商品名称短文本快速有效分类的多基模型框架
2021-02-25沈雅婷左志新
沈雅婷 左志新
(南京理工大学紫金学院 江苏 南京 210023)
0 引 言
分类一直是自然语言处理(NLP)领域的重点问题,被广泛地应用到生活之中。随着中国互联网信息技术行业的快速发展以及大数据时代的到来,电子文本数据呈现井喷式增长,例如微博、商品评论、商品名称等短文本数据占比最大。合理地对其进行分类,便于用户快速查找所需信息或商品,也便于商家及时发现问题和掌握用户需求,提高用户满意度。针对产生的大量短文本数据,人工分类存在速度慢,成本高等问题,所以需要机器去代替人工完成分类。
文本分类问题是NLP领域中一个非常经典的问题,最早可以追溯到20世纪50年代,早期主要通过知识工程,手工定义规则来分类,不仅浪费时间和人力,而且使用范围和准确度都十分有限。随着20世纪90年代互联网在线文本的涌现和机器学习的兴起,研究者重新开始对文本分类的研究,逐渐将文本分类问题拆分成特征工程和分类器两个部分,即基于传统机器学习的文本分类。其中特征工程包括文本预处理、特征提取和文本表示等,分类器基本都是统计分类的方法,如K近邻、朴素贝叶斯[1]、决策树、支持向量机等。以上方法相比早期的方法有着更好的分类效果,但是文本表示的特征表达能力较弱,还需要人工进行特征工程且非常费时费力,成本很高。随着计算能力提升、成本下降、海量大数据支持和人工神经网络兴起,基于人工神经网络的深度学习方法逐渐成为主流的研究方向,深度学习方法利用人工神经网络的网络结构自动获取特征表达的能力解决文本分类的文本表示问题[2],避免了繁杂的人工特征工程,即端到端地解决问题。在文本分类中,常用的神经网络模型有TextCNN[3-4]、TextRNN、fastText[5]等。
直至目前,文本分类在工业界和学术界已经积累了很多方法,主要分为基于传统机器学习、基于深度学习两种文本分类实现方法。基于深度学习的文本分类方法比基于传统机器学习的文本分类方法准确度高,而常规深度学习的文本分类方法中的神经网络训练时间较长。