融合知识图谱表示学习的栈式自编码器推荐算法
2021-02-25王卫红吕红燕曹玉辉
王卫红 冯 倩 吕红燕 曹玉辉
(河北经贸大学信息技术学院 河北 石家庄 050061)
0 引 言
爆炸性增长的信息数据,为人们的工作、生活、学习提供巨大便利的同时也带来了信息迷航[1]与信息过载[2]问题,为此推荐系统应运而生。推荐系统主要是通过对用户行为数据进行分析与处理、构建用户兴趣模型,从而主动向用户推荐最合适的商品,帮助用户快速地做出决策[3]。目前,因其可以挖掘用户隐式兴趣并提供个性化服务,已成为一个重要的研究领域。协同过滤算法因其通用性、易理解性等优势已成为推荐系统中使用最为广泛的算法之一,但实际应用中因其存在数据稀疏、语义信息欠缺等问题,导致该算法推荐性能较低[4]。
因此,本文提出一种融合知识图谱表示学习的栈式自编码器推荐算法。该算法利用栈式自编码器获取项目深层特征,并与知识图谱表示学习算法得到的语义信息进行融合,能够同时解决数据稀疏性和语义信息欠缺问题,得到更为准确的推荐结果。
1 相关工作
目前,国内外研究学者针协同过滤推荐算法存在的数据稀疏性问题进行了大量研究。文献[5]综合考虑用户评分行为、评分偏好和属性特征,提出一种混合相似度计算模型;文献[6]采用EMD方法对传统的相似度计算进行改进,并与用户信任关系相融合;文献[7]将评分相似度、兴趣相似度、属性相似度与置信度相融合,更为准确地为用户找到所需项目,有效地解决了数据稀疏问题;文献[8]提出一种融合多源异构数据的矩阵分解模型,缓解数据稀疏性问题;文献