基于自注意力机制预训练跨蒙汉语言模型
2021-02-25苏依拉牛向华仁庆道尔吉
苏依拉 高 芬 牛向华 仁庆道尔吉
(内蒙古工业大学信息工程学院 内蒙古 呼和浩特 010080)
0 引 言
机器翻译是人工智能领域的重要研究课题之一,主要目标是研究如何使用计算机实现一种自然语言到另一种自然语言的自动转换[1]。针对蒙汉机器翻译中平行语料资源稀缺的问题,提出利用单语语料[2-8]训练来提高蒙汉机器翻译的质量。而实现基于单语语料库训练的蒙汉机器翻译系统最重要的基础就是需要一个翻译性能良好的初始化翻译模型,而初始化的翻译模型是基于字典的翻译系统和语言模型相结合才能实现的,故预训练一个表现较好的语言模型就显得尤为重要。
语言模型这个概念最早出现在统计机器翻译中,是统计机器翻译技术中较为重要的概率模型之一。通俗而言,语言模型就是一串词序列或者一句话的概率分布,其作用就是可以为一个长度为n的句子计算其存在的可能性的概率分布p。在统计机器翻译中常用的是N-gram语言模型,N表示n元模型,当n选取较大时,就会产生数据稀疏问题,从而导致估算结果出现较大的偏差。因此,实际中最常用的是三元模型,也就是Tri-gram模型。为了缓解N-gram语言模型导致的数据稀疏的问题,也由于计算机技术的快速发展,现在有很多研究者专注于预训练神经网络语言模型的研究。实际上,语言模型就是依据上下文信息去预测下一个词,因为不需要人工标注的数据,所以预训练语言模型,其实就是从大量的单语语料中,学习到比较丰富的语义知识的表示。使用神经网络训练时基本上都是基于后向传播算法(Back Propagation,BP),通过对网络模型的参数进行随机的初始化,再通过一些优化算法去优化初始的模型参数。预训练的原理是:对神经网络模型的参数不进行随机的初始化,而是有目的地训练一套网络模型参数,之后将这套参数用来做初始化,然后再训练。在迁移学习中也大量地使用了这样的思想。
