一种无监督学习型神经网络的无人机全区域侦察路径规划
2021-03-02李波杨志鹏贾卓然马浩
李波, 杨志鹏, 贾卓然, 马浩
(1.西北工业大学 电子信息学院, 陕西 西安 710129;2.中国电子科技集团公司数据链技术重点实验室, 陕西 西安 710068;3.中国航空工业集团公司西安航空计算技术研究所, 陕西 西安 710068)
无人机路径规划是指在任务空间中设计一条从起点到终点使得无人机飞行代价最优的航路,但是这种点对点的路径规划不能够覆盖全部任务区域[1-2]。在现实中,例如农药喷洒、地图测绘、战场侦察等应用场景都依赖全覆盖路径规划,因此开展全覆盖路径规划算法研究具有重要意义。
在全区域覆盖领域,国内外学者做了大量的研究。随机覆盖策略方法[3]在机器人遇到障碍物无法继续直行时就随机旋转一定的角度继续前进。分块法[4]是通过障碍物的边界对任务空间进行划分,然后在完整任务空间连接图中使用深度优先搜索的方法保证机器人访问每个任务子空间,实现对任务空间的完全覆盖。模板法[5]是根据先前信息来定义机动决策模板,并根据机器人所处环境的信息与各个模板进行匹配,选择合适的运动策略并且不断重复该过程进行区域覆盖。
由于随机策略无法确保全覆盖且效率较低,分块法需要已知探测环境,模板匹配的方法存在无法处理动态环境等问题[6]。针对上述不足,能够通过训练达到自适应的神经网络引起了我们关注。
复杂结构的神经网络在输入信息充足的情况下,能够较为准确地逼近任意连续的非线性函数[7]。传统的神经网络学习模式大致可以分为2种,即:有监督学习、无监督学习。神经网络有监督学习就是通过训练样本来学习输入与输出之间隐藏的规律,再利用学习得到的规律将新的输入数据送入网络并得到推算的结果[8]。而对于本研究的输入、输出都是在一定区域内的连续值,在没有训练数据的情况下,很难根据全区域覆盖的任务需求去设计每一种情况的值。综上所述,无人机基于神经网络全区域侦察路径规划面临的问题有:环境信息未知,先验知识匮乏,网络不具有解搜索空间,样本数量获取有限等。
现有的遗传算法及其改进型遗传算法同神经网络的结合都是为了提高神经网络的计算精度,并且改进其易陷入局部极小值等问题,对网络的权值与阈值进行了优化[9]。