[9]提出一种新的相似性强化机制来增强基于内存的协同过滤方法,从而解决数据稀疏性问题;文献[10]将属性进行聚类,利用相似特征选择过滤掉冗余属性,降低了数据稀疏性;文献[11]使用关联检索框架中的传播激活算法探索用户之间的关联关系,帮助构建用户兴趣模型有效处理稀疏性问题;文献[12]提出基于邻域的CF的相似性度量方法,提高处理稀疏数据的处理能力。上述研究从评分矩阵填充、相似性方法改进等多个角度探讨了解决数据稀疏性的方法,但未考虑语义信息问题。
语义信息对于推荐系统而言至关重要。2006年Loizou A博士在推荐系统研讨会(ECAI2006)上指出:传统的推荐算法由于没有考虑语义信息,使得在实际应用中,这些算法在实时性、鲁棒性和推荐质量等方面存在严重的不足[13]。因此,将语义信息融入协同过滤推荐算法中,利用语义知识对用户兴趣和项目内容进行描述以提高算法的推荐质量便成为近年来协同过滤算法研究的一个重要方向。目前针对语义推荐算法的研究较少,文献[14]将基于用户显式数据的协同过滤算法与知识图谱表示学习方法相融合,来增强项目的语义信息;文献[15]将语义网中的本体技术运用到社交网络的服务推荐系统中,得到更加准确的推荐结果;文献[16]引入WordNet词汇结构,分析用户标签与项目之间的相似度,在语义方面更好地理解用户偏好;文献[17]提出混合多准则的语义增强协同过滤算法,具有较好的推荐效果;文献[18]构建基于语义网的推荐模型,应用于农业学习资源推荐。由此可知,这些探讨语义问题的研究工作中并未考虑数据稀疏性问题。