近几年,在自然语言处理(NLP)领域,在多项NLP任务上使用预训练语言模型的方法皆获得了令人可喜的成果,因此预训练语言模型也受到人们广泛的关注。例如,2018年在NTM领域引起热门讨论的几篇文章都和预训练语言模型有关,其中三个比较具有代表性的模型为ELMo[9]、OpenAI GPT[10]和BERT[11],它们都是神经网络语言模型。因神经网络语言模型在当前研究中表现最佳,且使用神经网络的方法可以结合上下文信息学到一些语义信息有利于翻译系统性能的提升,所以本文也采用了该方法预训练语言模型。
1 基于多头自注意力机制的研究
虽然基于LSTM[13]神经网络的方法在一定程度上能够缓解长距离依赖问题,但是因为不能进行并行运算,所以计算速度相对比较缓慢。而且,基于双向LSTM[14]神经网络预训练语言模型的方法看似是双向的,实则是两个单向运算结果的拼接。为了实现真正意义上的双向运算,本文使用基于多头自注意力机制(Multi-head Self-attention Mechanism)的框架预训练跨蒙汉语言模型,此框架依然是编码器-解码器的结构,只不过编码器由多层编码器层堆叠而成,在每一层编码器层中都包含前馈神经网络层和使用了基于多头注意力机制的Transformer的注意力层[15]。
注意力机制来自人类的视觉注意力机制,当人类使用视觉感知外界事物的时候,一般不会将场景中的事物都扫描一遍,而是有选择地去观察那些对自己有用的信息。而注意力机制也是基于这样的原理,注意力函数可以被形容为一个查询(Query)到一系列键值对(Key-Value)的映射,如图1所示,其计算公式如下:
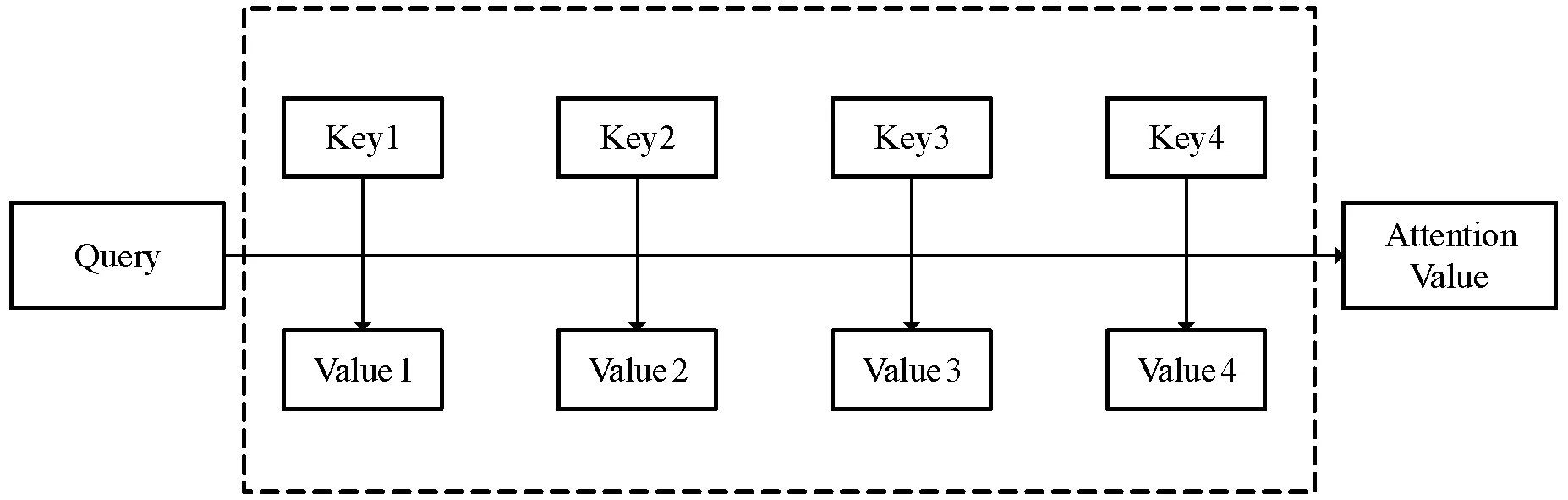
图1 注意力机制原理
(1)
