基于语义行为的车辆轨迹停留点提取算法
2021-03-01秦晓安殷西祥
陶 健,王 睿,秦晓安,殷西祥
随着车载智能终端设备、定位技术和存储技术的快速发展,车辆轨迹数据的收集存储得以实现.如何有效分析利用这些轨迹数据,成为数据挖掘者研究的热点问题[1-3].其中,停留点作为车辆轨迹中隐含的重要信息,表示用户经常出没的、带有重要语义信息的地区,如餐馆、景点等;提取停留点能为车主日常出行、位置信息搜索、观光浏览等提供辅助决策,同时也是构建位置服务个性化推荐系统的基础.
轨迹数据挖掘的早期研究主要针对时间、几何特性,并未考虑空间特性;其中有关停留点提取的算法大致分为三类:基于时间的聚类算法、基于密度的聚类算法,以及分割聚类算法.
关于时间聚类算法,KANG[4]根据轨迹点的时间连续特性,通过时间阈值和距离阈值设计了基于时间的聚类算法;LV 等人[5]考虑到由于高楼遮挡造成GPS 信号损失使得轨迹不连续问题,在时间聚类算法上增加容忍距离阈值对形成的相邻聚类区域进行判断是否需要合并;MONTOLIU 等人[6]考虑连续位置点缺失造成停留点误判问题,在时间聚类算法上增加时间差阈值对相邻位置点进行聚类判别;侯颖超等人[7]考虑车辆行驶在户外,且不存在长时间信号缺失现象的问题,在时间聚类算法上增加速度阈值对候选停留点进行过滤.虽然时间聚类算法能够发现长时间停留的停留点,但是对时间阈值要求较高,而车辆轨迹中出租车轨迹更多的是短暂停留,这极易造成停留点的丢失.
基于密度的聚类算法,是从轨迹的几何特性出发,对位置点稠密区进行聚类来发现任 意 形 状 停 留 点,如SmoT[8]、CB-SMoT[9]、DJ-Cluster[10]等,但难以解决行驶在路网上的车辆轨迹的停留点提取,容易将十字路口、立交桥等误判为停留点.
关于分割聚类算法,ASHBROOK 等人[11]利用K-Means 的算法思想设计了基于切割聚类的停留点提取方法;HUANG 等人[12]通过切割聚类的思想,提出一种停留稳定性的概念,进而对轨迹进行切割划分,将停留稳定性高于切割标准的子轨迹聚类作为停留点.分割聚类算法虽然能够发现停留时间较短的停留点,但并没有针对车辆轨迹行驶在路网的特征,会将十字路口等地误判为停留点.
不同的应用场景决定了空间轨迹特点不同,车辆轨迹一般通过车载智能终端设备采集所得,设备在行车期间一直保持供电,且长期行驶在户外,一般不会产生信号缺失问题,且轨迹位置点时间间隔较为恒定.但车辆轨迹被路网严格约束,行车中会遭遇大量红绿灯路口、立交桥等,如图1 所示.先前的停留点提取方法[3-12]会造成停留点误判问题,将十字路口或立交桥的伪停留点(Pseudo stay point,PSP)误判为对某地感兴趣停留点.
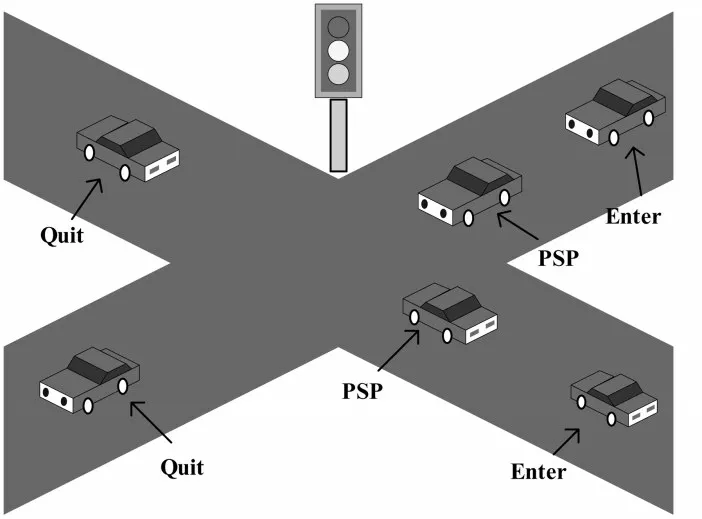
图1 十字路口的伪停留
针对上述问题,本文提出一种基于语义行为的车辆轨迹停留点提取(Semantic behavior-based vehicle trajectory stay point extraction,SPE)算法,该算法从语义行为分析的角度,利用轨迹进行空间路网建模,将车辆行驶中产生的伪停留点有效剔除,提高了停留点的提取精度,为车辆用户语义行为的分析打下基础.