本文为了同时解决数据稀疏与语义信息欠缺问题,提出一种融合知识图谱表示学习的栈式自编码器推荐算法。
2 SAEKG-CF
2.1 基本思想
本文提出的算法旨在同时解决数据稀疏与语义信息欠缺问题,针对数据稀疏问题采用栈式自编码器进行降维和特征提取,针对语义信息欠缺问题采用知识图谱表示学习算法获得项目的知识语义信息,并将两者相结合,得到优化的推荐结果。
栈式自编码器[19]是一种深度模型结构,通过多层编码器和解码器可以自动地抽取深层隐式特征,相当于输入数据的压缩表示,这种表示能更好地代替原始数据。栈式自编码器强大的特征提取能力能够有效地缓解数据稀疏性问题,但缺少对结果的语义解释。
知识图谱融合多源异构数据信息将用户与用户、用户与项目、项目与项目之间相互连接起来,且可以结合推理得到数据的语义信息[20]。现有研究表明,知识图谱表示学习方法能将知识图谱中的实体和关系嵌入到一个低维语义空间,利用连续数值向量高效地计算实体间的语义联系[21]。
因此,SAEKG-CF将栈式自编码器和知识图谱表示学习算法进行融合,既可以对栈式编码器产生的结果增加语义解释,又可以缓解协同过滤推荐算法中数据稀疏性和语义信息欠缺的问题。该算法的工作原理如图1所示。

图1 SAEKG-CF工作原理
2.2 算法设计
2.2.1基于栈式自编码器的特征相似性度量
设用户个数为M,项目个数为N,用户对项目的评分矩阵记为RMN,用户集合为U={u1,u2,…,ui,…,uM},项目集合为V={v1,v2,…,vi,…,vN},对于任意一个项目,根据用户对项目的评分可产生一个项目向量Rj=(r1j,r2j,…,rMj)。本文算法将原有的三层自编码器网络结构设置为七层的栈式自编码器,其中包括一个输入层,五个隐含层和一个输出层,其结构如图2所示。