注意力函数值的计算步骤如下:首先是计算Query和每一个Key之间的相似度权重,相似度如果是通过点积再除以维度K进行计算的,则称为放缩点积注意(Scaled Dot-product Attention);然后通过Softmax将计算得到的权重进行归一化操作;最后将归一化之后的相似度权重和Value做加权求和就得到了注意力值。
自注意力机制就是运算过程中Key、Value、Query是相等的。多头注意力就是多个自注意力。多头注意力运算过程是Query、Key、Value首先进行一次线性变换,然后再执行多次的放缩点积注意力运算。而且每次Query、Key、Value进行线性变换的参数W是不一样的。然后将多次的放缩点积注意力结果进行拼接,再进行一次线性变换得到的值作为多头注意力机制的结果。多头注意力可以允许模型在不同的表示子空间里学习到相关的信息。在蒙汉语言模型的训练过程中,指的就是当输入一句话时,句子中的每个词都得和其他的词做注意力运算,这样就能学习到句子中每个词之间的相互依赖关系,即能更进一步地解决长期依赖的问题。
而Transformer的整体构成其实也是一个编码器-解码器的结构,只是整个编码器是由很多个子编码器组成的,每一个子编码器中包含一个多头注意力机制和一个前馈神经网络。它的解码器部分则和编码器部分类似,但是为了更好地优化网络,又添加了一个多头注意力层,并使其与其他层进行了残差连接。
1.1 框架构建
基于多头自注意力机制的框架最大的特点就是使用一个多层双向的Transformer编码器,因为Transformer中包含自注意力机制,所以该框架中所有的网络层都是直接相互连接的,这也是其优于双向LSTM神经网络模型的地方,因此它实现了真正意义上的双向和全局。基于多头自注意力机制框架的组成结构如图2所示。
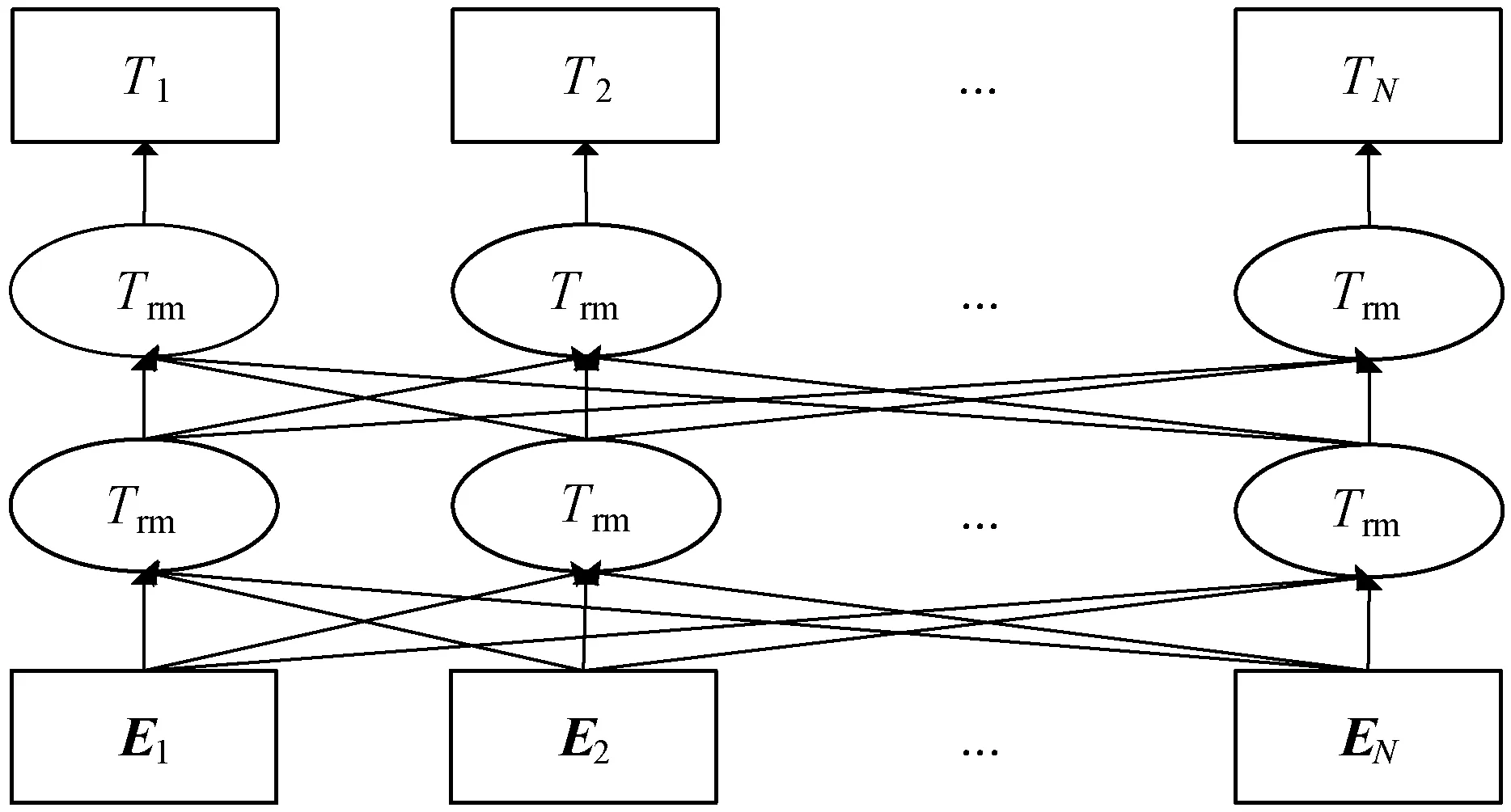
图2 多头自注意力机制
