基于生成对抗网络的多标签节点分类研究*
2021-03-01陈文祺汪洪吉
陈文祺,王 英,3,王 鑫,汪洪吉
(1.吉林大学计算机科学与技术学院,吉林 长春 130012;2.吉林大学人工智能学院,吉林 长春 130012;3.吉林大学符号计算与知识工程教育部重点实验室,吉林 长春 130012)
1 引言
近年来,随着互联网技术的不断发展,互联网应用层出不穷,越来越多的人们在互联网上进行工作和娱乐,互联网逐渐深入人们生活的方方面面,其所承载的信息量与日俱增,大数据这一概念应运而生。在这些信息数据中,既有图像、视频和文献资料这种保存信息的数据,也有保存信息之间关系的数据,而后一种信息数据就是以社交网络和引文网络等为代表的结构化数据。这些结构化数据是由节点和边组成的图结构,节点可能是图像、视频和文献资料这种保存信息的数据,而边则是节点与节点之间的连接关系,如论文与论文之间的引用关系等。
随着大数据时代的来临,从互联网上浩如烟海的数据中获得想要的信息就成了当务之急。而数据挖掘技术就是通过提取数据和变量之间的相互关系获得精炼数据的技术,被广泛应用于社交网络和推荐系统中,其本质是对上述图结构数据中的节点进行分类,从而获得节点隐藏的其他特征。
数据量疯狂增长,随之而来的是处理数据、从数据中获得有用信息愈发艰难。加拿大多伦多大学教授Hinton等人[1]在神经网络的基础上提出了深度学习的概念,他们发现多层人工神经网络模型在特征学习方面有很好的表现,该学习模型学习到的特征数据相比于原始数据能够表现出更深层的内涵,这种数据能够更好地应用于分类和可视化问题,同时可以采用逐层训练方法来解决神经网络很难训练到最优的问题。在这之后,研究人员基于深度学习提出了各种应用于不同领域的模型,例如卷积神经网络CNN(Convolutional Neural Network)[2]模型就是一种通过卷积层和池化层来进行特征提取的深度学习模型,其在图像识别等领域的应用取得了辉煌的成就。
深度学习模型一般分成3种:第1种为生成型深度结构,这种结构旨在描述数据的高阶相关特性或观测数据和相应类别的联合概率分布,例如自编码器和深度置信网络等;第2种为判别型深度结构,这种结构旨在为模式分类提供分辨能力,通常描述数据的后验分布;第3种则是混合型深度结构,这种结构同时包含了生成模型和判别模型,典型的例子就是生成对抗网络GAN(Generative Adversarial Network)[3]模型。该模型包含一个生成模型和一个判别模型,其中生成模型的目的是捕捉真实数据的分布,判别模型的目的则是判断输入的是真实数据还是生成的样本,二者之间通过Maxmin博弈来进行优化。这种模型应用到了多个领域,并取得了较好的成绩。
网络嵌入是生成对抗网络可以应用的一个方向,对于节点分类来说,通过网络嵌入得到特征向量是极其重要的步骤,由此通过生成对抗网络获得的特征向量有助于获得更好的节点分类效果。基于此,研究人员提出了图生成对抗网络GraphGAN(Graph Generative Adversarial Network)[4],一种利用生成对抗网络来拟合其真实连通性分布的模型,通过该模型得到的拟合真实连通性分布的特征向量在链接预测、节点分类和推荐系统中的应用都取得了优异的成绩。
因此,采用生成对抗网络的方式将节点映射到低维空间,保持真实连通性分布以获得不同邻居的信息,以此来进行节点分类是一种可行的方案,为大数据时代进行数据挖掘提供了一条新的思路,具有一定的理论研究和参考价值。