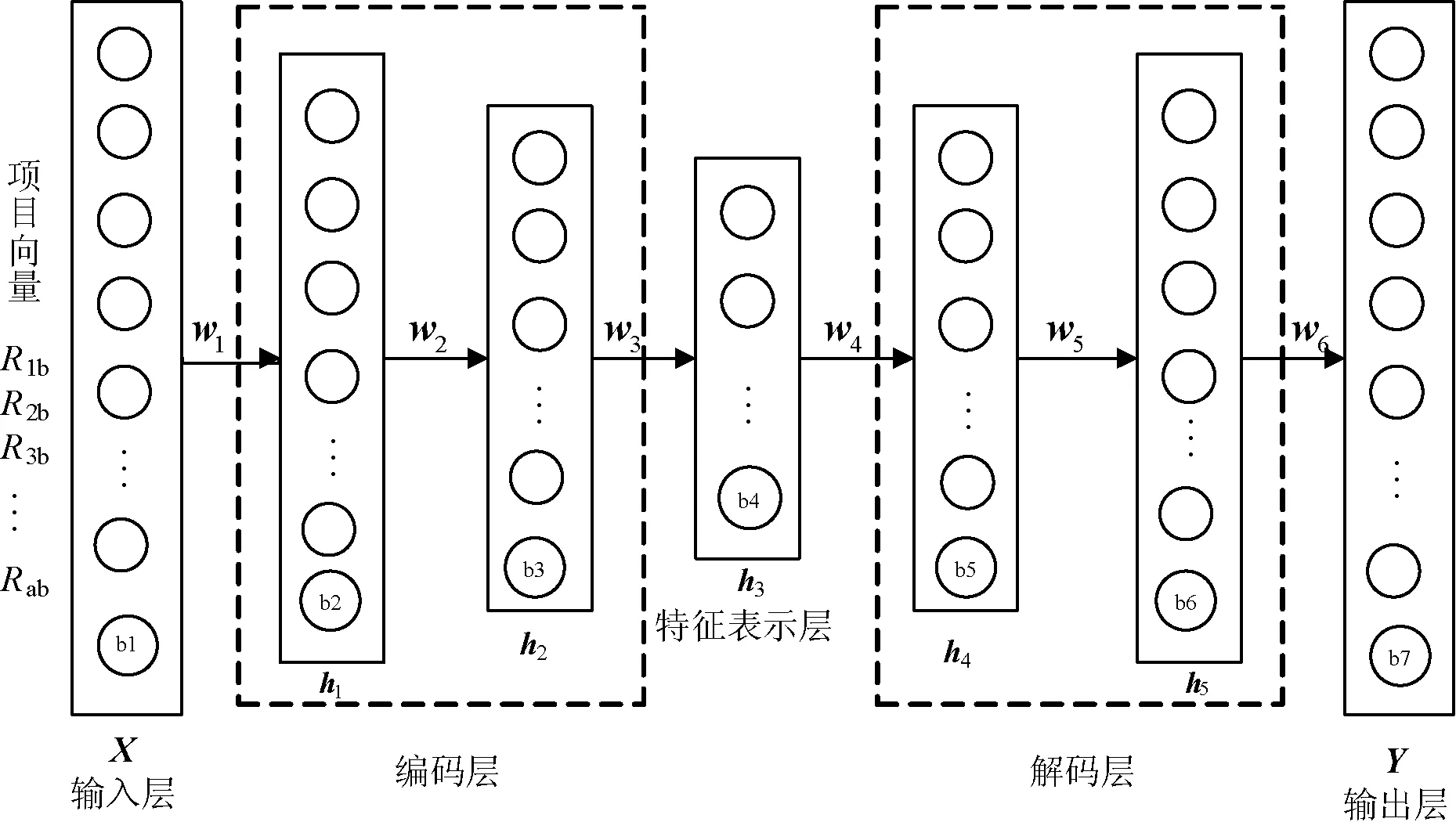
图2 栈式自编码器结构图
可以看出,前三层为编码阶段,后三层为解码阶段,中间为特征表示层,各层之间采用的是全连接,各层之间的输出为:
hi=f(wihi-1+bi)
(1)
式中:wi为权重矩阵;bi为偏置向量;f(·)为激活函数。为防止过拟合,加入了正则项的损失函数:
(2)
式中:h1i为输入向量的第i个分量;h7i表示重构后向量的第i个分量;λ为正则化系数。
本文算法通过最小化损失函数来训练整个网络,输出训练好的隐含层数据h4记为Rvi,表示项目的特征向量。根据得到的项目特征向量进行相似性度量,采用余弦相似度计算:
(3)
2.2.2基于知识图谱表示学习的语义相似性度量
知识图谱的表示学习算法能够将知识图谱三元组映射到低维向量空间,从而实现数值表示。本文使用在语义表达方面具有较好性能的TransE[22]算法,来增强用户-项目评分矩阵中项目的语义信息。
TransE通过不断调整头实体向量h、关系向量r和尾实体向量t,使得h+r尽可能地与t相等,即‖h+r‖≈‖t‖,‖·‖可以选择L1或者L2范数,其模型如图3所示。
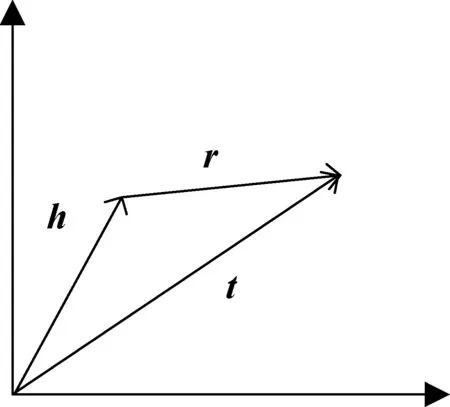
图3 TransE模型