本文提出对神经网络通过遗传算法进行无监督训练的学习方法来完成全区域覆盖路径规划,主要包括:①结合无人机威胁探测、区域搜索等信息,构建神经网络输入,设定无人机引擎推力大小为神经网络的输出,实现神经网络对无人机运动的直接控制;②根据无人机是否满足威胁约束、机动约束、全新区域探测等条件,构建适应度函数,利用遗传算法使神经网络进行无监督学习,训练后的神经网络能够完成无人机状态输入到动作输出的有效映射,实现无人机自主侦察路径规划和威胁规避;③加载在确定环境下无人机离线学习的控制模型数据,实现了复杂未知环境下无人机全区域侦察路径规划,验证了本文所构建模型的迁移能力和泛化能力。
1 无人机全区域侦察数学模型
1.1 栅格法环境建模
采用栅格法来表示环境信息。设环境的最大长度为L,宽度为W。考虑机载侦察设备的侦察能力影响,设定正方形栅格的边长为D,则栅格的总数目为L/D×W/D。
环境中包含诸如敌方雷达、防空火炮的威胁;还有自然环境中山峰和恶劣气象的威胁。本文使用一系列点组成的多边形来表示上述威胁。当某个栅格超过一半的面积被威胁所覆盖,则该栅格所覆盖的面积均被定义为威胁范围,否则为可飞范围。
1.2 无人机模型
无人机由于受到飞机性能的约束,在进行全区域侦察时并不能按照任意路径飞行。因而在进行无人机路径规划的时候为了使航迹真实可飞,必须考虑飞机过载、最小转弯半径、最大飞行距离等制约条件。本文中无人侦察机飞行高度恒定在5 000 m,最大飞行速度为200 m/s。

图1 无人机等高盘旋受力图
图1表示无人机正常盘旋时作用在飞机上的诸外力。由图1可以得到如下方程组:

(1)
式中:P为发动机推力;Q为阻力;Y为升力;G为飞机重力;V为速度;γ为滚转角;R为转弯半径。
当飞机结构强度或升力特性允许的最大过载为ny时,由(1)式可得最小转弯半径Rmin
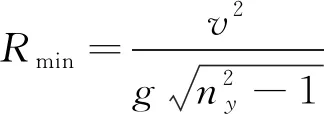
(2)
无人机传感器分为两部分,一部分是用于探测各式环境信息的机载雷达,另一部分是挂载在飞机下方的光电吊舱。其中机载雷达能够对无人机周围的威胁进行探测,并且可以对周围环境的侦察情况进行感知。
根据机载吊舱的工作性能和无人机的飞行高度,本文中无人侦察机能够完成一定范围内正方形区域的信息采集和拍照过程。
1.3 评价指标
无人机全区域侦察任务要求无人机对整个任务空间进行探测并自主躲避各种威胁。为了定量分析算法的性能,本文定义了如下评价指标。
1) 覆盖率
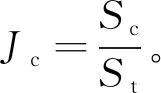
2) 路径重复率
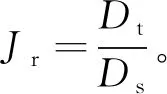
3) 高频重复率
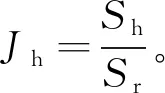
2 神经网络下的无人机全区域侦察路径规划
