改进LNS和邻域保持嵌入算法的研究
2021-02-25黄莹莹
李 元 黄莹莹
(沈阳化工大学信息工程学院 辽宁 沈阳 110142)
0 引 言
随着自动化技术日新月异的发展和人民生活水平的不断提高,人们对生产产品的质量要求也越来越高,因此生产过程也趋于复杂化。生产过程的复杂化不可避免地产生大量且维数较高的数据,故障诊断技术就是利用这些可以被采集、存储、分析和利用的过程数据进行数据建模,进而进行故障诊断。但现实的是在建模时,这些高维数据通常计算量较大并且很难建立监控模型,因而有必要对这些数据进行降维处理。降维后的数据由于包含原始数据大部分特征并且容易进行监控,故而受到很多专家学者的青睐。目前常见的数据降维算法有很多,比较熟知的线性降维技术有主元分析(Principal Component Analysis,PCA)[1]、偏最小二乘(Partial Least Squares,PLS)等[2],非线性降维技术包括局部线性嵌入(Locally Linear Embedding,LLE)[3]、拉普拉斯特征映射(Laplacian Eigenmap,LE)[4]等。上述降维方法所能处理的数据类型和动机都不同,因而彼此的目标函数也有些许差异。PCA是基于数据驱动方法的多元统计过程控制中常用的降维方法[5],它寻找数据分布方差最大的方向,并将该方向作为第一主元方向。PLS可以用于提取与质量变化相关的主元。LLE、LE是近年来比较热门的非线性降维技术,它们的共同点在于都是利用样本点的局部近邻信息来获知其内部结构信息,但它们有一个缺点就是“样本外”问题[6]。所谓“样本外”问题是指它们利用训练数据建立过程模型,但是新来的测试数据(训练数据之外)不能直接投影到过程模型上而是需要重新计算,因此给计算带来困难。He等[7]提出了一种新的流形学习算法-邻域保持嵌入(Neighbor Preserving Embedding,NPE)算法,NPE算法虽然由LLE算法延伸而来,但与非线性降维技术LLE不同的是,NPE是一种线性降维技术,它除了继承了LLE算法的邻域结构保持特性还有效解决了“样本外”问题,它和LLE算法一样都是利用训练数据建立模型,但新来测试数据可通过一个投影矩阵直接投影到过程模型上。
