电子政务领域中文术语层次关系识别研究
2021-02-25邓三鸿张宝隆
张 卫,王 昊,邓三鸿,张宝隆
(1.南京大学信息管理学院,南京210023;2.江苏省数据工程与知识服务重点实验室(南京大学),南京210023)
1 引言
数据驱动时代,电子政务信息作为我国政府机构的战略性资源,正伴随着自动化办公与社会管理的革新与日俱增。2019年,中央部委成功打通了42个国务院部门垂直管理信息系统[1],而地方平台“云上贵州”更是以1387TB的数据量实现了省市县政府9728个部门政务系统的对接[2]。不难发现,海量电子政务信息资源在开放共享中日益表现出多源异构的特征,这使得传统的以电子政务主题词表为核心的政务术语知识体系的不足也越发凸显,其特点主要表现为3个方面:①基于内容主题的术语层次较浅。就国内具有代表性的《综合电子政务主题词表》而言,其范畴表依据主题内容划分为21个知识范畴,虽然涉及政务领域广,但是术语层次较浅(仅至3级)。②基于结构关系的术语层次缺失。词表内诸多层次术语具有结构包含关系(如“保卫”与“安全保卫”),但尚不全面。③术语层次关联缺少语料支持。过去在缺少政务语料的条件下,只能采取人工构建词表的方式。随着电子政务的发展,公众对政府工作的参与性显著提高,一方面通过网络百科以标准化的形式了解政务知识;另一方面借助社交媒体关注实时的政务信息资源。这些都在当下催生出大量政务语料,也为在缺少语料库条件下形成的词表开拓了较大的术语层次优化空间。
由此可见,传统词表中的电子政务术语由于缺少在大规模语料支持下对层次范畴和语义逻辑的深层优化[3],难以在大数据时代适应电子政务信息资源的标引、检索以及组织工作,这就使得从语义角度自动化识别电子政务术语的深层关联显得尤为重要。
本体作为语义网体系内一种有效的知识组织方式,可以在信息系统的整合过程中将资源解析为机器所能理解的知识,通过语义驱动实现信息资源在网络环境内的交换与共享[4]。因此,本研究以本体学习6层次理论[5]中的概念层次为指导,采用电子政务主题词作为术语集,首先通过对网络百科语料中提取的内容特征采取聚类的方式生成具备高召回率的概念层次,称为基于内容的层次关系;其次,借助术语共现理论[6]对社交媒体语料建立概念格结构生成具有高准确率的概念层次,称为基于结构的层次关系;最后,将二者相融合,以前者为整体框架、后者为修正指导,从而形成了一整套电子政务术语本体构成方案,所形成的电子政务本体将在信息检索与推荐、跨部门协同共享、政务知识发现等实际应用中提供支持。
2 相关研究工作
采取内容与结构相融合的方法,对电子政务术语层次关系进行识别工作的研究基础主要包括两个方面:电子政务术语层次的组织工作和术语层次关系的识别方法。
就我国电子政务术语层次的组织工作而言,具有代表性的是中国科学技术信息研究所于2005年编制完成的《综合电子政务主题词表》,该词表由字顺表与范畴表所组成,是迄今为止国内收词量最多、专业覆盖面最广的政务主题词表[7]。然而,由于词表由来已久,而且电子政务信息资源开放共享的诉求日趋强烈[8],学者们也逐步展开了对词表的改进工作。贾君枝等[9]运用FAST主题词分面对词表进行分面式改造以契合公众检索需求。王汀等[10]则基于词表与百科提出了面向大规模本体的自动化扩充方案。目前,尚未有学者对词表的层次体系进行补充扩展抑或延伸细化。考虑到在缺少语料库下人工构建词表的主观性以及现有层次关系的不完备性[11],例如,在字顺表内,结构层面的术语“保卫工作”并未像“安全保卫”那样归置为“保卫”的下位类,也没有从内容层面细化“安全保卫”与“保卫工作”二者术语间的语义联系。因此,本文将基于范畴表的知识体系,通过大规模语料识别内容与结构层面的术语层次关系,形成具备深层树状结构的电子政务术语本体。
就本体中术语层次关系的识别方法来说,主要包括基于规则模板的方法与基于统计的方法[12]。基于规则模板的方法往往与句法依存分析[13]相结合,需要人工制定语言模板,在面向大规模非结构化文本所能获取的层次关系较为有限[14]。此外,不同领域所制定的模板方案在相互间的可移植性不高[15],这也不利于规则模板的推广。因此,本研究对电子政务术语层次关系的识别工作将基于统计的方法展开。由于采取不同的统计方法能够分别识别内容与结构两者层面上的术语层次关系,故将其划分为与之对应的两个角度:内容角度和结构角度。
