融合卷积神经网络和流形学习的肺结节检测
2021-02-25杨怀金夏克文刘方原张江楠
杨怀金,夏克文,刘方原,张江楠
(河北工业大学电子信息工程学院,天津 300401)
癌症由于其高死亡率、高治愈难度、高治疗费用使现代社会成为一个“谈癌色变”的社会[1]。依据美国癌症协会报道,所有癌症中,肺癌是死亡率和发病率最高的癌症之一[2]。若能及早发现,并且及时治疗,患者的五年生存率可以达到90%,早发现、早治疗是提高存活率的关键[3]。
肺癌的早期表现是肺结节,医生通过观察肺部CT中肺结节的特征来判别患者是否患有肺癌。孤立性肺结节(solitary pulmonary nodule,SPN)[4]是肺结节中的一种,约有34%为恶性肿瘤细胞。现主要研究SPN的检测技术,肺结节的检测关键环节包括候选结节的检测、特征提取和筛选分类。
为提高放射科医生的工作效率,研究者提出将计算机技术应用到医学诊断中,作为第二意见,辅助医生做出判断[5]。随着数据量的增长,传统的算法已经无法适应,卷积神经网络(convolutional neural networks,CNN)[6]可以自主地从数据中提取特征,不需要人为调整参数,在图像识别中应用广泛。U-net模型是由Olaf Ronneberger等[7]针对医学图像分割提出来的一种“端到端,像素到像素”语义分割网络,总结了全卷积网络的特征和优点,具有多尺度的特征融合、适合医学图像分割等特点。
局部线性嵌入算法(locally linear embedding,LLE)作为一种经典的流形学习算法,易于理解、方便实现、全局最优无须迭代。为了克服原始的权值只考虑距离因素而忽视结构因素的缺点,文献[8]采用测地线(Geodesic)距离来描述结构,引出一种新的权值构造方法,提出改进重构权值的局部线性嵌入算法(IRWLLE),在人工和人脸数据的实验中证明算法具有良好的降维效果和识别率。
XGBoost0由很多分类回归树(CART)集成,本质上还是一个迭代决策树(gradient boosting decision tree,GBDT),但是通过泰勒级数展开目标函数,使得模型以分布式计算,在速度和效率上得到了质的飞跃。
结合以上论述,针对U-net网络不足进行改进,用于候选肺结节特征分割,用IRWLLE进行肺结节的特征提取,XGBoost进行假阳性肺结节的筛选工作,构建一整套肺结节检测系统。
1 算法论述
1.1 U-net基本模型
由于U-net的网络结构像“U”形,所以称为U-net网络,主要分为两个部分,如图1所示。
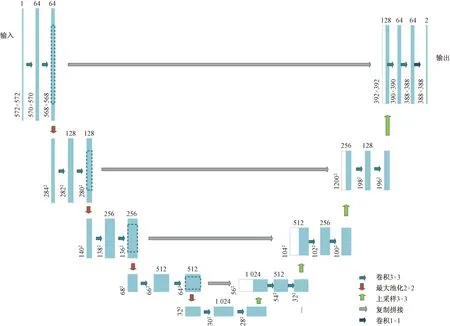
