LDA最大概率填充与BiLSTM模型的文本分类研究
2021-03-01袁丽莉张正平
袁丽莉,侯 磊,张正平
(贵州大学 大数据与信息工程学院,贵阳 550025)
0 引 言
随着大数据和“互联网+”的高速智能化发展,互联网已发展成为当今世界上最大的信息资源库,而大多数信息是以文本方式呈现出来的[1]。从这些海量且杂乱无章的数据文本中筛选出所需的有用信息是当前数据挖掘领域的研究热点。文本分类是自然语言处理(NLP)领域中的基础任务,能将复杂的文本信息有效的组织和管理,并已广泛用于信息检索、自动聊天系统、垃圾邮件过滤等领域。
目前,常用的文本分类方法可分为两类,一类是基于传统的机器学习,例如支持向量机(SVM)、决策树等;另一类是基于深度神经网络的文本分类方法,该种方法通常采用卷积神经网络(CNN)和循环神经网络(RNN),其一般流程为文本预处理、结构化表示、特征选择和分类器构建,通过学习训练得到分类模型,最后利用分类模型对测试样本进行预测,从而达到对文本分类的目的[2]。通过对当前文本分类的研究不难发现,文本表示是文本分类中的难点之一,尤其是在文本的语义表达方面最为困难。文本在机器学习中表示大多采用向量空间模型,该模型容易造成向量维数过大,数据稀疏的问题,从而影响最终分类的结果。因此,如何将文本表示为机器可以理解的形式,又保留文本原有的潜在语义至关重要[3-4]。文献[5]提出一种基于LDA 主题模型和Word2Vec 词向量模型,完成对文本词向量的构建,结合神经网络对构建的词向量获取联合特征的方法,实现文本分类;文献[6]采用三层CNN模型,提取文本的局部特征,整合出全文的语义,利用长短时记忆网络(LSTM)存储历史信息的特征,以获取文本的上下文关联语义;文献[7]采用词向量完成原始文本的数字化,利用双向长短时记忆网络(BiLSTM)进行语义的提取,同时采用改进的注意力层(Attention)融合正向和反向特征,获得具有深层语义特征的短文本向量表示;文献[8]提出一种BiLSTM 和CNN 混合神经网络文本分类方法,两种神经网络的结合充分发挥了CNN 的特征提取能力和BiLSTM 的上下文依赖能力,同时采用注意力机制提取信息的注意力分值,增强模型的特征表达能力。
基于上述的研究,经过word2vec 形成的词向量矩阵,由于文档集里的各个文本长度不一,造成词向量矩阵的行数不一,在实验过程不能批量处理数据。本文提出一种基于LDA 的最大概率填充模型,该模型对词向量矩阵进行填充,使构建的词向量矩阵行数等于最大文本长度,丰富了语义信息,采用BiLSTM_Attention模型对通过填充后具有上下文丰富语义信息的文本词向量矩阵进行训练,达到分类器可以根据给定的标签信息对输入信息进行分类的目的。
1 LDA_BiLSTM_Attention 文本分类模型
1.1 词向量矩阵生成模块
分词过后的文本需要转化为计算机能识别的形式,目前主要采用Word2Vec模型。Word2Vec 包含了CBOW 和Skip-gram 两种模型,CBOW模型利用词的前后各C个词来预测当前词,如图1(a)所示;Skip-gram模型则是利用当前词预测其前后各C个词,如图1(b)所示。在CBOW模型中,输入层是词W(t)的前后各C个词向量,投影层将这些词向量累加求和,输出层是一棵以训练数据中所有词作为叶子节点,以各词在数据中出现的次数作为权重的树[9]。最后应用随机梯度上升法预测投影层的结果作为输出,Skip-gram模型与之类似。当获得所有词的词向量后,可发现这样的规律:“king”+“woman”=“queen”,可见词向量有效表达了词语的语义信息[10]。
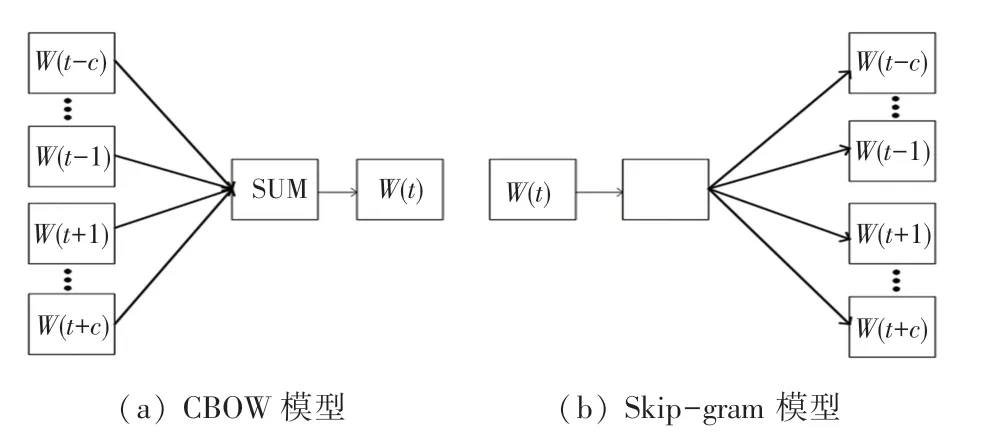
图1 LDA模型Fig.1 LDA model
1.2 LDA 主题填充模型
判断两个文本是否相似,传统的方法是找出两个文本中共有的词个数,这种方法的缺点在于忽略了文本的语义信息,使得两个原本相似的文档因为没有共有的词而造成判断错误。所以在进行文本分类时,语义也是需要考虑的一个重要的因素[11-12]。本文采用的LDA模型就能够很好地解决文本的语义问题,通过文本混合主题上的概率分布选择一种主题,从被抽取到的主题上所对应的单词概率分布中抽取一个词,然后重复上述过程,直至遍历文档中的每一个单词。图2 为LDA 生成模型,K为主题个数,M为文档总数,Nm是第m个文档的词数,β是每个主题下词的多项分布的Dirichlet 先验参数,α是每个文档下主题的多项分布的Dirichlet 先验参数,zm,n是第m个文档中第n个词的主题,wm,n是第m个文档中的第n个词,隐含变量θm和φk分别表示第m个文档下的主题分布和第k个主题下词的分布,前者是k维向量,后者是v维向量。主题模型学习参数主要是基于Gibbs 采样和基于推断EM 算法求解,Gibbs 采样算法是一种特殊的马氏链的方法,是经过对词的主题采样生成马氏链。马氏链的生成过程是根据所有词的其它时刻的主题分布估计当前词分配于各个主题的分布概率,当算法重新选择了一个与原先不同的主题词时,反过来会影响文本-主题矩阵和主题-词矩阵,这样不断地进行循环迭代,就会收敛到LDA 的误差范围内。当完成主题采样后,就可以学习模型的最终训练结果,生成两个矩阵分别为文本-主题分布矩阵θ及主题-词分布矩阵Φ,公式(1)和公式(2)如下:


图2 LDA 生成模型Fig.2 LDA generative model
1.3 最大概率的文本主题填充方式
运用词向量模型对输入文本进行词向量矩阵嵌入生成之后,因为文档里的文本长度长短不一样,导致文档集里的各个文本生成的词向量矩阵的大小各不相等,在目前的处理方法中,通常采用填零法、循环法和随机法进行填充,导致构建的词向量矩阵存在稀疏性以及语义混乱等问题[5]。为了在实验中能够进行批处理数据和丰富文本特征信息,本文提出基于最大概率主题下的LDA 填充方式,以文档集里的最大文本长度为基准,寻找文本对应文本-主题矩阵最大的概率主题,找到此主题下的词概率分布,依照概率大小将词映射为词向量,并依次对词向量矩阵进行填充,直至构建的词向量矩阵行数等于最大文本长度。填充流程如图3 所示。
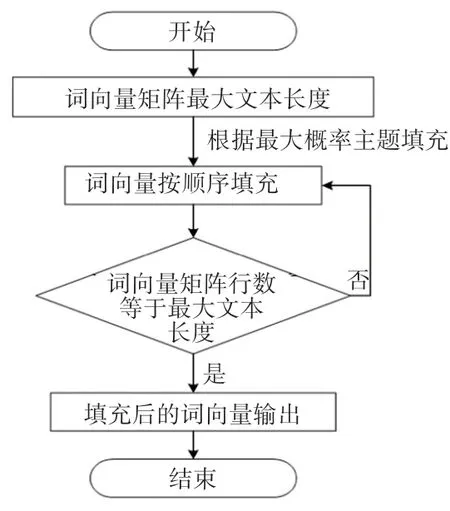
图3 LDA 填充流程图Fig.3 LDA filling flow chart
1.4 BiLSTM 和注意力机制
例如:“The driver of this car was charged by speeding and hitting pedestrian”,若不联系后文则很难推断在此处charge 是收费还是指控的意思,BiLSTM 双向捕捉能获得更细粒度的信息,提出了双向神经网络,结构如图4 所示。