由于NPE算法的简便性并且降维后原高维空间线性结构依然可以被保持,因此被广泛应用于人脸识别和故障诊断中。Liu等[8]提出了一种新的特征提取方法-联合稀疏邻域保持嵌入(JSNPE)。NPE可以保持局部结构但却忽略了全局特征,因此赵小强等[9]提出了张量全局-局部邻域保持嵌入方法(TGNPE)。针对动态过程,杨健等[10]提出了时序约束NPE算法(TCNPE)。针对高维分类数据,寇勃晨等[11]提出了自适应NPE方法(IM-ANPE)。针对多模态数据,宋冰等[12]提出了LSNPE算法。
NPE算法使用z-score方法标准化,z-score方法可以消除量纲但当数据疏密程度不同时标准化后数据的多模态特征依然明显。因此针对方差差异明显的多模态数据,引入Ma等[13]提出的局部近邻标准化(Local Neighbor Standardization,LNS)方法,该方法在消除量纲的同时可以使数据中心平移到原点,且标准化后的数据疏密程度相同。
综上所述,针对现代生产过程数据多模态和复杂数据分布问题,本文提出MLNS-NPE算法对工业过程进行故障诊断。MLNS方法提高了NPE算法对稀疏多模态数据的故障检测性能,NPE算法在数据降维的同时提取数据的局部信息,削弱原始空间离群点的影响。最后将该方法用于故障诊断中,取得良好的故障检测效果。
1 邻域保持嵌入(NPE)算法
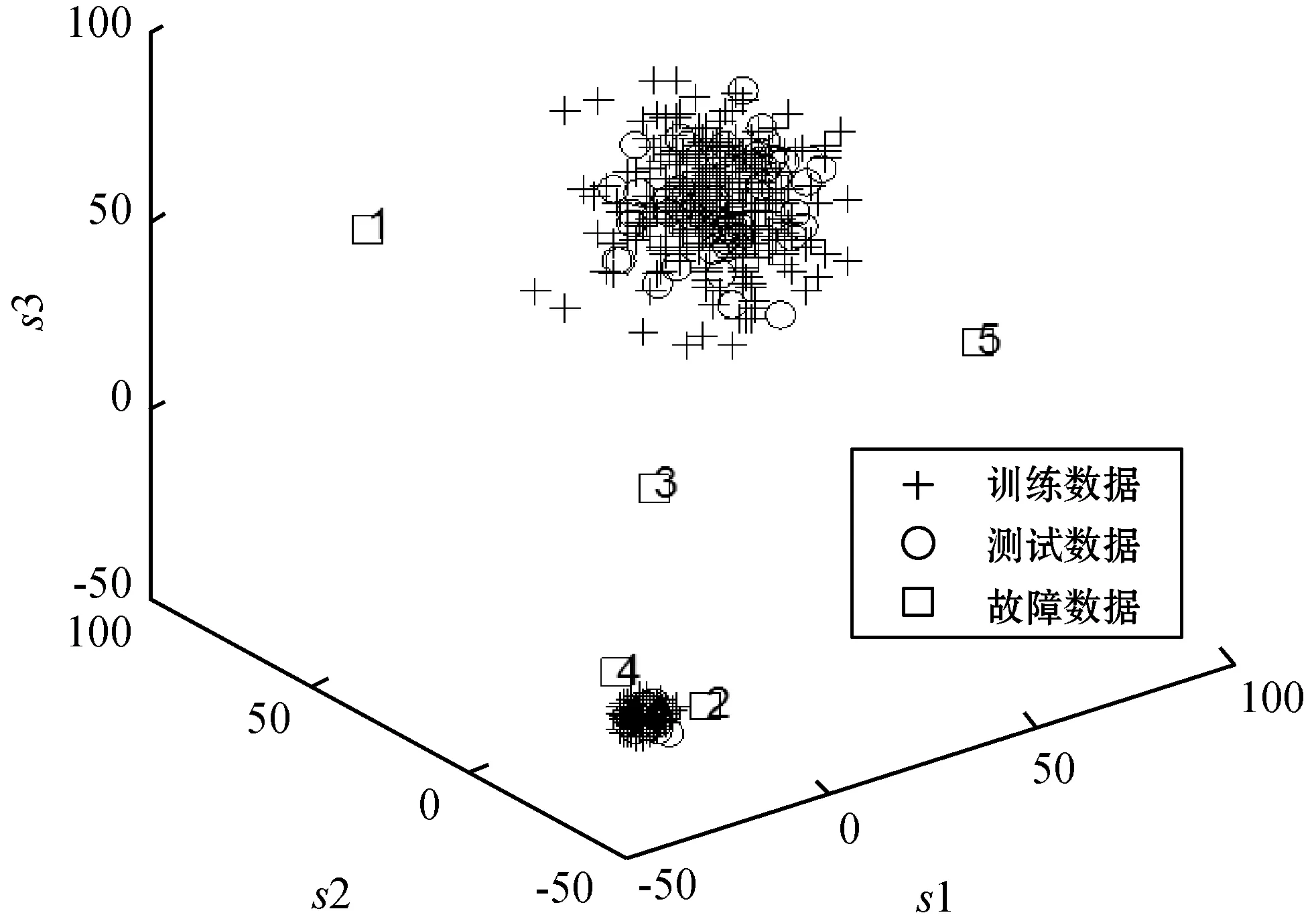
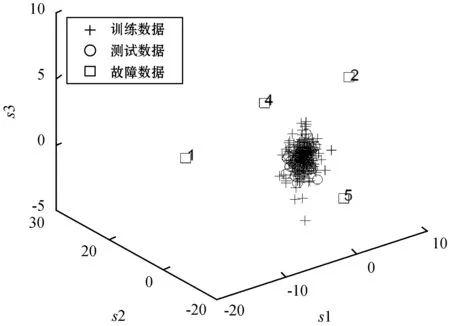
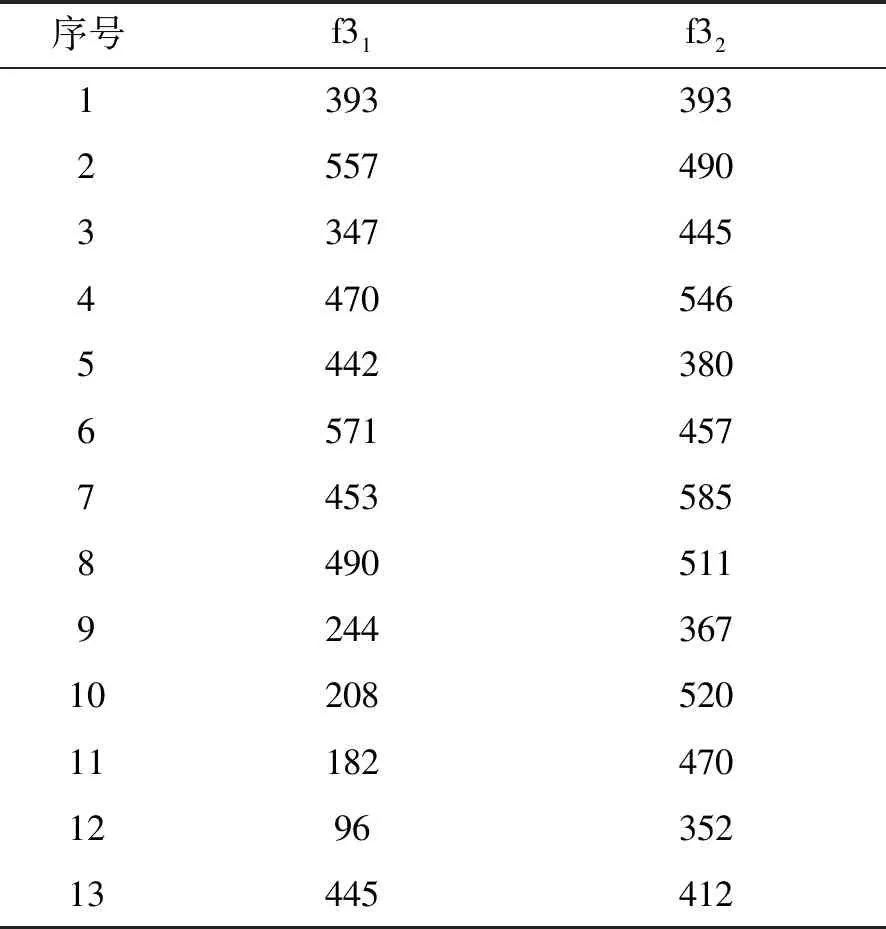
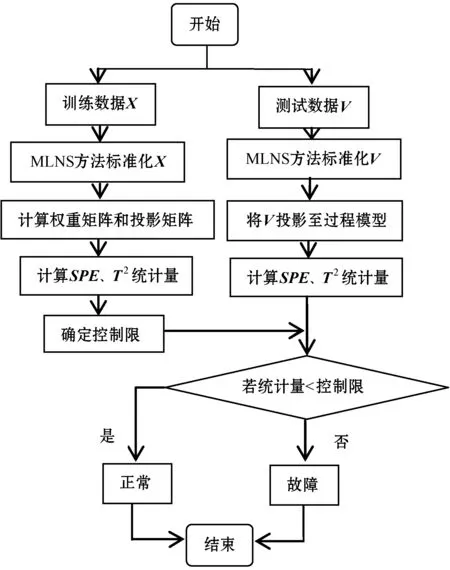
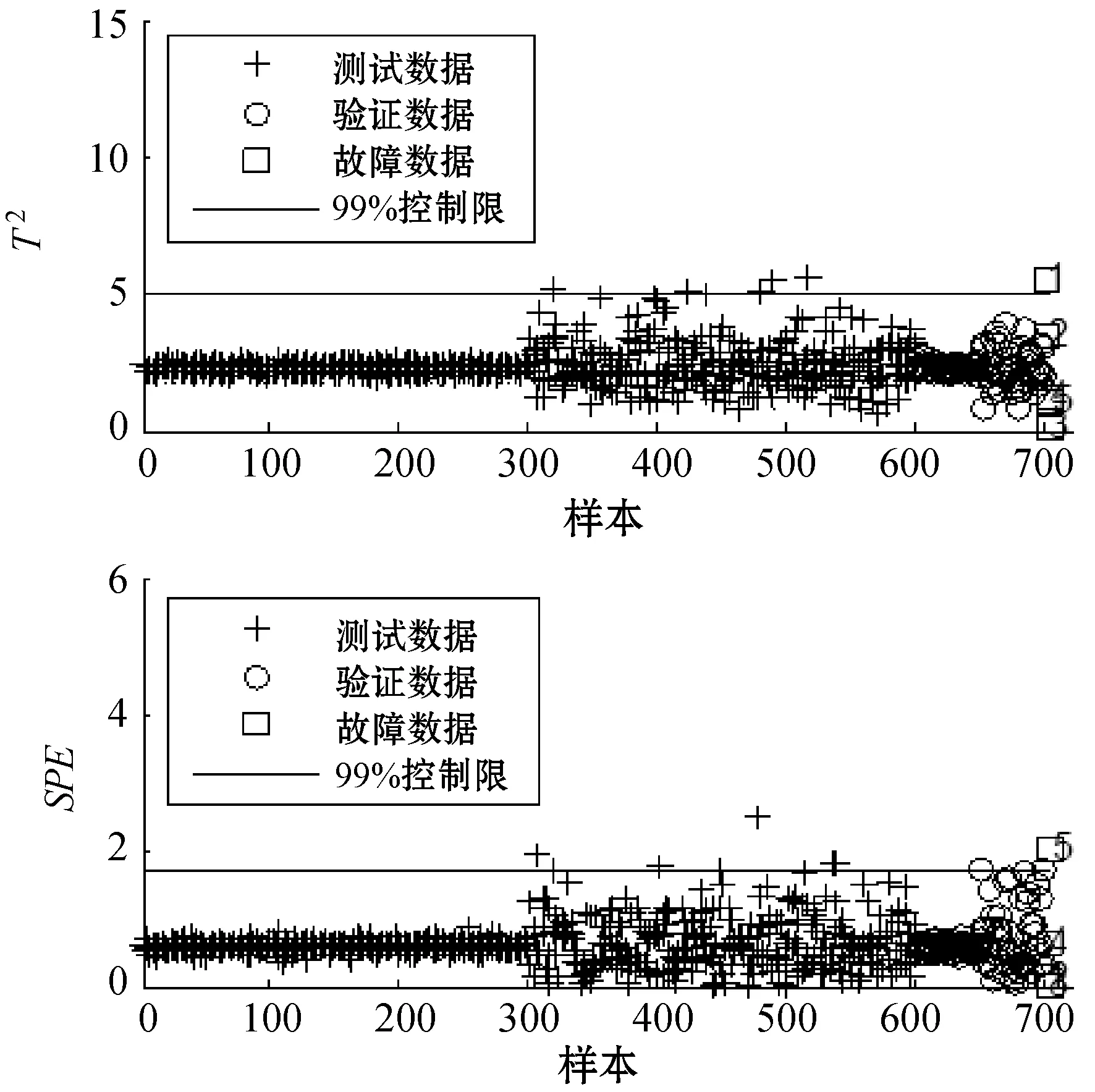