短文本分类的本质还是文本分类,可以直接使用这些方法,但是短文本存在长度短、特征稀疏、表述不规范等特点导致分类性能明显下降。目前针对短文本的特点,主要有通过外部语料库构建词向量、利用网络资源构建专门的类别词库对特定的短文本进行扩展等方法,以提高短文本的分类性能。虽然这些方法降低了短文本的稀疏性,提高了分类准确率,但是获取覆盖所有类别的外部语料库是很困难的。并且在大数据的时代背景下,短文本数据的流通变得越来越快,已有的文本分类方法无法达到既准确率高又训练速度快,这就限制了其在大数据背景下的广泛使用,渐渐不能满足时代对信息处理的高速要求。因此,为了满足时代要求,迫切需要寻求一种新的方法以实现对短文本又好又快地自动分类。
本文提出一种新的模型框架(B_f),以快速文本分类算法(fastText)作为基模型,借鉴自举汇聚法(Bagging)集成算法基本思想,构建多基模型的方法对文本进行分类。通过实验证实提出的方法在文本分类中较独立基模型具有不错的效果,较基于机器学习的传统文本分类算法和深度学习分类方法在准确度与效率上有明显优势。
1 相关知识
1.1 fastText模型
fastText是一个基于浅层神经网络、架构简单的快速文本分类器,由Facebook在2016年开源。其优点是可以使用标准多核CPU在10分钟内训练超过10亿个词,比常规深度学习模型快几百倍,在5分钟内可以对超过30万个类别的50万个句子完成分类。其通过使用n-gram(N元模子)特征来缩小线性规模,其分类准确度能够与常规深度学习模型保持相当,但训练时间却大大短于常规深度模型,分类速度也比深度模型快很多。
fastText由输入层、隐藏层和输出层三层构成,其模型结构如图1所示。
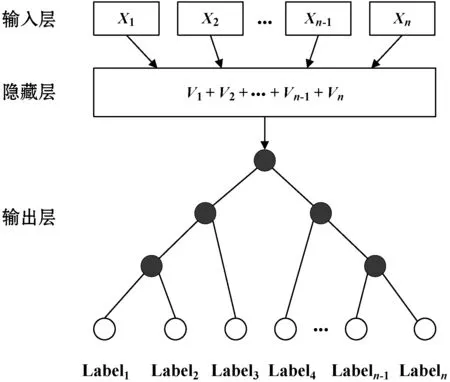
图1 fastText模型结构
图1中:Xn表示第n个单词以及字符的n-gram特征的one-hot表示;Vn表示第n个单词以及字符的n-gram特征密集向量表示;Labeln表示第n个标签。