图1 U-net网络结构图Fig.1 U-net network structure
第一部分,特征提取部分,图 1左侧部分以类似VGG-16的网络为模板,通过连续的卷积层和池化层进行高阶语义特征的提取。以两个卷积层加一个池化层为一组,U-net第一部分共包含了4组,以第一组为例,网络的输入图像尺寸是572×572,连着两次使用64个3×3的卷积核进行卷积操作,其中使用ReLU函数作为激活函数、每经过一次卷积层操作特征图尺寸降低2个像素。接着使用卷积核尺寸为2×2的最大值池化层来进行特征降维,每经过一个池化层,特征图尺寸降低50%。通过连续4组的卷积和池化操作之后,在网络的中部通过一个包含512个28×28的卷积层,最终得到了一个尺寸为28×28×512的特征图张量。
第二部分,上采样部分,这一部分的核心思想是将高阶的语义特征通过上采样层进行放大,并将上采样结果与第一部分的高阶语义特征相拼接。先对第一部分得到的28×28×512的特征图做一次上采样操作,使得特征图的尺寸扩大一倍变为56×56×512,接着将第一部分中与之对应的特征图与上采样结果进行拼接,得到56×56×1 024。接着再连续通过两次核尺寸为3×3的卷积层,得到融合前端语义特征的特征图。以一个上采样层加两个卷积层为一组,第二部分同样含有四组。在网络的最后一层是一个卷积核尺寸为1×1的卷积层,其主要目的是为了将各个通道的特征图信息叠加起来,并生成类别掩码。
1.2 全卷积肺结节分割网络
虽然U-net具有多尺度的特征融合、适合医学图像分割等特点,但未使用有效的抗过拟合措施,使用的ReLU激活函数也无法解决梯度“死区”现象。因此,从降低过拟合、提升泛化能力、加速模型训练的角度,以U-net网络为基础,重新构造网络,提出一种全卷积肺结节分割网络(fully convolutional lung nodule segmentation networks,FCLNSN)。
1.2.1 整体网络结构
整个网络的结构如图2所示,层名“输入”代表网络的入口,输入是一张512×512大小的肺实质图片,层名“输出”代表网络的输出,是一张512×512大小的肺结节分割掩码,其轮廓表示肺结节所在范围。箭头表示的是卷积、池化等操作。
整个网络包括34个层结构,如表1所示。其中核参数为2×2的卷积层17个,1×1的1个,最大池化层4个,上采样层4个,合并层4个,随机失活层4个。下面详细介绍各个层结构以及参数的选择。
1.2.2 激活函数设计