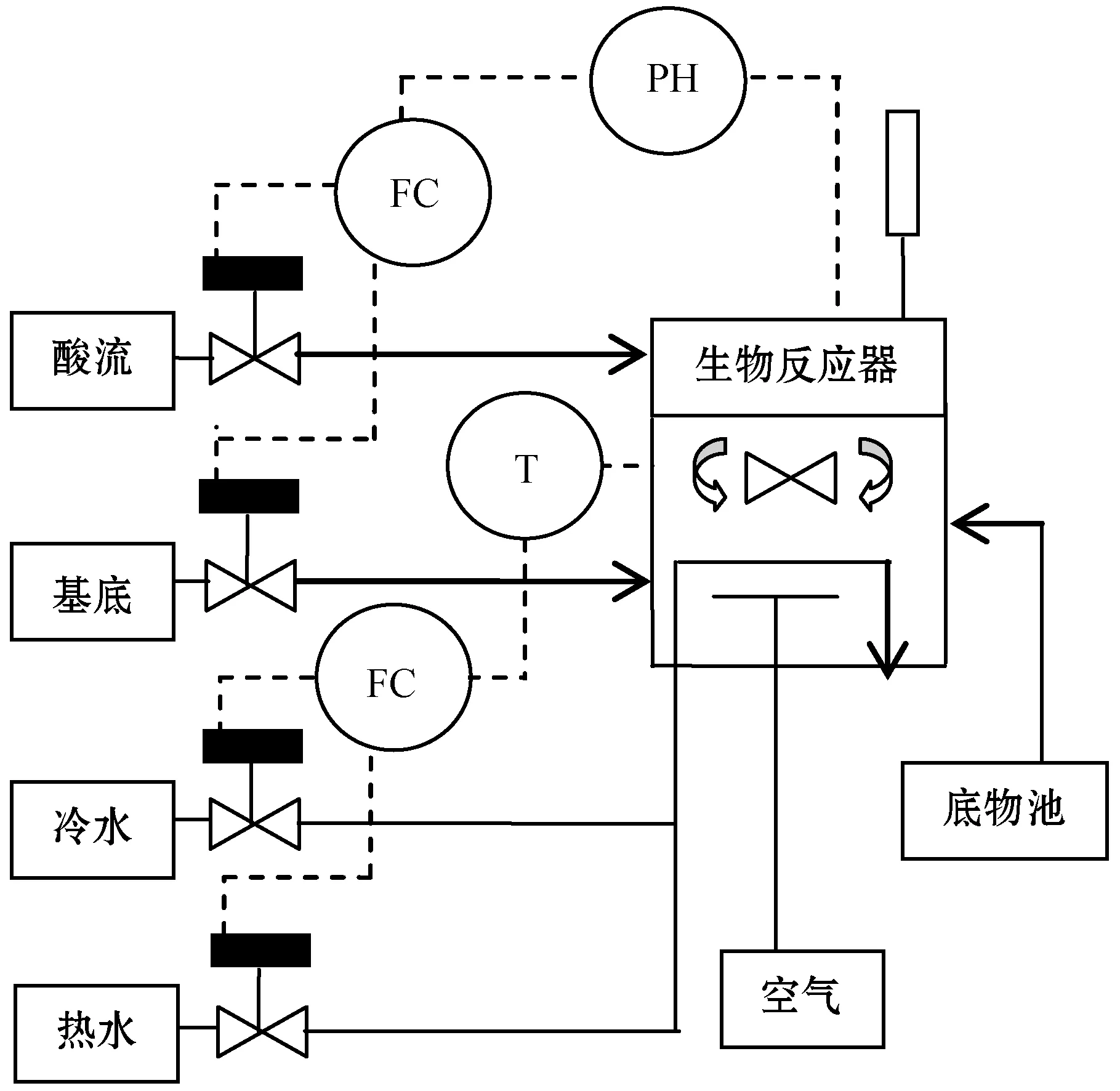
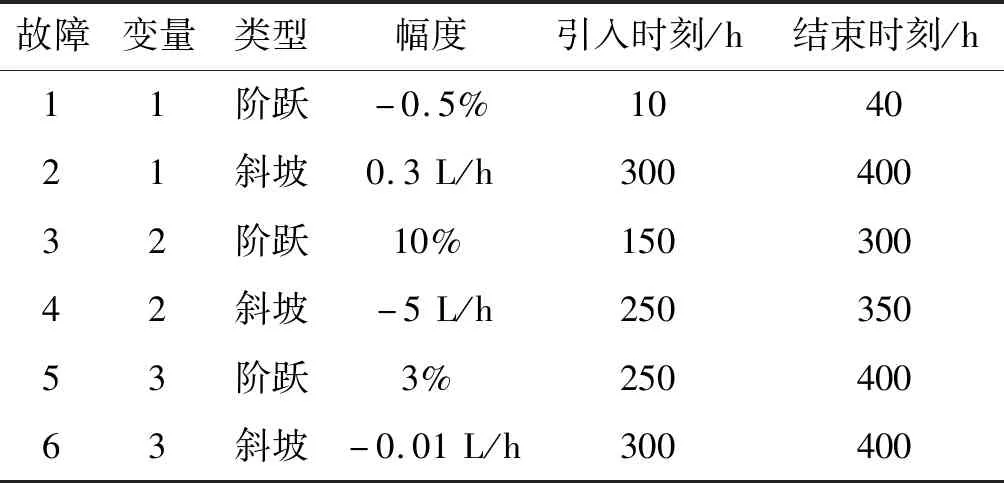
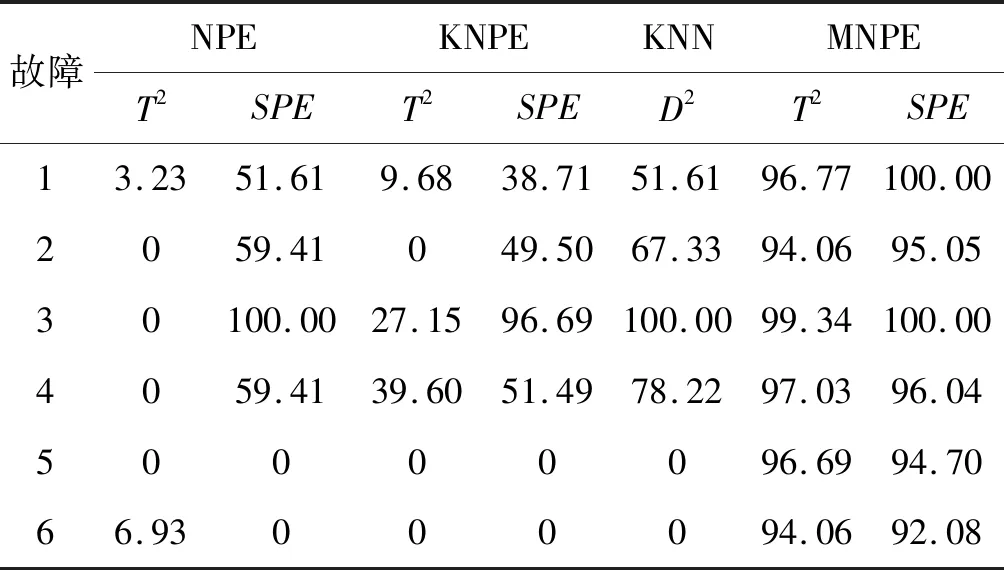
NPE是流形算法的一种,为避免“样本外”数据问题,它的目标就是寻找一投影矩阵A=(a1,a2,…,ad)将原始数据集X=(x1,x2,…,xn)∈RD映射到特征空间中,特征空间的数据集Y=(y1,y2,…,yn)∈Rd(d (1) 构造邻接图:使用k近邻法,若xj属于样本xi的k近邻,则两者之间有一条直接的边。 (2) 构造权重矩阵:通过最小化重构误差函数得到局部权重值,重构误差函数为: (1) 式中:wij为样本xi与其近邻xj之间的权重系数;W为权重矩阵且约束条件∑wij=1。当xj∈xk时,wij≠0;当xj∉xk时,wij=0。 式(1)的求解可以引入拉格朗日乘数法,式(1)可以写成: (2) 式中:zi=(xi-xj)(xi-xj)T。构造拉格朗日函数: (3) (4) (5) 因此得到的权重矩阵为: (6) (3) 构造投影矩阵。NPE的思想是若在原始高维空间权值wij可以线性表示样本xi,那么它同样可以在投影空间线性表示yi,以此表示其线性结构得到了保持。投影矩阵A可以通过下式得到。 (7) q=y-Wy=(I-W)y (8) q2=qTq=yT(I-W)T(I-W)y= aTX(I-W)T(I-W)XTa (9) 构造拉格朗日函数: L(a)=aTX(I-W)T(I-W)XTa+λ2(aTXXTa-1) (10) (a) 原始数据 (a) LNS 对a求导,得到式(11),其中λ=-λ2。 2X(I-W)T(I-W)XTa+2λ2XXTa=0 (11) 因此式(7)的最优化问题转化成为XMXTa=λXXTa的广义特征值求解问题。a0,a1,…,ad-1是特征值λ0≤λ1≤…≤λd-1对应的特征向量,M=(I-W)T(I-W),则投影矩阵A=[a0,a1,…,ad-1]。 