基于RFM模型和随机行动者导向模型的技术机会识别
2021-02-25张振刚罗泰晔
张振刚,罗泰晔
(1.华南理工大学工商管理学院,广州510640;2.广州数字创新研究中心,广州510640;3.广东省科技革命与技术预见智库,广州510640)
1 引言
技术机会识别,是发现特定技术领域内具有潜在价值的技术应用机会的过程。在科技发展日新月异的背景下,准确识别领域内的技术机会,对于研发组织的可持续发展具有重要的意义。识别技术机会的方法分为定性分析和定量分析两类。在定性分析方法方面,德尔菲法和情景分析法是两种主要的方法[1]。定性分析方法主要依靠专家的意见,存在程序复杂、耗时长、社会成本高、专家意见的差异性不易处理等问题[2]。因此,大多数研究者都采用定量的方法来识别技术机会。在进行定量分析时,专利数据是常用的素材。专利是创新成果的一种表现形式,其本质在于包含在其中的知识,一个专利所含有的知识可以看成是若干知识元素的集合[3-4]。根据知识基础观(knowledge-based view),知识是创新投入和价值创造的主要来源[5]。因此,有学者提出了知识组合理论,其认为创新在本质上是研发或实验中对知识元素进行组合的过程[6-8]。这个过程既包括探索新的知识元素组合,又包括对已有知识元素组合的重用(reuse)[6]。在对知识元素进行组合的过程中,不同的知识元素出现的时间、频率及组合能力各不相同。因此,本研究利用知识元素的这些特征来识别特定领域的技术机会,提出一种基于专利分析的技术机会识别新方法。
2 相关研究
2.1 技术机会识别
目前,技术机会识别主要有三个研究方向。第一个研究方向是研究技术融合。技术融合是指两个或多个技术领域实现知识的共享和交叉应用[9]。例如,Park等[10]以生物和信息领域的专利为分析对象,基于专利引用网络来预测两个领域间的知识流动,进而发现技术融合的机会。Han等[11]通过关联规则对专利分类号进行分析,发现了信息通信领域与其他技术领域的技术融合机会。第二个研究方向是研究技术空缺,即识别能够满足某领域技术需求的机会[12]。例如,Choi等[13]使用贝叶斯模型对专利进行聚类,进而发现领域内的技术空缺。Son等[14]以光刻技术的专利为例,利用生成式拓扑映射(GTM)来开发专利地图,并发现地图中的空白区域,通过空白区域与原始关键词向量的逆映射来解释每个空白的含义,最终发现了空缺的技术机会。第三个研究方向是研究新兴技术,即具有高增速、高新颖度、高不确定性以及高市场潜力的技术[15]。例如,Joung等[16]构建了专利关键词矩阵,使用层次聚类的方法来发现葡萄糖生物传感器领域的新兴技术。Moehrle等[17]以影像技术的专利为素材,通过专利语义分析来识别领域内的新兴技术。
2.2 RFM模型
RFM模型是市场营销领域识别客户价值的经典模型,用于在观测点对观测期(观测点之前的一段时间)内顾客消费的情况进行分析,从而识别出重要价值客户[18]。R(recency)是指顾客消费的临近性,常用最近一次消费距离观测点的时间长度来衡量;F(frequency)是指观测期内顾客消费的频率;M(monetary)是指顾客的消费能力,常用观测期内顾客消费的金额来衡量。基于RFM模型,Cheng等[18]分析了一家台湾电子产业公司的顾客的忠诚度;Yan等[19]通过分析财产保险公司的客户的终身价值来评估客户风险;Seymen[20]研究了英国连锁超市顾客流失的情况,并进行顾客细分;马宝龙等[21]提出了一种对未来顾客价值进行识别的方法,并用一家购物中心的顾客交易数据进行了实证分析。
2.3 随机行动者导向模型
随机行动者导向模型(stochastic actor-oriented models,SAO模型)是基于纵向数据来分析网络动态演化的模型,可同时分析网络的演化和网络节点行为的变化,是近年来社会网络分析领域兴起的从动态视角分析社会网络的有力工具。在SAO模型中,网络演化的过程被称作社会选择(social selec‐tion),而网络节点行为变化则是社会影响(social influence)的过程。SAO模型把网络的演化视为网络中的节点建立、维持或终止与其他节点之间连接的过程。网络节点的连边选择受如下目标函数控制[22]:

其中,snet表示影响节点连边选择的各种效应;βnet表示效应的参数估计。
类似地,网络节点在不同时期的行为变化受如下目标函数控制:
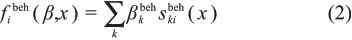
其中,sbeh表示影响节点行为变化的各种效应;βbeh表示效应的参数估计。
基于SAO模型,Cao等[23]分析了基于建筑信息建模的工程中合作网络的演化。吴江等[24]研究了在线医疗社区用户关系网络的动态演化。Finger等[25]探讨了驱动银行间货币市场网络形成的因素。在分析网络成员行为的演化方面,Mohrenberg[26]分析了贸易开放政策在不同国家间的扩散情况。Kavaler等[27]研究了开源软件社区软件开发者的代码所有权和开发效率的变化。
2.4 述评
在技术机会识别方面,现有基于专利数据的定量分析方法大多停留在专利的外部指标层面,如专利关键词分析、引用情况分析等,对专利的知识本质还缺乏充分利用。RFM模型主要用于客户关系管理领域,但其通过关键指标聚类来识别重要价值对象的思想可以为其他领域的研究提供借鉴。在SAO模型的使用上,现有研究主要集中在分析社会网络的演化和网络节点行为的变化,而鲜有用于知识网络的分析。本文基于专利的知识本质和知识组合理论,借鉴RFM模型的思想来评价特定领域的知识元素,使用SAO模型来分析知识网络的演化和知识元素的组合特征,并在此基础上提出识别特定领域技术机会的新方法。
3 研究设计
由于一个技术领域内的知识元素众多,不同知识元素的利用价值各有不同,本研究需要识别能反映领域内技术发展趋势的知识元素,并探索这些知识元素进行组合的新机会。因此,本文采用三个步骤进行分析:第一步,提出识别趋势性知识元素的方法;第二步,分析知识元素的组合规律,并提出识别技术机会的方法;第三步,根据所提出的方法,预测趋势性知识元素的组合机会,并检验预测的准确性。其中,第二步要以特定技术领域的专利数据为素材,本研究以人工智能领域为例,在分析前进行数据的收集。选择人工智能作为目标分析对象的原因有三方面:第一,从领域知识特性上看,人工智能领域的知识具有多学科交叉性,覆盖了电子、计算机、生物医学等多个知识领域。分析人工智能领域的技术创新,实质上是分析多个领域的技术创新。因此,与单一领域相比,选择人工智能领域作为分析对象更具普遍性和代表性。第二,从统计学特性上看,人工智能领域的专利成果较多,能够提供大样本的分析素材,使分析结果更具可靠性。第三,从实践性上看,目前,世界上许多国家和地区都把人工智能作为战略性新兴产业。因此,挖掘人工智能领域的技术机会,具有重要的实践参考价值。
3.1 数据收集
本研究借鉴文献[28]使用的检索式,用从德温特专利数据库检索了2013—2018年人工智能领域的专利数据,共12579条记录。参考已有研究的做法[4,29],本文用专利的国际分类号(IPC)来表示专利所含有的知识元素。专利的国际分类号采用等级形式,分为部—大类—小类—大组—小组等五个等级。已有的大部分研究都是采用分类号的前四位(即小类级)来代表知识元素。但小类级的代码包含的技术范围过于宽泛,不能准确描述专利所具有的知识元素。而分类号到大组级能够较好地反映专利所代表的产品、技术过程和机制[30]。因此,本文用大组级的分类号来代表专利所具有的知识元素。
3.2 技术机会识别方法
根据知识组合理论的观点,专利发明是对相关知识元素进行组合的结果,不同的知识元素的组合能力不尽相同[31]。在一个观测期内,不同的知识元素出现的频率和出现的时间也存在差异。知识元素的这些特征与市场营销领域顾客的消费行为特征存在相似性。因此,借鉴RFM模型的思路,本研究使用三个指标对知识元素进行评价,识别出领域内的重要知识元素。其中,R代表知识元素出现的时间特征,F表示知识元素出现的频率,M则代表知识元素的组合能力。根据相关研究,一个知识元素的组合能力越强,则该元素与其他知识元素的相关性越强,能够与之进行组合的知识元素越多,其应用越具有多样性,其应用潜力和应用价值也就越大[7,29,31]。本文对三个指标的计算方法如表1所示。