其中:EN表示加入了位置信息和句子切分信息的词向量,Trm表示训练模型Transformer,TN表示翻译译文。在基于多头自注意力机制预训练语言模型的框架中,其输入是加入了位置信息和句子切分信息的词向量EN,接着在多层Transformer上预测任务进行训练,称之为遮挡式语言模型(Mask Language Model,MLM)。此任务中,在输入词向量序列时,随机地使用标记MASK遮挡15%的词,然后通过训练来预测这些被遮挡的词是什么。
1.2 实验设置
首先对语料库进行预处理,使用词级粒度的方法对中文语料进行切分,再使用BPE进行子词级处理,学习到一个共享的蒙汉词汇表,将蒙汉语料库中共有的标记作为锚点来对齐两种语言的词向量空间,如数字和英文字母等,训练好一个跨语言词向量空间。接着借鉴MLM的方法进行语言模型建模,从BPE处理之后的文本中随机抽取15%的BPE标记,训练中80%的时间用MASK标签代替,10%的时间用随机的标记替换,剩余10%的时间保持正确的BPE标记不变。MLM预训练语言模型的过程如图3所示。
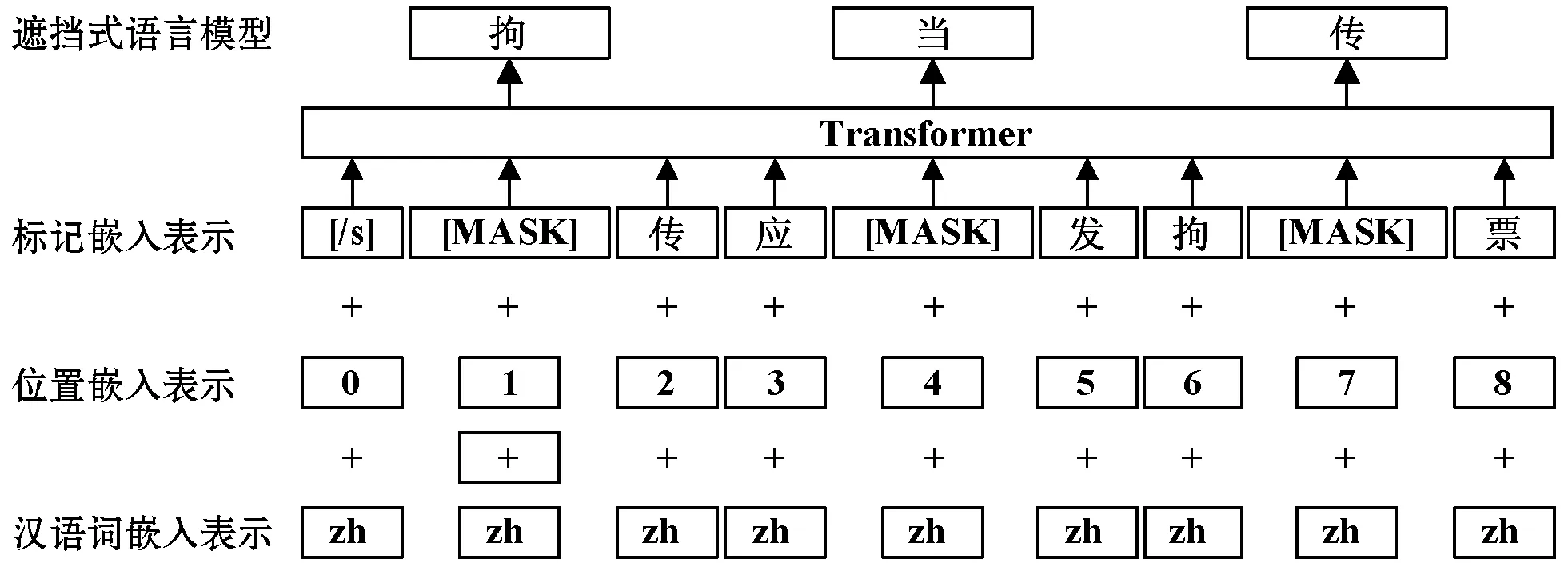
图3 MLM预训练语言模型的过程
实验环境配置为:Python 3.6.0,PyTorch 1.0.1,NumPy,fastBPE和Moses。
实验参数设置为:BPE codes数量设置为60 000,词向量的维度设置为512,Transformer的神经网络层数设置为6层,多头注意力机制设置为8头,droupout设置为0.1,注意力机制的droupout设置为0,激活函数使用GELU,batch_size设置为16,句子的最大长度设置为256,使用Adam优化算法,学习率lr设置为0.000 1,学习率衰减率设置为0,一阶矩估计的指数衰减率beta1设置为0.9,二阶矩估计的指数衰减率beta2设置为0.98,epoch_size设置为300 000,batch_size设置为16。