2.1 神经网络的构建
无人机在发展初期普遍使用比例-积分-微分控制理论和线性控制方法对飞行进行控制。但是无人机发展的终极目标是摆脱人类直接参与控制决策。所以要求无人机能够根据自身状态和外界环境信息进行自主的飞行姿态、航迹规划和作战决策方面的控制,这是传统控制方法所不具备的能力。
神经网络在这一应用场景中表现出良好的能力,因为神经网络善于找寻输入与输出之间的映射关系。同时人工神经网络能够通过自学习来不断优化自身的网络结构,从而达到更好的控制效果。本文意在构建一个前向神经网络,控制无人机的机动决策,并最终完成全区域侦察任务。
2.1.1 输出层
无人机向前飞行的速度由2个引擎的合力决定。通过改变左、右2个引擎推力的相对大小可以使飞机进行转向机动,故设定神经网络的输出为左、右引擎的推力大小(al,ar)。当发动机接收到神经网络的输出后,可以调整引擎推力F=(al,ar),实现无人机飞行姿态的调整。
为了对无人机进行连续控制,神经网络的输出值应该是连续变化的。本文采用logistic函数作为激励函数,如图2所示。
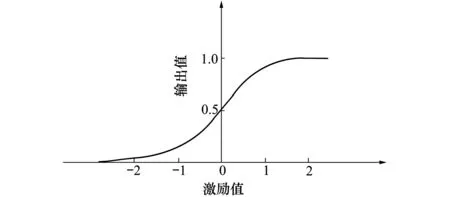
图2 S型曲线
当神经元的激励值趋于正无穷时,函数值逼近1;当激励值趋于负无穷时,函数值逼近0。当激励值为0的时候函数值为0.5。S形函数如(3)式所示

(3)
式中:e为自然常数,其值近似为2.718 3;a是神经元的激励值,即S形函数的自变量;p为S形函数变化率。
2.1.2 输入层d1
无人机将机载雷达探测到的数据作为神经网络的输入,如图3所示。设定传感器个数j=5,利用传感器分别测量无人机正右方、右前方、正前方、左前方、正左方威胁指数s1~5,其中
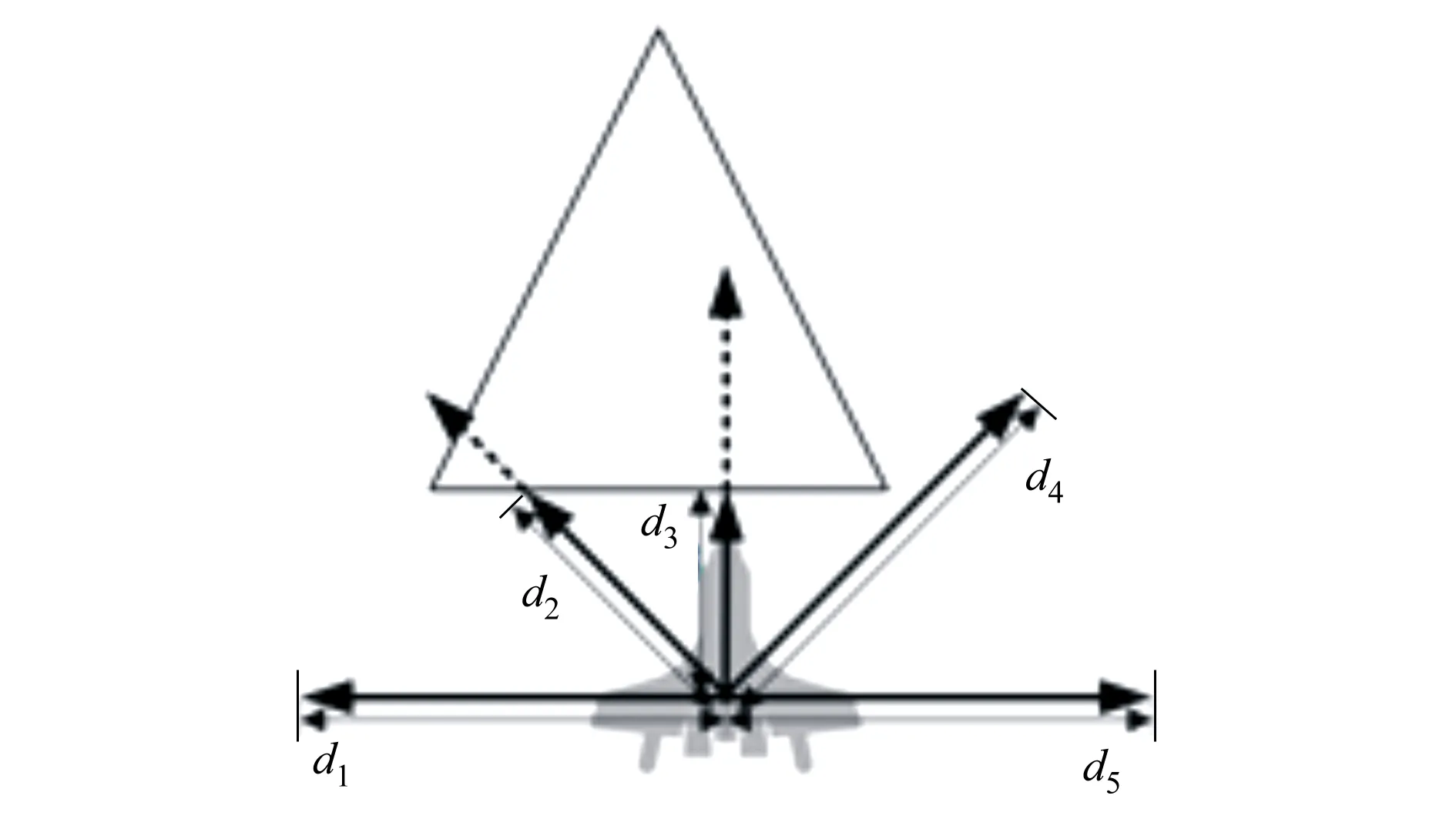
图3 机载雷达探测威胁读数
(4)
式中:sj表示第j个传感器测量的威胁指数;dj表示第j个传感器测量到的无人机与威胁边界的距离值;d为传感器的测量范围。为了防止无人机与威胁边界距离过近(即无人机与威胁边界的距离已经小于最小转弯半径),需要检测每个传感器返回的读数是否都大于安全距离。
除此之外本文希望无人机根据已经探测过区域的信息优先去探测还未被侦察的区域。如图4所示,栅格化地图的每一个区域都存储着无人机在该栅格中停留的步长数,无人机传感器能够探测其末端位置所处方格中的停留步长数t1~5,因此可以得到无人机传感器区域搜索信息为

(5)
