基于MapReduce 的个性化课程推荐系统设计与实现
2021-03-01徐伟,许鹏
徐 伟,许 鹏
云计算、大数据、人工智能技术的发展改变了传统的课程教学模式,促进了线下线上课程教学模式的融合,尤其是在今年的新冠肺炎疫情期间,各学校为了深入贯彻教育部“停课不停学”的指示精神,要求教师在职教云、腾讯课堂、学习通等在线教育平台上进行线上授课,开展线上课程建设.线上课程以其具有的不受时间场地限制、授课形式灵活多样的特点,在新冠肺炎疫情期间得到广泛应用.据不完全统计,新冠肺炎疫情期间线上课程数量急剧增加,占课程总量的85%,在一定程度上满足了学生学习知识和技能的需求,但同时也给学生选课带来了困扰.为了能够让学生在众多的线上课程中选择到适合自身学习特点的课程,笔者提出设计开发一款高效精准的个性化推荐系统[1],该推荐系统可以根据用户的历史行为数据发现用户的喜好,形成用户画像数据,从而为用户做出精准的个性化推荐,提供更加优质的服务.
本文在对当前主流在线教育平台的课程推荐功能进行深入研究的基础上,对学生购买课程的历史数据进行分析,将评分数据作为学生对课程喜好度的主要依据,将评论数据作为次要依据,基于协同过滤推荐算法,使用MapReduce 计算模型计算出课程间的相似度,最终向学生推荐符合其喜好的课程列表,实现了个性化课程推荐[2]功能.
1 系统架构
整个系统由日志采集子系统、数据清洗子系统、数据计算子系统、在线教育平台业务子系统组成.通过收集业务系统学生用户的行为数据,针对不同学生进行个性化课程推荐,以满足不同学生用户的需求.系统架构如图1 所示.
(1)日志采集子系统.负责采集用户的操作日志,并通过大数据组件Flume 将每天的数据实时采集到HDFS 中.Nginx 服务器除了作为网站的代理服务器外,还作为网站日志接收服务器,网站所产生的日志信息发送到Nginx服务器,Nginx 将接收到的日志存储在日志文件access.log 中.Flume 组件运行在集群中并实时监控access.log 文件的增量日志,一旦监测到有新的增量日志就会将新日志导入到HDFS文件系统的指定目录[3].
(2)数据清洗子系统.负责对日志进行数据清洗,剔除无效数据,从HDFS 指定目录读入非结构化日志数据,然后根据特定规则切分日志条目,将不符合特定规则的脏日志数据舍弃,并将清洗后的数据存入数据仓库以便于其他应用程序使用[4].
(3)数据计算子系统.基于协同过滤推荐算法,采用MapReduce 离线计算框架,通过Linux 定时任务[5]周期性计算课程相似度,并把结果回写到MySQL 的推荐表中.
(4)在线教育平台业务子系统.本业务系统是基于Python 语言的轻量级Web 框架Flask快速开发的在线教育平台[6],主要包含用户模块、课程模块、订单模块、评论模块等核心业务模块,具备线上教育平台的核心业务功能,包括前台课程展示页面与后台管理员页面,同时在课程详情页面还包括课程的推荐列表.在管理员页面可以对课程进行相应的操作,以及查看不同维度统计信息.在Web 开发中,页面跳转是通过不同的Flask 控制器View 视图函数进行控制,根据用户的请求路径调用对应的视图函数进行处理[7].
2 MapReduce 计算模型执行过程
本文采用MapReduce 离线计算模型,使用Linux 下执行定时任务工具crontab 周期性对学生行为日志数据进行离线计算,并将计算结果通过Sqoop 同步更新到数据库中.MapReduce 采用的是分而治之的数据处理方式,Map操作即为“分”操作,将一个大数据块分解为多个切片,交由集群中的各个节点去计算;而Reduce 即为“合”操作,合并各个节点上的计算结果并输出[8].