TransE的优化目标函数定义为:
‖h′+r-t′‖]+
(4)
式中:γ是间距参数;S为知识图谱中三元组集合;S′为负例样本三元组组合,该类负例样本由S中的头实体或者尾实体随机替换成其他实体所得。
TransE算法在处理单一关系上具有高效性,但在多关系上存在局限性[23],因此,本文算法采用随机梯度下降进行不断迭代,使目标函数达到最优,针对知识图谱中存在的多关系实体进行单独训练,得到每个关系对应的该实体向量,取均值作为该实体的语义向量,从而改善TransE算法在多元关系上的性能。将项目语义向量表示为:
V=(e1,e2,…,ed)T
(5)
式中:en表示项目V语义向量在第n维上的值。
由于在对实体进行映射时,采用的是欧氏距离,因此为了准确描述项目间的语义相似性,本文算法采用同等范数的欧氏距离来计算项目之间相似性,计算公式如下:
(6)
可以看出计算结果越接近于1,两个项目之间的语义相似性越高;反之计算值越接近于0,说明两个项目之间关系疏远。
2.2.3融合项目相似性计算与评分预测
(1) 融合相似性矩阵的计算。基于评分矩阵,通过式(3)和式(6)可以得到项目的特征相似性矩阵和语义相似性矩阵,然后对两个矩阵进行融合,依据推荐结果的准确率得到最优融合相似性矩阵,原理示意如图4所示。
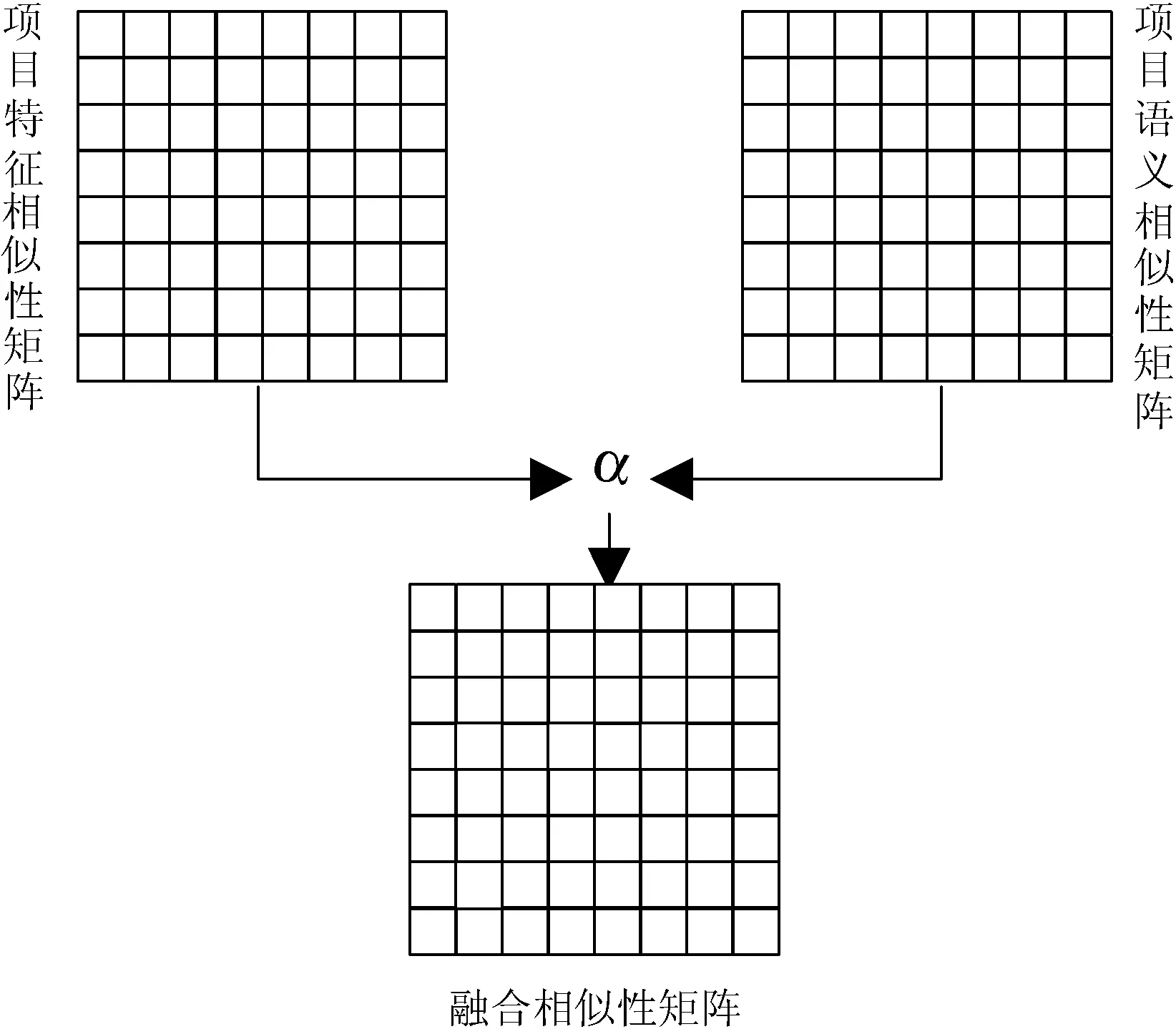
图4 融合原理图
融合公式如下:
sim(va,vb)=αsim2(va,vb)+(1-α)sim1(va,vb)
(7)
式中:α为融合因子,实验中通过不断调整α的值,找到最优融合相似性矩阵。