得到投影矩阵A后,原始数据被分为特征空间Y和残差空间E: X=AY+E (12) Y=(ATA)-1ATX=ATX (13) E=X-AY (14) 分别在特征空间和残差空间建立T2统计量和SPE统计量: (15) (16) 式中:Λ为对角矩阵。 使用上述NPE算法时所用的数据标准化方法为z-score标准化方法,z-score方法是针对数据集整体的均值和标准差进行标准化,它可以实现单一模态数据的标准化处理,但在处理方差差异明显的多模态数据时,只能消除量纲,各模态疏密程度并没有变化。针对方差差异明显的多模态数据,近年来出现了种新的数据标准化方法即局部近邻标准化(LNS)方法,LNS标准化方法如下: (17) 式中:N(xi)、mean(N(xi))、std(N(xi))分别为样本xi的近邻集、均值和标准差。 LNS寻找样本xi的k近邻作为近邻集,对各自模态正常样本而言,其近邻集的均值和标准差都源于各自模态,正常样本与其近邻集均值的距离较小,因此xi-mean(N(xi))可以使数据中心平移到原点,相比稀疏模态,密集模态更靠近原点。稀疏模态方差较大,xi-mean(N(xi))除以std(N(xi))可以使稀疏模态向内聚拢,密集模态方差较小,作商使密集模态数据向外扩散,因此两个模态经LNS处理后多中心变为一个中心并且疏密程度大致相同。正常样本与其近邻集均值的距离小于故障样本与其近邻集均值的距离,因此LNS方法处理后故障样本偏离原点,远离正常样本。 LNS虽然能有效处理稀疏多模态数据,但当故障样本位于多个模态中间时,它的k个近邻样本可能同时位于几个不同模态中[14],此时故障样本近邻集方差波动大,因此LNS方法处理后得到的新样本同正常样本一样接近原点,此时故障样本混入正常样本导致LNS无法识别该故障。采用MLNS方法来解决样本近邻间跨模态问题。MLNS标准化方式如下: (18) MLNS方法寻找样本第一近邻的近邻集,对于正常样本和非位于模态之间的故障样本,其作用同LNS方法。