内容角度,是指通过对文档内容所解析出的向量空间进行聚类以达至对术语聚类的目的。该方法由于对识别术语关联性具有较高的召回率而得到广泛应用,具体包括:层次聚类[16]、K-means聚类[17]、DBSCAN聚类[18]等。然而,这些方法在大规模术语层次关系的识别中均具有一定局限。如层次聚类是一种小规模高精度的聚类算法;K-means运行结果具有较大的随机性;DBSCAN聚类易将大量独立点判断成噪声,不适合高维稀疏数据。相较之下,源于图论思想的谱聚类[19]逐渐受到学界的推崇,其核心思想是通过降维将高维空间的数据映射到低维,从而实现对样本数据特征向量的聚类,面对高维稀疏矩阵能够实现精准且稳定的划分效果,适用于从内容角度识别术语层次关系。
结构角度,是指在术语共现理论的指导下通过形式概念分析(formal concept analysis,FCA)建立能够抽取出层次关系的概念格结构。该方法由于具备较高的准确率,在术语层次识别中也有不俗的表现。如de Farias等[20]通过FCA对巴西莫索罗市犯罪记录数据进行分析并建立具有犯罪模式的概念格,以期规划预防和打击犯罪的战略。王昊等[21]以“白血病”为例借助FCA实现了中文医学领域本体层次结构自动构建的有效方法,并对面向学科资源的医学专业术语层次关联的抽取进行了详细论证。
对两者进行比较。从内容角度采取聚类的方式识别层次关系,有利于提高术语关联的召回率,但准确率无法得到较好的保障;从结构角度采取FCA方法,能够有效地提高术语层次间的准确性,但由于概念格结构相对复杂使得层次关系的识别过于严格,导致在层次关系的抽取中会遗漏掉很多上下位关系。可以发现,采取基于内容或结构的统计方法各有利弊,然而尚未有研究将两者方法整合以优化术语层次关系的识别效果。
综上所述,在电子政务术语的组织工作中,鲜有学者基于大规模语料对内容与结构层面的术语层次体系进行扩展延伸,更鲜有研究将基于内容和结构的统计方法相融合对术语层次关系的识别效果进行优化改进。因此,本文拟将基于大规模语料从内容与结构双重视角识别电子政务术语层次关联,以前者生成的基于内容的层次关系为整体框架,以后者生成的基于结构的层次关系为修正指导,形成一个兼顾层次关联召回率与准确率的电子政务领域术语本体。
3 采用方法
本研究所采用的方法是针对电子政务术语所检索到的自然语言文本,从内容和结构双重视角识别电子政务领域中文术语层次关系的逻辑流程,如图1所示。
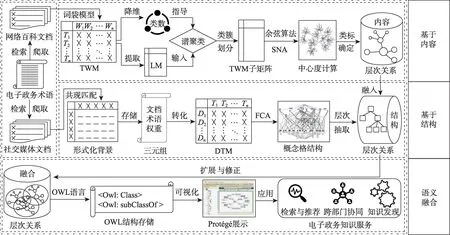
图1 电子政务中文术语层次关系识别的逻辑流程
由图1可知,电子政务中文术语层次关系的识别主要包括3个模块:①基于内容的层次关系识别。从内容特征的角度识别层次关系需要保证文档内容对电子政务术语内涵的支撑度,故采用网络百科作为语料,按照术语列表依次获取百科文档;随后,构建词袋模型从文档内容中提取关键词特征,获得文档-词语矩阵(document word matrix,DWM),并根据术语与百科文档间的独立匹配关系将其转化为术语-词语矩阵(term word matrix,TWM);接着,使用降维所确定的聚类数目与TWM所提取的拉普拉斯矩阵(Laplacian matrix,LM)进行谱聚类划分矩阵类簇,并形成TWM子矩阵;进一步,对子矩阵进行余弦相似度计算以获取术语之间的相似度,采用社会网络分析(social network analysis,SNA)计算术语中心度,并将中心度较高的术语作为子矩阵的类目标签;最后,使用多层谱聚类的方式,形成一个初步具备理论内涵的层次框架。②基于结构的层次关系识别。考虑到识别基于结构的层次关系有赖于在每篇文档中不同术语之间的共现属性,可用于揭示实践场景中电子政务术语间的应用情况,故采用社交媒体文档作为语料,并按照术语列表依次检索、爬取;随后,通过在社交媒体文档内术语的共现匹配建立形式化背景,并以<文档-术语-权重>三元组的格式存储;接着,将三元组转化为文档-术语矩阵(document term matrix,DTM),使用FCA建立电子政务术语的概念格结构,并从中抽取出更为精细且具备实践特性的层次关系。③语义融合。将基于内容与基于结构的层次关系相融合使其互为扩展、修正,便构成了更为完整、准确的电子政务术语本体,通过OWL结构存储即可开展多元的电子政务知识服务。下文将对整套流程中所采用的具体方法展开阐述。
3.1 基于内容的TWM与基于结构的DTM构建
从内容的角度通过聚类识别电子政务术语的层次关系,需要深入网络百科文档对单个术语的释义提取内涵特征,同时,要避免单个特征的力度过大,故采用TF-IDF构建电子政务术语内容文本的词袋模型[22],提取并统计出每个电子政务术语所对应的释义文档中相对于整体语料文档区分度较高的关键词及其权重,以此作为特征量化其在每个文档中的重要度。其中,单个文档的关键词及关键词权重能够形成一个权重向量,即文档特征向量,所有文档特征向量的集合便构建了电子政务领域的DWM,而由于每个电子政务术语能够与其释义文档独立匹配,故DWM亦可转换为TWM,后续聚类工作将基于TWM展开。