(2) 评分预测。根据得到的最优融合相似性矩阵,预测用户对未评价物品的评分,计算公式如下:
(8)
式中:Ru,vb为用户u对项目vb的评分;sim(va,vb)表示项目va和vb的相似度;Tu为用户交互的项目列表。
3 实 验
3.1 数据集与评价指标
实验数据集采用MovieLens-1M和Book-Crossing Dataset,MovieLens-1M数据集主要包括6 040个用户对3 952部电影的100多万条评分记录[24]。Book-Crossing Dataset[25]主要包括17 860个用户对14 967本书籍的100多万条评分记录。本文知识图谱采用文献[26]开源的电影和书籍知识图谱,数据集80%作为训练集,20%作为测试集,并用5折交叉验证的方法进行实验,将平均值作为最终的实验结果。本文采用准确率(Precision)、召回率(Recall)和F1值作为评价标准。计算公式如下:
(9)
(10)
(11)
式中:M(u)为推荐算法产生的推荐列表;N(u)为真实的行为列表。准确率与召回率两者之间是相互影响的,理想情况是两者取值都高,但实际情况通常是准确率高时,召回率的值较低,因此采用F1值来权衡这两个指标,作为推荐效果好坏的依据。
3.2 实验结果与分析
在MovieLens-1M数据集上栈式自编码器采用的网络规模为6 040-4 000-2 000-300-2 000-4 000-6 040,正则化系数λ取0.1,并在该数据集上对参数α和知识图谱表示学习嵌入维度dim进行调优。