式中:tj为无人机在第j个传感器末端所处方格内的停留步长数;tmax为无人机最大停留步长数。本文设定tmax=30,表示当无人机在方格内停留超过30步时,区域搜索信息mj的示数恒为1。
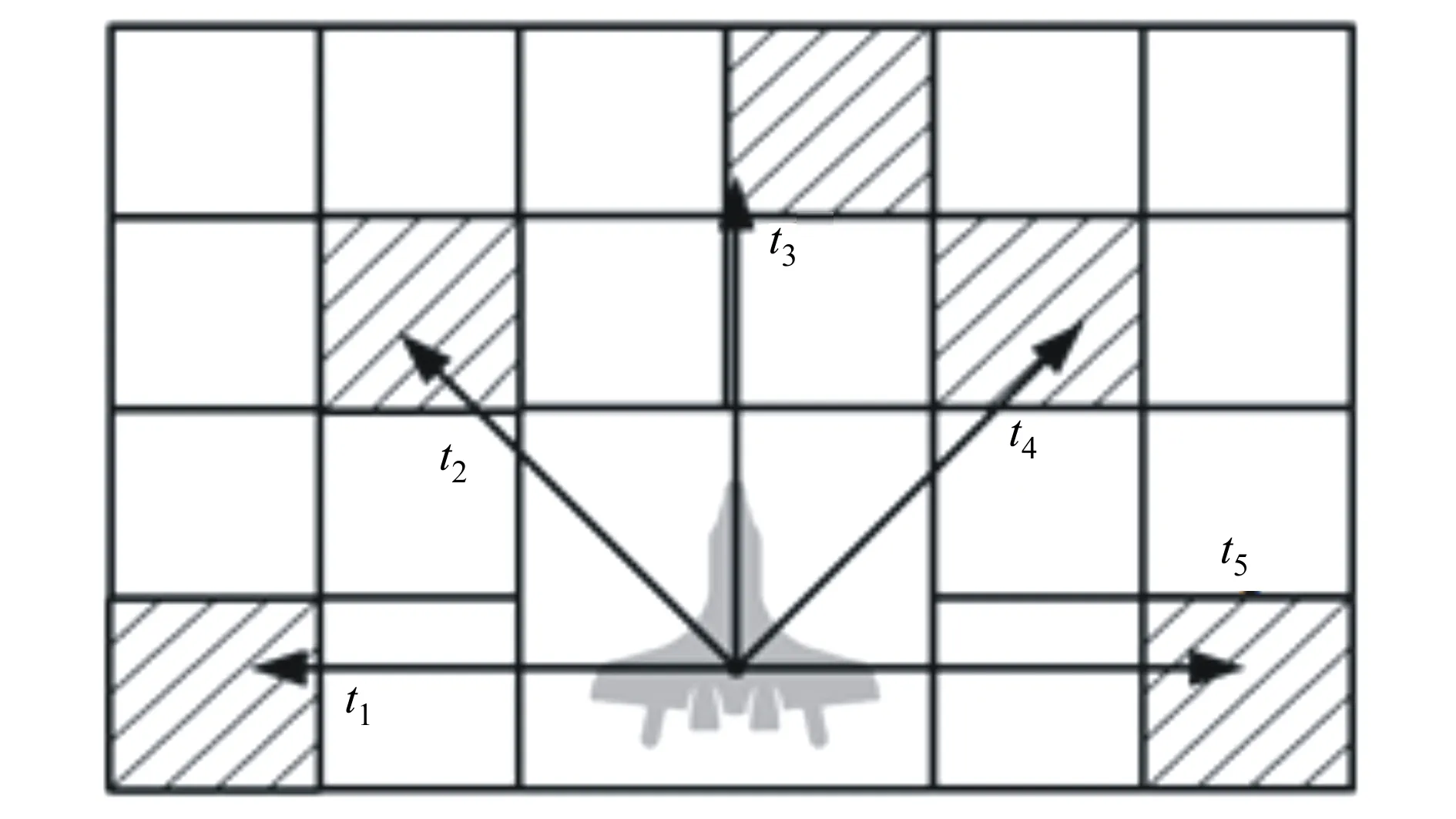
图4 雷达探测到访信息读数
因此,结合无人机威胁探测、区域搜索信息和无人机位置(x,y),最终设定神经网络的输入为
S=[s1,s2,s3,s4,s5,m1,m2,m3,m4,m5,x,y]
(6)
2.1.3 隐藏层及神经元个数的确定
本研究通过大量的实验发现在隐藏层数为1、神经元数为6时神经网络的性能最佳。图5为控制无人机进行全区域侦察的神经网络结构图。

图5 神经网络结构图
2.2 神经网络的无监督学习模型
传统的神经网络学习模式大致可以分为2种,即:有监督学习、无监督学习。有监督学习依赖训练样本,通过训练样本调整神经网络的权值,从而找寻输入与输出之间的关系。通过2.1节可知,本文中神经网络的输入与输出均是一定区域内的连续值,并不是0或1的布尔值。在没有训练数据的情况下,很难根据全区域覆盖的任务需求去设计每一种情况的值。所以需要使用无监督的学习方法来优化执行无人机全区域覆盖的神经网络。
在没有辅助信息和解搜索空间知识的条件下,遗传算法是一个有效的方法。该算法可以基于任务背景直观的对适应度函数进行设计,从而进行个体的评价与选择,并在此评价基础上进行遗传操作。这一特点使得遗传算法能够适应不同的应用场景。
神经网络无监督学习模型的执行过程如图6所示。神经网络的输出控制着无人机的飞行决策,离线学习阶段中每个仿真步长内的飞行决策组成了执行任务的飞行轨迹。将适应度函数作为决策的优化函数,根据执行任务的飞行轨迹对无人机神经网络进行打分,然后判断解集合中是否有满足算法终止条件的解。如果没有就利用遗传算法对网络参数进行优化并更新网络参数,然后重复之前的步骤。

图6 无监督学习模型
2.2.1 染色体编码与初始化
初始条件下的神经网络权值是在极值的区间中随机生成的,通常初始条件下的网络表现是极差的。遗传算法通过对初始种群中每个个体的表现进行打分,从中挑选优秀的个体进行遗传,以此来不断优化神经网络的权值。
2.2.2 适应度函数
全区域侦察任务要求无人机能够在神经网络的控制下自主的躲避威胁,那么适应度函数必须能够反映无人机规避威胁的能力。同时,该适应度函数需要满足无人机的机动约束。考虑到无人机应该优先探索未侦察的区域而不是在有限的区域内进行重复搜索,适应度函数F还需要体现对无人机完成全新区域侦察的评价。综合考虑以上因素,本研究中设定适应度函数F为