激活函数是卷积神经网络中至关重要的一部分,因为有了激活函数,网络才有了非线性能力。常见的激活函数包括Sigmoid函数、tanh函数、修正线性单元(ReLU)函数等。Nair和Hinton于2010首次提出ReLU这种极为简单但是异常有效的激活函数。
目前,ReLU函数是使用最广的激活函数,但这并不能掩饰其不足之处。对于ReLU的导数而言,若误差x<0时,梯度便为0,换句话说,对于小于0的这部分卷积结果响应,它们一旦变为负值将再无法影响网络训练——这种现象称为“死区”。为了缓解“死区”现象,研究者将ReLU函数中x<0的部分调整为αx,其中α为0.01或0.001数量级的较小正数。提出新型的激活函数被称作Leaky ReLU函数0,其导出公式为
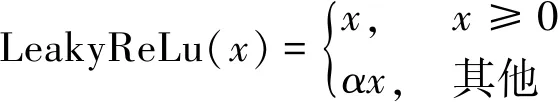
(1)
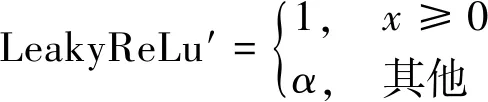
(2)
原始ReLU函数实际上是Leaky ReLU函数的一个特例,即α=1,不过由于Leaky ReLU中α为超参数,合适的值较难设定且较为敏感,因此Leaky ReLU函数在实际使用中的性能并不十分稳定。
参数化ReLU(PReLU)[11]的提出很好地解决了Leaky ReLU中超参数α不易设定的问题,其图像同Leaky ReLU相同。PReLU直接将α也作为一个网络中可学习的变量融入模型的整体训练过程,是一种自适应的求解方式,根据任务的需要集合数据集特征,让网络自动找到最优的参数,从而解决Leaky ReLU超参人为设定不合理的问题。
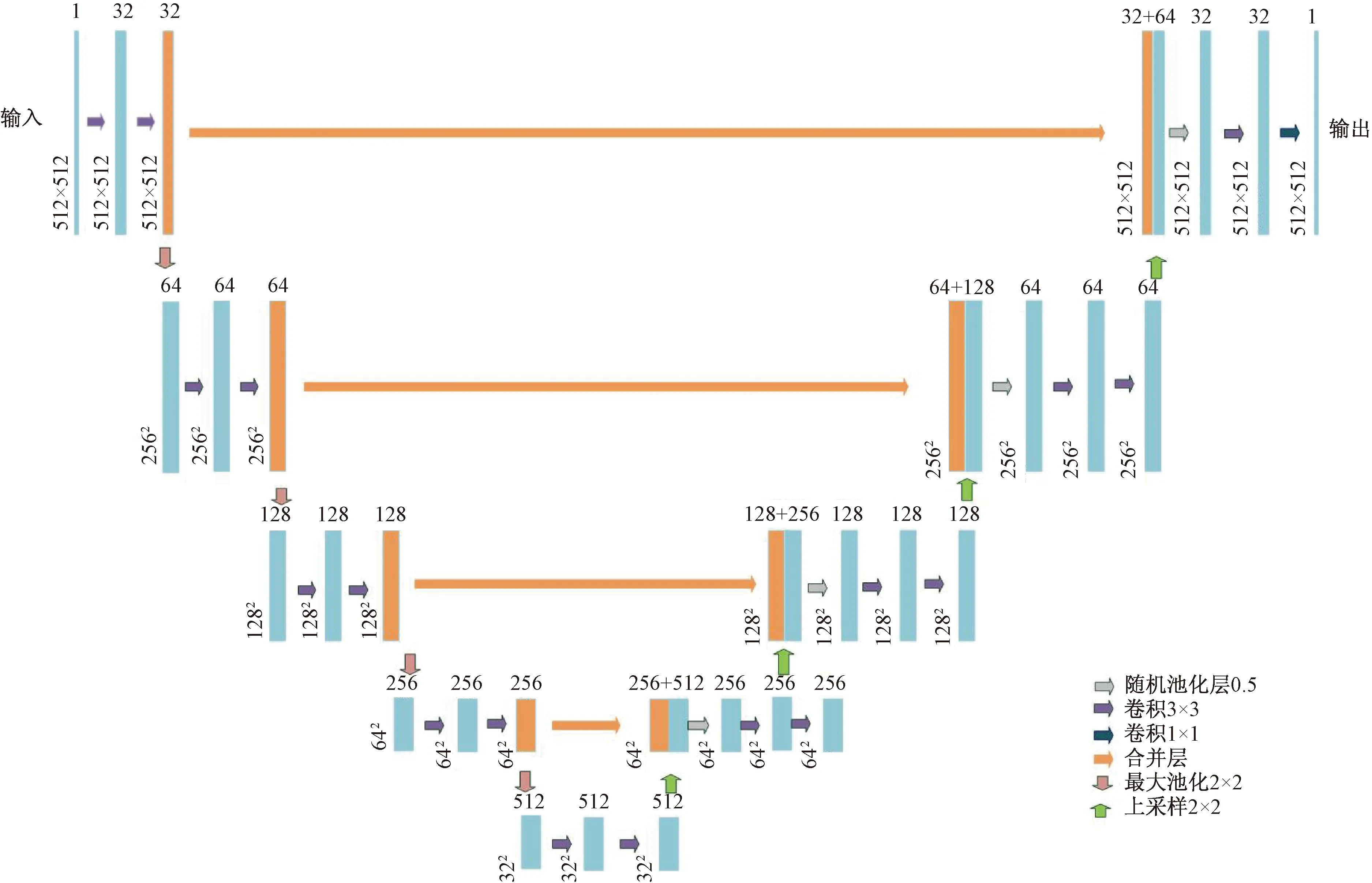
图2 FCLNSN结构示意图Fig.2 Schematic diagram of FCLNSN structure
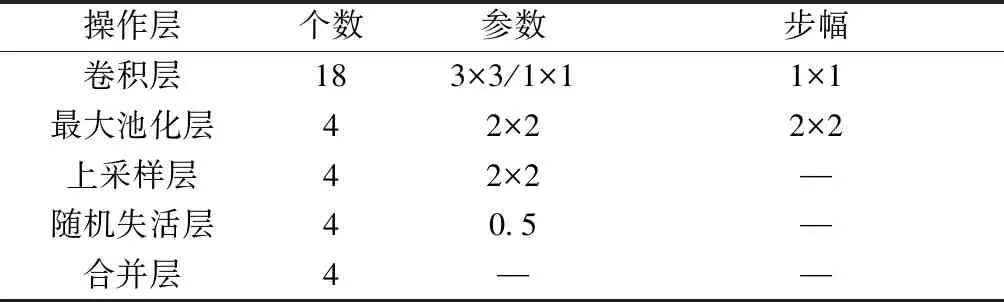
表1 FCLNSN结构参数表Table 1 FCLNSN structure parameter table
1.2.3 损失函数设计
目标函数决定了卷积神经网络的训练学习方向,通过构造合适的目标函数可以将预测输出值与样本标签相比较,求得他们之间的损失。通过反向传播算法,将误差向前传播,从而使整个网络得到训练,参数得到更新。常见的损失函数有交叉熵损失、坡道损失、中心损失、L1和L2损失。鉴于分割任务的特点,构造损失函数为
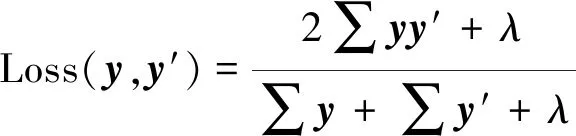
(3)
式(3)中:y为样本的真实标签矩阵,按照列或者行的顺序拼接成的一维向量;y′ 为网络最后一层的输出矩阵展成的一维向量;λ为常量,将其设置为λ=1以防止Loss为0,发生无法训练的状况。