Book-Crossing数据集中栈式自编码器采用的网络规模为17 860-8 000-3 000-300-3 000-8 000-17 860,其他参数采用MovieLens-1M数据集调优得到的参数值。
3.2.1融合因子的优化及K值确定
融合因子α取值不同,所得到的推荐效果也会有所差异,本文在区间[0,1]内,以0.2为间隔选取α值,当α为0时表示基于栈式自编码器的推荐算法,当α为1时表示基于知识图谱表示学习的推荐算法,选取表示学习嵌入维度为200,图5和图6分别为准确率和召回率曲线。
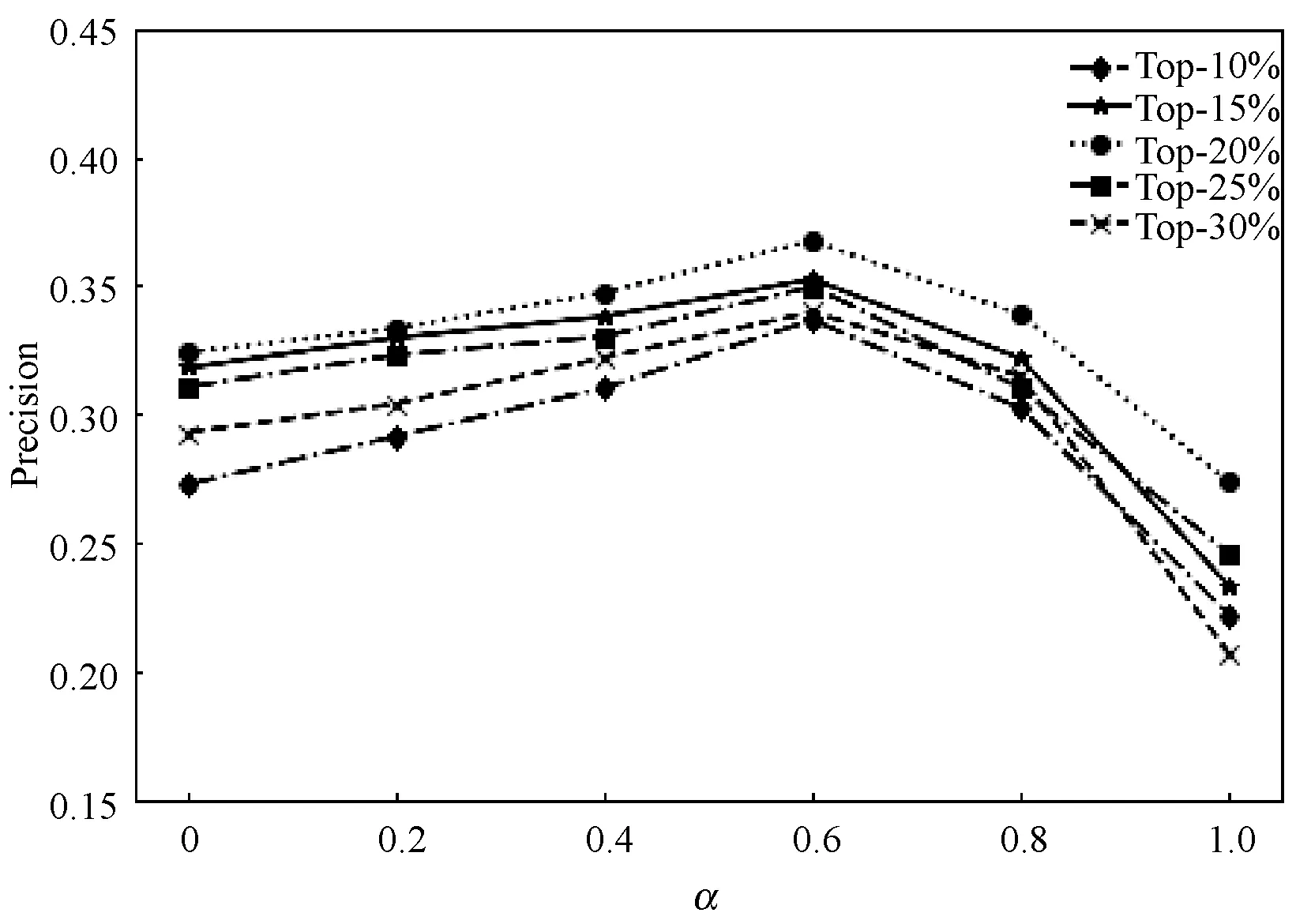
图5 Precision比较

图6 Recall比较
可以看出,随着α的增加,准确率和召回率均呈现先上升后下降的趋势,当α值为0.6,准确率和召回率的值达到最高。当推荐列表长度为20时,整体推荐效果最佳。因此本文算法将α值设置为0.6,k设置为20。
3.2.2表示学习嵌入维度确定
知识图谱表示学习将实体嵌入低维一个空间,维度的取值同样会对推荐效果产生一定的影响,本文分别选取了50~300维进行实验,图7-图9分别为准确率、召回率和F1值随维度的变化情况。
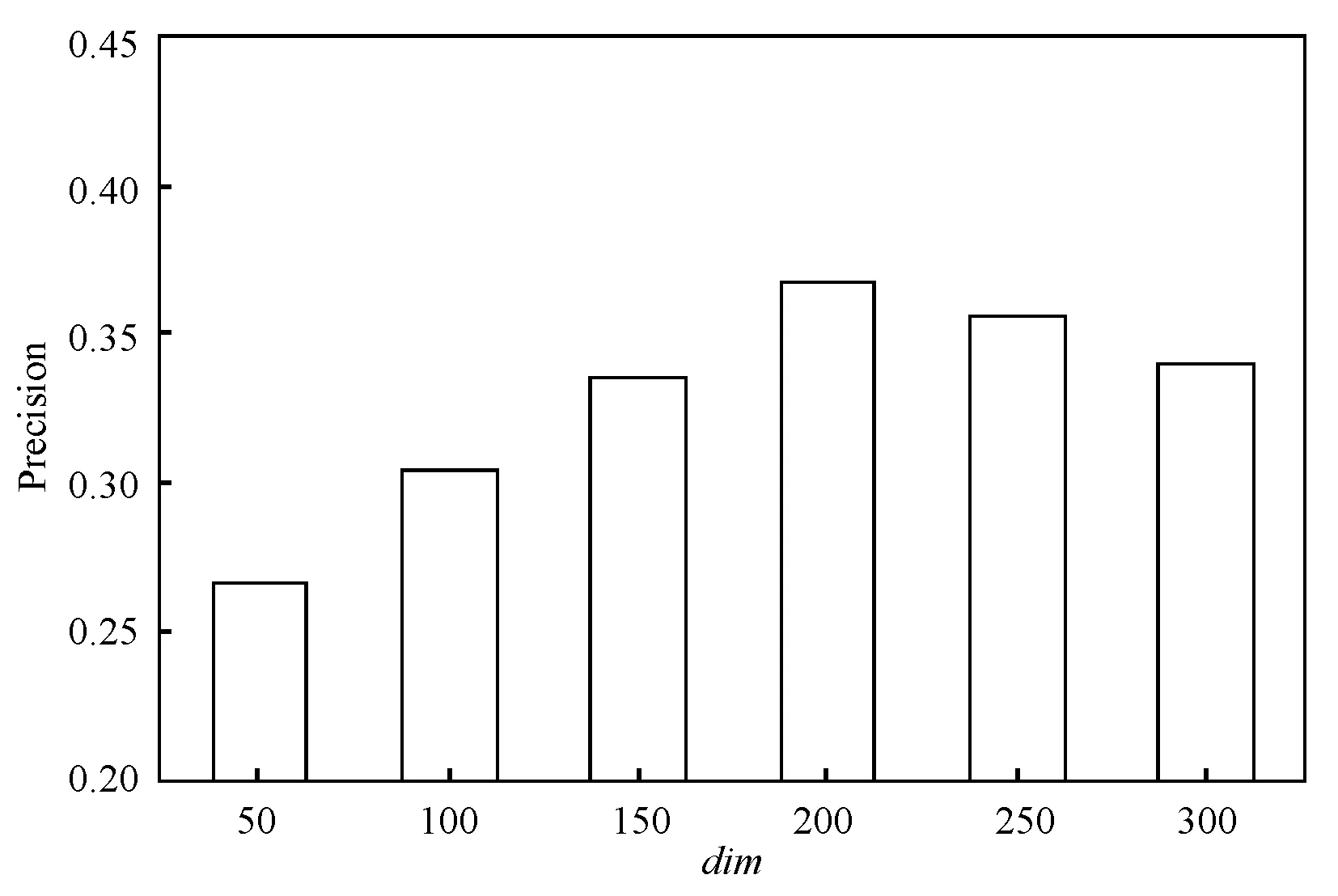
图7 Precision随维度的变化情况
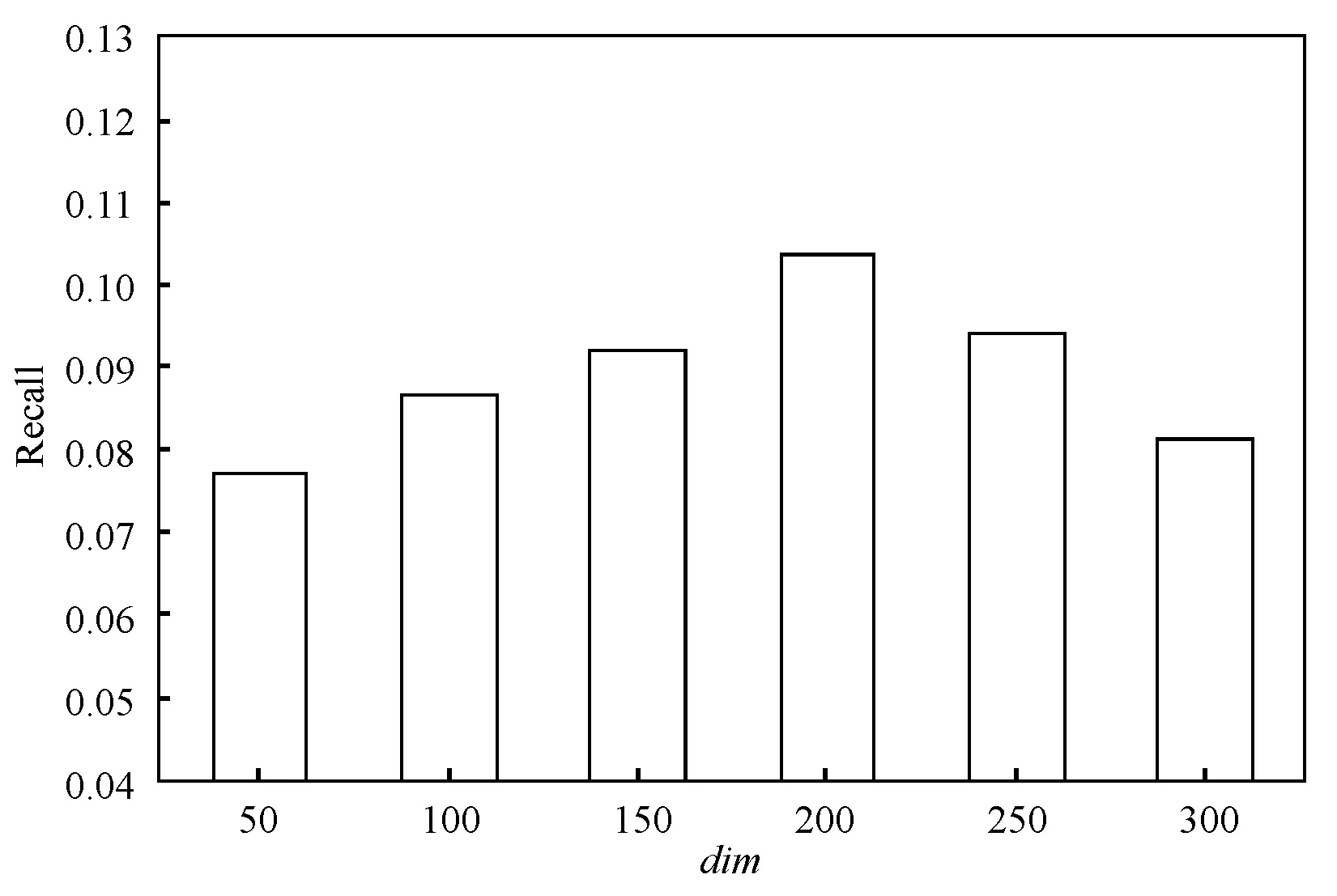
图8 Recall随维度的变化情况

图9 F1随维度的变化情况