从结构的角度通过FCA识别层次关系,需要统计出所有术语在每条社交媒体文档内的共现情况,故而采取函数匹配判断单个社交媒体文档内所有术语是否出现,若出现统计为1,否则为0。若在一篇文档内不止一个术语出现,则称为术语共现[23]。其中,单个文档内术语集合的共现情况能够形成一个向量,所有文档向量的集合便构建了存储<文档-术语-权重>三元组的电子政务领域DTM,后续FCA工作将基于DTM展开。
3.2 基于PCA与T-SNE的聚类数目确定
对电子政务术语TWM聚类之前需要确定聚类数目,目前受到学界认可的自动化处理方式是将矩阵降维至二维或三维空间,通过可视化辅助聚类数目的判断[24]。
(1)主成分分析(principal component analysis,PCA)是一种对高维数据进行线性降维的方法[25],将高维特征映射到低维正交特征上,计算数据在正交特征上投影的方差,方差越大,正交特征包含的信息量越多,删去小特征值方向上的数据即可达到降维效果。
(2)T分布随机邻域嵌入(T-distributed stochas‐tic neighbor embedding,T-SNE)是一种非线性降维算法[26],通过高维数据点之间的概率分布使得相似对象有更高的概率被选中,同时,将对象点映射至低维空间构建概率分布,使两者尽可能相似以达到降维的效果。
首先,用数据点间的条件概率表示相似度,以xi为中心构建高斯分布(方差为σi),则有高维空间中任意两点xi、xj间的相似性pj|i均可使得邻域内的点(k)相似性较大,如公式(1)所示:
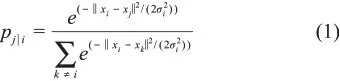
其次,为克服数据点间的“拥挤问题”,对高维数据点分布实行对称化使其与采用t分布的低维概率分布矩阵对称,用高维空间数据点对xi、xj和映射的低维空间重组的数据点对yi、yj之间的联合概率pij、qij分别表示数据点之间的相似度,如公式(2)所示:
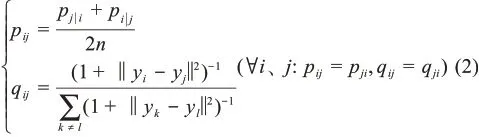
再次,采用KL散度(Kullback-Leibler diver‐gence)作为目标函数测度两种分布之间的差异,利用随机梯度计算的方法优化迭代目标函数,目标函数与梯度计算的判别式分别为
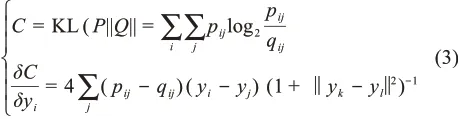
最后,T-SNE使用困惑度(prep)描述样本点的有效近邻点个数,其通过二分搜索的方式寻找最佳方差,计算公式为
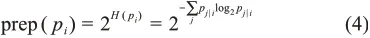
其中,H(pi)是pi的香农熵,用来度量样本数据的不确定性。熵值越大,困惑度越大,领域数据点的数量越多,相互之间的概率也越接近。
综上所述,PCA算法运行高效但特征值分解具有一定局限,降维主元并不一定最优;T-SNE精确性更优,而高复杂度计算会导致训练时间过长。因此,可先行使用PCA对TWM进行线性降维,若降维效果不佳,则进一步采取T-SNE开展非线性降维。
3.3 基于谱聚类的术语类簇划分
在聚类数目的指导下,可对电子政务术语百科文本的TWM进行谱聚类划分术语类簇。谱聚类是一种源于图论思想的聚类算法,将集中的数据点视为无向加权图的顶点,从而让数据点之间的相似关系转化为无向图的加权边,使得数据集的聚类转化为无向加权图的切分问题[27]。谱聚类的核心在于对数据集LM的特征向量进行聚类,以达到更为精准的划分效果,具体步骤如下:
Step1.输 入 数 据 集TWM={v1,v2,…,vm},聚 类 数目为l。
Step2.将数据集图谱化,定义任意两点vi、vj之间的权重wij来表示两点之间的相似度,当数据点间有连接边时,wij>0;否则,wij=0,且无向图的性质使得wij=wji。此外,图形的边权重通过高斯距离获得,计算公式为
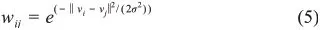
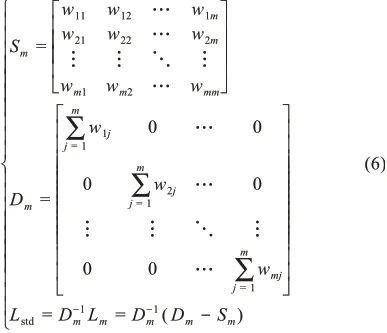
Step3.通过数据集的边权重计算相似度矩阵Sm与对角矩阵Dm,以此构建拉普拉斯矩阵(Lm),并将其进行标准化处理(Lstd):
Step4.计算并获取Lstd前e个最大的特征值与特征向量,将特征向量作为列向量进行集合得到矩阵um×e={u1,u2,…,ue},并对其规范化得到新矩阵Tm×e,规范公式为