本文主要以内蒙古工业大学构建的123万句蒙汉对齐语料库中的蒙古语作为源语言端单语语料库,以全球AI挑战赛(AI Changer)中给出的1 000万句英汉对齐语料库中的汉语作为目标语言端单语语料库为研究数据。训练集均为123万句对蒙汉单语语料,验证集均为3 000句对蒙汉平行语料,测试集均为1 000句对蒙汉平行语料。
1.3 实验结果
实验的评测使用的是语言模型评测中常用的两个指标:语义困惑度(Perplexity,ppl)和准确率(Accuracy,acc)来判断的。ppl越小表示语言模型越好,而acc越高表示语言模型越好。
在整体预训练过程中,跨蒙汉语言模型的ppl和acc在测试上的变化趋势分别如图4和图5所示。
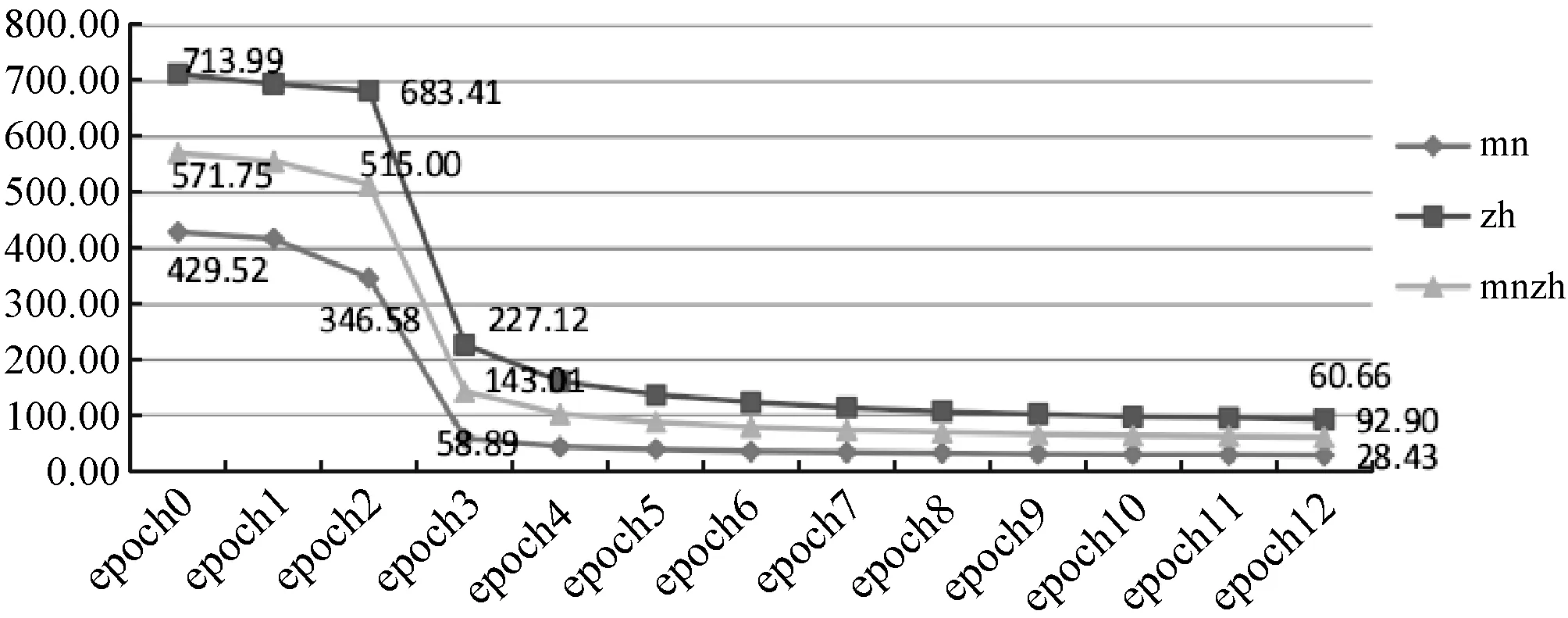
图4 语言模型的ppl变化趋势
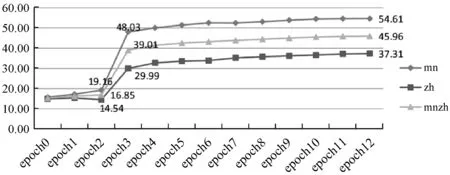
图5 语言模型的acc变化趋势
可以看出在epoch 3时训练结果有了很大的提升,而当到达epoch 10左右结果的变化开始趋于平缓。这说明基于自注意力机制的预训练语言模型的方法,训练速度还是比较快的。由于结果可以很快收敛,所以短时间内也可以预训练一个比较好的跨蒙汉语言模型。
2 基于预训练语言翻译模型的构建
本文总体技术路线图如图6所示,图中虚线框表示的部分即为语言模型预训练部分。将其添加到蒙汉语言模型之前对语言模型的参数进行初始化。
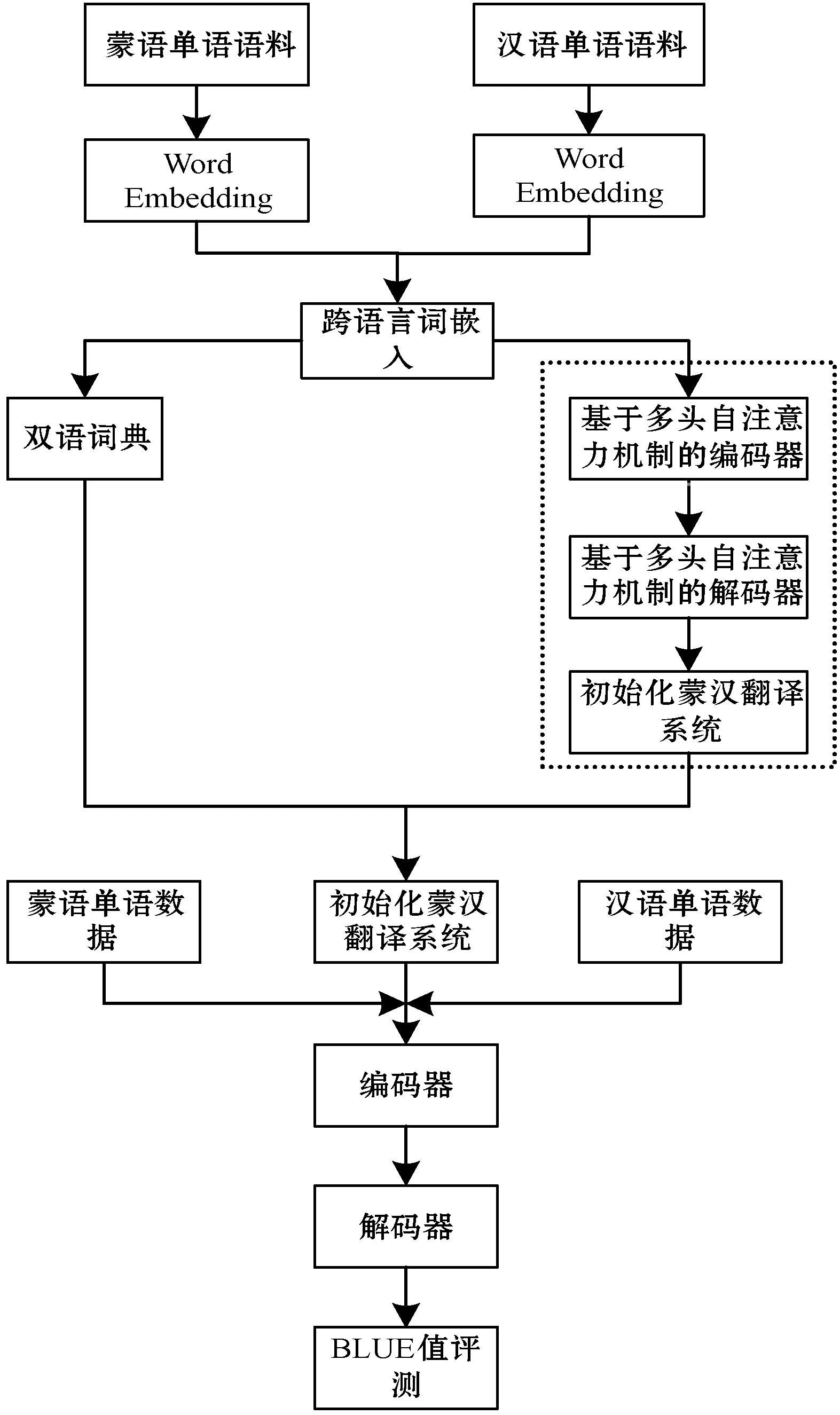
图6 预训练语言模型的蒙汉机器翻译总体技术路线图
2.1 实验设置