1 车辆轨迹停留点提取
1.1 相关定义及描述
本文令VT={Tr1,Tr2,…,Trn} 为车辆轨迹数据集合,按照一天的时间间隔划分,一条轨迹Tri为一辆车行驶一天的位置点集合,其详细描述如定义1 所示.
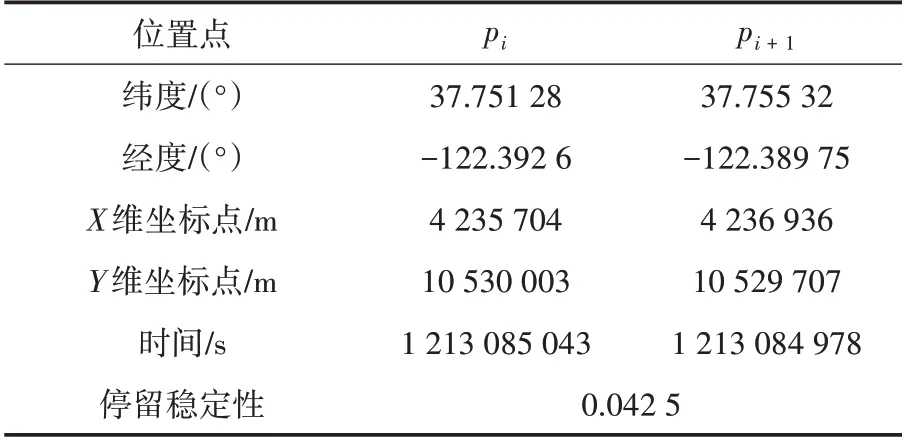
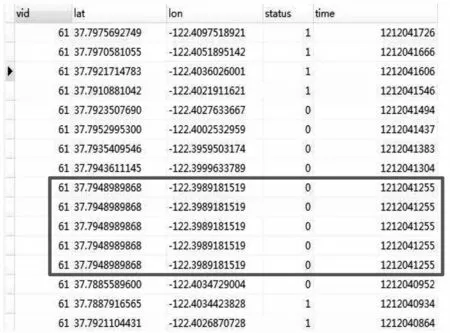
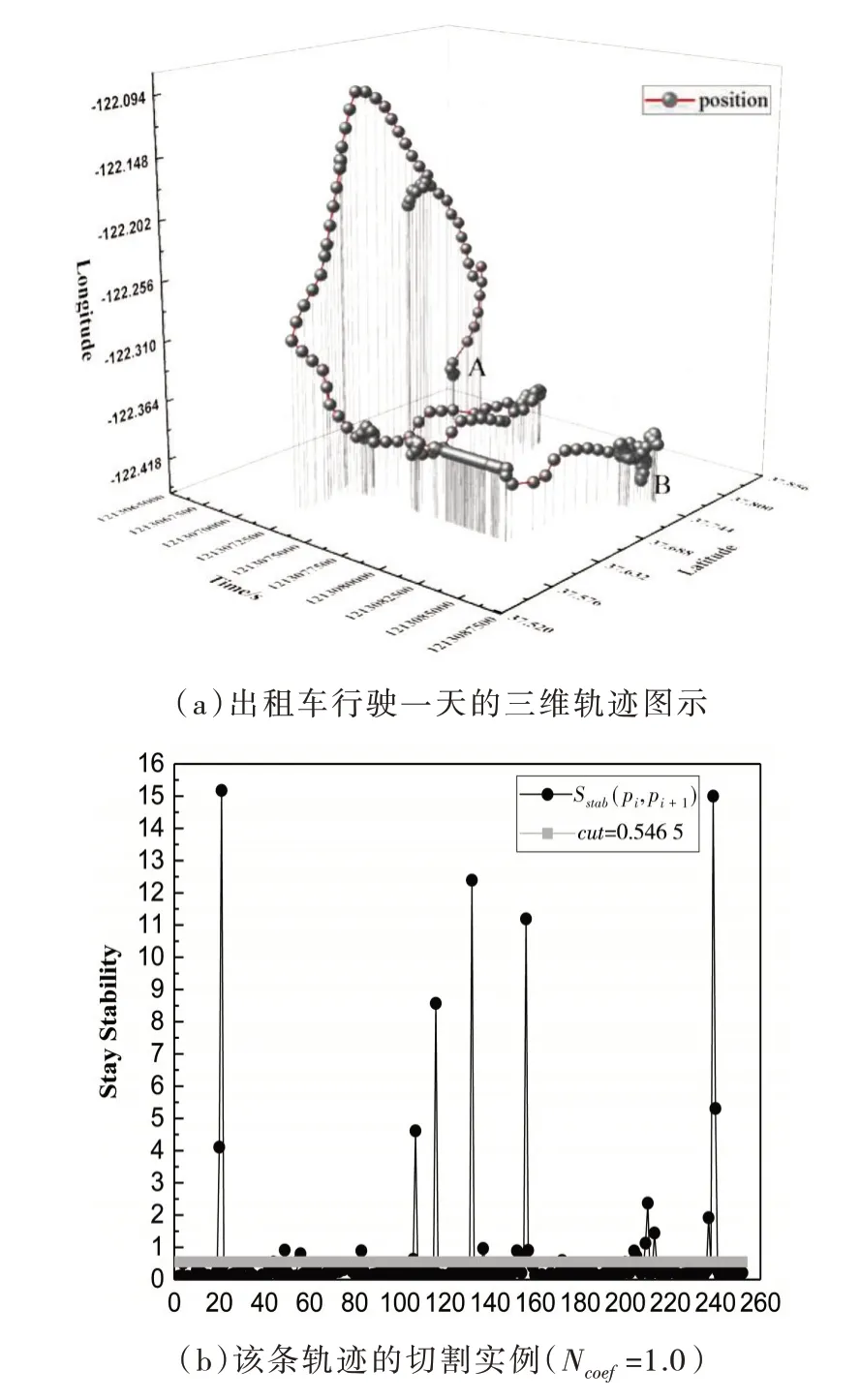
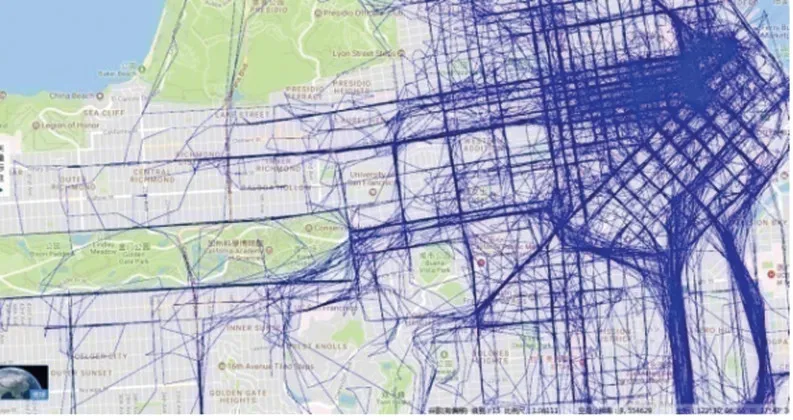
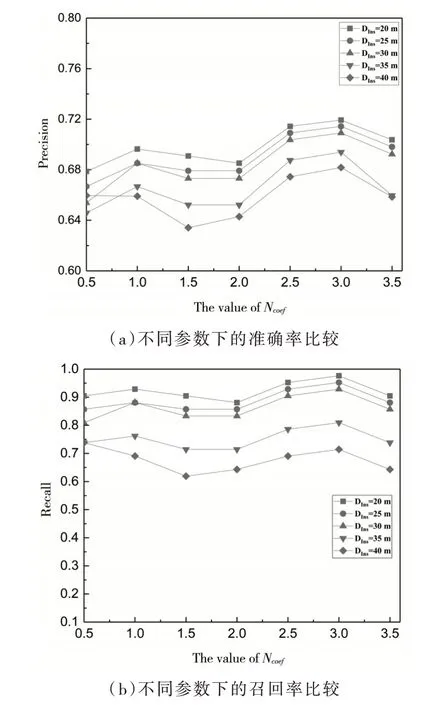
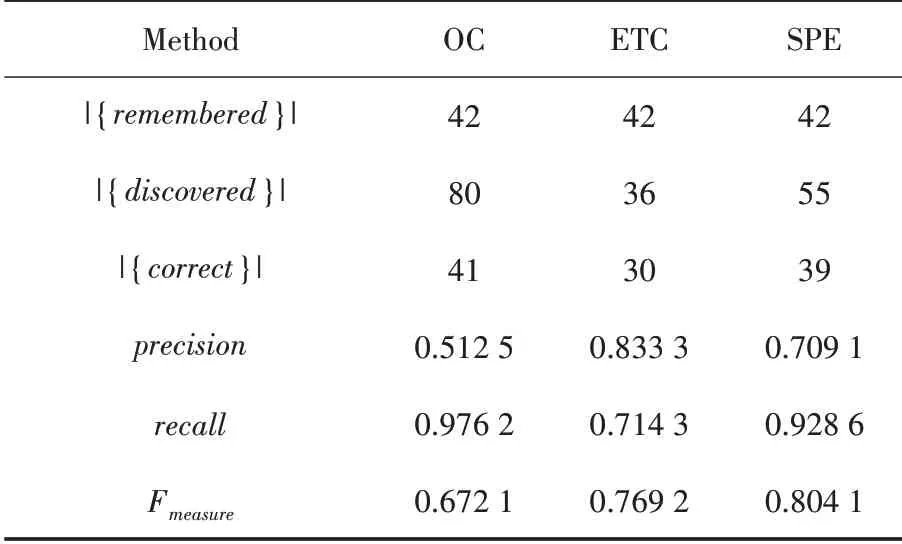
定义1(车辆轨迹)车辆轨迹是包含时间的有限位置点序列,用符号表示为Tri=1≤i≤n,其 中,idi表示车辆唯一标识;表示二维地理空间中位置点的纬度与经度,其数据是在WGS-84坐标系下采集所得;ti为位置点的时间戳信息,且∀1 定义2(曼哈顿距离)已知两个连续经纬度位置点pi(lati,loni)和pi+1(lati+1,loni+1),通过坐标转换工具将其转换为二维平面空间坐标,即pi(xi,yi)和pi+1(xi+1,yi+1),则连续位置点的曼哈顿距离为: 其中:xi和yi分别是对应纬度lati和经度loni转换的二维平面空间坐标点. 定义3 (停留稳定性)相邻位置点pi和pi+1之间的停留稳定性表示为: 其 中:Δti=ti+1-ti是 相 邻 位 置点pi和pi+1之间的时间间隔,Δdi=len(pi,pi-1)为相邻位置点的曼哈顿距离且不为零. 为了便于理解,本文根据路网基本都是东西、南北走向,且采用出租车数据集,相比传统欧式距离的计算方法[12],采用曼哈顿距离方法计算相邻位置点距离更为合理且效率更高,具体如表1 给出的旧金山出租车轨迹的相邻位置点停留稳定性计算实例. 