基于python 的社交情感分析注意力模型
2021-03-01薛涛
薛 涛
(运城师范高等专科学校 数计系,山西 运城 044000)
0 引 言
人们通过社交平台来表达感受、情绪和态度,社交平台的帖子中通常包含丰富的信息,因此社交媒体成为热门研究对象。其中,情感分析是最基本且关键的研究主题之一[1-3]。情感分析的目的是分析社交媒体的极性,以判断人们对某些事件所持有的正面、负面或中性态度[4-5]。有研究者提出将社交媒体中的表情符号应用于情感极性预测,目前大多数现有的方法不仅依赖于手工特征,还分别考虑了表情符号和纯文本的情感,但并没有充分探索表情符号对文本情感极性的影响。表情符号在纯文本的情感极性中起着重要作用,对于情感原本是中性的纯文本,在纯文本后添加开心或沮丧的表情会使帖子表达不同的情绪极性。
本研究提出了一种深度学习模型,结合表情符号对文本情感极性的影响以进行情感分析。该模型使用双向长短期记忆模型来构建社交平台帖子的表示,使用注意力模型计算每个单词的权重。研究的主要贡献有两点:首先建立了带有表情符号、包含超过1 万条帖子的语料库;其次,联合训练微博帖子中的表情符号和单词,获得包含其上下文信息的表情符号表示。
1 符号语料库
大多数现有的情感分析语料库仅包含一小部分带有表情符号的内容,这些语料库并不适用于基于表情符号的情感分析。因此,需要收集和注释带有表情符号的文本。
由新浪微博收集了250 000 条微博帖子,从中提取了85 000 条包含表情符号的帖子。根据每个表情符号的出现次数,对微博帖子进行排名,并选择至少出现10 次的表情符号集。用表情符号分割每条微博帖子,选择只包含一个表情符号的微博帖子,并过滤掉帖子中的URL、用户名和主题标签以清理数据,并选择至少出现10 次的表情符号集。用表情符号分割每条微博帖子,并保留长度大于5 的微博帖子。在筛选出的35 000 条微博帖子中,随机抽取了18 000 条微博帖子进行下一步标记,并使用Jieba 中文文本分词工具进行分词。
采用手工标注的方式来构建语料库。情感极性分为正面、中性和负面,分别用0、1、2 表示。首先,仅根据文本来判断每个帖子的极性,即从文本中删除表情符号,仅使用每条微博帖子的纯文本来确定帖子的极性;然后,结合文本和表情符号来确定每个帖子的极性。语料库的极性结果见表1。
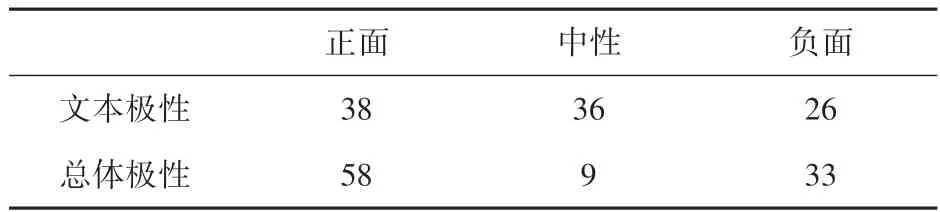
表1 语料库的极性Tab.1 Corpus polarity %
由此可见,表情符号的出现会改变帖子的情感极性。表2 展示了情感极性变化的社交帖子情况。

表2 情感极性变化的情况Tab.2 Changes of emotional polarity
2 情感分析模型
本文提出的社交情感分析注意力模型结构如图1 所示。
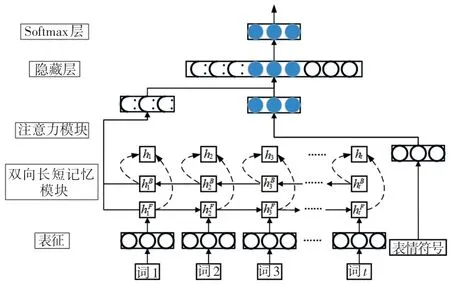
图1 情感分析模型Fig.1 Sentiment analysis model
应用双向长短记忆(Bi-directional Long Short Term Memory,Bi-LSTM)模型学习句子的表征,将表征作为特征对情感的极性进行分类。本文使用PyTorach 来实现该模型,PyTorach 是一个基于Python 的深度学习框架。模型初始化过程如下:


LSTM 能捕获序列中的长距离依赖关系。一个LSTM模型由多个LSTM 单元组成,其中每个LSTM单元对神经网络中的记忆进行建模。LSTM 单元包含的门结构允许LSTM 存储和访问随时间变化的信息。给定一个包含词wt的短文本,使用嵌入矩阵We将这些词嵌入到向量xt=Wewt中,该向量的维度是d。Bi-LSTM 包含一个前向LSTM 以读取从x1到xT的文本和一个后向LSTM 以读取从xT到x1的文本,即:

Bi-LSTM 将每个词wt映射到一对隐藏向量和中,那么一个词可以表示为一对向量的串联,即ht=。因此,得到[h0,…,hT],然后将其输入到平均池化层以获得句子的表示s。
为了表明表情符号对文本情感极性的影响,提出了一种基于表情符号的注意力机制。给定一个微博帖子,每个词对情感极性的贡献是不一样的,表情符号的交互权重也不均等。EA 机制结合单词和表情符号来衡量微博帖子中单词的权重。
在微博帖子{w1,...,wT;E} 中,wi表示单词,E表示表情符号。首先,wi和E都被转换为向量表示,即xi和e。
聚合这些词的表示以形成句子表示,句子表示s是隐藏状态hi的加权和,即:

其中,权重ai用于衡量第i个词的重要性,其计算方式为:

其中,函数f(·)表示单词的重要性,函数f(·)的定义为:

其中,Wh、WE是可学习的参数;vT表示v的转置;b是偏置。
串联了3 种类型的特征,如下所示:

其中,和表示最后一步中前向和后向LSTM 的隐藏状态。
训练的目标是最小化交叉熵损失,在引入基于表情符号的注意力机制后,获得了用于文本情感分析的特征lc。模型使用线性变换,将lc投影到C种类别的目标空间中:

之后,使用一个softmax 层来获得微博帖子情感的概率分布:

其中,C是情感标签的数量,pc是情感标签c的预测概率。
softmax 层的python 实现如下所示:


设(d)是帖子的目标分布,pc(d)是预测的情绪分布,D是微博帖子的集合。训练目标是最小化集合D中的(d)和pc(d)之间的交叉熵损失,则损失函数定义为:

3 实验评估
为了获得单词和表情符号的嵌入表示,使用word2vec.3 的SkipGram模式,对由350 万条微博组成的大规模语料库上训练单词和表情符号嵌入。
实验中使用5 重交叉验证。原始数据被随机分成5 个相等的部分,其中4 个部分用于训练,第5 部分用于测试。从4 个训练部分中随机选择一个部分作为开发集来调整超参数。分类结果通过准确度来衡量。准确度定义为T/N,其中T表示预测的与真实情绪评级相同的情绪评级数量,N表示微博的总数量。由于多分类中类不平衡问题,还使用了宏观精度来进行更公平的比较。
将词嵌入和表情符号嵌入的维度设置为200。LSTM 单元中隐藏状态和单元状态的维度设置为100。在训练期间,使用Adadelta 作为优化方法。训练的批次大小为16,动量为0.9,初始学习率α为0.01。
为了评估本模型的性能,将其与E-only[6]、SVM、LSTM 和Bi-LSTM 等算法进行了比较。其中,E-only 是仅使用表情符号来判断情感的极性,Bi-LSTM 将微博帖子的文本和表情符号作为Bi-LSTM模型的输入进行情感分析,实验对比了各个模型的精度、召回率、F-度量和准确度,表3 给出了所有模型进行情感分析的实验结果。由于类不平衡问题,算法在中性极性的性能要远低于其它极性。
实验结果从表3 的结果可见,由于模型利用了包括文本、表情符号特征,以及表情符号对文本的影响,本文模型表现最佳。这表明基于表情符号的注意力,可以有效地捕捉表情符号对文本情感极性的影响。此外,LSTM 优于SVM,表明与具有稀疏指标特征的离散模型相比,神经网络模型能更好地提取文本和表情符号特征。

表3 实验结果对比Tab.3 Comparison of experimental results
Bi-LSTM模型与本文模型对不同情感极性的准确率比较,结果见表4。从中可以看出,在情感变化方面,本文模型在大多数情况下优于Bi-LSTM模型。

表4 极性变化的准确度对比Tab.4 Accuracy comparison of polarity changes
4 结束语
本研究设计并实现了基于注意力模型的情感分析模型。该模型考虑了表情符号对文本情感极性的影响。与现有的模型相比,本模型实现了较好的性能。未来的工作将在以下两个方向上进一步研究表情符号对短文本情感极性的影响。首先,将研究扩展到其它类型的短文本。其次,将采用其它神经网络模型以探索表情符号对文本的影响。