本文第2节介绍相关工作;第3节阐述生成对抗网络模型的具体构造;第4节通过生成的节点特征向量矩阵来进行节点分类并与其他模型进行对比,以测试所提模型的可行性。
2 相关工作
节点分类作为数据挖掘技术的一种应用,通过节点的各种信息进行分类,能够解决很多问题。对于引文网络和社交网络等网络结构数据来说,要将网络中的节点进行分类,要考虑的不仅仅是节点本身蕴含的信息,还有节点之间的连接信息。
传统的节点分类方法可以分为2种。一种是基于迭代使用局部分类器的方法,该类方法根据中心节点的节点信息和邻接节点的标签信息来进行节点分类。例如,Neville等人[5]将贝叶斯分类器作为局部分类器,通过训练数据训练贝叶斯分类器,然后选择测试数据中与训练数据中节点存在边的节点,将其特征向量作为输入,贝叶斯分类器输出该节点的标签,不断迭代,直到所有节点分类完毕;Bhagat等人[6]提出了一个最近邻分类器作为局部分类器的方法,即每次将有标签的节点的标签赋予和当前节点相似度最高的节点,经过不断迭代,将标签赋予所有节点;Lu等人[7]将逻辑回归分类器作为局部分类器,把邻接节点的标签作为当前节点的特征向量,并以此来进行迭代分类;Macskassy等人[8]则直接把当前节点的邻接节点标签进行加权平均作为分类结果,然后不断进行迭代以至所有节点的分类结果趋于稳定。
另一种则是通过随机游走来进行分类,这种方法必须假设在图中可以通过有限步数从任何无标签的节点到达存在标签的节点,在此基础上,根据随机游走的概率生成一个状态转移矩阵,并以此矩阵来进行节点的分类。例如,Azran[9]提出了一种利用节点之间的相似性来构造马尔可夫随机游走的概率转移矩阵并对节点进行分类的算法;Desrosiers等人[10]则提出了一种基于随机游走的节点相似度度量算法,并将其应用于节点分类领域。这些传统的节点分类方法需要大量人工定义的变量,同时也不能将节点信息和连接信息考虑周全,更不能通盘地结合两者进行考量。由于传统节点分类方法的局限性,研究人员考虑将其他领域的方法引入节点分类中。
神经网络算法近年来在各个领域取得了长足的进步,甚至在某些方面取得了质的突破。图神经网络是一种可以运行在图结构上的神经网络模型,这种模型利用图中的节点信息和连接信息挖掘图数据中潜藏的信息,并通过借鉴其他神经网络模型产生了各种不同的处理图数据的图神经网络。例如Niepert等人[11]提出的借鉴卷积神经网络的模型,即图卷积神经网络。
生成对抗网络是神经网络的一个分支,自从被提出以来,研究人员陆续提出了几种具有代表性的生成对抗网络模型。例如,(1)条件生成对抗网络CGAN(Conditional Generative Adversarial Network)[12],这种模型的生成模型和判别模型的输入都需要一些条件信息,如标签信息和属性信息等,基于此该模型能生成给定条件的图像。(2)深度卷积生成网络DCGAN(Deep Convolutional Generative Adversarial Network)[13],这种模型是把卷积神经网络引入到生成对抗网络,并进行了以下改进:①将卷积网络中的池化层改为卷积层;②将全连接隐藏层去掉;③对生成模型和判别模型进行归一化;④生成网络使用ReLU激活函数;⑤判别网络使用LeakyReLU激活函数。该模型经过上述改进后具有更强的生成能力,能生成足以以假乱真的图像。(3)信息生成对抗网络InfoGAN(Info Generative Adversarial Network)[14],该模型增加了一个潜在编码,该编码可以包含多个属性,用于调整生成图像的属性。