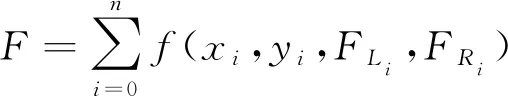
(7)
总适应度得分由所有仿真步长内的适应度得分求和所得,n为全区域覆盖任务总共花费的仿真步长数目。第i个仿真步长的适应度得分由无人机质心所在位置(xi,yi)和无人机左右引擎的推力FLi和FRi共同决定。
(8)
其值由三部分组成,如(8)式所示:c(xi,yi)为无人机满足威胁约束集的奖励得分,d(FLi,FRi)为无人机满足机动约束集的奖励得分,g(xi,yi)为飞行到全新区域的奖励得分。

(9)
式中,A为以(xi,yi)为圆心、Rmin为半径的圆。当传感器测量范围内无障碍物(s1~5=1)或无人机可飞区域A与威胁区域Ω不重合(A∩Ω=Ø)时,视为无人机满足威胁约束集,会得到1分;否则得到0分。此外
(10)
式中:r(FLi,FRi)为实际转弯半径;Rmin为最小转弯半径。通过判断无人机实际转弯半径是否小于最小转弯半径来确定无人机是否满足机动约束集。如果满足约束则得到1分,否则0分。
(11)
式中:Ψ(xi,yi)表示点(xi,yi)所在栅格的无人机停留时间;k1为初次侦察栅格奖励系数,k∈N*。通过第i个仿真步长中无人机的位置坐标确定所在栅格无人机是否已侦察,若未侦察则增加k1分。
2.2.3 个体选择、交叉变异方法
本文使用精英选择对种群中的个体进行挑选,精英数目为4。交叉方式选择常用的两点交叉方式。变异操作用变异位的权值加上一个-1到1的扰动值实现。
2.2.4 神经网络优化迭代停止条件
迭代过程中满足下列2个条件中的任何一个时,算法终止。①无人机完成全区域侦察任务;②遗传算法的演化次数达到预定的最大阈值。
3 仿真实现及结果分析
3.1 仿真系统说明
本仿真实验设定环境长72.5 km,宽52.5 km,栅格边长2.5 km,考虑到威胁环境占比,真实的无人机侦察航程小于标准无障碍飞行距离De=1 575 km。为保证无人机在燃油耗尽前飞行收集到有效样本,设定最大仿真步长数为8 000,即无人机应当在8 000 s完成全区域侦察任务。
仿真系统各个模块的结构关系如图7所示。无人机的类型决定了执行任务的类型,本文中是全区域侦察任务。无人机的正常飞行需要数字地图的支持,数字地图模块把真实环境变成无人机能够理解的形式。任务模块能够对任务的完成情况进行评估,然后遗传算法模块根据其评估结果去优化神经网络中的权值。神经网络模块提供对无人机飞行的控制,确保其能规避威胁并且高效地完成任务。最终UI模块把无人机的飞行状态、数字地图的外观和任务的完成情况进行展示。