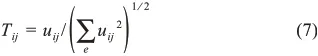
Step5.对Tm×e的 行 向 量 使 用K-means聚类,输出类簇C1,C2,…,Cl,各类簇内的术语为通过聚类所划分的电子政务术语集合。
因此,通过谱聚类可构建电子政务术语TWM的无向加权图,并计算LM开展后续聚类工作,以达到从内容层面划分电子政务术语类簇的目的。
3.4 基于中心度的术语类标确定
在划分了电子政务术语类簇后,紧接着就是提取每个类簇的类目标签。首先,针对谱聚类所切分TWM的 类 簇C1,C2,…,Cl提 取 出 子 矩 阵TWM1,TWM2,…,TWMl。其次,在每个子矩阵内以词语为属性构建术语特征向量,通过余弦算法计算术语特征向量的相似度,获得表示术语间相似度的术语-术语矩 阵(term-term matrix,TTM)TTM1,TTM2,…,TTMl。最后,将TTM输入社会网络工具借助SNA计算各子矩阵内的术语中心度,提取中心度较高的术语作为子矩阵的类目标签,即类簇C1,C2,…,Cl的标签。
3.5 基于FCA的概念层次结构生成
FCA是一种数学语言驱动的本体概念构建方法,概念所有对象的集合被认定为概念的外延,而其中公共属性的集合被称为概念的内涵。从中抽取包括内涵和外延在内的概念层次结构,称为概念格结构模型[28]。因此,采取FCA便能够利用对象(政务文本)与属性(政务术语)之间的二元关系抽取出基于结构的层次关系。
若电子政务术语集合A(属性)、社交媒体文档集合O(对象)以及二者间的关系R共同构建了一个三元组B=(A,O,R),其中,aRo表示在对象o∈O中有属性a∈A,将三元组B进行转化获得电子政务DTM。
那么,在三元组B中,对O、A的幂集定义两个映射f和h如下:
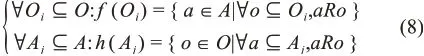
公式(8)反映了对象集合(Oi)中的共同属性以及相同属性(Aj)中的所有对象。此时,若f(Oi)=Aj且h(Aj)=Oi,则认为C=(Oi,Aj)是以Oi为外延、Aj为内涵的概念。
若对 于概念C1=(O1,A1)、C2=(O2,A2)有A1⊆A2,则称C2是C1的子概念,而这种父子关系便形成了层次序以揭示概念间的层次关系。
实质上,概念间的父子关系的判断是推理DTM内以文档为特征的术语向量间的包含关系。因此,采取求与运算实现FCA判断DTM内术语向量间的父子关系,可识别基于结构的电子政务术语层次关系。
3.6 基于语义融合的层次关系优化与评价
在将基于内容与基于结构的层次关系进行融合之后,便可以从扩展与修正两个角度优化电子政务术语语义融合的上下位关系,并提炼出4种典型的融合类别,如表1所示。
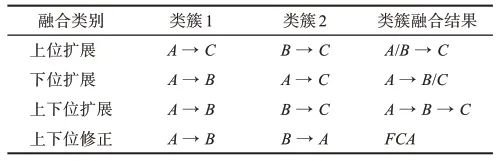
表1 语义融合类别
在表1中,语义融合的类别主要包括:①上位扩展,即不同的上位术语(A、B)指向同一个下位术语(C),以扩展下位词的上位概念;②下位扩展,即代表一个上位术语(A)同时指向不同的下位术语(B、C),以扩展上位词的下位概念;③上下位扩展,即通过同一个术语(B)将其上位术语(A)与下位术语(C)融合,以扩展上下位概念;④上下位修正,即以FCA结果为准,对冲突的上下位关系(A→B、B→A)开展进一步修正。

对电子政务术语层次关系优化之后,紧接着就是对所识别术语层次关系的召回率与准确率进行评价。如前文所述,现有的标准化主题词表中,术语间层次关系尚存不足,不利于对基于语料库所识别的术语层次关系进行评判。因此,本文将诉诸电子政务领域专家对术语层次关系的召回率与准确率进行评价,计算公式为其中,R表示基于术语实体进行抽样评价所获取的召回率;P表示基于术语关系进行抽样评价所获得的准确率。其中,基于术语实体进行抽样评价,是指随机抽取特定数量的电子政务术语。根据术语集内所识别出的上下位关系,领域专家一方面评价得到正确识别的术语层次(TP_entity);另一方面给出术语集内尚未识别出的层次关系(FN_entity),以此计算得出R。同时,由于当抽取的术语集中层次关联的数量较少时会影响准确率的计算精度,故基于术语关系随机抽取特定数量的层次关联(TP_relation+FP_relation),并由领域专家评价得出正确识别的数量(TP_relation),以此计算得到P。
3.7 基于OWL语言的知识存储与展示描述
将基于内容、结构和融合所得的层次关系通过OWL语言进行存储形成电子政务知识结构。OWL存储语法 主要有<owl:Class>和<rdfs:SubClassOf>两种形式[29]。其中,前者用于定义类,后者用于描述类之间的父子关系,包含两种知识存储方法,如图2所示。