生成对抗网络经过不断发展,在各个领域内都开花结果,在网络嵌入领域也不例外,GraphGAN[4]模型就是用于将图中的连接信息和节点信息映射到低维空间,以便于进行连接预测和节点分类等。在此模型之前,网络嵌入可以分为2种:一种是生成模型,即假定每个节点都存在一个潜在的真实连通性分布,该分布表示图中其他所有节点上的连通性分布,图中的边被视为由这些条件分布生成的可观察样本,之后通过最大化图中边的似然性来学习网络嵌入。例如,DeepWalk[15]使用随机游走的方法对每个节点的“上下文”节点进行采样,并尝试最大化每个节点的“上下文”节点的对数似然;node2vec[16]则通过一种有偏的随机游走过程进一步扩展了该思想,该过程在为给定节点生成上下文时提供了更大的灵活性。另一种则是判别模型,就是对于训练数据中的2个节点来说,根据2个节点的特征向量和2个节点间边的存在与否来学习节点特征向量和边的存在之间的关系,用以预测测试数据中边是否存在。例如,结构化深度网络嵌入SDNE(Structural Deep Network Embedding)模型[17]使用自编码机,利用多层非线性函数捕捉网络的高度非线性结构,同时利用一阶相似度作为监督信息,保留网络的局部结构,二阶相似度作为无监督学习部分,保留网络的全局结构,从而构成一个半监督的深度学习模型;属性保存网络嵌入PPNE(Property Preserving Network Embedding)模型[18]则是在存在边的节点对和不存在边的节点对上通过监督学习直接学习网络嵌入,在学习过程中还保留了节点的固有属性。尽管生成模型和判别模型可能有很大的区别,但两者并不是2条平行线,GraphGAN模型就是融合了生成模型和判别模型的一种网络嵌入模型。
3 基于生成对抗网络的节点分类模型NC-GAN
为了解决传统节点分类方法存在的问题,本文提出基于生成对抗网络的节点分类模型NC-GAN(Node Classification based on GAN),拟将生成对抗网络引入节点分类,通过结合节点信息和连接信息,将网络中的节点映射到低维空间中,获得更加合理的节点表示,再通过节点表示进行分类,以期获得更好的分类效果。
3.1 模型相关定义

生成器旨在尝试拟合真实连通性分布,在这个过程中生成器生成虚假但逐渐逼近真实的样本节点用以欺骗判别器。而判别器则对生成器生成的样本和真实数据进行判断,在提高判断的正确率的过程中,使得生成器生成的样本更加真实。生成器和判别器通过不断进行的交替最大最小化损失函数来进行优化,该损失函数如式(1)所示:
Ev~G(·|vc)[ln(1-D(v,vc))])
(1)
3.2 生成器的实现
生成器G(v|vc)旨在拟合真实连通性分布pture(v|vc),从图中所有节点的集合V中选择与vc最有可能存在连接的节点,产生样本数据供判别器进行判断,并期望通过生成足以以假乱真的样本降低判别器的正确率。对于损失函数来说,生成器的目的就是将判别器正确分辨的概率最小化。由于生成的样本数据是离散的,本文将通过策略梯度来计算损失函数中参数θG的梯度:
(2)

一种最简单的生成器的实现可以将生成器定义为其他所有节点的Softmax函数,即:
(3)
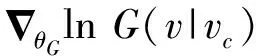