表1 知识元素评价指标
表1 中提到的知识网络由知识元素组成,知识网络中的节点代表知识元素,两个知识元素在同一个专利中出现,代表了一种组合,在网络中将代表这两个元素的节点相连。基于上述三个指标,本研究通过聚类的方法来发现领域内的重要知识元素。这类知识元素具有三个特点:一是出现的时间离观测点较近,具有一定的时效性,代表了新近的应用方向;二是出现频率高,代表了领域内的热门技术应用;三是与较多的知识元素进行过组合,具有较强的组合能力。对具有这三个特征的知识元素进行研究和应用,在一定程度上代表了未来领域内技术的发展趋势[12]。因此,本文把这类知识元素称为领域内的趋势性知识元素。
在识别出趋势性知识元素后,本研究需要对这些知识元素未来的组合机会进行预测。为得出知识元素间进行组合的特征和规律,使用SAO模型来分析知识网络的演化。本研究以2013—2015年每年都出现的知识元素为对象,以一年作为一个观测期,共三期,相应地构建三个知识网络,用于SAO模型的分析。SAO模型的参数估计和模型检验使用R语言中的RSiena程序包编写代码,采用马尔科夫链-蒙特卡洛估计法(MCMC)来进行研究。表2中列出了影响知识元素间进行组合的常见效应及其参数估计的情况。

表2 SAO模型检验
从表2可以看出,模型的总体最大收敛率(over‐all maximum convergence ratio)为0.0623,小 于0.25,这说明模型整体收敛度较好,各种效应检验可靠。Rate parameter period 1表示从第一个观测期(2013年)到第二个观测期(2014年)之间知识网络中节点的连边改变的平均程度;Rate parameter period 2表示从第二个观测期(2014年)到第三个观测期(2015年)之间知识网络中的连接改变的平均程度。degree(density)的系数为负,说明所构建的网络密度较低。transitive triads的系数为正且效应显著,表明知识网络在演化过程中存在明显的传递性效应,即具有共同邻近节点的知识元素间有建立连接的趋势。degree act+pop效应反映的是程度中心度高的节点在网络演化过程中建立更多连接的趋势,该效应的系数为正且显著,说明知识网络中程度中心度高的知识元素在网络演化过程中能够与更多的知识元素进行组合。
因此,一个知识元素的中心度、与焦点知识元素的共同好友数可以作为判断这个知识元素与焦点知识元素进行组合的可能性的指标。这两个变量及其交互作用能在一定程度上反映两个知识元素间的组合趋势。此外,两个知识元素在知识网络中的距离也会在一定程度上影响两者进行组合的可能性[32]。基于上述分析,本文提出组合值的概念,用来衡量知识元素间的新组合机会,焦点知识元素i与知识元素j的组合值用如下公式计算:
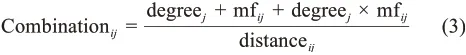
其中,degreej表示知识元素j在知识网络中的程度中心度,即网络中与j直接相连的节点数;mfij表示知识元素i和j在网络中的共同邻居节点数;distan‐ceij表示知识元素i与j在知识网络中的距离。两个知识元素的组合值越大,意味着两者间进行组合的可能性越大。
4 数据分析
本研究将检索到的专利数据分为两段:2013—2015年为一个时间段,2016—2018年为另一个时间段。基于2013—2015年的数据,利用本研究提出的方法来识别趋势性知识元素,并预测趋势性知识元素可能出现的新组合,即新的技术机会,然后利用2016—2018年的专利数据来检验预测的准确性。
4.1 知识网络构建
由于第3.2节中的公式(3)包含了知识元素在知识网络中的中心度,本研究根据2013—2015年间的所有知识元素在专利中的共现情况构建一个整体知识网络,如图1所示。图1中各节点旁边的代码为IPC分类号,代表知识元素的名称,整个网络中有696个节点。
4.2 趋势性知识元素识别

图1 知识网络
为识别出人工智能领域的趋势性知识元素,本文采用K均值聚类的方法,基于RFM模型的3个指标,将696个知识元素划分到不同类别。由于指标数为3,理论上最多可以把知识元素分为8类。本研究首先采用轮廓系数来确定最合适的类数[2]。图2显示了不同聚类数对应的轮廓系数。