对于位于模态之间的故障样本而言,无论其第一近邻属于哪个模态,其近邻集都全部属于该模态,均值和标准差也都属于该模态,此时近邻集方差波动较小,因此经MLNS方法处理后,该故障样本远离数据中心,偏离正常样本。下面用一数值例子说明:随机生成一多模态数值例子,两个模态满足: 每个模态选取300个训练样本,50个测试样本,共600个训练样本,100个测试样本。并设置5个故障,分别为f1(-40,45,70)、f2(-30,-50,-16)、f3(0,5,6)、f4(-25,-15,-25)、f5(75,0,20)。 如图1所示,原始数据包含数据中心不重合的两个模态:模态1密集,模态2稀疏。f1、f5为稀疏模态故障,f2、f4为密集模态故障,f4为密集模态的微弱故障,f3位于两个模态中间。原始数据经z-score标准化处理后消除了量纲,但数据分布仍为稀疏多模态。如图2所示,使用LNS方法处理后稀疏多模态数据变为疏密程度大致相同的单一模态数据,数据中心平移到原点附近。此时f1、f2、f4、f5偏离正常样本,但位于模态间的f3混入正常样本,被正常样本覆盖。使用MLNS方法处理后稀疏多模态数据变为疏密程度大致相同的单一模态数据,多模态数据中心重合并且平移到原点附近,多模态特性消除,f1、f2、f4、f5偏离正常样本的同时f3远离正常样本点。 表1为f3的前13近邻,f31表示故障样本f3的前13近邻,可以看出第9、10、11、12个近邻属于第一模态,其余为第二模态,因此f3存在近邻样本跨模态问题。f32表示f3第一近邻的前13个近邻,可以看出,第一近邻属于第二模态,第一近邻的前13个近邻全部属于第二模态,因此采用MLNS方法避免了模态中心故障近邻集跨模态问题,f3被成功检测,提高了NPE算法对疏密不同数据的检测能力。 表1 故障样本f3的前13近邻 传统NPE算法使用z-score标准化方法,但对于多模态数据而言,经z-score标准化后,数据仍具有多个中心,即仍然是多模态结构。