表1 相邻位置点停留稳定计算实例 其中经纬度坐标位置点通过坐标转换工具转换为二维平面空间坐标点,位置点时间为Unix 时间戳格式,根据公式(1)和公式(2)进行计算,得其停留稳定性为:Sstab(pi,pi+1)= 0.042 5. 定义4(平均停留稳定性)结合停留稳定性的公式,一条轨迹Tri的平均停留稳定性如公式(3)所示: 其中:A、B是轨迹Tri的第一个位置点和最后一个位置点,n是A、B间相邻位置点的间隔数量. 定义5 (候选停留点)轨迹Tri的部分连续位置点{pa,pa+1,…,pb}构成的子轨迹Trab聚类成为候选停留点,当且仅当该子轨迹的所有相邻位置点的停留稳定性都高于切割线cut,该子轨迹Trab构成的候选停留点表示形式为: 定义6(停留点)某一时间区域或空间区域内车辆用户产生某种感兴趣语义行为,如对公园、餐馆等感兴趣而停留的点. 一般在进行轨迹停留点提取之前,由于人为或机器问题,会造成车辆轨迹数据中大量位置冗余,需要对原始轨迹进行数据清洗[13]实现数据可用性的目的. 图2 数据清洗实例 图2 所示的旧金山出租车轨迹数据样本,框里的为冗余数据.本文将TXT 格式的样本数据导入到MySQL 数据库中,应用MySQL 的“去重语句”,将其中的冗余数据进行清洗,仅保留其中一条,为后续停留点的提取提高精度. 在SPE 算法中,为了提高停留点实用性,从语义行为的角度对停留点进行精炼,其过程主要分为两个阶段:采用基于停留稳定性切割聚类(Cutting clustering based on stay stability,CSS)算法将停留稳定性高的子轨迹聚类作为候选停留点.采用基于十字路口过滤(Filtering based on intersection,FBOI)算法将位于十字路口的那些伪停留点进行过滤得到符合车辆用户对某地感兴趣的停留点. 