基于深度学习的音频分离
2021-03-01何一锋戴艺宁陈一凡
何一锋 戴艺宁 陈一凡

摘 要:目前部署的沉浸式音频内容的范式是基于音频对象的,它是由一个声轨和位置元数据组成的。 基于电影对象的作品通常由几十个同时进行的音频对象组成,这给音频对象的提取带来了挑战。我们通过构建一种深度学习方法来提取对象,从基于对象的作品的多声道渲染中学习,而不是直接从音频对象本身学习。这种方法可以解决对象的可扩展性问题,也提供了以监督或无监督的方式来制定解决问题的可能性方案。
关键词:音频分离,深度学习,监督,无监督
中图法分类号TP389.1
1简介
音轨和位置元数据组成的音频对象在播放过程中被渲染成特定的听觉布局(如5.1或立体声),这比传统的多声道制作提供更高的灵活性、适应性和沉浸性。基于对象的音频制作是由几十个同时进行的音频对象组成。这种对象的可扩展性问题也从模型优化的角度带来了挑战。语音[7-9]和通用[3, 10]源分离文献中描述的包络模糊性问题也出现在这里。由于任务的来源(或说话人)独立性质,监督学习所需的输出到基础真理对不能被任意分配。 为了克服这些挑战,我们提出了一种基于多通道学习的方法:我们监督学习的参照物不是物体,而是由这些物体呈现的多通道混合。基于多通道的学习的灵感来自于人类评估电影作品的方式,根
据这种方式,即使两个混合中的物体数量可能不同,如果两个基于物体的作品在多通道布局中的渲染也是相似的,那么它们就被认为是相似的。我们提取少量的对象,通常是1-3个,对应于最突出的听觉事件,以及一个多通道的剩余部分,称为 "嵌入通道",包含没有嵌入对象的音频。因此,我们研究独立于源的深度学习模型,除了嵌入通道外,还可以提取多达3个的对象。
2多渠道学习
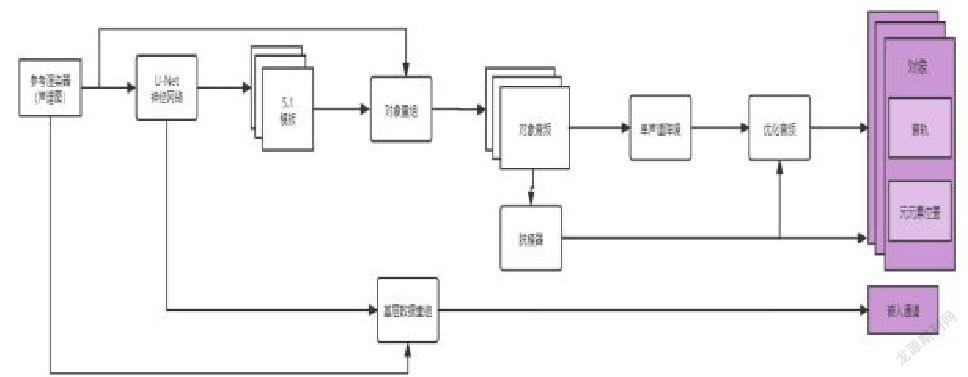
我们设计并建立了一个神经网络,给定一个多声道摘录,提取一个固定数量的音频对象、位置元数据和一个多声道提醒(嵌入通道)。为了简化操作,我们假设5.1输入--尽管我们的方法可以扩展成任何多声道输入格式。如上所述,我们的训练目标并不依赖于基于对象的监督学习。相反,我们的训练目标被设计为以有监督或无监督的方式从多通道渲染中学习(见图1)。
· 监督学习一个基于对象的参考组合需要渲染一组预先确定的多通道布局(例如,2.0、5.1、7.1、9.1)。 所获得的渲染结果被用作重建损失的参考,该损失是在多声道布局领域定义的。 这个损失是由每个多通道格式的重建损失的加权平均数组成的。 这种监督下的配置需要一个基于对象的训练集,所有的参考多通道渲染都来自于此。
· 我们设计并建立了一个神经网络,给定一个多声道摘录,提取一个固定数量的音频对象、位置元数据和一个多声道提醒(嵌入声道)。因此,基于多渠道的学习是通过处理问题的结构化方式实现的。我们通过模型的结构和损失函数中的额外正则化项来执行这种结构。
·无监督学习也可以用来适应一个特定的多声道摘录。通过无监督学习适应特定的5.1混音,可以在不需要任何训练数据库的情况下提取音频对象。这种 "无监督编码 "的情况可以被看作是一个5.1到5.1的自动编码器,它覆盖了一个特定的例子,其中模型的结构和正则化损失项的指导使模型朝着提取潜在的有意义的音频对象方向发展。
图1. 基于多通道的音频对象提取型。对于推理和训练,可学习的对象提取器(编码器,见图2)从输入的5.1中提取对象和床位通道。对于训练,不可训练的可区分的渲染器将它们解码为一些布局。对于无监督训练,目标函数只基于5.1的混合(蓝框)。在有监督的训练中,其他渲染器會被额外考虑(蓝色和黄色方框)。
3建模
我们的模型由一个对象提取模块(编码器)和一个渲染器模块(解码器)组成--见图1。编码器(图2)执行音频对象提取,并将5.1输入转换为基于对象的格式。 解码器的对象是将提取的对象和嵌入通道渲染成多通道混合,以便进行有监督或无监督的基于多通道的学习。
编码器(图2)由以下部分组成:(i)掩码估计块,一个可训练的深度神经网络,用于估计对象和嵌入通道掩码;(ii)其余对象提取块,用于从估计的掩码中提取音频对象(包括位置元数据)和嵌入通道。(iii)依赖于可微分的数字信号处理层来进一步处理对象掩码和床面通道掩码,以重建对象和床面通道。去除器从5.1对象音频中提取位置元数据。我们目前的实现是基于一个可区分的数字信号处理层;当然,它也可以扩展为一个可学习的深度神经网络。解码器扭转了优化过程(在渲染过程中,对远离正面位置的对象降低了对象的电平)。 解码器只是一个完全可区分的音频对象渲染器,它将对象和嵌入通道渲染成特定的多通道布局。
在我们的实现中,整个模型是用Tensorflow编写的,包括可训练和不可训练的数字信号处理模块。脱模器和解削器也对应于杜比全景声渲染器。该模型对48kHz的5.44秒的音频摘录进行操作,FFT窗口长度为2048个样本,导致256个时间仓和1025个频段的音频补丁,它们被分组为128个mel bands。