MapReduce 编程模型是一种并行数据计算模型,该模型根据数据输入量的大小将数据划分为N个相对独立的数据切片,启动N个Map 任务,每个Map 任务获得一个切片数据,该切片数据经计算处理后生成键值对,以(Key/Value)的形式输出,在Map 和Reduce 中间需要一个Shuffle 过程,该过程将Map 的输出结果Key/Value 键值对按Key 进行分组,形成P个Key/ValueList,然后 交 给P个Reduce 任务去处理,即一个Shuffle 之后的Key 对应一个Reduce 任务,如果用户指定了Reduce 任务的个数,则需要通过对Key 进行Hash 计算,求出Hash 值,然后根据Hash 值将不同的Key 发送到不同的Reduce 任务,Reduce 任务接收到来自Shuffle 的Key/ValueList 输入,通过迭代ValueList 计算并输出最终结果,这是单个MapReduceJob 的完整执行过程[9],如图2 所示.
在实际项目开发中,可以根据自身的业务功能进行灵活选择,比如,如果只是一个简单的数据清洗作业(Job),可以只有Map 过程,而没有Reduce 过程;也可以将多个Job 串联在一起,形成一个复杂的计算逻辑,将JobA的输出作为JobB 的输入,JobB 的输出作为JobC 的输入直至整个任务完成[10].
3 基于协同过滤算法的课程推荐实现过程
本课程推荐系统主要实现两个功能,分步骤实现,首先计算出课程与课程间的相似度,然后根据用户的订单及评分数据,找出课程相似度比较高的课程列表进行推荐.以下为具体实现过程.
首先,获取用户对某一课程的评价信息,主要是评分数据,这一信息可以在订单表中获取.通过Sqoop 数据导入导出工具,按指定要求增量或者全部导出所有数据到HDFS 指定目录,这里只导出用户ID、课程ID 和评分数据.数据集如表1 所示.
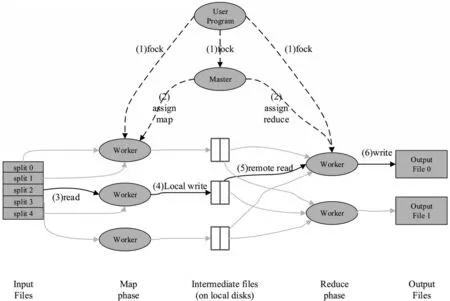
图2 单个MapReduceJob 完整执行过程
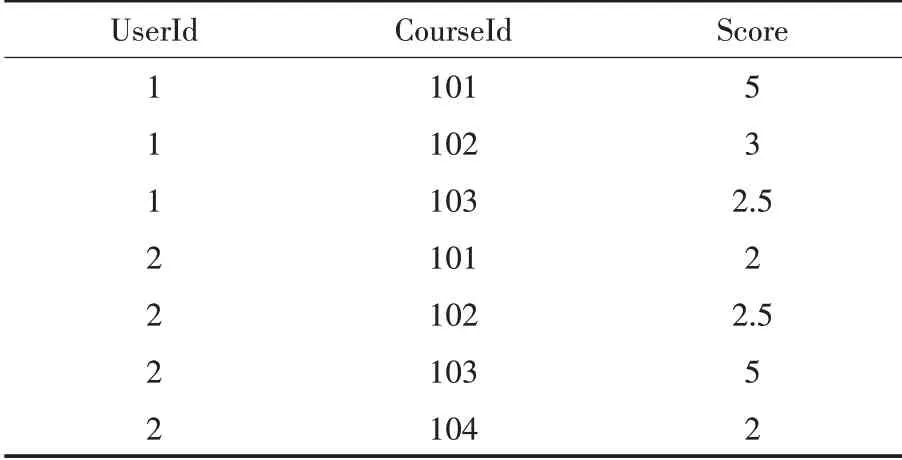
表1 课程评分表
然后,运行指定的MapReduce 程序,读入上述数据集,建立用户对课程的评分矩阵并把计算结果存入相应目录中.用户对课程评分矩阵如图3 所示.
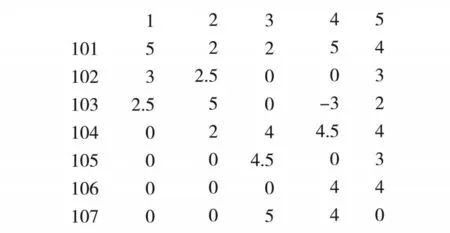
图3 用户对课程评分矩阵
评分矩阵的行为课程ID,列为用户ID,评分矩阵中的数值代表该ID 用户对该ID 课程的评分数据,如果数据为0,则表示该ID 的用户尚未对该课程进行评价.从该矩阵列方向看,每一列在MapReduce 程序中可以用一行字符串101:5,102:0,103:-3,104:4.5,105:0,106:4,107:4 表示.按照上述方式处理矩阵,图3 用户评分矩阵的5 列就可以由5 行类似的字符串来构成.那么第一个MapReduce 程序的功能就是将关系型评分矩阵按照列维度进行数据转换操作.