基于停留稳定性切割聚类算法.现实生活中,车辆用户每当遇到一个感兴趣的地方,不会瞬间停止,而是缓慢地到达目的地;此外,对有些地方可能只是短暂的停留,如出租车用户.应用CSS 算法可以不依赖停留时间的长短,而发现在某地短暂停留的情况,具体如算法1 所示. 为了更好解释该算法,给出CSS 算法的一个应用实例,如图3 所示. 图3 基于CSS 算法的应用实例 图3 (a)所示的是出租车在旧金山城区行驶一天的三维立体轨迹图例,其中A 点是行驶中的第一个位置点,B 点是出租车最后停止的位置点,从图3(a)中可以发现运动轨迹和目的地具有极大的随机性. 图3(b)所示的是这条轨迹进行CSS 算法后的一个切割实例图,该条轨迹在进行公式(3)计算后得到平均停留稳定性为AveSstab(A,B) =0.546 5;当切割系数Ncoef= 1.0,即切割线cut= 0.546 5 时,位于切割线以上的稳定性子轨迹为16 条,调用算法的第4 步,得到候选停留点为16 个. 基于十字路口过滤.车辆在行驶过程中会遭遇大量十字路口而被迫停留,这些伪停留点并不是车辆用户感兴趣的语义行为,故提出基于十字路口过滤算法来对候选停留点进行精炼,如算法2 所示. 同时,Semantic MediaWiki还支持将语义查询代码内嵌入内容文档中,这样就可以根据需要,直接引用并显示检索的内容,并与原文档内容进行有机的整合,既简化了编辑步骤,又增加了知识文档的共享程度。例如创建一个内容文档页面如下: 如图4 所示,由于驾驶员的行车偏好,车辆轨迹在路网之上分布极不均匀,算法2 中首先通过车辆轨迹对空间路网进行建模[14]获得十字路口,不仅可以快速对整个路网进行十字路口提取,而且更有利于车辆轨迹在空间上的近似化分析,更适用于任何城区的十字路口提取研究. 