图2 轮廓系数
从图2可以看出,聚类数为4时,轮廓系数最大,故本文把知识元素聚为4类。由于部分聚类指标有较大的方差,在聚类前先对各指标数据进行了标准化处理。聚类结果如图3所示。
从图3中可以看出,696个知识元素被划分为了4类,知识元素数量分别为439、53、200、4。各类的聚类指标均值如表3所示。
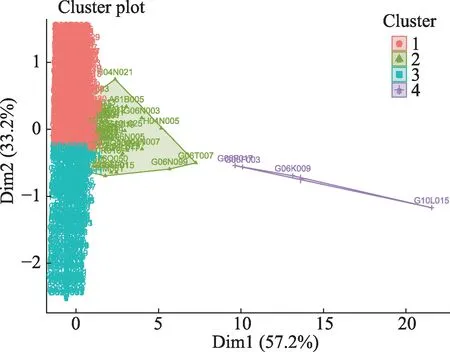
图3 聚类结果

表3 聚类指标均值
从表3可以看出,第4类的4个知识元素平均出现时间短、频率高、组合能力强,故本研究认为这4个知识元素是人工智能领域的趋势性知识元素,这4个知识元素的具体内容如表4所示。
从表4可以看出,人工智能领域的趋势性知识元素可以分成三类:电数字数据的处理(包括处理方法和处理装置)、图像识别和语音识别。可以认为,这三类知识代表了人工智能领域的应用趋势。因此,本文需要对这三个具体方向的新技术机会进行识别。
4.3 技术机会识别及验证
为分析表4中的4个趋势性知识元素的新技术机会,本研究基于公式(3),计算在2013—2015年未与这4个知识元素组合过的知识元素与其组合值,并将组合值最大的10个知识元素视为趋势性知识元素潜在的新技术机会,具体结果如表5所示。
为了检验上文提出的方法的有效性,本文统计了2016—2018年每个趋势性知识元素与表5中的10个知识元素进行组合的实际情况,结果如表6所示。
结合表5和表6可以看出,对于趋势性知识元素G06F017来讲,组合值最大的10个知识元素中有5个在2016—2018年间与之进行了组合。例如,知识元素G01N021与G06F017之间的组合出现了3次,知识元素G07C009与G06F017之间的组合出现了1次。技术机会识别的准确率为50%。类似地,对于趋势性知识元素G06K009、G06F003和G10L015来讲,技术机会识别的准确率分别为90%、70%、60%。总体而言,本研究预测的40个新技术机会中有27个在2016—2018年间出现,总体预测精度为67.5%。因此,本研究提出的方法能够以一定的准确率识别出趋势性知识元素新的技术机会。

表4 趋势性知识元素及其描述
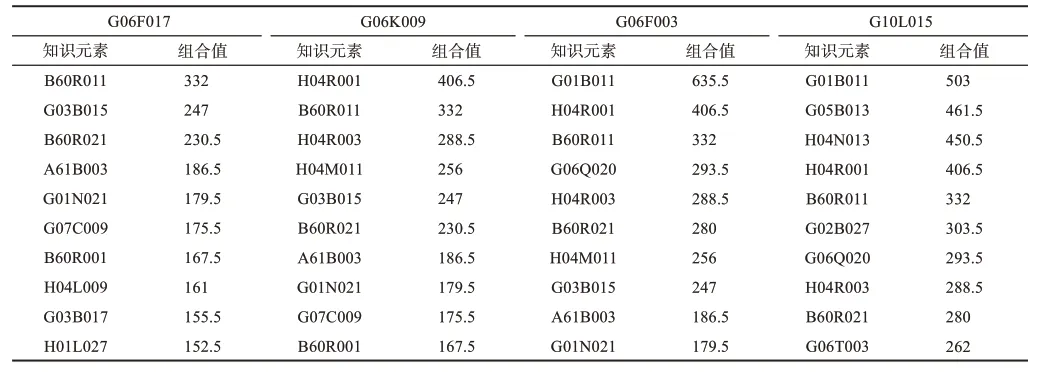
表5 趋势性知识元素的新技术机会
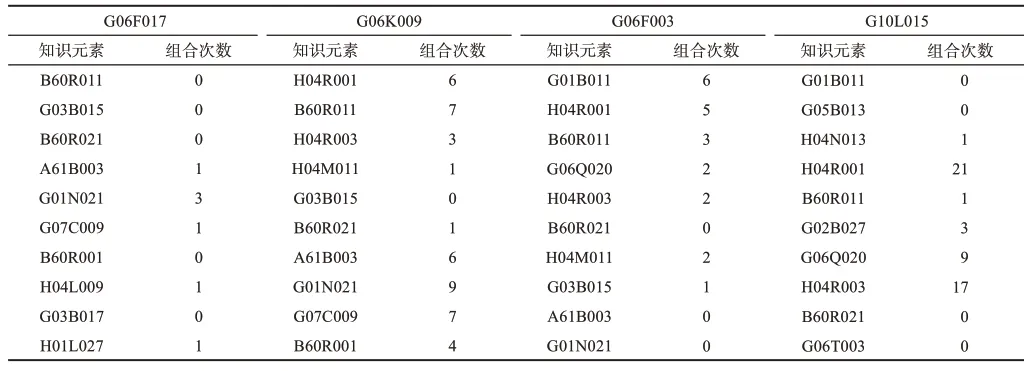
表6 趋势性知识元素新技术机会验证
从知识元素的具体内容上看,人工智能技术的应用范围非常广泛,包括:医学诊断(A61B003)、立体电视系统(H04N013)、光学计量(G01B011)、支付系统(G06Q020),等等。这在一定程度上增加了研发人员确定研发对象的难度,而本文提出的方法能够在研发方向上给予研发人员一定指引和启发。
4.4 稳健性检验
为检验上文所提出的方法的稳健性,本研究从德温特数据库检索了3D打印领域2014—2018年间的17272条专利数据进行分析。3D打印于2013年左右兴起,涉及材料、信息、电子、机械等多个技术领域,具有多学科、多领域交叉融合的特征,因此具有一定的代表性。基于2014—2016年的专利数据,本研究进行趋势性知识元素的识别和技术机会的预测,再用2017—2018年的数据进行检验。知识元素聚类结果如图4所示。