fastText是将已经分词后的文本作为输入,输出该文本属于不同类别的概率。使用文本中的词和词组构成特征向量,通过线性变换,将特征向量映射到隐藏层,然后构建层次Softmax分类器根据类别的权重和模型参数使用Huffman编码对标签进行编码,将Huffman树作为输出[6-9],Huffman树的叶子节点即为标签。
当数据集的类别很多时,线性分类器的计算会变得很昂贵。为了降低Softmax层的计算复杂度,fastText使用了一个基于Huffman编码树的分层Softmax。在这个Huffman树中,每个叶子节点即代表一个标签。利用了类别不平衡的这个事实,将每个类别出现的频率作为权重,使用Huffman算法构建Huffman树,出现频率高的类别比出现频率低的类别深度要小,使得计算效率更高。
常用的特征有词袋(Bag-of-words,BoW)模型和n-gram特征。其中词袋模型不考虑词之间的顺序,但是对于很多分类问题而言,词序十分重要,如果词序不同,文本含义可能截然相反,但是直接考虑顺序的计算成本又很高昂,而n-gram考虑了局部词序。因此,fastText使用n-gram特征,通过向量表示单词n-gram来将局部词序考虑在内,过滤掉低频的n-gram,从而提高效率[10]。
1.2 Bagging集成学习算法
Bagging[11]是通过多个模型相结合降低泛化误差的技术,把多个不同的个体分类器集成为一个分类器的集成学习方法,主要思想是将训练数据有放回地抽样训练多个不同模型,然后将所有模型对测试样例的表决输出。由于Bagging集成学习算法的个体分类器之间没有强依赖关系,从而可以并行,可使用分布式计算进一步提高算法的效率。
1.3 其他文本分类方法
1) TextCNN模型。CNN是一种前馈神经网络,广泛应用于模式识别、图像处理等领域,是深度学习的代表算法之一。2014年,纽约大学Yoon Kim将CNN应用在文本分类上提出TextCNN模型,一个简单且具有少量超参数调整的CNN,可根据具体任务进行微调进一步提高性能。对矩阵化的文本进行卷积和最大池化后,再通过全连接层的Softmax进行结果输出。由于其结构简单、效果好,在文本分类任务上有着广泛的应用。