1.2.4 随机失活层
随机失活层又称Dropout层,在卷积神经网络领域,“过拟合”现象是非常常见的,这也符合U-net的使用情况。为了解决过拟合问题,一般会采用模型集成的方法。训练和测试模型将会是一个极为费时的大问题,总结来说有泛化能力差、时间消耗大两大缺点。在2012年,Hinton[12]提出Dropout技术。同年,Alex、Hinton在其论文中提到的AlexNet中首次用到了Dropout技术,用于防止过拟合,由于其出色的泛化能力一举夺得了当年的图像识别的冠军。
为了充分抑制模型的过拟合,在FCLNSN网络中采用随机失活层。Dropout在前向传播的时候,在每个训练批次中,以一定概率暂时忽略卷积核,也就是使其输出为0,可以明显地减少过拟合现象。这种方式可以减少特征检测器(隐层节点)间的“相互作用”,所谓检测器相互作用是指某卷积节点依赖其他卷积节点才能发挥作用,这样可以使模型泛化性更强。具体操作中,在训练网络阶段,由于要控制神经元的休眠与否,所以每个神经元都要添加一个概率控制阀,如图3所示。
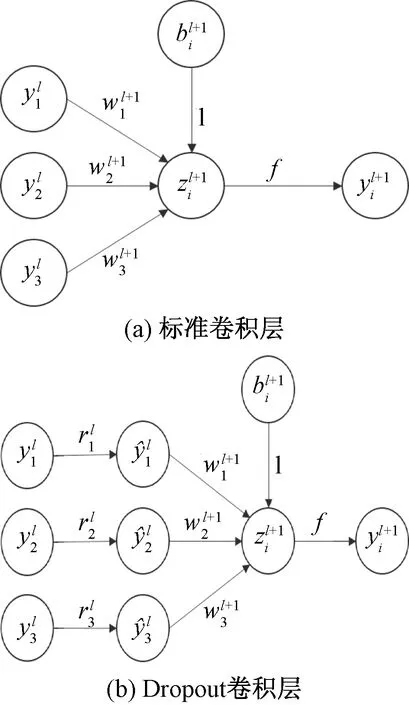
图3 数值化计算模型Fig.3 Numerical calculation model
原始的神经网络的计算公式为
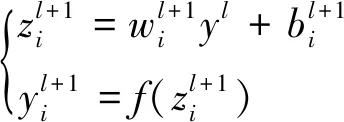
(4)
式(4)中:l为层数;i为神经元序号;wi为神经元参数;b为偏置项;f为激活函数;y为神经元输出。加入Dropout技术的神经网络的计算公式为
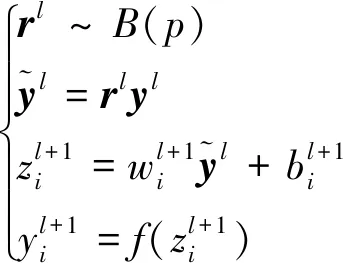
(5)
式(5)中:rl为一个由0,1组成的向量,服从随机概率分布B(·);P为屏蔽概率。在本网络中,将P设置为0.5。
1.2.5 参数初始化方案及优化器设计
网络参数更新以及模型的训练是依赖梯度下降算法驱动的,模型训练学习的好坏不仅与数据相关,很大程度上取决于参数初始化的好坏。2015年He等[14]对“Xavier参数初始化”算法进行了优化,排除了参数初始化过程非线性激活函数造成的干扰因素,故参数初始化方案选择He参数初始化方案。在优化器设计方面,使用更优越的Nadam优化器进行网络模型的更新,Nadam具有更强的约束条件,对梯度的更新也更为迅速、直接。
1.3 改进重构权值的局部线性嵌入算法

(6)
式(6)中:DE(xi、xij)、DG(xi,xij)分别为样本xi与其邻域内样本点xij间的欧式距离和测地距离;dm为邻域内所有测地距离的中值。
2 系统模块设计及应用