因此NPE算法在处理具有多个中心且疏密程度不同的多模态数据时,其处理效果并不好。针对疏密程度不同的多模态数据的故障检测,本文提出一种基于MLNS-NPE的故障检测方法,使用MLNS方法代替原始NPE算法的z-score标准化方法,去除数据的多中心和方差差异特性,然后进行NPE建模。基于MLNS-NPE的多模态故障检测分为模型建立和在线检测两个阶段: 1) 正常状态下的模型建立: (2) 在高维空间构造邻接图,根据式(6)构造权重矩阵。 (3) 根据式(7)构建投影矩阵。 (4) 计算SPE、T2统计量。 2) 在线检测: (1) 应用MLNS算法标准化新样本V。 MLNS-NPE算法流程如图3所示。 图3 MLNS-NPE流程图 本节数值例子使用上节的数值实例,分别用NPE、KNPE、KNN、MLNS-NPE四种算法对该多模态过程进行检测。其中NPE、KNPE、MLNS-NPE算法的重构近邻数为6,KNN算法的近邻数为13,MLNS-NPE算法中第一近邻的k近邻数为13。检测结果如图4所示。 (a) NPE算法 使用上述四种方法检测:其中NPE和KNPE两种方法都使用z-score方法进行标准化,检测效果如图4(a)和图4(b)所示。NPE方法的SPE、T2统计量各检测到一个故障,此时控制限完全由较稀疏模态确定。使用KNPE方法,将数据映射到高维,有效降低了非线性的影响,T2统计量检测到故障f1、f5,SPE统计量没有检测到故障,此时模态间差异仍然存在,控制限仍然由稀疏模态确定,因而故障检测率较低。 图4(c)使用了KNN方法,可以有效处理疏密程度相似的多模态数据,但在处理疏密程度差异较大的多模态数据时,控制限依然由稀疏模态确定。由图4(c)可以看出,虽然D2成功检测出4个故障,但位于密集模态的微弱故障f4没有被检测出来。图4(d)使用MLNS-NPE方法,两个模态变为一个模态,消除模态间结构信息,T2、SPE均成功检测出所有故障。四种方法故障检测结果如表2所示。 