2) 朴素贝叶斯模型。贝叶斯算法是以贝叶斯原理为基础,使用数理统计的知识对样本数据集进行分类。贝叶斯分类算法的误判率很低,在数据集较大的情况下表现出较高的准确率,同时算法本身也比较简单。朴素贝叶斯算法是在贝叶斯算法的基础上进行了相应的简化,即假设给定目标值时属性之间相互条件独立,也就是特征向量中一个特征的取值并不影响其他特征的取值,虽然在一定程度上降低了贝叶斯算法的分类效果,但是由于其实现简单且表现惊人,成为应用最为广泛的分类模型之一。
2 框架设计
B_f使用fastText模型作为基模型,借鉴Bagging集成算法的基本思想,挑选fastText的两组最优超参数。15次打乱预处理后的训练数据作为训练样本集分别进行训练,最后构建由15个产生的基模型组成的多基模型,结合少数服从多数的投票机制才能对预处理后的测试样本数据进行标签预测,B_f的总体流程如图2所示。
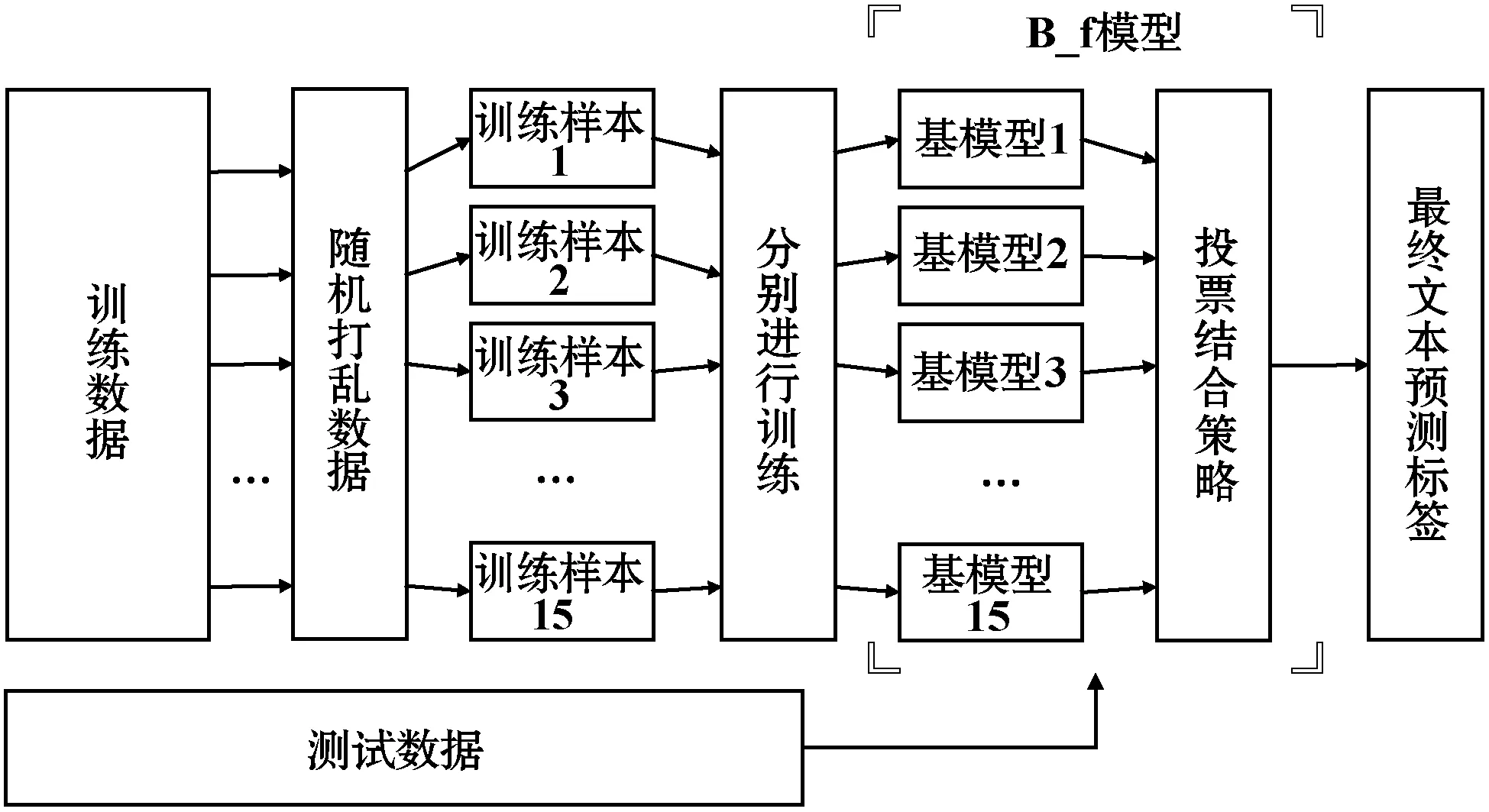
图2 B_f总体流程
2.1 预处理
在使用数据之前,需要对原始文本数据进行预处理工作。主要流程有分词和去停用词等,步骤详述如下:
1) 中文分词。中文与英文不同,英文是以词为单位,词与词之间用空格分隔,而中文是以字为单位,需要使用相关分词工具将中文汉字序列分割成词并用空格分隔[12]。中文分词算法可以分为三类:(1) 字符串匹配算法,其核心思想是词典匹配完成词语切分;(2) 基于理解的分词算法,其基本思想是在分词的同时进行句法、语义分析,因为中文语言的复杂性,目前基于理解的分词系统还处于试验阶段;(3) 基于统计的分词算法,其主要思想是将每个词看作是由字组成的,如果相连的字在不同文本中出现的频率越多,则证明这段字越有可能是一个词。目前Python常用的分词工具有jieba分词、THULAC(一个高效的中文词法分析工具包)等。因此本文选取了具有分词速度快、准确率高和使用简单等特点的jieba分词作为本文使用的分词工具。部分文本使用jieba分词样例如表1所示。
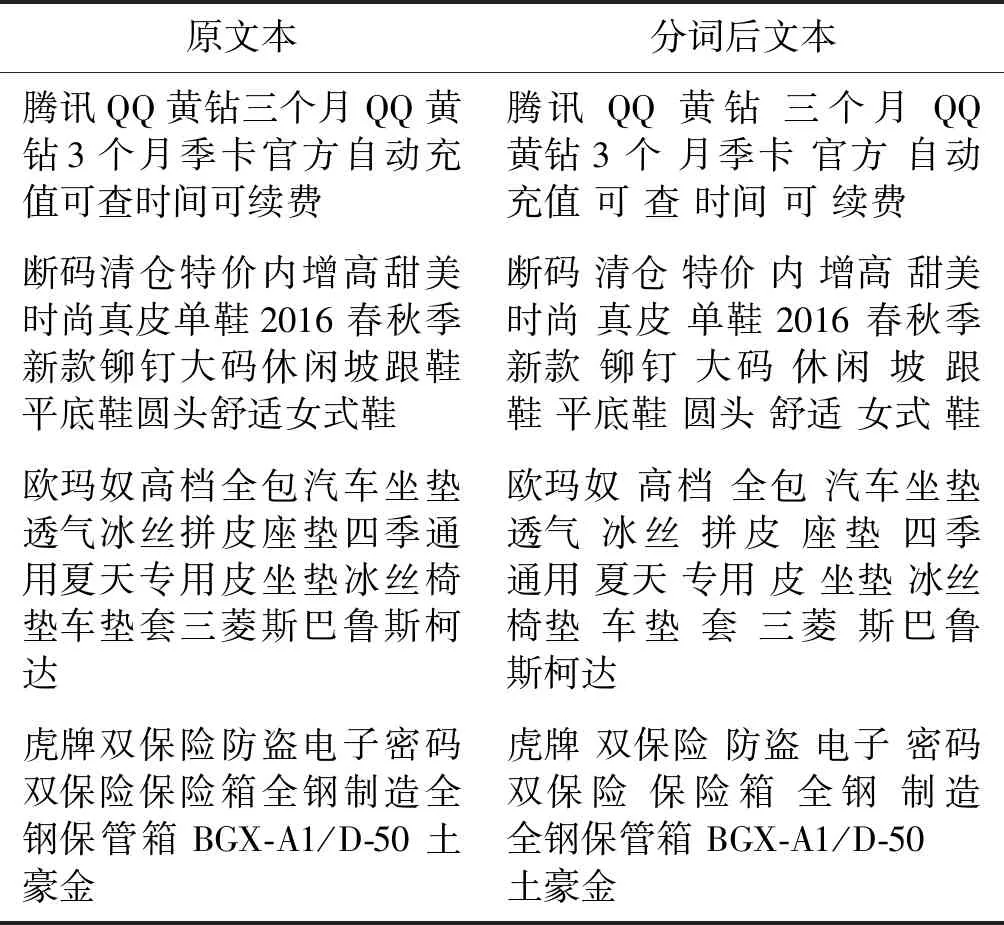
表1 部分文本使用jieba分词样例