2.1 预处理模块
这一步骤主要包括原始数据文件到图像数据的转化,同时进行一定的图像去噪和对比度增强操作,如图4所示。针对肺部CT图像中存在的随机噪声通常采用中值滤波法进行去噪,同时直方图均衡化方法可以很好地增强图像的对比度,有助于突出肺部组织的特征。图5是经过预处理模块后得到的肺部CT的灰度图像,深色区域是肺实质组织。
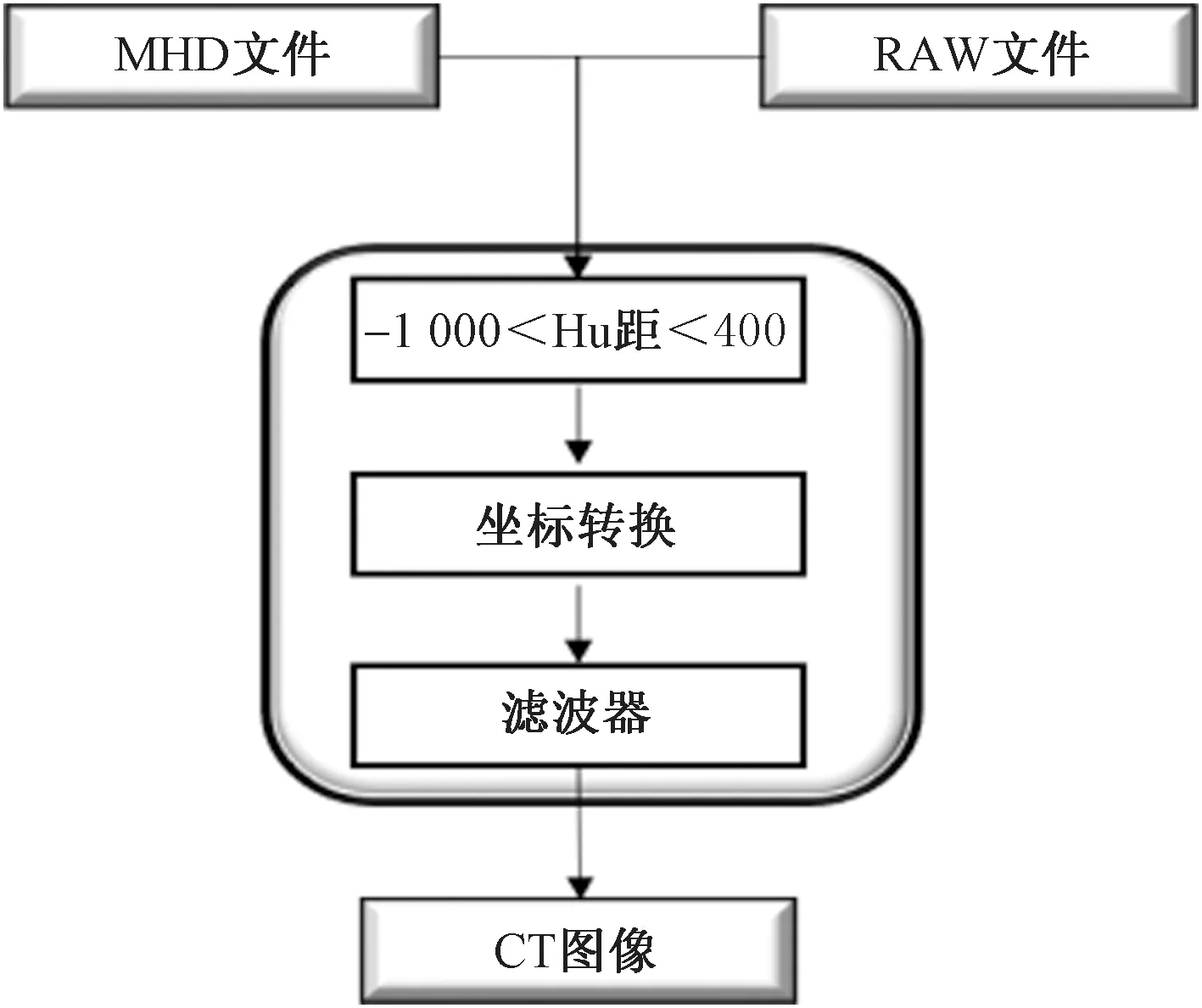
图4 预处理模块Fig.4 Preprocessing Module
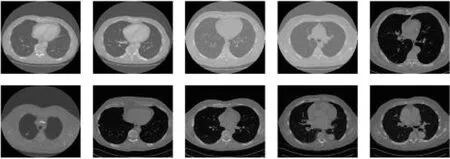
图5 肺部CT灰度图像Fig.5 CT grayscale image of the lungs
2.2 肺实质分割模块
肺实质分割是肺结节检测中至关重要的一步,可以减小肺结节的检测范围,从而直接提高结节检测的准确率。图6是肺实质分割模块的主要流程。
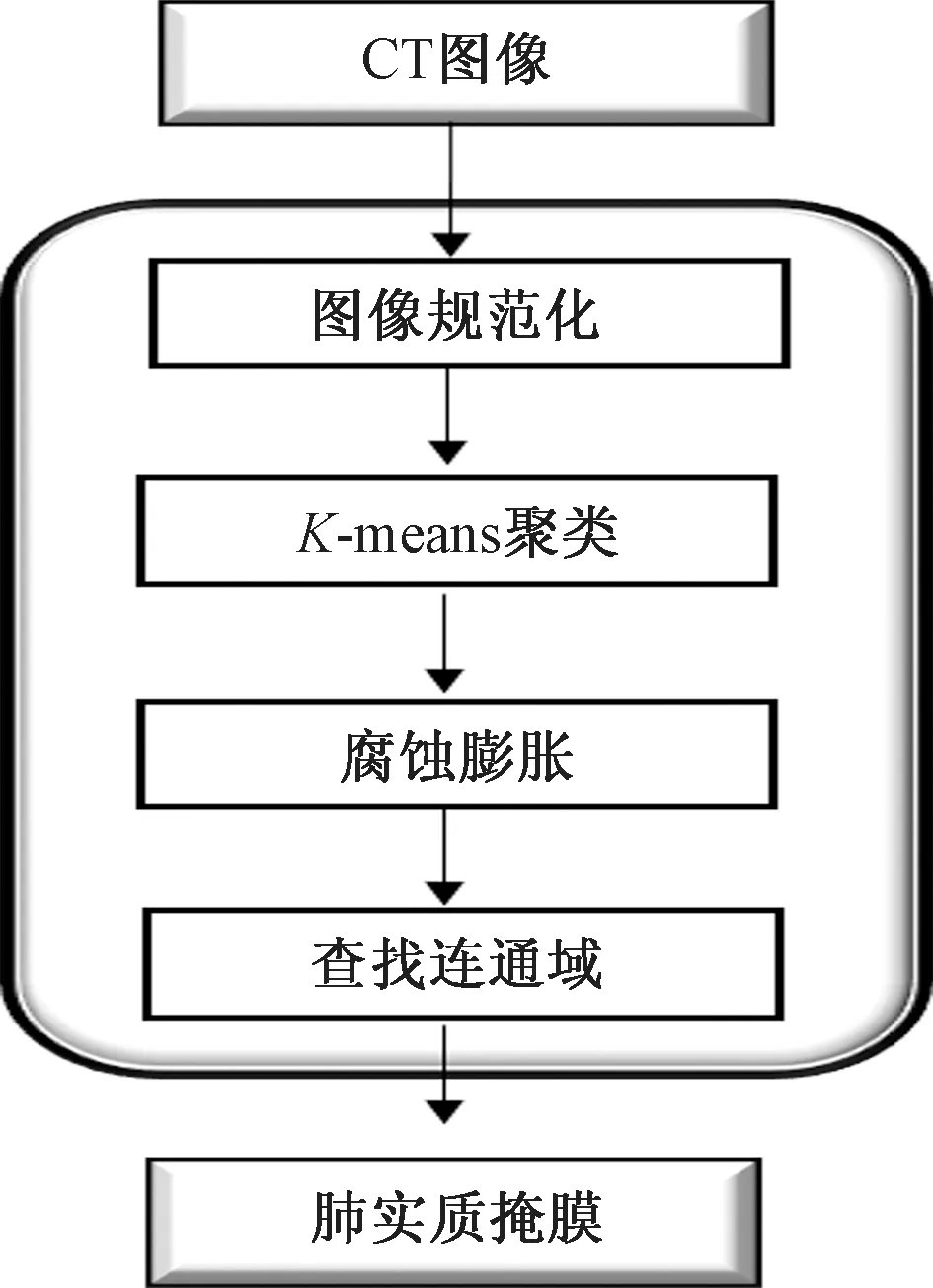
图6 肺实质分割模块Fig.6 lung parenchymal segmentation module
由于肺部区域的灰度值与其周围组织及背景之间的灰度值相差较大,利用这一个特点,采用K-means聚类算法对肺部图像进行初始分割;接着使用腐蚀、膨胀的形态学操作去除背景及气管、血管等干扰组织,修复模板边缘缺口;查找连通域得到完整的肺实质掩膜,如图7所示。最后,将完整的肺实质模板与预处理后的原始图像作乘法操作,得到完整的肺实质,如图8所示。

图7 肺实质掩膜图像图Fig.7 Image of the lung parenchyma
图8 肺实质图像Fig.8 Image of lung parenchyma

图9 候选结节分割模块图 Fig.9 Candidate nodule segmentation module figure
2.3 候选结节分割模块
候选肺结节分割模块是整个检测技术的关键模块,如图9所示。使用FCLNSN模型进行肺结节分割,对比传统的肺结节检测算法具有无须人为构造特征、分割更精确的特点。
对于FCLNSN模型,首先对数据集进行预处理,根据前几个模块生成训练所需的肺实质图像以及标签(ground truth,GT),GT记载了图像的类别和肺结节的位置信息。接着通过对训练数据集若干轮的遍历,训练求解模型的最优参数。FCLNSN的训练流程如表2所示。

表2 FCLNSN模型训练流程表Table 2 FCLNSN model training process table