图4 车辆行驶轨迹可视化图示 为了验证本文提出的SPE 算法的有效性,文献[6]给出停留点提取的指标,包括准确率、召回率和调和平均值. 本文中准确率指的是正确停留点数量与发现停留点数量的比值,如公式(4)所示. 其中:|{correct}|为正确停留点数量,据微软研究者所述[15],当发现的停留点和车辆用户记忆中的停留位置距离不超过50 m,则该停留点为正确停留点;|{discovered}|为经过SPE 算法发现的停留点数量. 召回率指的是正确停留点数量与出租车司机记忆点数量的比值,如公式(5)所示. 其中:|{remembered}|为车辆用户记忆中停留位置点,本文中的记忆点为出租车上下客位置点,即车辆轨迹属性中状态位由0 变1 和由1 变0 的相应位置点. 调和平均值是准确率和召回率的平衡指标,被作为停留点提取的实用性指标,具体如公式(6)所示. 实验环境是在Windows7 32 位操作系统上使用Java 语言开发,并运行在一台配置为2.83G Intel 双核CPU,内存为3G 的PC 机上,通过My Eclipse 软件进行Java 语言的编写与调试,并将结果通过Origin 软件进行量化.本实验采用的车辆轨迹数据是PIORKOWSKI 等人[16]提供的包括500 辆出租车于2008 年5 月17 日至6 月10 日在旧金山城区行驶近一个月的真实出租车轨迹数据集,该数据集已经应用于学术研究的多个领域,具有真实可靠性,具体如表2 所示. 表2 旧金山出租车轨迹数据集 本文提出的SPE 算法中,每一个子算法的参数值都会影响停留点提取的效果,接下来详细阐述算法中用到的参数值的选取. (1)ρ和N的选取.根据城市道路交通的车道规定[14],将圆形区域设定值ρ的取值为直径50 m.通过旧金山出租车1 011 条轨迹数据的Δα处理,得到转向点67 480 个,结合旧金山城区的特点,并经过数次测试,选取最小转向点数为N= 30,得到十字路口数量为|INS|= 352.