(2) 去停用词。去停用词为了将文本中一些出现频率高、无实际意义、对有效信息噪音干扰的词去掉,如“的”“是”“和”等,并且可以节省计算机的存储与计算资源[13]。本文使用“哈工大停用词表”、“四川大学机器智能实验室停用词库”和“百度停用词表”相整合的停用词表作为中文停用词表对文本进行过滤。
2.2 超参数调优
超参数[14-15]是机器学习以及深度学习模型内的框架参数,是在学习之前设置的参数,而不是通过训练得到的。通常,需要对超参数进行调优,给学习机选择一组最优超参数,以提高学习的性能和效果,是一项繁琐但至关重要的任务。通常需要手动设定,不断试错调试,需要大量的专家经验;也可以通过贝叶斯优化算法[16-17]等自动的优化模型进行调优。
由于n-gram超参数是fastText模型一个重要的超参数,能够影响模型的时间效率以及分类精度,所以将n-gram超参数设置为一个固定的值,再进行调优可以大幅度提高超参数调优的进度。通过多次手动调优的实验发现,对于商品名称而言,n-gram超参数设置为1或2时,模型的时间效率以及分类精度最好,研究者需要根据具体数据进行微调。
将预处理后的商品名称训练数据划分为训练集和验证集,然后分别将fastText模型的n-gram超参数设定为1和2,进行超参数调优,获得两组最优超参数。
2.3 构建多基模型
B_f共由15个fastText基模型组成,其中7个由n-gram超参数为1的最优超参数组作为超参数训练得到,另外7个由n-gram超参数为2的最优超参数组作为超参数训练得,最后1个基模型是在这两组最优超参数组中随机抽取一组最为超参数训练得。如图3所示。当对文本进行预测时采用投票机制[18]融合,得到最终预测标签。多基模型如图2所示。
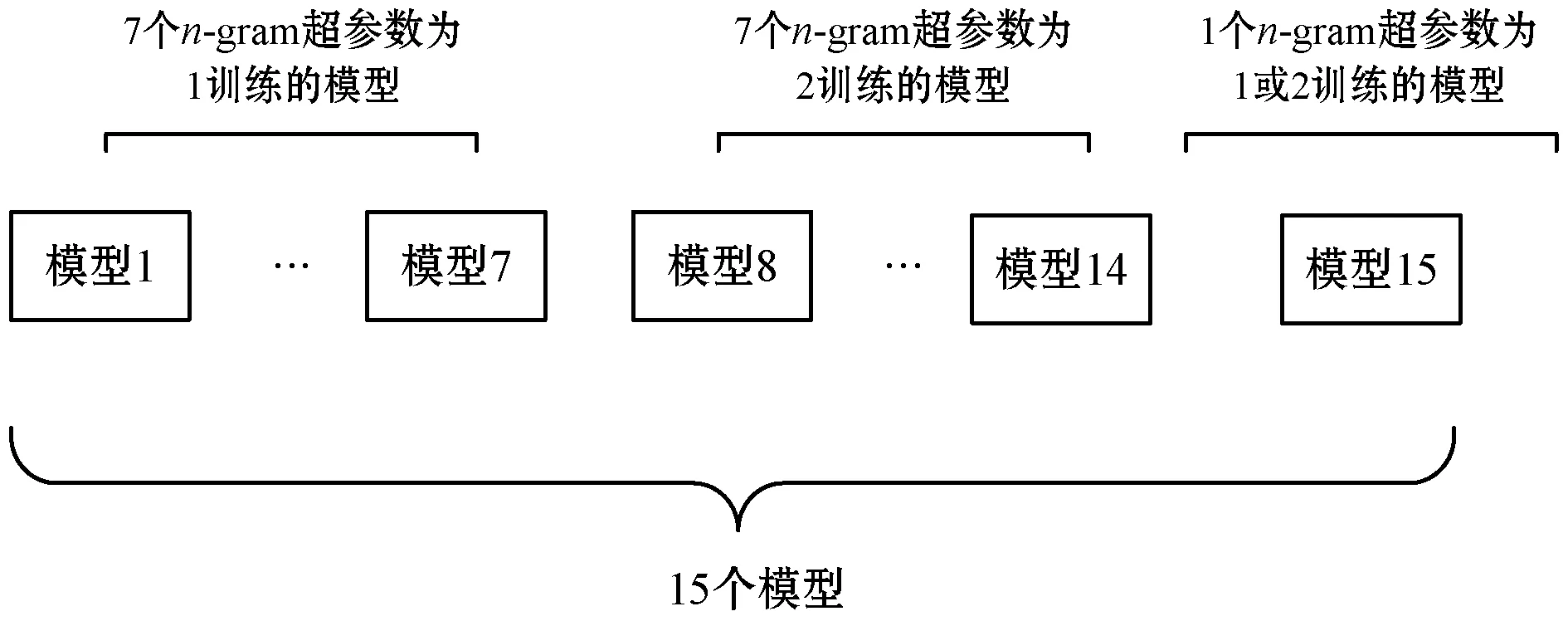
图3 多基模型示意图
每个基模型的训练数据都是由训练集随机打乱而来。对于神经网络来说当训练集较大时,训练集前面的样本对模型权重的影响会随着训练变小,通过多次的打乱达到一种综合的目的。多基模型相对于独立模型而言,对容易产生歧义的样本分类更加有效,单个模型对不同类别的样本分类具有偏向性,实现效果有限,使用多个模型组合能够提高模型的泛化能力[19-20]。
