基于DNN-FM模型的网络入侵检测研究
2021-02-25张全龙王怀彬
张全龙,王怀彬
(天津理工大学 计算机科学与工程学院,天津300384)
入侵检测技术是计算机网络安全的重要组成部分.入侵检测的概念是James Nderson于1980首次提出[1].当前流行的入侵检测方法是通过使用不同的机器学习来降低错误率技术.入侵检测系统(intrusion detection system,IDS)[2]是提供本地网络服务以确保网络系统安全的独立系统.目前,有很多入侵检测方法,并且许多预测是通过机器学习算法完成的[3,8].使用传统的机器学习算法AdaBoost来研究,能保持较好的检测率[4].使用朴素贝叶斯多项式分类器,此方法介绍了针对正常流量和攻击感染流量的实时计算机网络数据捕获的技术[5].使用AdaBoost增强朴素贝叶斯来提高弱分类算法准确度[8].中使用混合数据挖掘方法k-means和(k-nearest neighbor,KNN)以减少时间系统的复杂度[7].使用了一种基于改进的kmeans和(support vector data description,SVDD)的异常检测算法,通过计算SVDD构成的最小超球的距离,如果测试样品小于在超球面的中心,则测试样本属于此类[6].提出了一种基于改进的K-means和多级(support vector machines,SVM)的网络入侵检测算法.该算法使用改进的K-means将要检测的数据划分为不同的聚类,并标记为正常或异常.然后使用多级SVM对异常集群进行标记,进行详细分类,最终实现对网络攻击的检测.
所有这些方法,朴素贝叶斯[4],AdaBoost[5],SVM[6],KNN[8]等是传统的机器学习方法,主要是基于规则的方法.而这些方法不能够对低阶特征和高阶特征交互学习,本文使用的DNN-FM模型由于可以对低阶特征和高阶特征交互学习,所以可以提取更多的抽象入侵特征,有较高的准确率和检测率,且误报率较低.
本文的贡献总结如下:
1)提出DNN-FM模型,它集成了因子分解机(FM)和深度神经网络(DNN),分别负责低阶特征的提取和高阶特征的提取,能够对低阶和高阶特征交互进行学习.
2)模型有很高的准确率.
3)在基准数据集KDD99上进行多类分类实验,这表明对现有网络入侵检测模型的探索具有一致性.
1 相关模型
1.1 因子分解机(FM)
FM是一个因子分解机,用来对特征交互学习来进行预测[9].传统的方法仅当特征i和特征j都出现在同一数据记录中时,才能训练特征i和j的交互作用的参数.而在FM中,通过它们的潜矢量Vi和Vj的内积来测量,只要i(或j)出现在数据记录中,FM就可以训练潜矢量Vi(Vj).因此,FM可以更好地学习从未或很少出现在训练数据中的特征交互.FM的输出是一个加法单元和多个内部结构单元的总和

其中w∈Rm和w∈Rk(k已经给出),加法单元〈w,x〉反映出了1阶特征的影响,多个内部结构单元的求和反应的是2阶特征交互的影响.
1.2 深度神经网络(DNN)
DNN是深度学习网络的基本结构,具有至少一个隐藏层[10].可以理解为有很多隐藏层的神经网络,又被称为深度前馈网络(deep feedforward network,DFN).按不同层的位置划分,DNN内部的神经网络层可以分为:输入层,隐藏层和输出层,一般第一层是输入层,最后一层是输出层,而中间的层数都是隐藏层.层与层之间是全连接的,即第i层的任意一个神经元一定与第i+1层的任意一个神经元相连.DNN可以为复杂的非线性系统提供建模,并且可以用于学习高阶特征交互.DNN模型的基本公式

2 DNN-FM模型的构建
构建的DNN-FM模型如图1所示,DNN-FM由两个部分组成,FM部分和DNN部分,它们共享相同的输入.对于特征i,标量wi用于权衡其1阶重要性,潜矢量Vi用于测量其与其他特征相互作用的影响.将Vi反馈到FM部分来进行2阶特征交互,并馈入DNN部分来对高阶特征交互.所有参数,包括w,Vi和下文中的网络参数W(n),b(n)来联合进行训练预测模型

其中,y∈(0,1)是最终的检测率;yFM是FM部分的输出;而yDNN是DNN部分的输出.
FM中的潜在特征向量(V)现在用作网络权重,这些权重已被学习并用于将输入场向量压缩为嵌入向量.除了使用DNN模型之外,将FM模型作为整体学习体系结构的一部分.将嵌入层的输出表示为

其中em是第m个字段的嵌入,而m是字段数.然后,将f(0)反馈至深度神经网络(DNN),正向过程为

其中,n是层深度;σ是激活函数.f(n),W(n),b(n)分别是第n层的输出,权重和偏差.此后,生成了一个密集的实值特征向量,最终将其输入到用于网络入侵检测的softmax函数中:yDNN=W|N|+1a|N|+1+b|N|+1,其中|N|值是多层隐藏层的层数,FM部分和DNN部分共享相同的特征嵌入.
一是社会突发事件。社会突发事件往往最容易形成网络舆情,在信息化时代,任何社会突发事件有可能引起网友激烈的讨论。由于网络社群的观点不一,极易发生言论冲突,如果不及时处理,会引发群众过激反应,给社会稳定带来威胁。