图5 是投影到Google Earth 上的局部十字路口可视化图,其中圆形图标代表十字路口. 图5 局部十字路口可视化示例 (2)Ncoef和DIns的选取.首先从旧金山轨迹数据集中随机选取一条轨迹,其包含位置点1 152 个,根据轨迹属性 中status的0,1 变化,对上下客位置点进行提取[17],得到车辆用户记忆中的停留点42 个. 图6 给出参数Ncoef和DIns的不同取值和与其相对应的准确率和召回率的变化,由于轨迹数据是明显的偏态分布,从图6 中可以分析出:随着两个参数值的改变,准确率和召回率呈现出一种波动的变化. 当距离阈值DIns一定的条件下,由于轨迹的平均停留稳定性极易遭受数据极端值的影响,即在切割系数Ncoef不断增大的初期,准确率和召回率都有明显地提高,但随着Ncoef继续增大,部分停留点可能会被割裂丢弃,从图中可以看出当切割系数Ncoef> 3.0 时,准确率和召回率都在不断降低,即选取切割系数为Ncoef= 3.0.当切割系数Ncoef一定的条件下,随着DIns的不断增大,十字路口附近的停留点会被过滤,导致准确率和召回率的降低,当DIns>30 m 时,出现明显降低;在DIns取值上,若选取太小,不能很好地将十字路口的伪停留点过滤,若DIns取值太大,又会丢失一些有意义的停留点,结合生活中行车至十字路口不允许停车的规定,本文选取距离阈值DIns= 30 m. 图6 Ncoef 和DIns 的参数值选取 分别将已存在的基于时间聚类(简称为ETC)算法[4]和基于分割聚类(简称为OC)算法[12]与本文提出的SPE 算法进行比较,实验中利用旧金山出租车轨迹数据分别对OC 算法和ETC 算法进行了多次测试,选择最佳的参数值,其中OC 算法的分割系数为Ncut=3.0;ETC 算法的最短停留时间参数为Tmin= 210 s,最大空间范围为Dmax= 130 m. 