2.4 算法描述
输入:训练集D;fastText算法A。
输出:B_f分类器C(X)。
Step1对训练集D进行预处理;创建预处理后的训练集D1。
Step2使用预处理后的训练集D1进行fastText算法A超参数调优;创建最优超参数组P1;创建最优超参数组P2。
Step3fori=1 to 7
Step4将预处理后的训练集D1随机打乱;创建样本集Di。
Step5用样本集Di和使用最优超参数组P1作为超参数的fastText算法A训练,得到基分类器ci(x)。
因此,赵五娘与公婆之间的关系,不是封建的孝道关系,而是体现了下层社会中人与人之间的一种优良的、朴素的道德关系。
Step6end for
Step7fori=7 to 14
Step8将预处理后的训练集D1随机打乱;创建样本集Di。
Step9用样本集Di和使用最优超参数组P2作为超参数的fastText算法A训练,得到基分类器ci(x)。
Step10end for
Step11将预处理后的训练集D1随机打乱;创建样本集D15。
Step12用样本集D15和随机使用最优超参数组P1或P2作为超参数的fastText算法A训练,得到基分类器c15(x)。
Step13输出B_f分类器
(1)
使用B_f分类器C(X)对未知样本x分类:
未知样本x分类时,每个分类器ci(x)得出一个分类结果,15个分类器投票,得票最多的类别即为未知样本x的分类结果,并输出分类结果:
(2)
3 实 验
3.1 实验数据与实验环境
1) 实验数据。实验使用浪潮卓数大数据产业发展有限公司提供的网络零售平台商品数据,其中商品名与标签来源于网络。选用其中已标记标签的数据作为实验数据,包含本地生活——游戏充值——QQ充值、本地生活——游戏充值——游戏点卡、宠物生活——宠物零食——磨牙/洁齿等1 260个类别。共有50万条数据,本文将分别取数据的100%、50%和1%作为实验数据,如表2所示,其中类别数目c随着数据规模增大而递增。实验全部通过十折交叉验证[21]方式进行,使获得的数据真实有效。