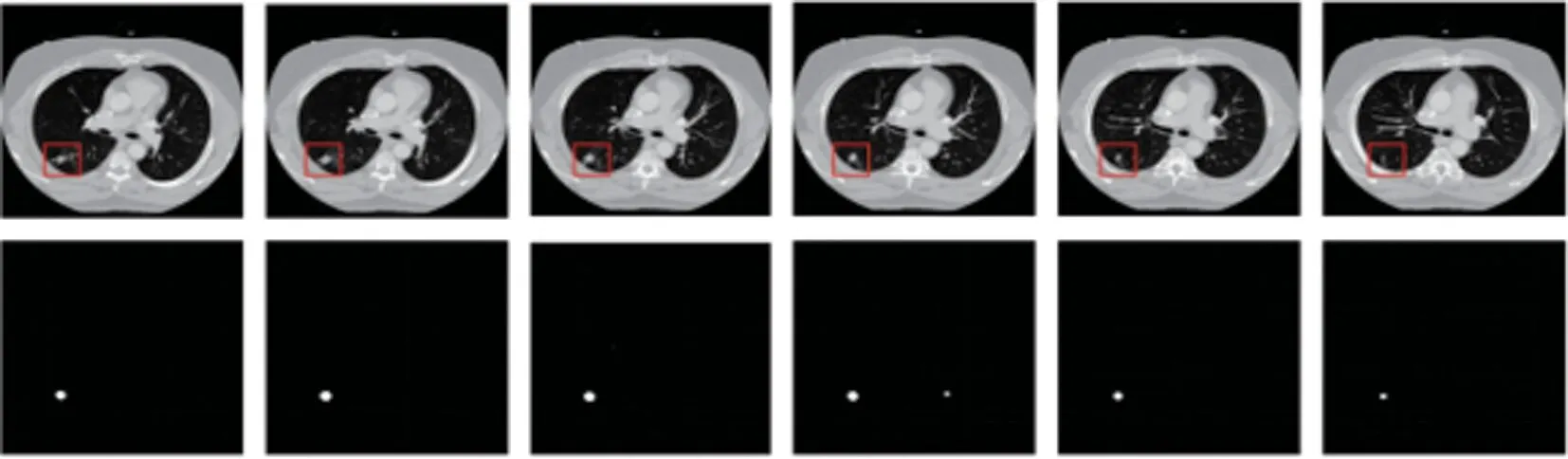
图10 分割结果Fig.10 Segmentation results
2.4 候选结节筛选模块
由于肺部CT图像的复杂性和异质性,在肺结节提取阶段不可避免地会产生大量的假阳性结节,为此需要进一步识别出真结节,去除假阳性结节。对于卷积神经网络检测出来的候选结节,包含了大量的假阳性肺结节,如图11所示,需要进行假阳性筛选,需要用到候选肺结节筛选模块,如图12所示。首先对图像进行必需的预处理,然后对于单个的样本根据欧式距离计算选取最近邻的k个样本,从而得到其局部邻域。使用局部近邻点对中心进行线性重构,计算当前样本点与各个近邻点的欧式距离和测地距离,以此来计算结构权值和距离权值,最终使用奇异值分解,求得数据集矩阵的特征值,从而得到数据集的低维嵌入。

图11 真假阳性肺结节Fig.11 True and false positive lung nodules
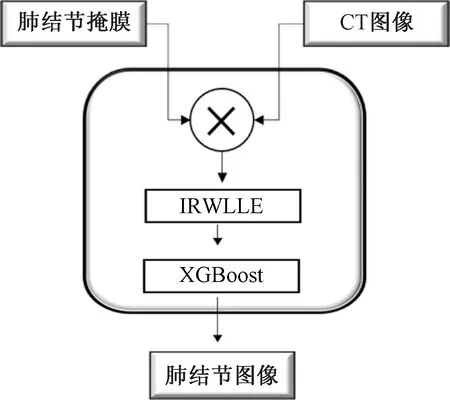
图12 候选结节筛选模块Fig.12 Candidate Nodule Screening Module
用IRWLLE算法得到的降维特征作为分类特征,用XGBoost作为分类器进行分类,其具有速度快,精度高的特点。
那么它们可相应地施行酉算子I(3)⊗ ⊗⊗I(4)和 ⊗I(4)之一,就能以的概率成功交换他们的量子态。
3 实验测试与分析
方向梯度直方图(histogram of oriented grandient,HOG)在结合支持向量机的行人检测任务上的表现令人印象深刻,在各种图像识别任务中均能见到其身影。为了验证系统的有效性和优越性,选取U-net和FCLNSN作为分割的对比模型,选择IRWLLE、LLE、HLLE、HOG算法作为特征提取的对比算法。
3.1 数据集描述
采用国际公用的数据集LUNA16(Lung Nodule Analysis 16),其源于更大的数据集LIDC-IDRI,是LUNA16赛事主办方专门推出的比赛用数据集,旨在评估各种计算机辅助系统的性能。
3.2 评估指标
对于预测类别,TP(true positive)为检测出的真阳性结节,TN(true negative)为检测出的真阴性结节,FP(false positive)为检测出的假阳性结节,FN(false negative)为检测出的假阴性肺结节。
在肺结节分割任务中,由于在训练集中只存在阳性肺结节,不存在阴性结节,所以只使用召回率作为衡量指标。召回率(recall,R)又称查全率,其定义为所检测出的真阳性肺结节在所有真阳性肺结节中所占的比例,其计算公式为