由图2可知,第一种方法(图2a)利用语法(10)先行定义父类术语“保卫”,随后通过式(11)在定义子类术语“安全保卫”的同时规定二者间的父子关系;第二种方法(图2b)运用语法(12)在定义子类的同时定义父类,并描述二者间的父子关系。第一种编码语法与第二种编码语法均可表示“保卫”为“安全保卫”的上位类,即采用任意一种均可对识别出的电子政务术语层次关系编码。将所有上下位知识结构存储为OWL文件,并使用Protégé打开,即可对电子政务领域术语的层次关系进行展示。

图2 电子政务术语层次关系编码
4 实验结果
本文以《综合电子政务主题词表》内“政法、监察”类主题词为术语集,采用第3节的逻辑方法,运用Python 3.7、Matlab 2017、Gephi 0.9.2、Protégé5.0等工具,分别从内容和结构的识别术语间的层次关系,将两者结果融合为电子政务本体以开展深入分析。
4.1 基于内容的层次关系识别结果及分析
基于内容层面识别电子政务术语层次关系需要诉诸网络百科语料,其中百度百科凭借其词条收录数量、开放编辑机制、搜索引擎用户基础等方面的优势已经成为全球最大的中文网络百科[30],更利于揭示中文领域的术语知识内涵。因此,按照术语集列表依次检索并爬取了所有术语的百度百科,爬取时间为2019年10月3日,在进行数据清洗后得到与术语匹配的1378个释义文本。接下来,对内容层面层次关系的识别将基于该文档展开。
(1)电子政务TWM构建。由于词表已根据主题内容将“政法、监察”类术语划分为5个二级范畴,故基于此分类标准通过TF-IDF模型分别构建这5类术语集的TWM,一共得到包括“综合用语”(232×1605)、“公安”(384×1949)、“司法”(522×2320)、“监察”(144×629)、“国家安全”(96×426)在内的16114个术语-词语关联权重。
(2)PCA与T-SNE联合辅助聚类数目确定。首先,对TF-IDF算法所生成的电子政务TWM进行PCA降维,将高维矩阵降至2维以展现术语在平面上的分布,从而辅助聚类数目的确定。若PCA线性降维的效果不佳,则进一步采取T-SNE非线性降维。以“司法”类术语为例,结果如图3所示。
由图3可知,“司法”类术语特征的PCA降维结果表明,电子政务术语在二维空间内分布较不均衡,不利于对术语聚类数目的可视化划分;而TSNE降维能够使得术语在文本空间内达到较好的分布效果。通过可视化不难发现,“司法”类术语的聚类数目可设定为5,其余类簇在确定向下细分的类目时均参照此种方法。
(3)基于内容的层次关系生成。在降维所得聚类数目的指导下,对电子政务术语的TWM进行多重谱聚类,获得电子政务术语的层次关系,如表2所示。
由表2可知,在内容视角下,电子政务术语经过多重谱聚类已划分为稳定层次,并在原有词表的基础上向下细分了3~4层。本研究通过余弦算法计算每个类目内术语间的相似度,再借助SNA计算术语中心度,将中心度较高的术语作为类目标签。以“司法”类第2层中的类簇为例,结果如图4所示。
在图4中,SNA结果表明该类簇内中心度前3的术语分别为“行政复议”(196)、“行政司法”(195)及“诉讼代理”(186)。其中,前两者的中心度最为接近,而从术语内涵的角度来看,“行政司法”是指行政机关依照司法程序解决纠纷的所有行政行为,其内涵广度超过了作为行政行为一种的“行政复议”,故择其为该类簇的标签。
本研究分别对表2中的第2、3、4层类目采用SNA的方法确定类目标签,从内容视角识别电子政务术语的层次关系,一共得到了1371对上下位关系。通过图2中的OWL语法对层次关系自动编码,可存储基于内容的电子政务术语层次知识结构,如图5所示。
读取“政法、监察”领域内由基于内容的电子政务术语知识结构所存储的OWL文件,通过Onto‐Graf插件对基于内容的层次关系进行展示,如图6所示。
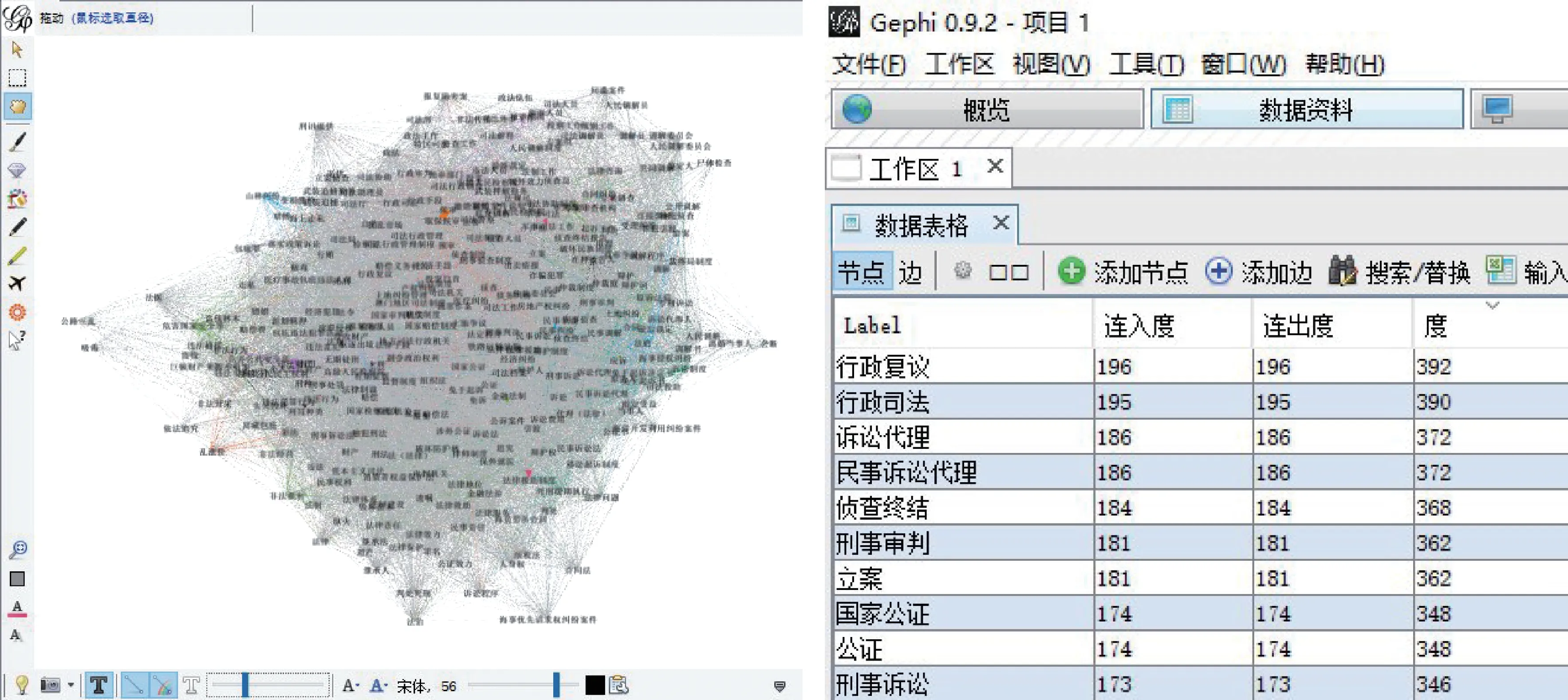
图4 类簇标签确定
图5 基于内容的电子政务术语层次知识结构
images/BZ_73_224_795_1013_1018.png
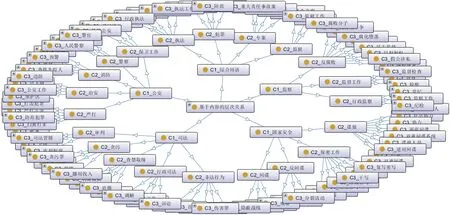
图6 基于内容的电子政务术语层次关系展示(1~3层)
在图6中,从外在特征的角度来看,基于内容的电子政务术语层次具备清晰的知识框架。在“综合用语”“公安”“司法”术语集内,类簇的最大深度可至5层;在“国家安全”“监察”术语集内,最小层次为2层。在知识框架的118个类目内,最大簇为“监察”类的第3层类目“监察工作”,共有44个术语;最小簇为“监察”类第2层类目“行政监察”,共有3个术语。此外,超过一半的知识类目分布于框架的第3层,占整体类目的56.8%,说明采取聚类方法所形成的基于内容的层次关系较为合理。
