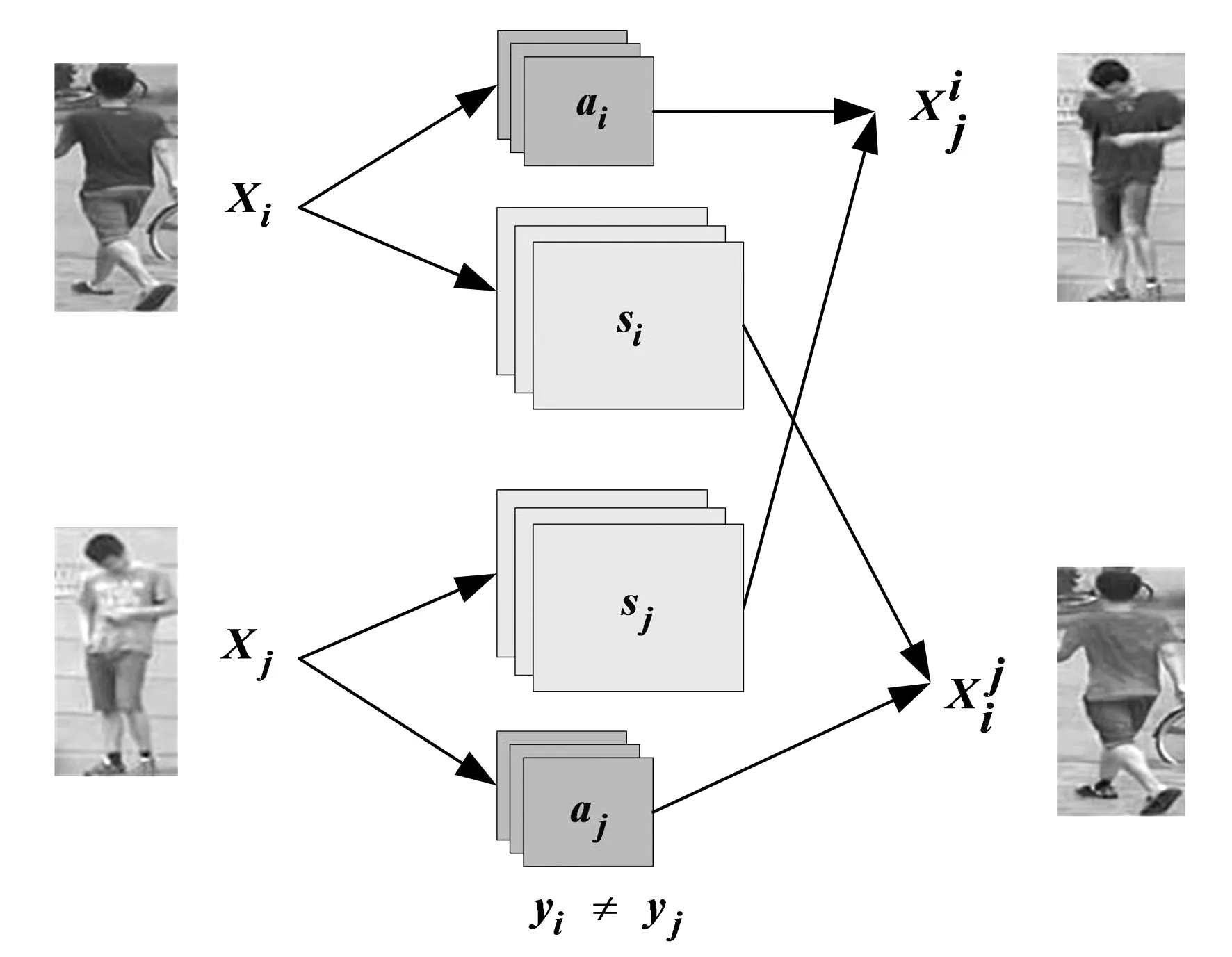
图4 互生成网络框架
2.1.3 基于外观特征的ID分配
网络提取了人物图像的姿态特征以及外观特征,由于行人图像在不同摄像机的视角下姿态是各异的,所以姿态特征并不具备区分不同行人的特性。在跨摄像机视角中,外观特征的不变性可以作为区分不同属性的行人。考虑到这个问题,首先训练一个基于外观特征对行人图像进行身份鉴别的网络模型,提取原始数据集中所有图像的外观特征,保留其标签属性,采用交叉熵损失对网络进行训练,损失函数如下:
(7)
式(7)为单个样本的损失,总样本的损失可以表示为:
(8)
(9)

2.2 判别网络
生成器G和判别器D在极小极大博弈中扮演了两个竞争对手的角色,D作为一个判别网络(如图5所示)将原数据集图像与生成图像共同输入到判别网络,提取特征利用交叉熵损失优化判别网络。
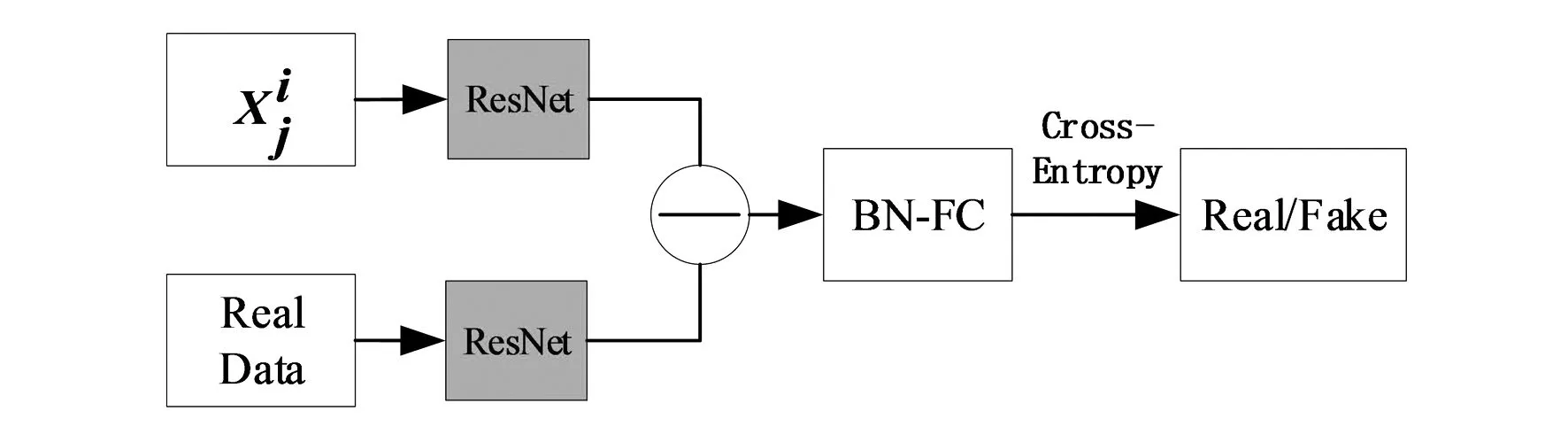
图5 判别网络模型
网络优化的目的是让D(xi)无限接近于1,D(O(ai,sj))尽可能大,使用对抗性损失[16]来匹配生成图像的分布与真实数据的分布如下:
L3=E[logD(xi)+log(1-D(O(ai,sj)))],
(10)
式中,D(xi)表示判断真实图片是否真实的概率。
对于相同的框架特征,将使用不同的外观特征进行图像合成的图像属性视为与提供框架特征的行人具有相同的身份属性。也就是说,可以看到同一位行人穿着不同的衣服,这迫使网络模型学习与衣服等特征无关的特征表示,从而迫使网络模型挖掘出更多的判别特征(图,背包等),进一步挖掘图像中的细粒度信息,并增强网络模型的鲁棒性。损失函数可表示为:
(11)
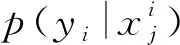