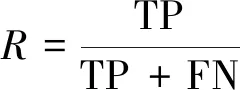
(7)
精确率(precision,P),又称为查准率。其定义为被网络预测为阳性的肺结节中,真阳性肺结节所占的比例,其计算公式为式(8)。精确率衡量了算法为了检出尽可能多的阳性肺结节,所付出的错检代价,查准率越大越好。
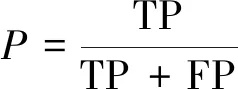
(8)
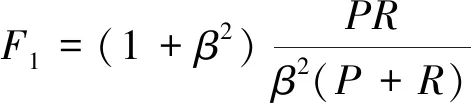
(9)
式(9)中:P、R分别为查准率和查全率;β为衡量查全率的系数。当β=1时,认为P、R同等重要;当β<1时,认为P更重要;当β>1时,认为R更重要。
3.3 肺结节分割实验
原始含有肺结节的CT图像共1 186张,由于数据量有限,为了增强模型的泛化能力,进行数据增强。每个结节选取前中后三张相邻的CT图像得到3 558张原始肺CT图像。除此之外每张图片还可以进行翻折、旋转、缩放、裁剪、加噪等处理,同时对肺结节的掩膜图像做相同的变换。经过数据增强之后,整个数据集共计35 580张图片。
为了评估模型的泛化性能,尽可能多的利用数据集的有效信息,并在一定程度上减小过拟合,使用K折交叉验证。将数据集均分为5份,4份用于训练,1份用于测试。训练平台为Windows 10,Intel i5-8400,Nvidia GTX1060 6G,模型框架选择Keras,设置训练轮数为500次,以rk≤0.5为真阳性标准。图13和图14分别为U-net与FCLNSN的训练日志图像。
观察图13(c)、图13(d)、图14(c)、图14(d)可以发现,在训练达到400轮时,无论是测试集上的查全率还是损失,都开始趋于平稳。
表3是U-net与FCLNSN的对比数据,可以发现在数据集完全相同的情况下,两者在训练数据集上的查全率相差了0.3%,而在测试集的查全率两者相差了2.7%。而在训练损失上,无论是训练集还是测试集,FCLNSN均好于U-net,拥有更小的预测误差。以上两点充分说明了FCLNSN较U-net具有更好的泛化能力,对于新样本能够更准确地预测,具有更强的抗过拟合能力。

表3 网络模型查全率与最小损失表Table 3 Relationship between test results and data labels
3.4 肺结节检测实验
候选结节分类是一种更强调空间结构的分类任务,为了检验IRWLLE相对LLE算法的优越性,选取已标注好的肺结节图像进行特征降维,共1 186张。同时,由于LUNA16没有负样本,为了数据集的均衡,对肺实质内进行随机采样,以此来作为假阳性结节,负样本数为1 200张。将所有的肺结节图片大小重置为100×100,使用KNN最近邻算法进行分类。