其次,读入评分矩阵,计算出课程的同现矩阵[11],如图4 所示.

图4 课程同现矩阵
课程同现矩阵的行为课程ID,列也为课程ID,矩阵的值表示两个课程同时被用户评分的次数,例如104 和105 这个课程组合被3、5 两个ID 的用户评价过,那么在矩阵中104 和105 所对应的数值就是2.如果两个课程同时被多个用户购买并评价过,那么这两个课程在很大程度上是相似课程,同时被购买并评价的次数越多,即课程同现矩阵中数值越大,根据协同过滤算法的定义,这两个课程的相似度就越高.从列方向上看,这个同现矩阵的每一列在MapReduce 程序中可以通过简单的字 符 串102:101 3,102:102 3,102:103 2,102:104 2,102:105 1,102:106 1,102:107 0表示,x*y的同现矩阵就由x个以上的字符串(y行)组成.可以看出,课程和课程的同现矩阵需要另外一个MapReduce 任务来完成,它是将第一个MapReduce 任务的输出作为输入进行计算的.
最后,计算课程相似度并产生最终推荐结果,推荐结果等于用户对课程的评分矩阵*课程同现矩阵.课程的同现次数*用户对各个课程的评分,反应出用户对课程的评分.
例如,计算用户2 对105 课程的喜好度,那么必须找到和105 课程相似的课程,课程之间的相似度体现在同现度上,同现度越高,相似度越高.比如101 课程和105 课程的同现度为4,说明101 课程和105 课程相似,用户2 对105 课程的评分为2,表示用户2 对105 课程的喜好度,101 课程和105 课程的同现度*用户2对101 课程的评分可得到用户2 对105 课程的喜好度权重值,将用户2 对各课程评分权重相加,最终计算出用户2 对105 课程的喜好度.第三个MapReduce 任务的功能就是实现评分矩阵和同现矩阵的相乘,并输出结果.推荐结果如图5 所示.

图5 推荐结果
个性化课程推荐系统开发完成后,部署在学校数据中心的服务器上,学生可以通过互联网或校园网访问使用该系统.为了解学生使用该系统的实际效果,设计了在线问卷调查系统,经统计共874 名学生参与问卷调查.调查数据显示:71%的学生认为该系统可以满足自己的个性化需求,感到“非常满意”;23%的学生认为对自己选课有所帮助,感到“满意”;6%的学生认为该系统的个性化课程推荐对自己帮助不大,感觉“一般”;没有同学感到“不满意”.系统满意度调查如图6 所示.
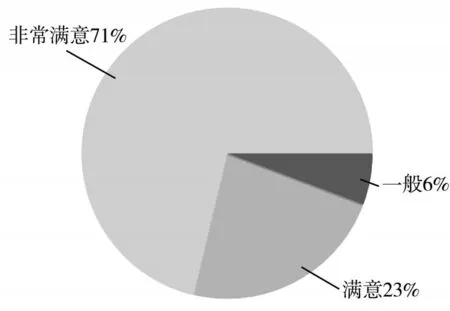
图6 推荐系统满意度调查
4 结语
随着在线教育体系的不断发展和完善,线上教学模式必将成为今后学生学习知识和技能的一个重要途径,而在线教育平台如何满足学生用户个性化需求将是一个值得研究的课题.本文采用协同过滤推荐算法,根据学生对课程的评分数据和对课程的历史评价数据,了解学生感兴趣的课程特征,使用MapReduce 离线计算框架计算出课程之间的相似度,从而实现了个性化的课程推荐功能,在很大程度上满足了学生的需求.后期将在业务系统中采集学生的个人爱好、喜欢的讲师授课风格等更多个性化特征数据并应用于算法模型中,进一步提高推荐系统的精准性.