2.3 目标函数
在训练阶段,网络优化了外观损失姿态损失、验证损失、以及判别损失作为优化的总目标,如式(12):
(12)
2.4 网络设置
基于PyTorch深度框架搭建网络模型,在训练阶段,采用ResNet50作为基准网络提取外貌特征,训练的基线网络仅仅依据外貌特征对图像进行分类。采用残差块与卷积层组合的轻量级网络[17]提取姿态特征。验证网络采用了DenseNet121[18]提取生成图像的外貌特征。生成网络[19]是由残差块经过下采样输入到卷积单元组成的,判别网络[20]是由6个卷积层和一个残差块组成。所有图像的宽高比为128×384,参数m设置为1,并且通过SGD方法优化和迭代网络。初始学习率设置为0.001。
3 实验数据库
3.1 数据集
本文提出的行人再识别算法在公开的数据集Market1501[21]、DukeMTMC-reID[22]上进行实验并取得不错的效果。本文使用累积匹配特征曲线(CMC)和平均精度均值(mAP)两个指标来衡量模型的性能。表1列出了数据集的详细信息。
Market1501是一个大型的行人数据集,采集了6个摄像机的数据,包含751个行人的12 936张训练图像, 750个行人的19 732张测试图像,边界框直接由可变形零件模型(DPM)[23]检测,这更接近于真实的场景,采用训练集中的12 936张图像训练网络,在single-shot模式下进行。
DukeMTMC-reID是由8个摄像机采集的1 812个行人图像,在数据集中有1 404个行人出现在两个摄像机以上的视角中,随机选择702个行人的图像作为训练集,剩余702个行人图像作为测试集。

表1 数据集详细信息
3.2 生成图像示例

图6 生成图像示例
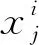
3.3 实验结果