图1 DNN-FM模型结构图Fig.1 DNN-FM model structure
3 实验部分
本文使用KDD99数据集,实验使用tensorflow 2.0版本在windows10系统环境下进行.
3.1 数据集
本文将KDD99数据集用作训练和测试数据集.有关KDD99数据集的详细信息,请参见[11].数据集中有 四 种 类 型 的 入 侵:Probe,Dos,U2R和R2L.在KDD99数据集中,仅选择了总数据集的10%,其中包含494 021个连接记录.其中约90%被随机选择为训练集,其余10%被用作测试集.测试集不仅包含训练集中已发生的攻击类型,而且还包含从未发生过的攻击类型.
3.2 数据预处理
数据集中存在四种类型的入侵,输入入侵的一条记录是具有41个元素的特征向量.每一条记录中有42个属性,41个要素和一个入侵类型.使用的数据集已经删除了重复的数据,所以不用再做删除工作.
1设置标签
将所有的攻击类型分为五大类,分别设置五个标签,如表1所示.

表1分类标签设置Tab.1 Classification label settings
2one-hot编码和标准化
KDD99数据集进行one-hot编码解决了分类器不好处理属性数据的问题,让特征之间的距离计算更加合理,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点.然后将所有的特征转换成“field_id:feat_id:value”格式,field_id代表特征所属field的编号,feat_id是特征编号,value是特征的值.为避免小的数值属性消失并减少计算迭代次数,用以下方程式给出的线性函数将数值数据归一化为[0,1]:其中,max为样本数据的最大值;min为样本数据的最小值;x为标准化后的数据.

3.3 实验结果和分析
为了评估模型的性能,使用了五个评估指标:准确性ACC(Accuracy),检出率(DR),召回率(Recall),F度量(F-measure),误报率(FPR).
预测正确的比上全部的数据,计算公式如下
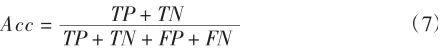
检出率(DR)和精准率(Precision)的计算方式是一样的是指样品的比例分类器正确地将所有样本分类预测类别为正,计算公式给出如下
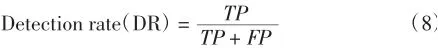
真实阳性率(Recall)是指分类器在实际类别为正的所有样本中正确预测的样本比例,其计算公式

F-measure是精确率和召回率的调和均值,可以一定程度反应模型稳健性,计算公式如下

误报率(FPR)是把正确的当成错误的个数的比例,也就是FPR(假正率),计算公式如下

表2中描述了这些方程式中使用的真正(TP),假负(FN),假正(FP),真负(TN)的说明.

表2混淆矩阵Tab.2 Confusion matrix
其中TP是指被模型预测为正样本,事实上也是正样本的数量;TN是指被模型预测为负样本,事实上也是负样本的数量;FP是指被模型预测为正样本,事实上是负样本的数量;FN是指被模型预测为负样本,事实上是正样本的数量.
实验结果如表3和图2所示.除U2R之外,其他类型的入侵的准确性均大于0.97.由于仅有U2R入侵记录较少,所以效果不好.而训练数据的数量:DoS>Normal>Probe>R2L>R2L,总体上检测的准确率也是这个趋势,表明数据规模越大,检测结果越好.如果有更多的U2R入侵类型的记录,相信检测的准确率会更好.

表3检测结果(DR,FPR)Tab.3 Detection results(DR,FPR)
3.4 不同方法的比较结果

图2检测结果(Acc,Recall,F-measure)Fig.2 Detection results(Acc,Recall,F-measure)
为了验证DNN-FM模型对入侵数据的整体检测性能,比较了几种方法的结果.而这些方法都是KDD 99数据集为基准,结果显示在表4中.
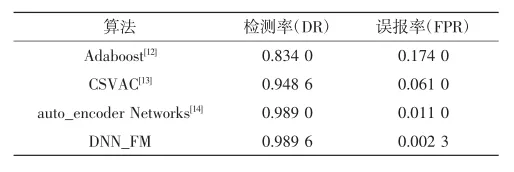
表4与其他方法的比较结果Tab.4 Comparison results with other methods
在KDD99数据集上的实验中,该方法实现了0.989 6 DR和0.002 3 FPR.从表中可以看出使用的模型可以获得较高的检测率,模型的整体性能优于其他机器学习算法.这表明DNN-FM模型是可行的模型.
4 结论
实验结果表明,基于DNN-FM模型的功能和性能优于基于传统机器学习的方法.使用DNN-FM模型进行入侵检测是可行的,尤其是在此多特征数据集中,可以更好的对低阶特征和高阶特征进行交互学习.但是,将来仍有一些问题需要解决.未来需要尝试使用其它的神经网络模型对高阶特征进行交互学习,结合低阶特征交互学习模型来进行网络入侵检测.因此,未来需要做更多的仿真实验.而且发现训练数据规模越大,检测性能越好.需要在数据集中添加更多的U2R和R2L入侵记录.