为了解决使用上述Softmax函数作为生成器所带来的问题,本文将使用一种能够解决上述问题的函数来实现生成器。这种函数在计算时仅使用少量涉及到的节点特征向量,并且能够充分地考虑图数据中的节点连接信息,以生成拟合真实连通性分布的样本,即生成样本时2个节点的特征向量乘积越小,且节点之间的相似度越低,两者之间存在边的概率越小。为了实现上述函数,首先要从每一个节点开始,通过以该节点vc为根节点对图数据进行广度优先搜索,得到以vc为根所生成的广度优先搜索树Tvc,那么Nvc(v)就是该广度优先搜索树Tvc中和节点v存在直接连接信息的节点的集合,包括树中该节点的父节点和所有子节点。对于节点v和与其邻接的节点vi∈Nvc(v)之间的相似性概率,定义为:
(4)
式(4)表示的是在广度优先搜索树中的节点v,与其他树中与之邻接的节点之间的相似性概率。该式是引入了注意力机制的结果,使用该式会使得生成样本时更偏向于选择相似度高的节点,从而使得相似度概率越大的节点对更新的影响越大。其中,‖gvi-gv‖2是给定的节点v和邻接节点vi之间的欧氏距离,利用节点特征向量计算得到的欧氏距离可以表示2个节点之间的相似度,欧氏距离值越大,代表2个节点越远,也就是2个节点相似度越低。∑vj∈Nvc(v)e(‖gvj-gv‖2)则是在树中与节点v相邻的所有节点与v之间的相似度之和。用某一个节点的相似度除以所有节点的相似度之和,代表的是后续样本选择中选择该节点的概率以及更新当前节点的概率。
为了获得生成器所需样本,需要利用式(4)计算图数据中所有节点与其邻接节点的相似性概率,并利用该相似性概率进行随机采样。
3.3 判别器的实现
判别器D旨在对生成器生成的样本和真实数据进行区分,通过判断结果对自身进行更新,使自身判断的正确率得以提升。在NC-GAN模型中判别器被定义为2个节点之间特征向量的乘积的Sigmoid函数:
(5)
其中,v和vc是给定的2个节点,dv和dvc是给定节点对应的k维特征向量。式(5)将2个节点特征向量的点乘代入Sigmoid函数中,得到的值就是给定的2个节点之间存在边的概率,特征向量点乘的值越大,2个节点之间存在边的概率越大。判别器以此概率作为对生成的样本和真实连通性分布中的数据进行判断的依据,并根据该概率来对自身进行随机梯度上升更新:
(6)
3.4 样本节点的选取
生成器需要生成样本节点以欺骗判别器,本文根据式(4)所计算的相似性概率来随机选择样本节点。首先从广度优先搜索树Tvc的根节点vc开始进行随机游走,随机游走的状态转移概率矩阵由节点之间的相似性概率组成。在随机游走的过程中,当访问到的节点是上一个节点的父节点时,选择上一个节点作为生成的样本节点。
详细来说,生成样本时可以选择以每一个节点为根的广度优先搜索树来进行随机游走取样,也可以随机选取其中的某一部分节点,从以这些节点为根的搜索树中随机游走取样。对于给定的节点vc,在以该节点为根的广度优先搜索树Tvc中进行随机游走,从根节点开始,通过式(4)计算当前节点和树中父节点与所有子节点之间的相似性概率,并根据这个概率来选择下一个要游走的节点,在随机游走中不断进行迭代,直到第一次选择上一个节点的父节点时,终止迭代,将上一个节点选择为生成的样本。节点vc有几个邻接节点,就生成几个样本供判别器进行判断和更新。生成器对生成样本进行更新时,使用生成样本时经过的路径上的节点对作为更新时的样本。算法1描述了生成器生成样本的过程。
算法1生成器生成样本
输入:给定节点vc,以vc为根的广度优先搜索树Tvc,节点特征向量集合{gi}vi∈V。
输出:对于给定节点生成的样本vgen。
步骤1vpre⟸vc,vcur⟸vc;
步骤2whileTRUEdo