表3 给出了三种算法对随机一条车辆轨迹提取停留点的结果. 表3 不同算法下的停留点提取表现 从表3 可以发现:ETC 算法的准确率要高于另外两种算法,主要因为该算法的最短停留时间Tmin的限定,能够将十字路口的那些短时间伪停留过滤,但会将短时间停留的停留点忽略,造成召回率较低;同时OC 算法的召回率要优于另外两种算法,因为分割算法不会被停留时间所局限,能够发现短时间停留的位置点,但该算法未将十字路口的伪停留进行过滤,造成准确率较低. 本文的SPE 算法在发现停留点上不会受停留时间长短的影响,又能过滤行车过程中被迫停留的伪停留点,故调和平均值相比另外两种算法要高出很多,在车辆轨迹的停留点提取上有更好的实用性. 本文首先深刻剖析行驶在路网之上的车辆轨迹特点,利用车辆轨迹进行路网空间建模,从车辆用户对某地感兴趣的语义行为角度,提出基于语义行为的车辆轨迹停留点提取算法.该算法创新地提出不依赖真实路网约束的噪点剔除方法,有效地排除十字路口与立交桥等的干扰.此外,通过车辆轨迹分析车辆用户移动行为将是后期的研究方向.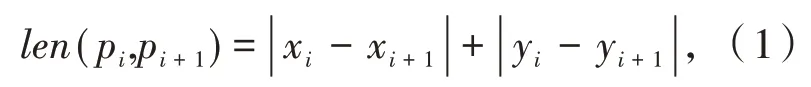
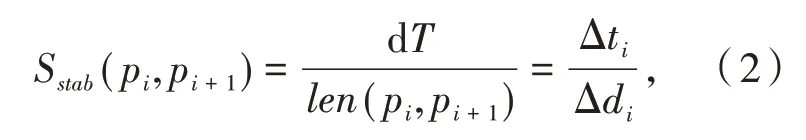
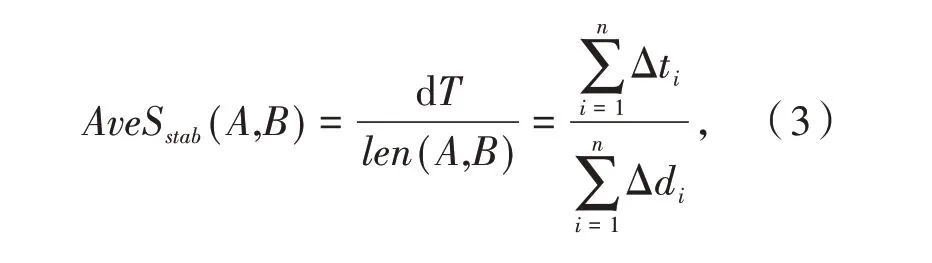
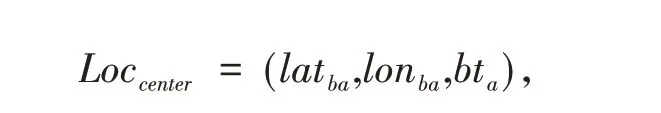
1.2 数据清洗
1.3 停留点提取算法


1.4 停留点实用性
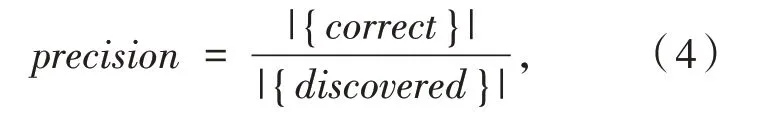
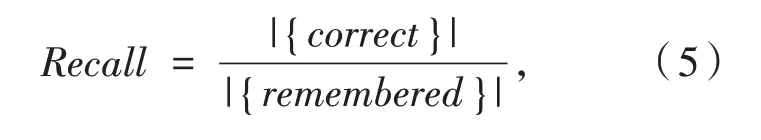

2 实验及分析
2.1 实验设置

2.2 参数值的选取

2.3 实验结果及分析
3 结语