图4 3D打印领域知识元素聚类

表7 3D打印领域技术机会识别
从图4可以看出,知识元素被聚为5类。其中,聚类5里的8个知识元素为3D打印领域的趋势性知识元素。根据本研究提出的方法对这8个知识元素的组合机会进行预测,结果如表7所示。从表7可以看出,本研究预测的80个技术机会中,有51个在2017—2018年出现,预测准确率为63.75%。这再次证明了本研究所提出的方法能够以一定的准确率预测特定领域的技术机会。
5 结论
本文基于知识组合理论,以人工智能领域2013—2015年的专利数据为素材,首先,通过RFM模型的三个指标对知识元素进行聚类,进而识别出领域内的四个趋势性知识元素。其次,使用SAO模型对知识网络的演化过程进行分析,发现了知识元素间进行组合的规律,并基于此提出了评估知识元素间进行组合的可能性的公式。最后,使用所提出的公式对四个趋势性知识元素的新组合机会进行预测,并使用2016—2018年间的专利数据验证了所提出的方法的有效性。同时,本研究也用3D打印领域的专利数据验证了所提出的方法的稳健性。
本研究具有一定的理论和实践意义。第一,本研究借鉴RFM模型中三个指标的具体内涵,提出了评价一个技术领域内知识元素重要性的方法。该方法能够识别出领域内的趋势性知识元素。第二,本研究使用SAO模型对知识网络的动态演化过程进行了分析,揭示了知识元素间进行组合的轨迹和趋势,发现与社会化网络相似,知识网络中也存在传递性效应和中心度效应。因此,本研究通过知识元素在知识网络中的位置特征来发现新的技术机会。第三,本研究提出了一种识别技术机会的新方法,丰富了利用专利数据进行技术机会发现的方法库。专利数据是可以通过公开渠道获得的数据。因此,本研究为研发组织发现技术机会和确定研发方向提供了一种可行的方案。
本研究也存在一定的局限性:首先,本研究以人工智能和3D打印领域的专利数据为对象进行分析,但不同技术领域的知识可能有不同的特点,其知识元素组合的方式也可能有所区别。因此,未来的研究可以对更多技术领域的专利进行分析,以进一步检验本研究所提出的方法的可靠性。其次,本研究所提出的方法预测技术机会的准确率在60%~70%,还有进一步提升的空间。本研究使用的知识元素中心度、共同邻近知识元素数、知识元素距离等均是描述知识元素特征及知识元素间关系的直观指标,能够对两个知识元素间潜在的组合关系进行基本地刻画,但不能进行全面地反映,解释力还可以进一步加强。
因此,未来的研究可以对本研究提出的公式进行优化。例如,在知识元素的网络位置特征方面,除了直接反映组合能力的程度中心度外,可以尝试反映中介性的中介中心度、反映连接紧密性的紧密中心度、反映网络冗余性的结构洞等变量。共同邻近节点数是节点相关性的一种体现,未来的研究也可思考出现时间等其他维度的相关性或相似性。