图4 BiLSTM_Attention 结构图Fig.4 BiLSTM_Attention structure diagram
首先,使用BiLSTM 学习当前词的上文词向量C1(Wi)和下文词向量C2(Wi),再与当前的自身词向量C(Wi)进行计算,公式(3)~公式(5)如下:
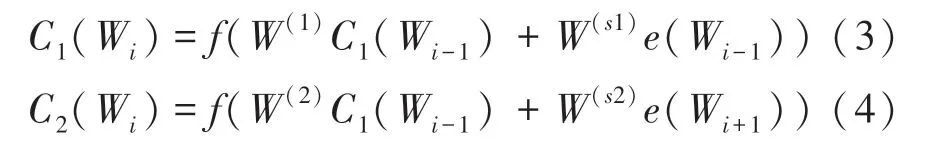

将Xi作为Wi的语义特征,通过激活函数tanh得到的潜在语义信息Yi,公式(6)和公式(7)如下:
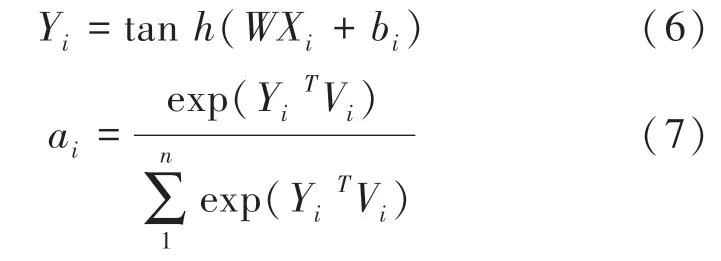
注意力机制是一种权重分配的机制,通过模仿生物、观察行为,将内部经验和外部感觉对齐,进一步增强观察行为的精度,在数学模型上表示为通过计算注意力的概率分布来获得某个输入对输出的影响,该方法后来被引入到自然语言处理领域。图4中的Vi作为不同时刻的输出权重,公式(8)对BiLSTM 网络的输出进行加权求和。

1.5 输出层
经典的全连接网络的输出层表示为公式(9):
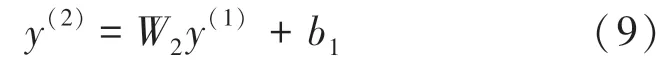
其中,W2为权重系数,b1为偏置项。
通过softmax函数分类,得到每个文本所在类别的概率分布,找出最大值的类别就是预测类别,计算公式(10)如下:

2 性能评测与实验分析
2.1 实验数据
本次实验采用的数据集为IMDB 电影评论分析数据集,共有3 个部分:分别为带标签的训练集(labeledTrainData),不带标签的训练集(unlabeledTrainData)和测试集(testData),实验参数见表1。
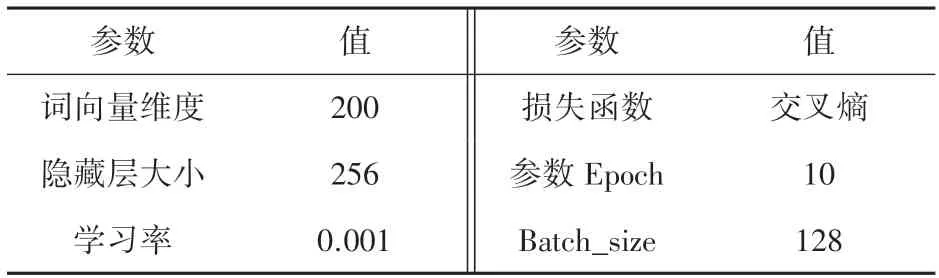
表1 BiLSTM 网络参数Tab.1 BiLSTM network parameters
2.2 实验评判标准
为客观评价本文提出的模型,将IMDB 电影评论数据集按8:2 的比例分为训练数据集和测试数据集。同时引入准确度(accuracy)、精确度(precision)、召回率(recall)、综合评价指标(F1)对实验结果定性分析,4 种指标计算公式如公式(11)~(14),各参数意义见表2。