表2 99%控制限下四种算法对数值例子的检测结果 青霉素发酵生产过程是典型的多阶段过程,整个生产过程分为三个阶段:1) 菌体生长阶段:发酵培养基接种后青霉菌在合适的环境中经过短时间的适应开始发育、生长和繁殖,伴随葡萄糖底料的快速消耗;2) 青霉素合成阶段:这个阶段主要合成青霉素,青霉素的生产率达到最大;3)菌体自溶阶段:这个阶段菌体衰老,细胞开始自溶,青霉素合成能力衰退。图5为青霉素发酵过程工艺流程。 图5 青霉素发酵工艺流程 本文通过Pensim仿真平台[16-17]实现青霉素发酵过程的仿真。Pensim仿真平台可以模仿青霉素发酵生产过程,它有5个输入变量用来控制发酵过程中各种参数的变化,还有9个过程变量,产生于菌体合成以及生长过程中,另外还有影响青霉素产量的5个质量变量。整个生产过程分为两个大的阶段,前43 h为青霉素菌生长阶段,为稀疏模态数据阶段;43~400 h为合成青霉素阶段,为密集模态数据阶段。可在前三个变量(空气流量、搅拌功率、底物流速率)上引入阶跃和斜坡故障,并且还可以设置两种故障的幅度、引入和结束时间[18-19]。 选取青霉素发酵过程的12个主要变量作为故障检测变量,如表3所示。对前三个变量施加的故障类型和幅度如表4所示,其中f1为稀疏模态故障,f2-f6为密集模态故障。实验时,采取仿真时间为400 h,采样时间为1 h,各输入参数全部采取Pensim平台的默认值运行一次,产生一个批次(400×18)的正常数据作为训练数据进行建模。 表3 青霉素变量类型 续表3 表4 故障类型 应用NPE、KNPE、KNN、MNPE四种算法依次进行仿真,NPE、KNPE、MNPE的重构近邻数为6,KNN的近邻数k=13,MNPE方法第一近邻的k近邻数为13。四种算法的故障检测率如表5所示。由于过程分为两个模态,且密度显著不同,不服从多元高斯分布,所以NPE、KNPE方法检测效率都较低。f3为大尺度故障,因此四种算法的故障检测效率都很高。KNN方法能够对一般多模态数据进行检测,但当数据模态差异明显时,控制限由稀疏模态确定,因此故障检测能力较低,f2、f4、f5、f6为这类故障。