从内在特征的角度而言,本研究将通过例证的方式从电子政务知识本体横向扩散的差异性与纵向延伸的继承性两个方面分别探索其优劣,如表3所示。

表3 基于内容的术语层次内在特征分析
一方面,表3展现了“公安”类术语内的一簇知识结构。从横向扩散的角度来说,“安全保卫”知识簇在第4层所拆分的类目标签可以代表保卫工作的针对对象(反动组织)、执行主体(队伍)和具体活动(反恐),能够体现出较为明显的差异;从纵向延伸的角度来说,C1_公安→C2_保卫工作→C3_安全保卫→C4_反动组织/反恐/队伍,也能在类簇不断细化的过程中反映出术语内涵的继承。因此,基于内容的层次关系具备一定的有效性。
另一方面,表3中的知识结构也尚存不足。如底层术语“防暴警察”归属于第4层的“反恐”类在内容层面虽无问题但并不全面,这是因为术语“警察”也可以作为其上位类,因此可进一步对电子政务本体进行扩展。又如该类簇将“保卫工作”设定为“安全保卫”的上位类,然而“保卫工作”的定义是指国家安全和公安保卫的组成部分,故将其作为“安全保卫”的下位类更为合适。此外,术语“反革命组织”归属于“反动组织”的范畴会比作为“队伍”的下位类显得更为贴切,所以已有层次关系亦可进一步修正。
4.2 基于结构的层次关系识别结果及分析
基于结构层面识别电子政务术语层次关系需要诉诸社交媒体语料。其中,以政务微博为代表的政务社交媒体历经十年发展,从2009年的几十个账号增长到如今的179930余个,已经成为我国最大的移动政务平台[31]。因此,按照术语集列表顺序自动检索并爬取了所有“政法、监察”类电子政务术语的政务微博文本,爬取时间为2019年10月3日,获取从当日起向前回溯10个页面的微博文档。本研究通过去除缺失值、重复值和整理文档集与术语集对应关系等数据清洗操作,得到与电子政务术语相匹配的政务微博共计21638条,基于结构的层次关系识别将围绕这类文档展开。
(1)术语共现关系生成。相较于基于内容角度使用单个术语的百科文档,基于结构识别层次关系更强调不同术语在文档内的共现情况。若继续按照词表对“政法、监察”类术语二级范畴的划分方式,会致使5个类簇内的术语相互隔离,同时也会遗漏很多上下位关系。较为典型的为“综合用语”类的术语集合包含有与其他4类术语集密切相关的术语,如“案件”“犯罪”“反贪”等术语,在实践场景中均有可能与“公安”“司法”“监察”类术语在政务文本中共同出现。因此,基于结构视角识别层次关系将不再采用词表所提供的二级范畴划分方式,而是将所有术语作为一个整体,通过函数匹配术语集在21638条政务微博文本内的共现结果,共得到32592个关联。
(2)形式化背景与FCA。将电子政务术语在文档中统计,得到共现关联以<文档,术语,权重>三元组的形式进行存储,并将其转化为DTM,形成电子政务领域的形式化背景EFM={D,T,R}。其中,D中 共 有21638个对象;T中 共 有1378种 属 性;R中存在32592个关联。通过编写求与运算程序对EFM实现FCA,如图7所示。
在图7中,由工作区的元胞数组可知,本实验使 用DTM(21638×1378)存 储EFM,通 过 对 象(电子政务文档)所形成的向量空间判断属性(电子政务术语)之间的包含关系,从而实现FCA获取电子政务术语间的上下位关系,并形成了Result对称数组(1378×1378),包括行术语(LT)、列术语(CT)和上下位关系(H),记作:LT为CT的H,例如,“案件”为“案件处理”的上位,如此累计得到1505对上下位关系。通过数据库连接运算删去其中冗余关系,最终获得1232对上下位关系。
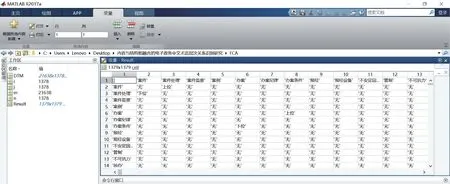
图7 基于结构的上下位关系生成
(3)知识存储与可视化。通过行列转换,将所获得的上下位关系转换到二维,并使用OWL语法进行存储,展示基于结构的电子政务术语层次关系,如图8所示。
在图8中,从外在特征的角度来看,电子政务术语基于结构的层次关系的整体框架尚不完备。在结构层次的392个类目中,仅首层就分裂出247个类目,占总体知识类目的绝大多数(63%),仅存有2簇最大深度虽也可至第5层,这使得纵向延伸的类目较为有限。此外,类目的最大簇为“案件”,共有49个术语;最小簇中含有1个术语,且在首层类目中占据的比例最大(39.3%)。不难发现,整体框架的层次性与完整性均略显不足。