图7 仿真系统结构图
仿真系统中离线学习功能实现了侦察无人机通过对加载地图的演化式学习过程,最终得到控制无人机进行自主避障和完成全区域侦察任务的神经网络参数。其中离线学习过程如图8所示,其中浅蓝色的飞机代表飞行状态正常,而浅红色的飞机代表由于碰撞到威胁而坠毁。本文用蓝色线条绘出了得分最高飞机的飞行路线。当每一代的无人机在进行8 000个仿真步长飞行的时候,会根据其飞行表现对每个个体进行打分。遗传算法会在这8 000个步长后利用精英选择法挑选个体进行遗传,并以此来不断优化控制无人机进行全区域覆盖的神经网络。

图8 离线学习过程
演化过程中最高适应得分和平均适应得分的变化趋势如图9所示。随着演化代数的不断增加,前200代的最高适应分数和平均适应分数提升较快。这说明由学习所得的神经网络控制的无人侦察机能够越来越好地完成全区域覆盖任务。随着演化的进行,虽然分数提高的速度逐渐减慢,且出现了小幅的震荡,但是最高适应得分保持收敛的趋势。
加速优化功能利用之前离线学习的学习成果,能够在较短的演化过程中快速提升适应度得分,从而大幅度减少了无人机从零开始学习避障和全覆盖的时间成本。当使用神经网络的先验知识对环境未知的地图进行全区域侦察时,在加速优化的模式下,无人机通过较少的演化次数就能得到较高的适应度分数,取得良好的学习效果。图10和图11分别对神经网络进行50次的演化,可以发现使用加速优化模式获得的适应度分数更高,达到了55 923;并且加速模式下适应度函数能够快速达到收敛条件。所以加速优化模式使得无人机不再需要从蹒跚学步开始,而只需要根据地图的特殊性,对神经网络的权值进行优化即可。

图9 最高与平均适应度得分变化曲线 图10 加速优化模式下适应度分数的变化曲线 图11 离线学习模式下适应度分数的变化曲线
在线应用功能提供了验证学习所得神经网络参数的功能,如图12所示,无人机能够有效规避威胁并执行高效的覆盖机动策略。红色越深的区域表示无人机在该栅格内停留的仿真步长数目越多。考虑到不同飞行环境下的无人机面对的大气威胁、地理环境威胁不同,为了验证算法的通用性,我们将训练好的结果迁移到复杂多威胁环境中。如图13所示,在复杂多威胁环境中,尽管路径重复率有所提高,但无人机依然可以安全完成全区域侦察。这表示经过训练的神经网络模型,能够适应复杂的未知环境,可以迁移至不同环境下的无人机侦察任务中。

图12 简单环境下的在线应用 图13 复杂环境下的在线应用
3.2 仿真结果分析
3.2.1 算法有效性分析