表2 评价指标函数意义Tab.2 The meaning of evaluation index function
2.3 实验结果分析
本文实验涉及的开发工具与实验环境:
硬件环境:CPU:Inter(R)core(TM)i5-4210 M,内存:8 GB,硬盘:500 GB。
软件环境:Windows10(基于X64 的处理器),python3.6.8。
为验证本文模型的有效性,选取RNN、BiLSTM和BiLSTM_Attention 3 种常规模型与本文提出的LDA_BiLSTM_Attention模型进行对比实验,实验结果见表3。

表3 评价指标函数意义Tab.3 The meaning of evaluation index function
从表3 中的数据可以看出,本文模型文本分类准确度达到98.43%,比BiLSTM_Attention模型提高了0.83%,在召回率方面也表现很好,综合评价指标最佳。RNN 网络因不能双向捕捉特征值导致分类效果最差,加入了注意力机制的BiLSTM模型相对于单独的BiLSTM模型综合评价指标也有所提升。由此可知,在BiLSTM_Attention模型的基础上加入LDA 算法填充词向量矩阵,能丰富语义,进一步捕获文本分类的信息,提高文本分类的准确率。
上述4 种模型的损失值和准确率随迭代次数的变化曲线,如图5 和图6 所示。由图5 和图6 可以看出,采用LDA 对词向量矩阵进行填充后训练的模型损失值最小,并且准确度最高,达到了98.4%。采用LDA 算法对词向量矩阵填充后进行分类的准确度相对于没有填充后进行分类的结果要高出0.83%,因为本文提出的LDA模型对词向量矩阵进行填充,丰富了上下文的语义关系,使得分类的准确率更高,可解释性也更好。

图5 Loss 变化曲线Fig.5 Loss curve
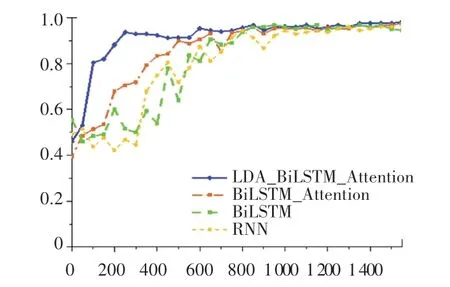
图6 Accuracy 变化曲线Fig.6 Accuracy curve
上述4 种模型的返回值和综合评价指标随迭代次数的变化曲线如图7 和图8 所示。可以看出本文提出的LDA_BiLSTM_Attention 混合模型性能表现最佳,未加LDA 填充算法的BiLSTM_ Attention模型性能表现次之,这说明LDA 算法对词向量矩阵填充后使用混合BiLSTM_Attention 结构作为模型主体的效果显著,充分发挥BiLSTM 算法在长文本序列中获取历史信息的能力与LDA 算法填充主题词向量矩阵的优势,从而提高了文本分类的综合指标。
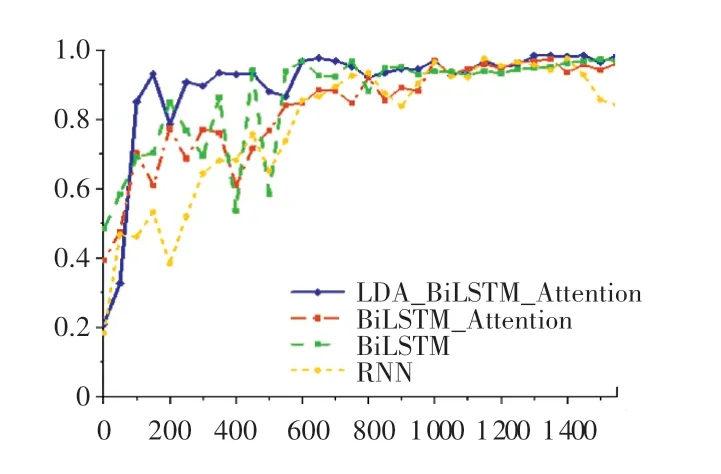
图7 Recall 变化曲线Fig.7 Recall curve

图8 F1 变化曲线Fig.8 F1 curve
3 结束语
文本表示是文本分类的重要过程,针对文本复杂语义表达的问题,本文提出一种LDA最大概率主题填充模型来丰富文本词向量矩阵。首先,运用word2vec 词嵌入方式生成文本向量;其次,根据LDA模型对文本向量进行填充,丰富语义信息,采用BiLSTM_Attention模型训练填充后的词向量矩阵;最后,采用softmax 进行分类。通过与其他几种文本分类模型的对比可知,本文提出的LDA最大概率填充算法能有效提高文本分类的准确度。