从内在特征的角度而言,基于结构的层次关系的精准性较高。延续对表2中层次关系的说明,结构层次结果显示,“防暴警察”为“警察”的下位类,“安全保卫”为“保卫工作”的上位类,“反革命组织”归置为“恐怖组织”的下位类,根据内容层次所识别“恐怖组织”为“反动组织”的下位类,推理可得“反革命组织”也从属于“反动组织”的范畴,这些均能够对内容层次框架进行有效的扩展与修正。此外,结构层次最大深度的2个类簇分别为C1_审判→C2_一审终审→C3_终审制度→C4_两审终审制度→C5_四级两审终审制度、C1_案件→C2_特别程序→C3_终审制度→C4_两审终审制度→C5_四级两审终审制度,根据“审判”“案件”的知识内涵,类簇在深层次细分过程中同样也能够保持较强的准确性。
4.3 语义融合结果及分析
基于内容的层次关系为电子政务术语本体搭建了初步框架,该框架具备有效的完整性与层次性,但准确性尚可优化。相较之下,基于结构的层次关系则更为精准,但对本体框架的支撑性略显不足。因此,进一步将两者进行语义融合,前者用于框架搭建,后者旨在修正与扩展,以构成一个框架完整、层次深入、精度准确的电子政务术语本体。
语义融合一共得到2603对上下位关系,通过连接运算对合并的上下位关系进行去重,得到2182对上下位关系,形成了“政法、监察”类电子政务术语本体,如图9所示。
在图9中,“政法、监察”类电子政务术语本体具备更为完整、清晰的外在特征,类簇最大深度延伸至11层,语义细分维度大幅加深。在整体框架的638个类目内,最大簇为“监察”类第3层类目的“检察”以及处于“司法”类第5层或处于“监察”类第6层的“监察工作”,均聚合有40个术语,而最小簇含包含1个术语,占总体类目的39.5%。此外,超过一半的知识类目(52.8%)分布于本体的第4、5层,最多的第4层类目占到整体的29.8%,说明了类目在不同层次间的分布更为均衡。
基于表1中所列举的语义融合类别,在电子政务本体中截取囊括所有类别的一个局部进行说明,其内容与结构层面的层次关系如表4所示。
在表4中,内容与结构两者层次关系的语义融合主要有4种代表形式:①上位扩展,即“出入境”“安全员”“保卫工作”多个上位术语指向同一下位术语“民航安全保卫”;②下位扩展,即同一上位术语“治安”指向“出入境”“治安处罚”多个下位术语;③上下位扩展,即通过同一术语“保卫”将其上位术语“打击犯罪”与下位术语“安全保卫”连接为同一个类簇;④上下位修正,以FCA为准对“安全保卫”与“保卫工作”的上下位关系进行修正。根据表4中内容与结构视角下层次关系的语义融合,从电子政务术语本体中抽取出经过扩展与修正后的上下位关系,如图10所示。

表4 电子政务术语层次关系融合(局部)
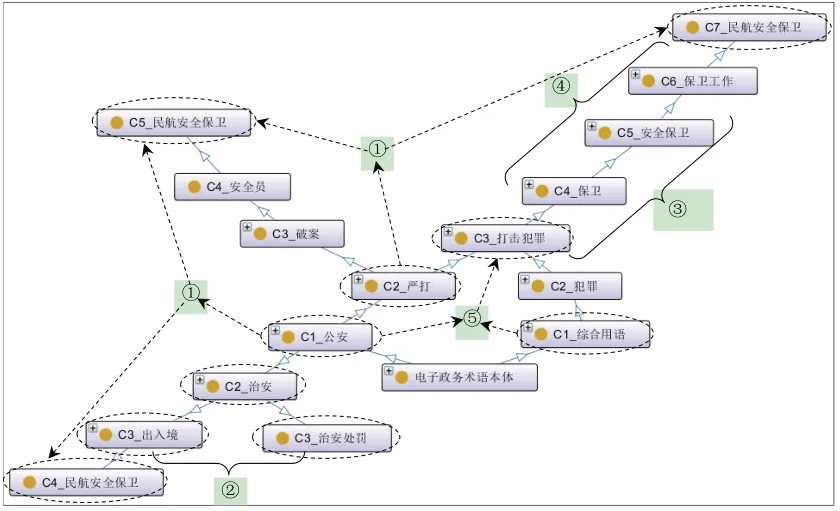
图10 电子政务术语本体扩展与修正(局部)
在图10中,语义融合主要展现了电子政务本体中“公安”类与“综合用语”类术语的扩展与修正情况。由①可知,在“公安”类术语集内,通过扩展上位概念“C3_出入境”“C4_安全员”及“C6_保卫工作”,使得类簇“C2_治安”以及由“C2_严打”所细分的“C3_破案”“C3_打击犯罪”分别指向了同一下位术语“民航安全保卫”,该术语处于“C2_治安”的第4层,“C3_破案”的第5层,“C3_打击犯罪”的第7层;由②可知,在“公安”类术语集内,“C3_出入境”“C3_治安处罚”扩展了其上位术语“C2_治安”的下位概念;由③可知,在“公安”“综合用语”类术语集内,上位术语“C4_保卫”及下位术语“C6_保卫工作”分别扩展了“C5_安全保卫”的上下位概念;由④可知,通过FCA所抽取层次关系的指导,将“C5_安全保卫”修正为“C6_保卫工作”的上位类。此外,在整体局部中可以进一步发现与①同属于上位扩展的编号⑤,其通过扩展上位概念“C2_严打”及“C2_犯罪”致使“C1_公安”与“C1_综合用语”分别指向了同一下位术语“C3_打击犯罪”,使得原本词表中不同二级范畴内的术语得以关联,也验证了以整体术语集进行FCA的必要性与有效性。
综上所述,①~⑤表明语义融合能够切实有效地扩展并修正术语的层次内涵,继而提升电子政务术语本体层次关系的召回率与准确率。
4.4 电子政务术语本体评价分析
在形成了电子政务术语本体之后,接下来就是测度本体中层次关系的召回率与准确率,继而对本体所识别的层次关系进行评价分析。本体中1~3层术语、3~7层术语和7~11层术语的数量分布大致满足1∶3∶1,故可大致分为1~3层的大类术语、3~7层的中层术语和7~11层的深层术语。其中,大类术语代表着电子政务本体的整体知识架构,中层术语在整体框架的基础上广泛扩散知识关联,深层术语则将扩散的知识进一步细化延伸。因此,从这3个层面测度术语层次的召回率和准确率能够有效评价电子政务本体的整体质量。