f1的类型为稀疏模态的微弱故障,其到正常样本的距离小于正常样本之间距离,因此故障检测效率比较低。使用MNPE算法,两个模态融合成单一模态,消除了多模态特征,与其他三种算法相比,6组实验MLNS-NPE故障检测效率最高。 表5 故障检测率 % 图6中f4的故障类型为斜坡故障,故障刚引入时,故障样本与正常样本间差异很小,存在故障延迟现象,因此四种算法在故障引入初始时刻的故障检测能力很弱,但所提出的MNPE方法的故障延迟最小,检测效率也最高。 (a) NPE算法 本文提出一种基于改进LNS和邻域保持嵌入的算法来提高NPE算法对方差差异明显的多模态数据的故障检测能力。MLNS方法可以使疏密程度不同的多模态数据变为单一模态,并近似服从多元高斯分布,从根本上消除多模态数据影响,为后续NPE算法的使用提供先决条件。利用NPE算法降维和特征提取,同时将高维局部信息保留。将二者结合应用在数值例子和青霉素生产过程中。与其他几种算法相比,所提出的MLNS-NPE算法故障检测率最高,验证了该方法的可行性。
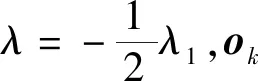
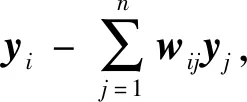
2 算法设计
2.1 局部近邻标准化

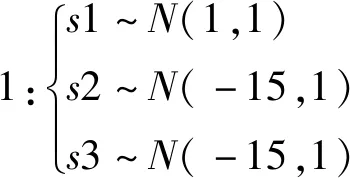
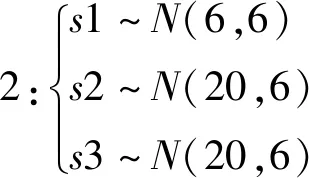
2.2 故障检测

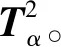
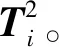
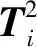
2.3 算法流程
3 仿真分析
3.1 数值例子
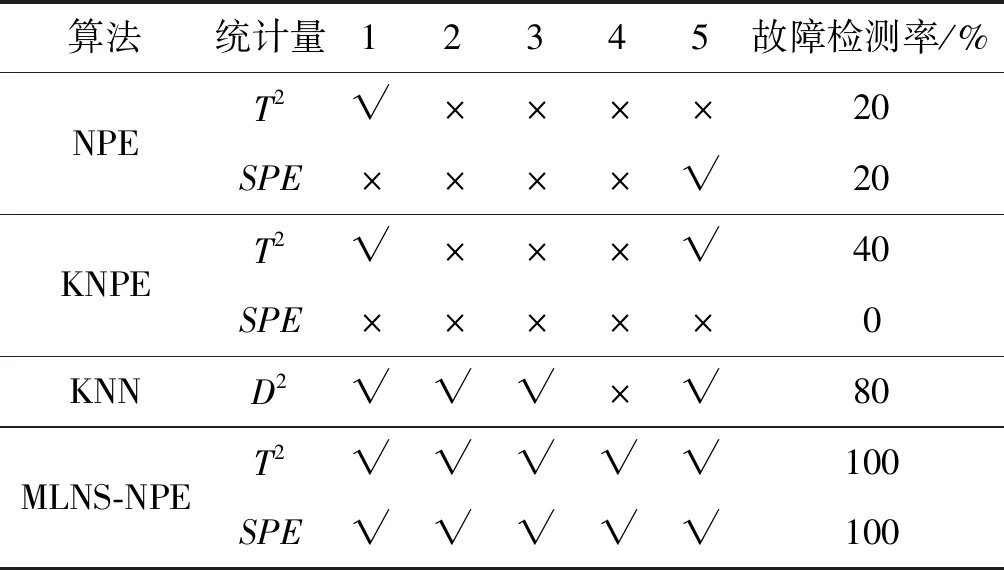
3.2 青霉素发酵过程



4 结 语