实验环境为Ubuntu 16.04的Linux系统,实验架构的基础为Pytorch,基于Facebook AI Research开源的框架XLM实现。参数设置如下:Transformer的神经网络层数设置为6层,多头注意力机制设置为8头,droupout设置为0.1,注意力机制的droupout设置为0,激活函数使用GELU,batch_size设置为16,句子的最大长度设置为256,优化函数使用Adam优化算法,学习率lr设置为0.000 1,学习率衰减率设置为0,一阶矩估计的指数衰减率beta1设置为0.9,二阶矩估计的指数衰减率beta2设置为0.98,epoch_size设置为300 000,batch_size设置为16,batch_size的最大值限定为64,实验终止条件设置为模型在验证集上10个epoch内不再发生改变。
2.2 实验结果
预训练语言模型的蒙汉机器翻译模型的BLEU值的变化趋势如图7所示。mn-zh表示蒙汉翻译模型的结果;zh-mn表示汉蒙翻译模型的结果;Test表示在测试集上的结果;Valid表示在验证集上的结果。
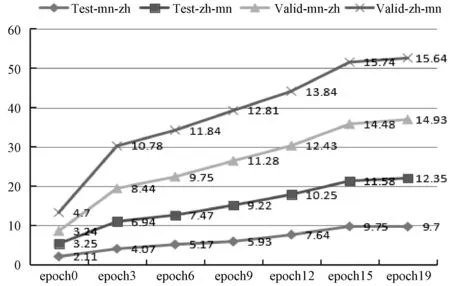
图7 预训练之后的BLEU值
如图7所示,预训练跨蒙汉语言模型之后,基于单语语料库训练的蒙汉机器翻译模型的BLEU值在20个epoch上呈现增长趋势,在测试集上蒙汉翻译性能于epoch17时表现最好,此时BLEU值为10.23,在验证集上蒙汉翻译性能于epoch19时表现最好,此时BLEU值为14.93。
3 平行语料改进预训练语言模型
本节考虑使用少量平行语料来改进蒙汉翻译模型。因为跨蒙汉语言模型和汉语语言模型在验证集中的ppl都很高,所以提出应用翻译语言模型(Translation Language Model,TLM)来改进跨蒙汉预训练。方法是在基于多头自注意力机制预训练语言模型的框架中加入另一个预测任务,此任务是预测下一个句子。