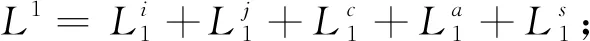
本文对提出的利用姿态特征以及外貌特征混合编码的行人再识别算法与现有的行人再识别算法进行了比较,如表3所示。表3中分割线以上为未采用生成图像扩充数据的算法,分割线以下为采用生成图像辅助训练的算法。由表中的实验数据可以看出,采用姿态特征和外貌特征混合编码的行人再识别算法后,在Market1501数据集上的表现效果较好,Rank-1仅比PCB算法稍低0.4%,但mAP的性能却高于PCB算法0.6%;在DukeMTMC-ReID数据集上的Rank-1仅仅低于Part-aligned、Mancs算法不到一个百分点,而mAP的性能仅低于Mancs算法。综上所述,本文提出的算法在两大公开的数据集上表现效果较好,Rank-1、mAP评估指标能优于现有的大部分主流算法,可以看出所提算法的优越性。
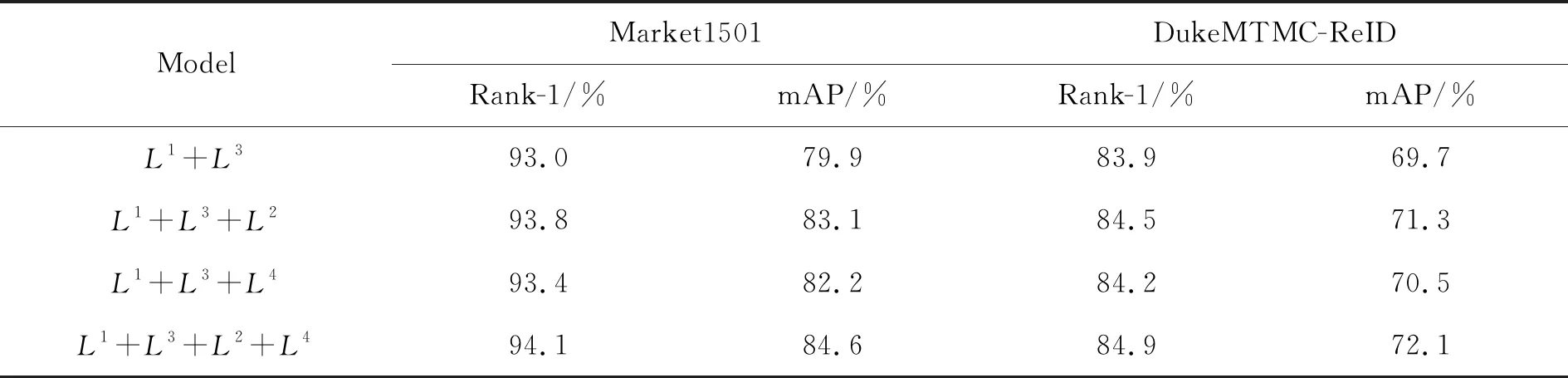
表2 不同损失函数对模型的影响

表3 本文算法与现有算法进行比较
4 结 论
本文提出一种利用姿态以及外观特征混合编码生成图像的行人再识别算法。采用多损失监督的方式修正生成图像,使得生成模块与判别模块是一个在线的交互循环,使得两者相互受益。生成模型通过切换外观特征以及结构特征,结合两幅图像中的特征混合编码生成高质量图像,判别模型将生成图像的外观特征反馈给生成模型的外观编码器,通过联合优化,进一步提高生成图片的质量。一方面,解决了数据集不足的问题,另一方面,进一步解决了行人图像不真实、模糊、背景不真实等问题。这种利用扩充数据集训练网络的方式,使得网络模型更加鲁棒。两个数据集的实验结果显示,算法的Rank-1指标相比于FD-GAN方法提升了2.9%、4.3%,相比于mAP提升了4.5%、6%。