可以看出,随着嵌入维度的增加,准确率、召回率与F1值先逐步增加,当维度为200时取值最高,然后逐步减小,因此选取知识图谱嵌入维度为200。
3.2.3结果分析
为了验证该算法的有效性,将其与协同过滤推荐算法(Item-CF)、奇异值分解(SVD)、栈式自编码器算法(SAE)、知识图谱表示学习算法(KG-CB)在不同稀疏程度的数据集MovieLens-1M和Book-Crossing上进行对比实验,表1为数据集稀疏程度,表2和表3为对比实验结果。
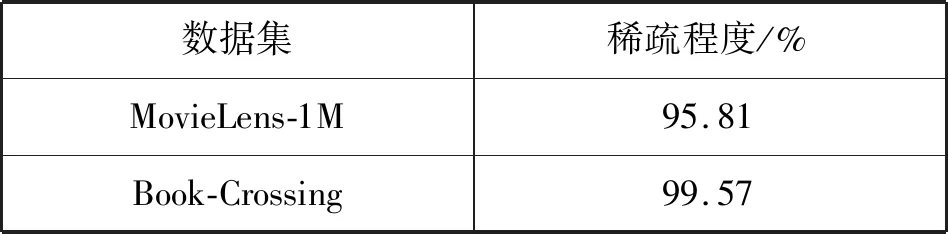
表1 数据集稀疏程度
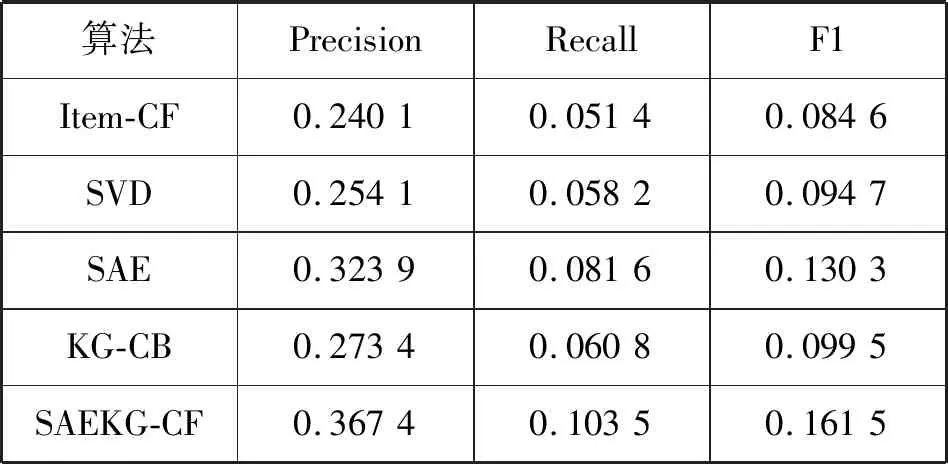
表2 MovieLens-1M对比实验结果

表3 Book-Crossing对比实验结果
从表2、表3可以看出,SAEKG-CF性能在不同稀疏程度的数据集上均优于其他四种算法,准确率、召回率与F1值有所提升,因此算法在一定程度上有效地缓解了协同过滤推荐算法中数据稀疏性和语义信息欠缺的问题。
4 结 语
针对协同过滤推荐算法中数据稀疏和语义信息欠缺问题,本文提出一种融合知识图谱表示学习的栈式自编码器推荐算法,利用栈式自编码器获取项目深层特征,并与知识图谱表示学习算法得到的语义信息进行融合。实验结果表明,该算法能够同时解决数据稀疏性和语义信息欠缺问题,得到更为准确的推荐结果。未来考虑在不同领域的数据集上进行实验,并寻找更优的网络层数,其次考虑引入其他深度学习模型来提高推荐效果。