图2. 编码器,它从5.1混音中提取物体和床位通道。如图1所示,红色方框表示模型的可学习部分,绿色方框表示不可学习的可区分的数字信号处理部分。
4训练目标
我们依靠两个主要的训练目标:重建损失,在多通道层面上匹配混合的内容,以及规则化损失,鼓励提取的对象表现得一致。
重建损失 - 这些损失来自于参考渲染/混合和解码器的输出之间的比较。正如在第2节和第3节中所讨论的,在基于多通道的监督学习中,我们比较了几个参考渲染(2.0)和解码器的输出。在基于多通道的监督学习中,我们将几个参考渲染(2.0、5.1、7.1和9.1,由基于参考对象的制作渲染)与相应的解码器输出进行比较。
正则化损失--为了说明这些正则化术语的必要性,对于无监督的情况,模型可以通过将所有内容发送到嵌入通道来将重建损失最小化为零。有必要使模型偏向于与预期的基于对象的制作方式相对应的解决方案。
5实验和评估
5.1实验方法
我们设计了一个实验。这项实验从5.1混音中提取1或3个对象和嵌入通道,这些对象是由可用于评估的已知对象呈现的。该实验是从包含1个对象和床铺通道的5.1混音中提取对象。混音中的对象是通过将伪随机合成轨迹分配给电影混音中出现的不同声音类别(车辆声音、特殊效果、乐器、声音、脚步声等)的真实音轨来创建的,这些音轨从Freesound Datasets[20-22]中获得。这些基于对象的节选还包含有真实的圆形录音的嵌入通道。
5.2 实验结果
在单对象实验中,前牵引床通道的表现明显优于基线。然而,在三对象实验中,"无监督 t "和 "精确调整 "的配置不如基线的表现。这个结果说明了"无监督 t "和 "精确调整 "方法的优势和劣势。虽然这些方法通过对一个特定的5.1节选实现了最好的对象提取结果,但我们引入的强烈的归纳偏见导致了积极的对象提取,这可能会影响到嵌入通道的质量。这一点对于 "无监督测定 "的影响尤其明显,即从头开始训练,在没有额外训练数据的情况下,需要对一个给定的5.1进行测定。
6结论
我们提出了一个独立于源的方法,即依靠强大的诱导性偏差来学习多通道渲染。我们探索的归纳偏差是基于架构约束(强制我们模型的瓶颈是一个特定的基于对象的格式),以及额外的正则化损失条款(强制对象按照基于对象的生产惯例行事)。 基于多渠道的学习可以以监督或无监督的方式进行,并在分离音轨方面能达到较好的效果。
参考文献:
[1] Berkan Kadioglu, Michael Horgan, Xiaoyu Liu, Jordi Pons, Dan Darcy, and Vivek Kumar, “An empirical study of Conv-TasNet,” in ICASSP, 2020.
[2] Yi Luo and Nima Mesgarani, “Tasnet: time-domain audio sepa- ration network for real-time, single-channel speech separation,” in ICASSP, 2018.
[3] Yuzhou Liu and DeLiang Wang, “Divide and conquer: A deep CASA approach to talker-independent monaural speaker separation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 27, no. 12, pp. 2092–2102, 2019.
[4] Ilya Kavalerov, Scott Wisdom, Hakan Erdogan, Brian Patton,Kevin Wilson, Jonathan Le Roux, and John R Hershey, “Univer- sal sound separation,” in 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 2019.
[5] Scott Wisdom, Efthymios Tzinis, Hakan Erdogan, Ron J Weiss,Kevin Wilson, and John R Hershey, “Unsupervised sound separation using mixtures of mixtures,” in NeurIPS, 2020.
本文得到上海立信會计金融学院大学生创新创业训练计划(s202111047008)基金支持. 何一锋(2000-),男,江西景德镇人,计算机科学与技术本科在读