改变参数k和d来寻找每种降维算法所能达到的最大识别率。
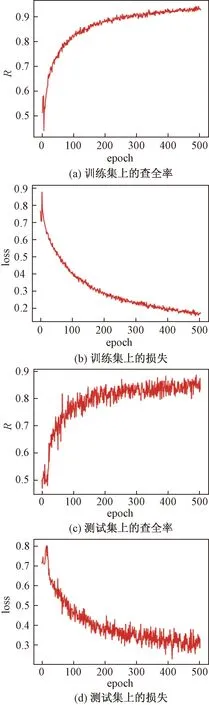
图13 U-net训练日志Fig.13 U-net training log
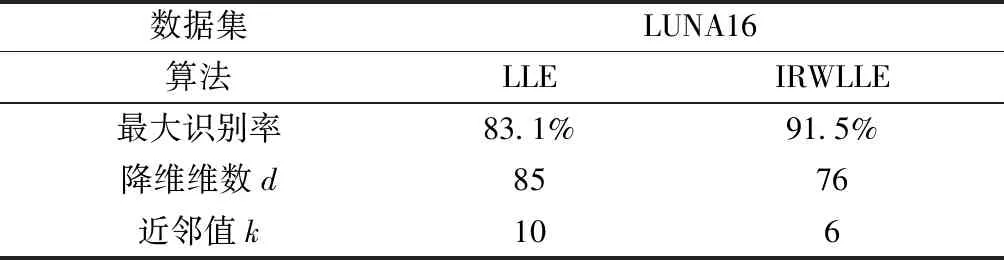
表4 肺结节识别率Table 4 Pulmonary nodule recognition rate
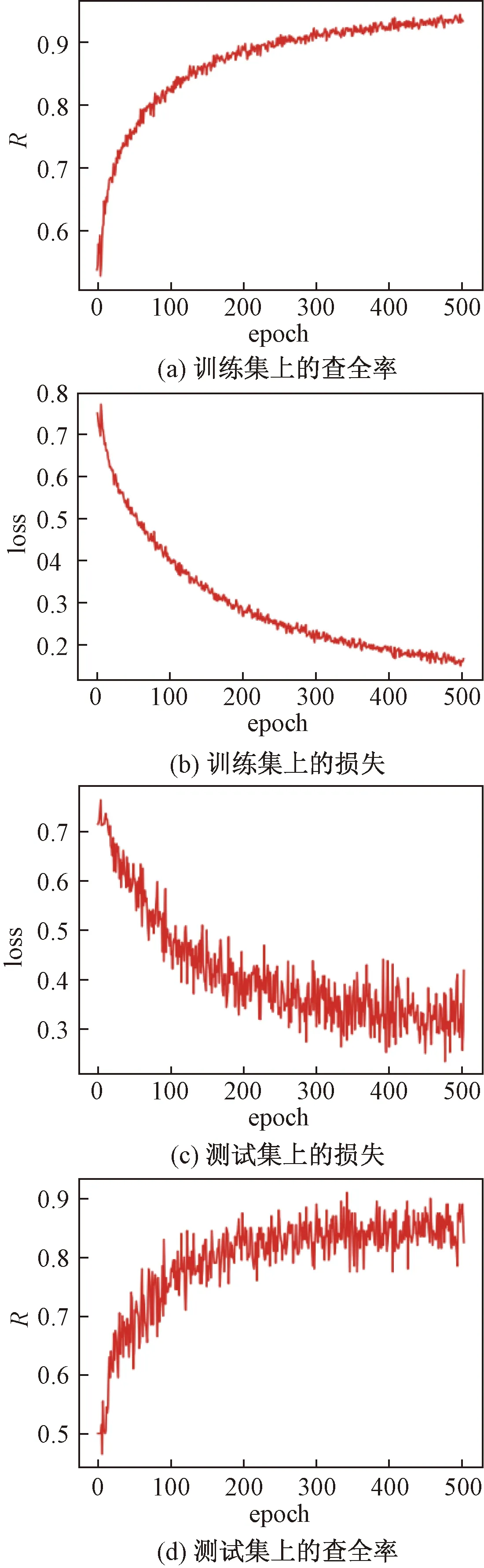
图14 FCLNSN训练日志Fig.14 FCLNSN training log
表4展示了LLE和IRWLLE算法在LUNA数据集上的降维和识别效果的比较。对比结果发现,IRWLLE算法无论是在识别率、降维的维数以及所需的近邻数上均由于LLE,证明了IRWLLE算法的优越性,也证明了在处理肺结节数据上的有效性。
3.5 整体效果分析
系统在使用FCLNSN网络模型进行分割的情况下,使用IRWLEE算法进行特征提取,最后使用XGBoost进行分类筛选,根据降维维度d、置信度阈值λ的不同进行多组统计,结果如表5所示。观察发现在降维到200维度时,系统可以保持较高的筛选准确率,能够有效地去除假阳性肺结节,提升系统的查准率。
表6是采用U-net和FCLNSN进行横向对比,同时将IRWLLE算法与多种特征提取算法进行横向对比的结果。令β系数为1,得到F1分数。对比可以发现,IRWLLE算法进行特征提取可以获得更好的识别准确率,同时由于FCLNSN较U-net有更好的泛化预测能力,所以结合FCLNSN网络的算法有更高的查准率。

表5 IRWLLE+XGBoost识别准确率Table 5 IRWLLE+XGBoost recognition accuracy

表6 各算法组合在测试集上的表现Table 6 Performance of each algorithmcombination on the test set
4 结论
介绍一种融合流形学习的卷积神经网络,将图像的空间流形信息作为一个附加特征,融入到改进的卷积神经网络模型当中,从而提升模型对数据的针对性,提升准确度,弥补泛化能力不足。首先使用全卷神经网络进行候选肺结节的分割,然后改进的流行算法对特征进行提取,最后使用XGBoost进行筛分类。通过实验对比,证实模型有效提升了肺结节的检测率和准确率,具有很大的研究和实践意义。