在此任务中,一方面输入同属于一句话中的两个句子,将其视为正例;另一方面则输入两句不属于同一句话中的句子,将其视为反例,两方面的任务各占一半。那么整个语言模型预训练的目标函数就是将这两个任务求和之后再使用极大似然函数求值。为了预测被遮挡的蒙语,该模型可以同时处理蒙语句子和与它对应的汉语句子,并通过重置汉语句子中的位置嵌入表示以使得蒙语和汉语词嵌入表示进一步对齐。TLM预训练语言模型的过程如图8所示。实验设置同第2节一致,只是在数据集中添加了3万句对的蒙汉平行语料库作为训练集,平行语料的预处理方式同验证集和测试集一致。
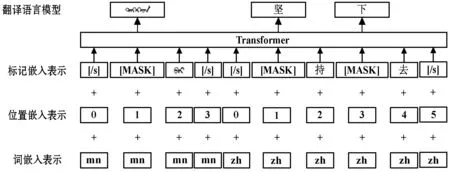
图8 TLM预训练语言模型的过程
加入TML预训练语言模型的蒙汉机器翻译模型的BLEU值的变化趋势如图9所示。
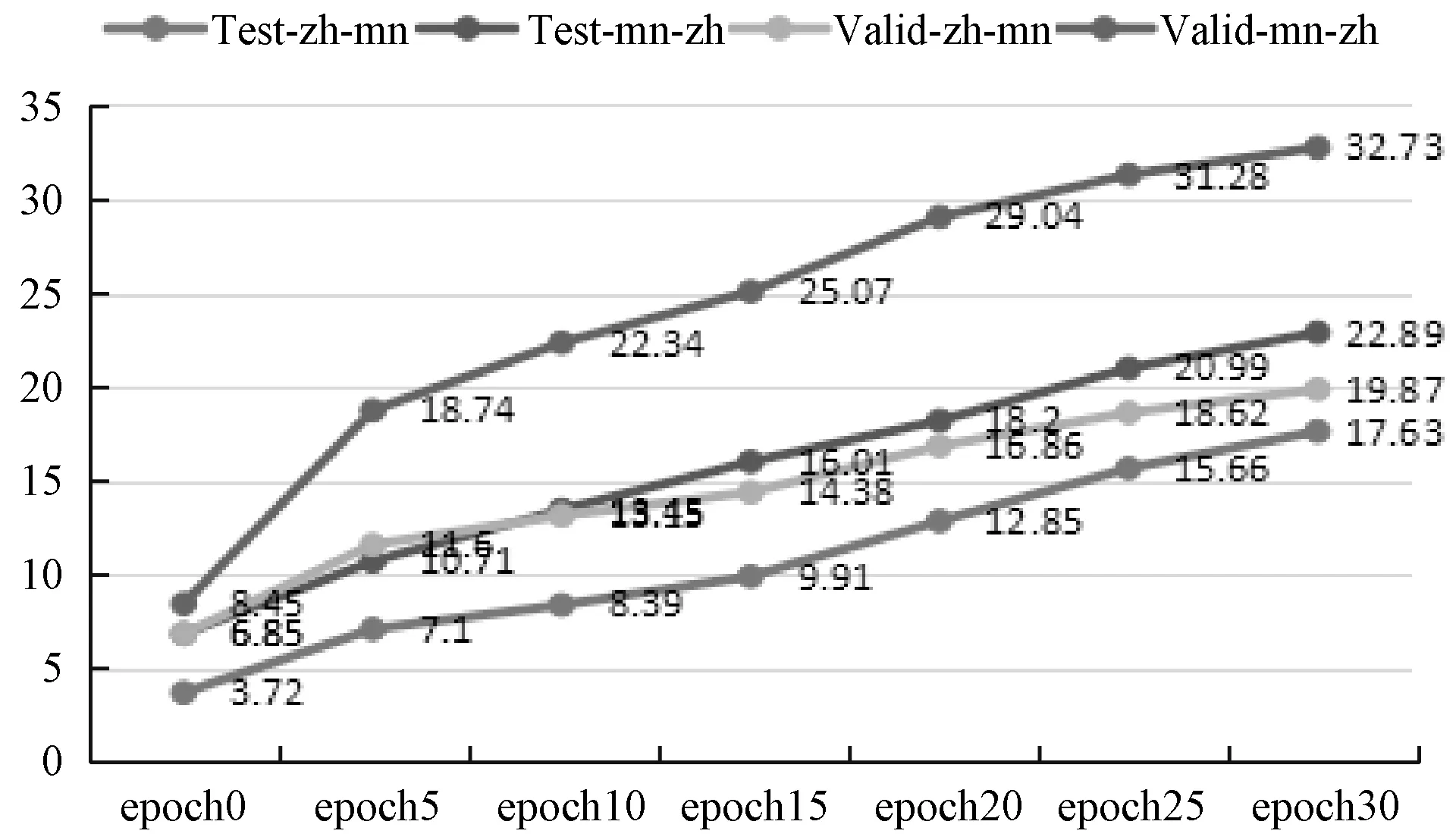
图9 添加TML后BLEU值的变化趋势
可以看出,添加TML之后,蒙汉机器翻译模型的BLUE值产生了较大幅度的提升,蒙译汉于测试集上在epoch 28表现最好,此时BLEU值为23.05,于验证集上也是在epoch 28表现最好,此时BLEU值为32.743。这证明加入平行语料库进一步促进了蒙汉词嵌入表示的对齐程度,提升了基于单语语料训练的蒙汉机器翻译系统的整体翻译性能。
4 实验结果分析
本文叙述了基于自注意力机制预训练跨蒙汉语言模型的方法以及添加少量蒙汉平行语料来进一步优化预训练语言模型的方法,并基于这两种方法构建了蒙汉翻译系统进行实验。将实验结果和基于单语语料库训练方法进行了对比,统计到三组实验在20个epoch上测试集的ppl和BLEU如表1所示,其相应的变化趋势如图10所示。
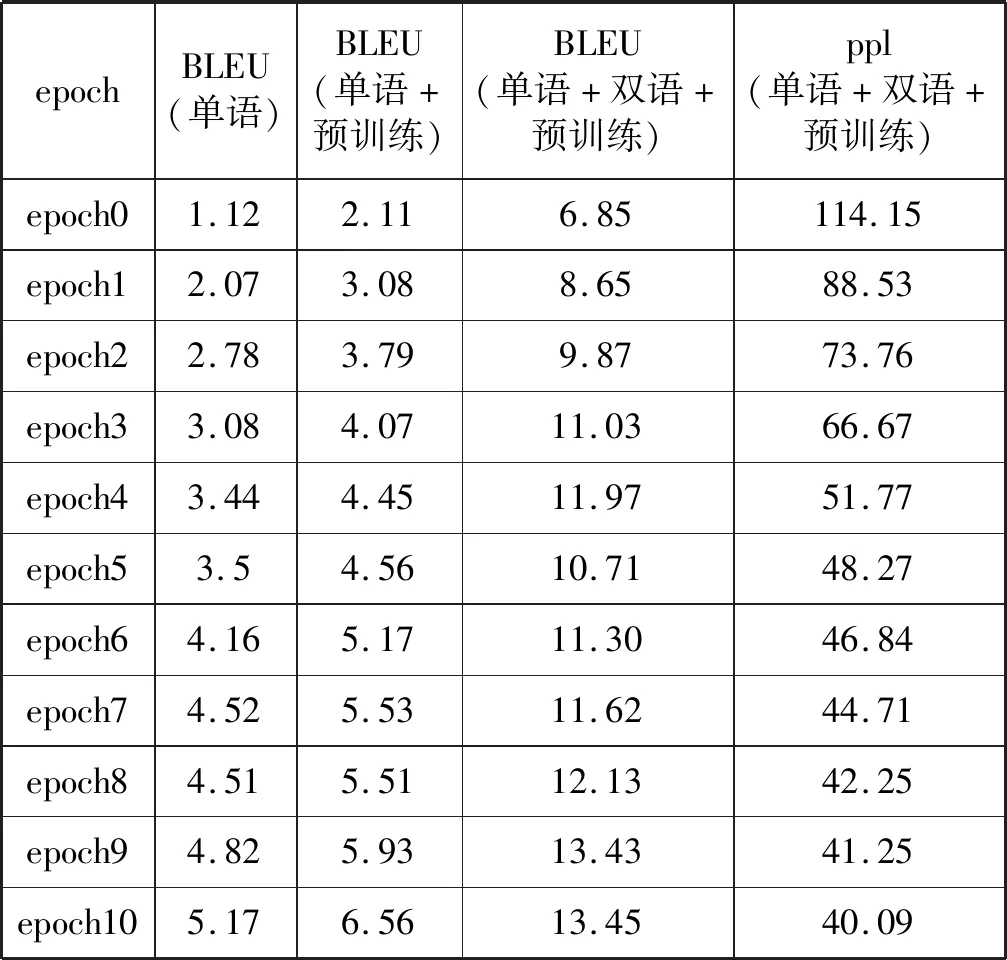
表1 三组实验结果