通过式(4)计算vcur与邻接节点的概率,并以此随机选择一个节点vi;
ifvi=vprethen
vgen⟸vcur;
returnvgen;
else
vpre⟸vcur,vcur⟸vi;
end
4 实验与分析
4.1 实验数据与模型
本节分别在数据集arxiv-AstroPh和arxiv-GrQc上进行链接预测对比实验,在BlogCatalog、Wikipedia、CiteSeer和Cora等数据集上进行节点分类对比实验,实验数据集的具体信息如表1所示。
用作对比实验的模型包括:
(1)GraphGAN[4]是使用节点特征向量的点乘来构造生成器的一种图生成对抗网络模型,该模型更偏向于将节点的连接信息投影到低维空间,并不考虑节点之间的相似度,对所有节点一视同仁。
(2)大规模网络编码LINE(Large-scale In-formation Network Embedding)[4]是一种利用图数据中的一阶相似度和二阶相似度来进行网络嵌入的模型。
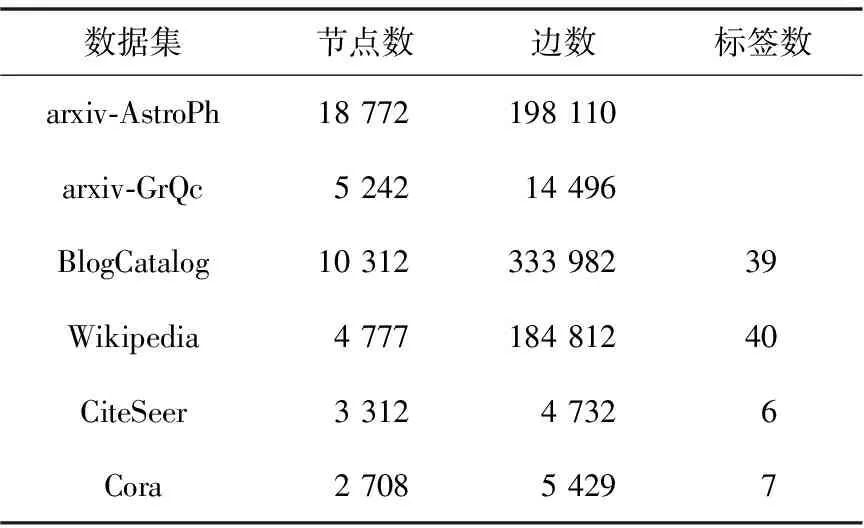
Table 1 Experimental datasets
(3)Struc2Vec[4]是一种从空间结构相似性的角度来计算节点相似度,并将其用来捕捉节点的结构特征以获得网络嵌入的模型。
(4)DeepWalk[15]是针对图表示学习的稀疏性提出的一种学习节点的社会特征的模型,该模型通过随机游走方法从图中提取节点序列,然后用节点序列来训练skip-gram模型,从而学习网络嵌入。
(5)node2vec[16]是DeepWalk模型的一种变体,也是通过随机游走方法提取节点序列,再通过skip-gram模型来学习网络嵌入。但是,在随机游走选择样本节点时,该模型同时结合了深度优先搜索和广度优先搜索,形成了一种有偏的随机游走。
(6)图卷积网络(GCN)[11]是在图神经网络中引入卷积神经网络所形成的一种神经网络。通过对图数据中节点信息和连接信息的提取来产生节点低维嵌入向量,再根据该低维向量来映射得到标签。
对于所有的对比模型,本实验采用默认设置,本文NC-GAN模型在进行梯度更新时,学习率设计为0.001。模型的迭代次数设置为20次,在每次迭代过程中,生成器和判别器的更新步数设计为30步。
4.2 实验结果与分析
本文NC-GAN模型所生成的数据,是将节点信息和连接信息同时映射到低维空间所得到的特征向量矩阵,该矩阵中节点之间的特征向量点乘值可以很好地反映出2节点之间存在边的概率,为了验证生成的特征向量矩阵所蕴含的这种连接信息,本节采用链接预测的方法,将本文NC-GAN模型的生成结果与其他图表示学习模型的生成结果进行对比。而为了验证NC-GAN模型生成的结果对节点分类的效果,本文将其生成的结果通过9∶1的比例使用逻辑回归进行对比。
4.2.1 链接预测
链接预测旨在预测2个节点之间是否存在边,该任务能很好地展现图表示学习所生成的结果中边的可预测性。在实验中,将按照9∶1的比例来划分数据集,以其中90%的数据作为训练数据,另外10%的数据作为测试数据。在训练结束之后,将得到节点的特征向量矩阵,并使用逻辑回归对给定节点之间边的存在概率进行预测。预测时,选择10%的数据集中的节点以及节点之间的边作为正样本,并选择随机断开存在的边的节点作为负样本。对比模型在数据集arxiv-AstroPh和arxiv-GrQc上的预测准确率(Accuracy)和Macro-F1如表2所示。