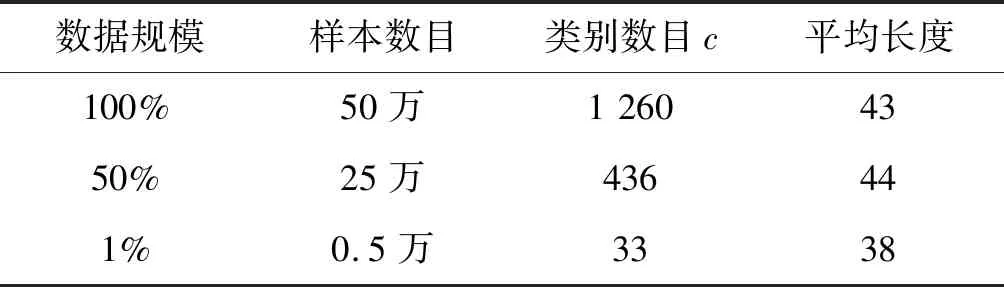
表2 不同规模下的数据集对比表
2) 实验环境。硬件环境平台:MacBook Pro,处理器2.6 GHz Intel Core i7,内存16 GB 2 400 MHz DDR4,macOS Mojave操作系统。软件环境平台:Python 3.7,scikit-learn,TensorFlow。
3.2 衡量方法
本文采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和综合评价指标(F1-Measure)作为评估指标。准确率(Accuracy)计算式为:
(3)
精确率(Precision)的计算式为:
(4)
召回率(Recall)的计算式为:
(5)
综合评价指标(F1-Measure)的计算式为:
(6)
式中:TP为真正例;TN为真负例;FP为假正例;FN为假负例。
使用十折交叉验证得到最终的准确率、精确率、召回率和综合评价指标,以减小实验结果的误差负例。
3.3 结果分析
对于文本分类任务,TextRNN和TextCNN是深度学习中最常见的两大类模型,由于TextRNN与TextCNN分类效果相差不大,TextCNN擅长捕获更短的序列信息,TextRNN擅长捕获更长的序列信息且训练成本更大。本实验使用的商品名称数据集,商品名称描述相对较短,特征词较集中,所以略去TextRNN,使用TextCNN作为对比模型。同时,作为传统文本分类算法的朴素贝叶斯,也较适合处理此类描述相对较短、特征词较集中的文本分类问题。本次实验采用对比分析,在预处理后的实验数据的100%、50%和1%上进行实验。将B_f与单个fastText模型、TextCNN模型以及朴素贝叶斯模型进行对比实验,并采用十折交叉验证方法对这四种算法分别训练十次,将每次训练的输出结果保留,并将十次输出结果取平均值得到四种模型结果的准确率、精确率、召回率和综合评价指标对比如表3-表6所示,其中最优值加粗表示。