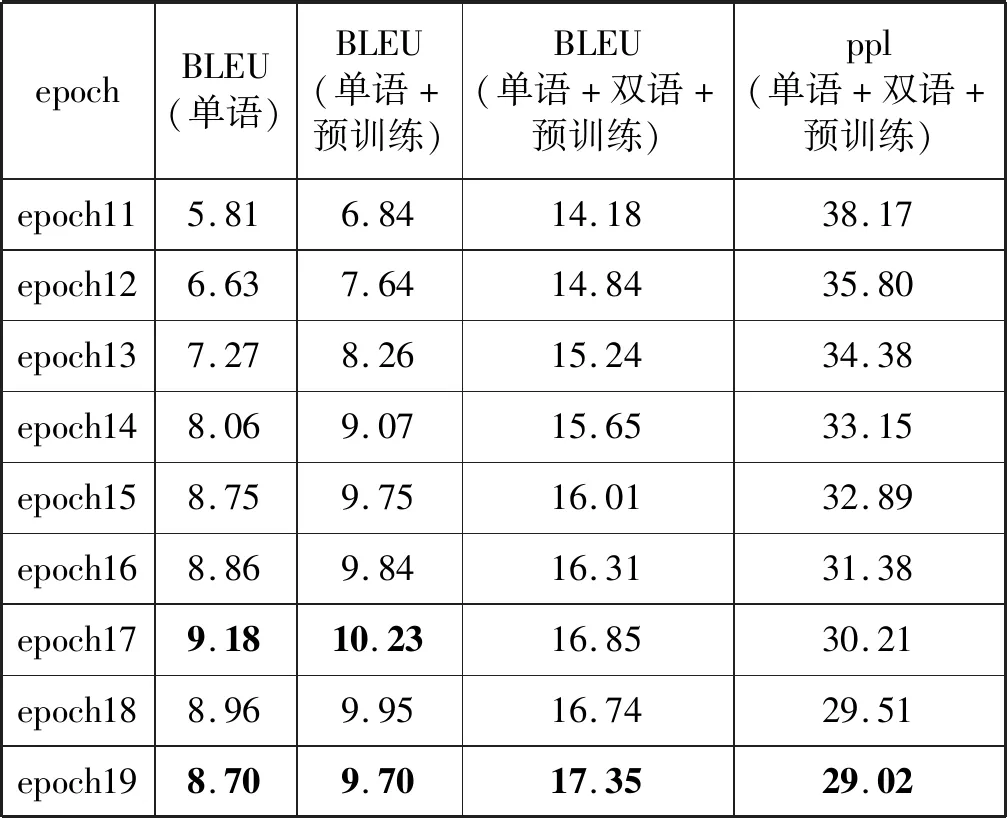
续表1
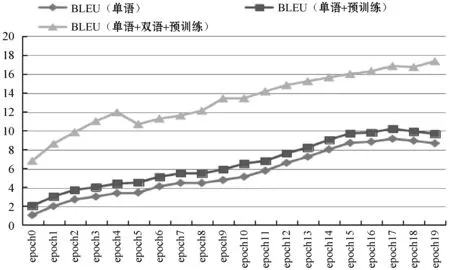
图10 三组实验BLEU值变化趋势
可以明显地看出,在语料库相同的情况下,预训练跨蒙汉语言模型的方法结果表现较好,说明语言模型对于基于单语语料库训练的蒙汉机器翻译性能有很大的影响,预训练跨蒙汉语言模型能够在一定程度上改善其翻译质量。通过对比实验证实了融合单语和双语语料预训练语言模型提升基于单语语料库训练的蒙汉机器翻译的可行性。三组实验训练出的最优BLEU值如图11所示。
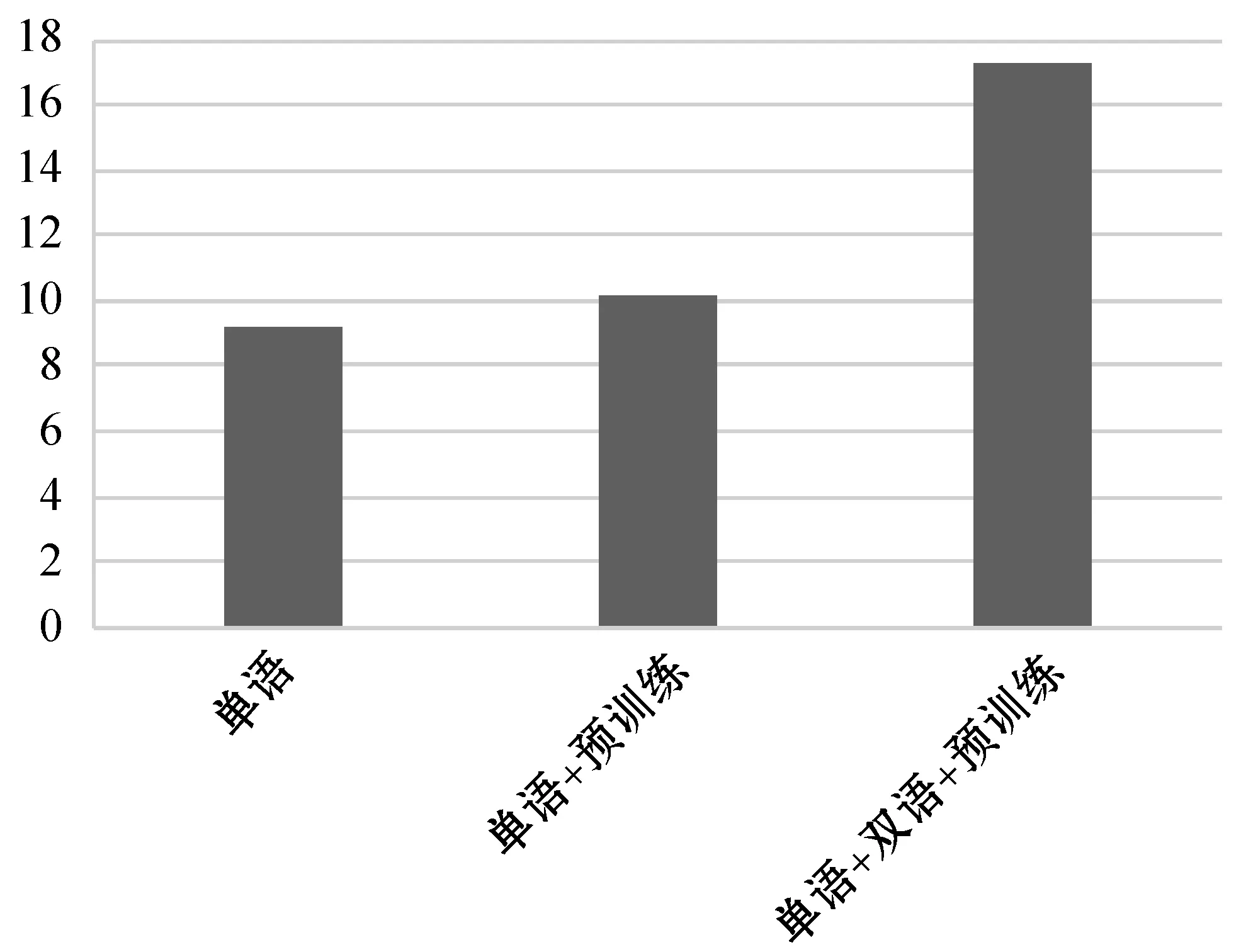
图11 最优BLEU值
基于单语语料库训练的蒙汉机器翻译系统在不同的epoch上翻译的测试语句如表2和表3所示。

表2 短句翻译模型测试
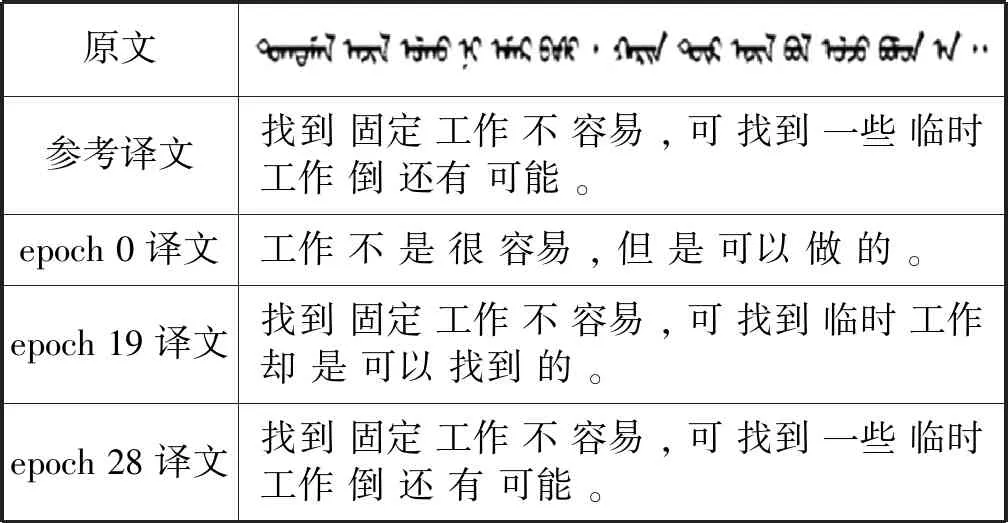
表3 长句翻译模型测试
如表2和表3所示,模型通过不断地学习最终可以将原句子表达的意思准确地翻译出来,而且在没有准确翻译出来时也没有出现UNK,而是使用了和原文中词语意思较为接近的词来代替。
5 结 语
本文主要介绍了预训练思想和基于自注意力机制预训练跨蒙汉语言模型的方式以及基于此方法设置的实验,并将实验所得的跨蒙汉语言模型应用于基于单语语料库训练的蒙汉机器翻译系统中。最后,通过和基于单语训练的蒙汉翻译模型的实验结果做对比。基于自注意力机制预训练跨蒙汉语言模型的方法极大地改善了蒙汉机器翻译系统的性能。究其原因,其一是自注意力机制能够学习整个句子中每一个词之间的关系,可以更好地学习到上下文的信息;其二是预训练的方法可以对参数进行有目的的初始化;其三是使用了少量的蒙汉平行语料库进一步提升了语言模型的准确率以及蒙汉词嵌入表示的对齐程度。