从表2中可以看出,模型LINE和Struc2Vec并不能很好地获取网络中节点之间的连接信息,在连接预测中表现不好。DeepWalk和node2vec模型对连接信息进行了考虑,在链接预测中取得了不错的成绩。模型GraphGAN则取得了相对来说最好的成绩,由于该模型在生成样本时更偏向于存在边概率更大的节点,最终模型生成的节点特征向量会更加容易判断出边是否存在。本文提出的模型NC-GAN更关注于节点之间的相似度,仅比更专注于节点连接信息的GraphGAN模型在链接预测上稍差一筹。
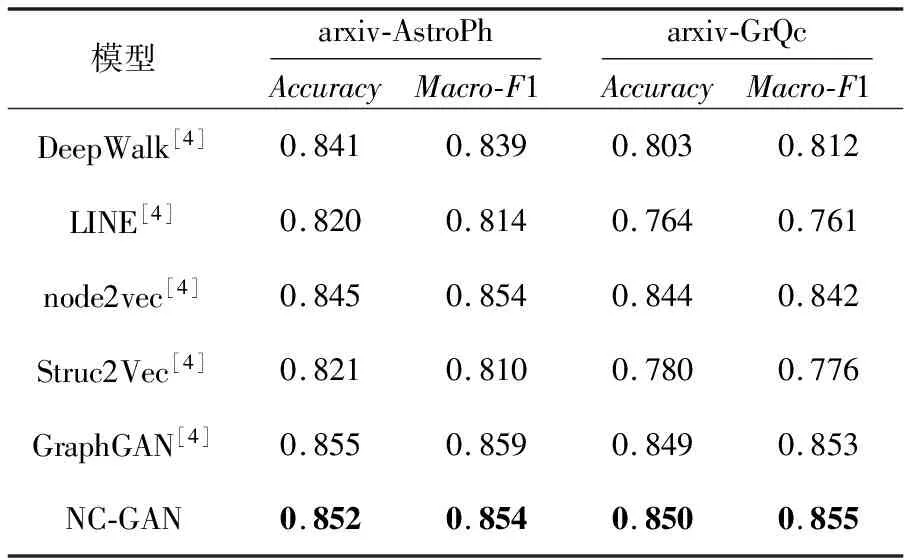
Table 2 Link prediction experiments comparison of each model
4.2.2 节点分类
节点分类旨在通过节点属性信息和节点之间的连接信息,将节点分成不同的类别,以对应不同的标签,以此来获取原始数据中不含有的信息。节点分类实验中将按照9∶1的比例把数据集分为训练集和测试集,通过监督学习在使用训练集进行训练之后,能够在测试集中预测节点所属的类别标签。实验分为2个部分:首先在数据集BlogCatalog和Wikipedia上使用各种使用图表示学习模型获得节点特征向量,再通过逻辑回归对各种模型的结果进行节点分类对比;然后在数据集CiteSeer和Cora上对图卷积网络得到的节点分类效果、使用GraphGAN模型得到的特征矩阵对应的逻辑回归节点分类效果以及使用NC-GAN模型得到的特征矩阵对应的逻辑回归节点分类效果进行对比。对比结果如表3所示。
从表3中可以看出,本文的NC-GAN模型在节点分类上的性能明显优于其他图表示学习模型。LINE 模型注重邻接节点的相似度,不考虑节点连接信息,得到的节点分类效果较差。Struc2Vec模型更关注于节点之间结构的相似度,得到的节点分类效果差强人意。DeepWalk和node2vec更关注于节点之间的连接信息,忽略了节点本身所蕴含的信息,导致节点分类的效果不是很理想。而GraphGAN则是更偏向于获得更加拟合真实连通性的分布,而不是更好地对节点进行区分。
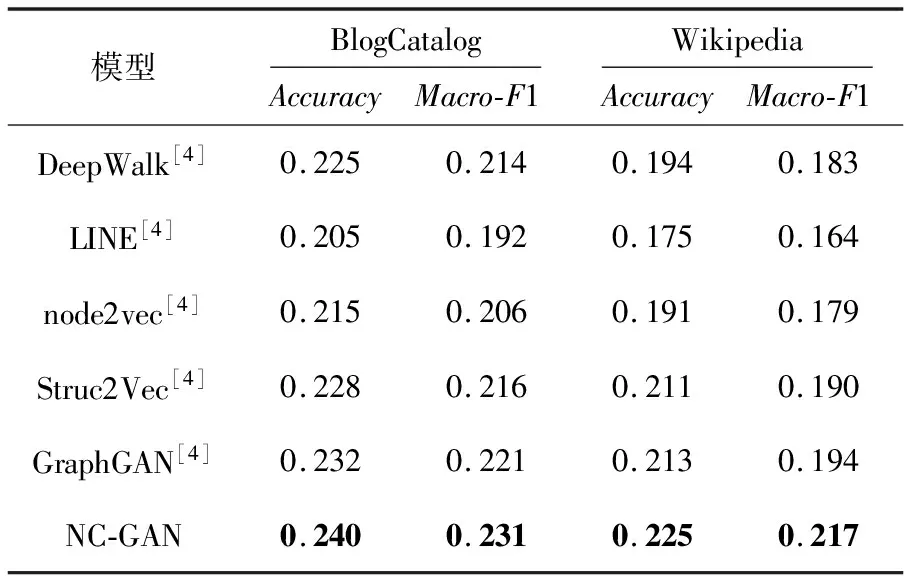
Table 3 Comparison of node classification experiments among learning models
根据图1所示对比结果,本文的NC-GAN模型所生成的特征矩阵,在经过逻辑回归计算分类后,所得的准确率比图卷积网络模型得到的分类准确率和GraphGAN模型经过逻辑回归得到的准确率都要高。由此可以看出,本文设计的模型在GraphGAN模型的基础上,对于节点分类来说更进了一步。
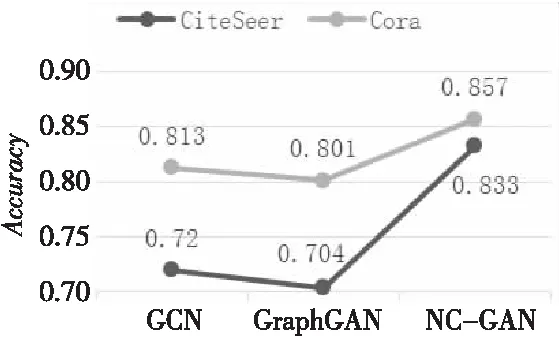
Figure 1 Node classification experiments comparison with graph convolutional networks
5 结束语
为了解决传统节点分类方法存在的问题,本文引入生成对抗网络。生成对抗网络通过生成模型和判别模型之间的二元博弈来生成所需的数据。GraphGAN模型将生成对抗网络引入图网络中,用于生成拟合真实连通性分布的数据,但由于过于重视节点之间的连接信息,没有考虑节点之间的关系,节点分类效果在对比模型中没有达到最好。本文在该模型的基础上考虑了节点之间的相似度,用相似度来代替节点之间的连接信息,使得生成的节点表示更有利于节点分类。实验结果也表明,本文的模型在节点分类的效果上优于其他对比模型。