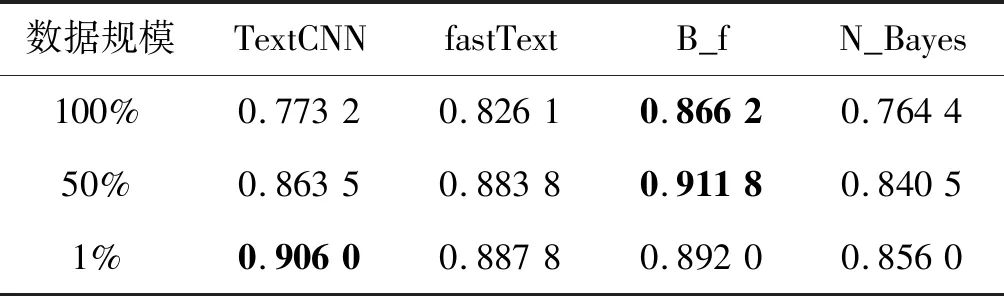
表3 四种模型结果准确率对比
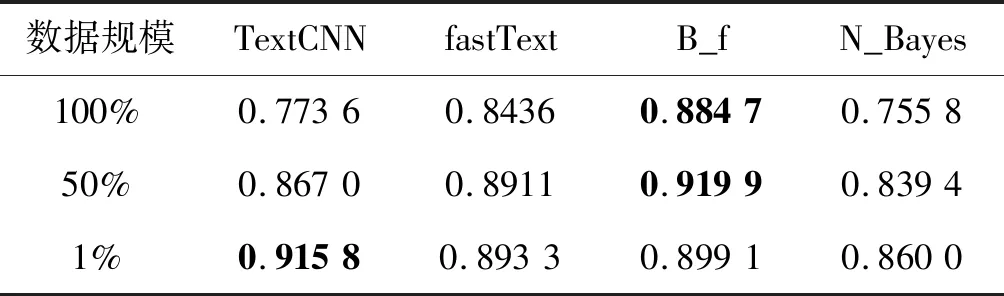
表4 四种模型结果精确率对比
表5 四种模型结果召回率对比
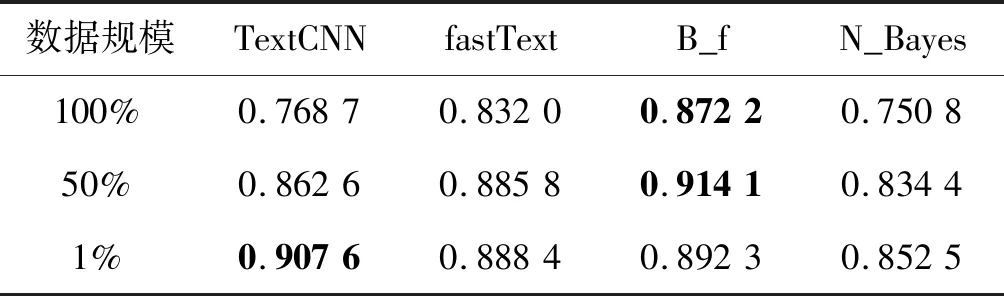
表6 四种模型结果综合评价指标对比
可以看出,本文模型在使用的数据规模为100%时预测精确率高达88.47%,其准确率也达到了86.62%,综合评价指标为87.22%。当数据规模为50%时,本文模型各项指标依然领先与另外三个模型。当数据规模为1%时,本文模型各项指标略微低于TextCNN。不难看出本文模型对于单个fastText模型有较大的提升,对比TextCNN模型在数据规模较大时也有着明显的优势,对比朴素贝叶斯模型同样有着明显优势。因此可得,本文模型相比于单个fastText模型、TextCNN模型、朴素贝叶斯模型较为理想,达到实验目的。
作为传统文本分类算法的朴素贝叶斯在训练时只需计算概率,并不需要复杂的矩阵计算或者迭代优化,因此朴素贝叶斯模型不作为训练时间参考模型。三种模型一次的训练时长如表7所示。不难看出,TextCNN模型由于结构相对复杂,通常需要很长的训练时间,训练成本较高,在数据规模较大的情况下此问题更加明显。fastText模型由于结构简单取得了很好的效果,本文模型由于采用fastText模型为基模型,也取得相对令人满意的效果。

表7 三种模型训练时间对比 s
4 结 语
本文在fastText模型的基础上构建了多基模型框架B_f。它比单个fastText模型具有更高的分类准确率;比TextCNN等深度学习模型在数据量大的情况下有着更短的训练时长和更高的准确率;比朴素贝叶斯等传统文本分类模型也具有更好的分类效果。能够有效地处理商品名称描述的文本分类问题,同时普遍适用于大规模数据的有监督文本分类问题。
鉴于本文提出的多基模型框架B_f的基模型之间没有强依赖关系,可以并行实现。下一步将考虑扩大模型规模,进行在分布式环境下的研究,以进一步提高文本分类的准确率和时间效率。