使用离线学习得到的神经网络权值,在同一地图内运行50次在线应用,求取平均值后得到覆盖率分别为90%,95%,99%,100%时的路径重复率和高频重复率,如表1所示。
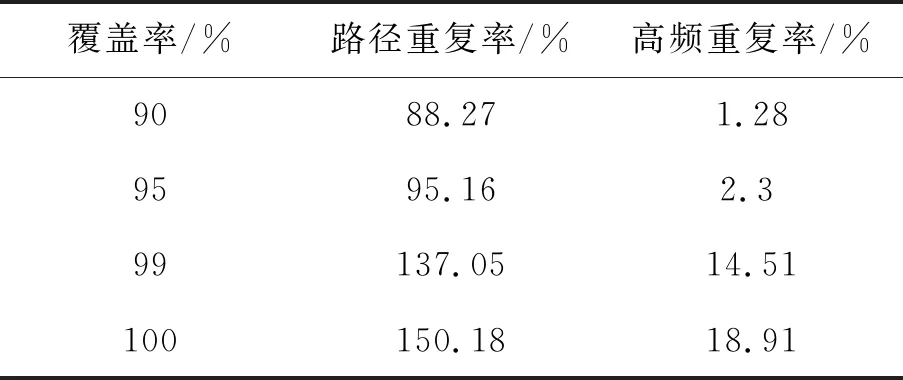
表1 不同覆盖率下的高频重复率
从覆盖率与重复率的对应关系可以发现,无人机已侦察区域面积达到任务要求的95%时,所飞行的距离和地图的标准全覆盖路程相当,高频重复率为2.3%说明算法能很快跳出局部最优。在适应性分数的指引下,该系统已经将规避威胁和快速进行全区域侦察的机动策略转化成为神经网络中的权值。这一表现是令人满意的,因为无人机没有任何先验知识,而仅是通过遗传算法来不断优化控制无人机的神经网络参数。在覆盖率从95%达到100%这一过程中,路径重复率和高频重复率均增加较快。这说明当大部分区域被侦察后,无人机想要从已侦察的区域中规划出一条能够到达未侦察栅格且不经过已侦察栅格的路线是比较困难的一件事情。由此可得出,覆盖率低于95%时,无人机能够高效的规划侦察的线路。随着覆盖率不断接近100%,无人机通常需要飞行一些重复的路径才能到达未侦察过的区域,最终全区域侦察任务完成时路径重复率近似为150%。
3.2.2 算法通用性分析
本文将图8中地图训练得到的神经网络参数导入到图12中地图进行在线应用,进而对比无人机在离线学习和在线应用中执行全区域侦察任务时路径重复率的变化情况,如图14所示。

图14 不同覆盖率下的路径重复率变化曲线
分析该变化曲线可以得到,当无人机侦察覆盖率在95%以下时,离线学习中训练得到的神经网络权值在在线应用中有良好的表现,两者的路径重复率差值保持在2%以下。随着覆盖率的提升,地图的特殊性逐渐显现。虽然最终无人机在在线应用中完成全区域侦察任务的路径重复率较离线学习高出11%,但无人机在环境信息未知的条件下借助离线学习的神经网络参数成功完成全区域侦察的任务。这说明无监督学习型神经网络下的无人机全区域侦察路径规划算法能够帮助无人机在环境信息未知的条件下完成全区域侦察任务。
4 结 论
传统的全覆盖路径规划算法需要根据威胁对任务空间进行划分或者储存机动模板。这就使得传统全覆盖路径规划算法无法在环境信息未知和环境信息动态变化的情况下使用。
本文提出无监督学习型神经网络的无人机全区域侦察路径规划算法,能够使无人机在离线环境下学习对障碍物的有效规避和整个任务空间高效的侦察。实验数据表明,本文离线学习所得的神经网络能够控制无人机完成全区域侦察任务,并且在不同的环境信息下能够进行迁移,具有良好的通用性。