基于术语的分布规律,本研究采取随机抽样的方式,分别从1~3层、3~7层、7~11层中分别抽取出20、60、20个术语实体以及术语集中所识别的上下位关系,总共抽取5次,取样过程中秉持每层术语的抽取数量相对均衡,如此便得到了用于评价召回率的5组术语实体样本;采取相同的方式从1~3层、3~7层、7~11层 中分别抽 取出20、60、20对层次关系,总共抽取5次,得到用于评价准确率的5组术语关系样本。结合论文发表数量、被引次数、代表性著作以及所在机构遴选出5位电子政务领域专家,并将5组样本分别发予领域专家对术语层次关系进行评价,收回反馈统计评价结果如图11所示。
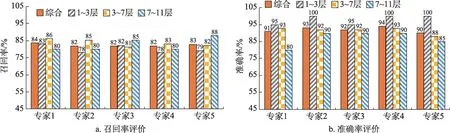
图11 电子政务术语本体抽样评价结果
由图11可知,从整体来看,电子政务本体层次关系的评价结果良好,5位专家评价的综合召回率均在80%以上,综合准确率在90%以上,这表明将内容与结构的层次关系相融合取得了较好的应用效果。从召回率而言,处于1~3层、3~7层、7~11层的术语关联的召回率较为均衡,并未体现出明显差异;从准确率来看,处于1~3层术语层次的准确率最高,3~7层次之,7~11层最低但也均在80%以上,这一方面说明了电子政务本体具备良好的知识扩展性与延伸性,同时,也反映了术语层次关系的准确率会随着层次加深逐级递减。基于此,在电子政务术语本体内各大类中进一步遴选出深层类簇进行准确性分析,如表5所示。
由表5可知,从整体上来说,电子政务术语层次关系的准确性较高。就“综合用语类”与“公安类”而言,两者分别通过“C2_犯罪”与“C2_严打”所细分的下位术语“C3_打击犯罪”在第3层合并为一簇,并自上而下深化至第10层,包含保卫、执法队伍、犯罪案件等子类术语;就“司法类”而言,术语细化主要包含依法行政、诉讼过程、实例案件等方面的内容,能至第11层;就“监察类”而言,术语依据监察工作与监察部门的内涵演化至第8层;就“国家安全类”而言,术语延伸的轨迹围绕间谍工作展开并达至第8层。
基于内容角度的层次关系大幅加深,同时也促使诸如“放火”“放火案”“放火案件”抑或“监察”“监察部”“监察部门”“纪检监察部门”等基于结构角度的层次关系得以关联,这说明采用电子政务语料识别术语层次关系有效弥补了人工词表的不足。
5 结语
本文基于内容与结构视角,首先,通过对网络百科内容所提取出的特征词语采取谱聚类的方式,生成基于内容的层次关系;其次,根据术语集在社交媒体文档中的共现匹配情况,采用FCA建立概念格结构,从而提取基于结构的层次关系,以前者具有高召回率的层次关系为整体框架、后者高准确率的层次关系为修正指导进行语义融合,形成了一整套电子政务领域中文术语本体识别方案。对“政法、监察”类电子政务主题词的实验表明,内容与结构层面的语义融合,则达到了很好的扩展与修正效果,专家评价结果显示电子政务本体中层次关系的整体召回率(≥80%)与准确率(≥90%)均较高,术语在语义内涵的延伸过程中较好地弥补了原有词表在内容与结构层面上的不足,这说明采用大规模语料所形成的电子政务本体具备良好的知识扩展性与延伸性。
表5 电子政务术语本体深部层次准确性分析
本文针对“政法、监察”领域所形成的电子政务术语层次关系识别方法,是一种可以在短时间内面向更多政务领域(“科技教育”“对外事务”“军事国防”)、更大规模术语开展知识组织工作的自动化体系,所构成的电子政务术语本体也将在后续知识管理工作中开启更为智能的应用,本文暂列出3点:①信息检索与推荐。利用电子政务本体的推理功能,一方面,通过关键词扩展助力于用户信息需求表达;另一方面,根据本体内术语的上下位关联实现政务信息的个性化推荐。②跨部门信息共享。基于“公安”“司法”“监察”“国家安全”等领域的关联术语,指导公安部、司法部、监察部、国家安全部等跨部门信息系统之间的政务信息资源共享,以开展不同部门间的政务合作。③政务知识发现。通过电子政务术语关联,探索未被发掘的政务知识资源,继而洞悉并提取出电子政务领域的新兴知识,以期为优化未来国家行政管理的工作效率提供参考。
另外,本研究也存在可完善之处。第一,通过机器识别层次关系通常对语料要求较为严苛,而百度百科与政务微博均源于网络文本,在无人工干涉的条件下会致使语料内容较为粗糙,后续将着重提高语料质量以展开对比实验;第二,文章对术语层次关系的识别来自现有词表,而长期以来,在政务工作中所产生的新主题词并未被词表收录,接下来的研究将试图识别未登录词间的关联以扩充电子政务本体的层次体系。
