基于改进TF-IDF算法的牛疾病智能诊断系统
2021-02-25杜永兴牛丽静李宝山
杜永兴 牛丽静 秦 岭 李宝山
(内蒙古科技大学信息工程学院 内蒙古 包头 014010)
0 引 言
计算文本相似度是研究疾病智能诊断的一种重要的方法。目前VSM空间向量模型和TF-IDF方法提取关键词技术广泛应用在人病智能导医系统中。林予松等[1]采取了用户关注度来计算症状的权重,设计了人工智能导医系统。徐奕枫等[2]提出基于疾病类间分布的症状权重改进算法,改善了传统TF-IDF算法提取疾病的效果,取得了不错的成绩。Teshnehlab等[3]首先通过主成分分析减少特征,然后使用基于深度神经网络算法对结肠癌分类,其分类准确度为0.6。Cheng[4]通过物联网和人工智能自动化设计一个可以及时解决动物园里的动物身体出现异常情况的系统,帮助动物管理员更系统地管理照顾动物。以上系统的设计都有着显著的成果,但它们需要用户在系统中选择相应的症状,不能实现对用户所输入的文本内容进行理解。在设计中实现理解用户输入内容的复杂度远高于直接选择症状。在对用户描述进行关键词提取时,用传统的TF-IDF算法在疾病的关键词提取中并未考虑到提取的权重比较高的关键词是否能合理地表示某种疾病。
针对上述问题,本文提出改进的TF-IDF算法,并将该算法应用在牛的疾病诊断系统中。首先用已有的方法对用户的输入的文本内容进行分词、提取关键症状词。然后采用向量空间模型VSM将提取的关键词用向量的形式表示,用余弦定理计算用户输入的关键词向量和已有的疾病关键词向量的值作为疾病的相似度。最后进行可信度的计算,推断出牛所患的疾病。应用该算法提取的关键症状词可以比较合理地表示疾病的症状,提高了系统的性能,使得该系统有效地实现了对牛所患疾病及时的诊断和治疗,对牧户在畜牧业的管理上也起到一定的指导和决策作用。
1 数据来源
应用Python框架和手工录入方式获取了451种关于牛的疾病,采用jieba分词[5]和手工整理的方式对病因、症状、诊断、治疗和预防等属性拆分,并将其对应的症状进行规范化处理,构造关键症状词语料库。
2 方法设计
2.1 空间向量模型及相似度计算
目前常用空间向量模型的方法来衡量两个文本之间的相似度[6]。向量空间模型(VSM)是把输入的文本和已有的文本都转换成向量的形式进行计算,提高了文本内容的计算性和可操作性,同时该模型也是目前应用最为成熟和广泛的模型之一[7-8]。
假设某用户描述用D(Document)表示,首先运用自然语言处理已有的技术对用户的描述进行分词、去停用词、计算权重、提取关键症状词。特征项一般由症状关键词组构成,指在文档中能反映用户描述的基本语言单位,用T(Term)表示。用户描述和关键症状特征可以使用集合表示为D(T1,T2,…,Tn),其中Tk是关键症状特征词(1≤k≤n)。生成向量空间模型的流程如图1所示。

图1 生成向量空间模型的流程
利用空间向量模型将文本内容转换成向量可以这样表示:对用户输入的文本m中的每个词,用Wi,m表示m中第i个词的权重,m=(W1,m,W2,m,…,Wt,m)表示用户输入文本m的词权重向量;同理,用Wi,n表示已有文本n中第i个词的权重,用n=(W1,n,W2,n,…,Wt,n)表示已有文本n的词权重向量,然后通过余弦定理计算m和n之间的相似度值作为两个文本之间的相似度[9-11]。其中症状权重W是根据TF-IDF原理计算出来。在本系统中m表示带匹配的疾病,n表示用户输入的描述。相似度计算如下:
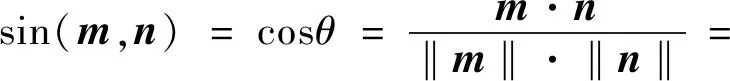
(1)
2.2 TF-IDF算法分析及改进
在利用VSM计算两种疾病的相似性度时,最重要的步骤是用TF-IDF算法计算关键症状词的权重,提取关键词[12-13]。TF-IDF算法的原理是TF×IDF,其中TF表示某个症状词在文档出现的频率,计算中发现像“的”“了”等这些不重要的停用词出现的次数比较高。为避免这种问题,引入逆文档频率IDF。包含当前词的文档个数越多,IDF的值越小,说明该词越不重要。其主要思想是如果某个特征项在一个文本中出现频率很高,且在其他文本中出现很少,说明此特征项具有很好的类别区分能力,应该给予较高的权重[14]。TF计算如下:
(2)
式中:Cin表示疾病特征词i在n种描述中出现的次数;Mn表示n种描述中总症状词数。IDF计算如下:
(3)
式中:将每个描述看成一个文档,N为文档总数;n为包含某项症状词的文档总数。TF-IDF计算公式如下:
TF-IDF=TF×IDF
(4)
将传统的TF-IDF算法应用在提取牛疾病的关键症状词时,发现“带有”“比较”“基本”“而”等词计算出来的权重很高。显然这些词作为疾病的关键症状是不合理的。分析原因如下:在计算某一种疾病的关键症状时,将同一种疾病的不同种医案描述作为不同的文档来计算关键症状。此时的用户描述除了停用词出现的次数比较多之外,剩下的是症状描述,比如“精神倦息”“不反刍”等症状词,虽然很重要但是由于在每个用户描述中几乎都有出现,根据TF-IDF原理就把此类经常出现的症状词当成停用词处理了。针对上述问题,本文提出基于改进的TF-IDF算法,可以有效解决这个问题。改进的TF-IDF计算式如下:

(5)
式中:Wij代表第j种疾病的i个症状。首先通过传统的算法算出关键词的权重,然后将提取的关键词和牛疾病症状词典进行匹配。如果该词在症状词典中,则将该词相应的权重乘以10;如果该词不在症状词典中,保留其原始的权重不变。最后将关键词的权重重新排序,选择权重较高的前20个关键词作为疾病的关键症状词。使每种疾病的关键症状权重更具有代表性,实现了相同症状在不同疾病占有不同的权重,更适用于疾病诊断。
2.3 可信度计算
单纯将相似度作为最后的结果返回给牧民是不够准确的。把可能度和相似度相结合作为疾病可信度计算结果,然后将可信度的结果按照从高到低的次序返回给牧民,增强结果的可靠性。可能度的计算使用的是不确定的推理,当用户输入描述时,将相应的症状权重相加。可能度的计算如下:
kndj=W1jx1+W2jx2+…+Wijxn
(6)
式中:kndj代表患某种疾病的可能度。将选中的疾病索引到对应的权重进行加权求和,最后进行可信度的计算如下:
CF=αkndj+βsim(m,n)α+β=1
(7)
式中:α取0.2,β取0.8进行最后的可信度计算。
2.4 系统设计流程
牛的疾病诊断系统主要运用智能化方式辅助兽医诊断。牧民在使用此系统时,输入相应症状的文本内容,系统首先会对输入的文本内容进行理解,然后计算出输入内容与系统内所有疾病的相似度,最后计算可信度。将查询结果按照可信度从大到小的返回给牧民,并给出相应的诊疗方案。牛疾病智能诊疗系统主要包括自然语言处理、疾病匹配处理、疾病可信度计算三个部分。具体系统设计流程如图2所示。
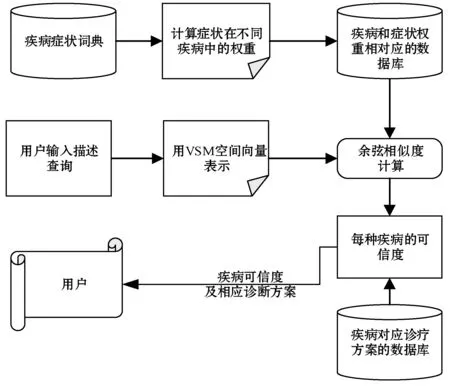
图2 牛的疾病诊断流程
3 实 验
3.1 实验环境和实验数据
实验的运行环境为Windows XP操作系统,CPU主频3.7 GHz,内存16 GB,数据库Microsoft MySQL 2018,开发工具为PyCharm 2018,编程语言为Python。实验数据采取随机抽取30头牛的病历样本进行实验验证,且这些疾病兽医已经给出正确的诊断结果。
3.2 评价指标
为验证改进后的算法在牛疾病诊疗系统中的准确率和可信度,本文采用基于传统的空间向量模型的相似度算法和本文提出改进的TF-IDF算法进行对比实验。实验采用随机抽取30头牛的病历样本进行实验验证,采用S@n(success atn) 方法进行结果评测[15],其表示正确疾病推荐结果在前n个推荐结果中所占比重。
3.3 结果分析
将实验数据采用S@n方法进行结果评测,两种算法的对比结果如表1所示。可以看出,当n取1、2、3时,本文算法的正确率明显高于传统算法。
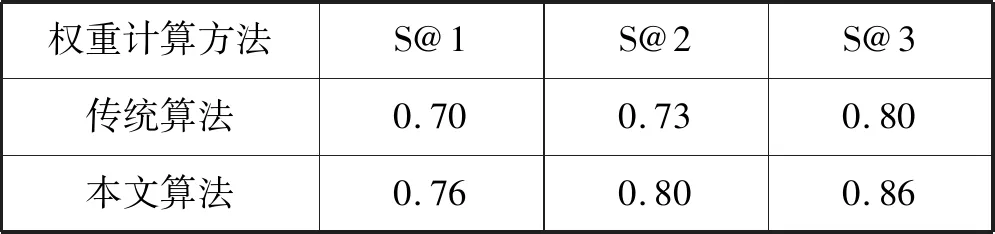
表1 算法准确率对比
通过上述计算相似度及可信度的方法,使用两种算法对同一实验数据计算出相似度和可信度的对比如图3和图4所示。可以看出,改进算法相似度和可信度较传统算法都有提高,其中可信度平均提高约4个百分点,说明本文算法在牛疾病诊断中更具有可行性。
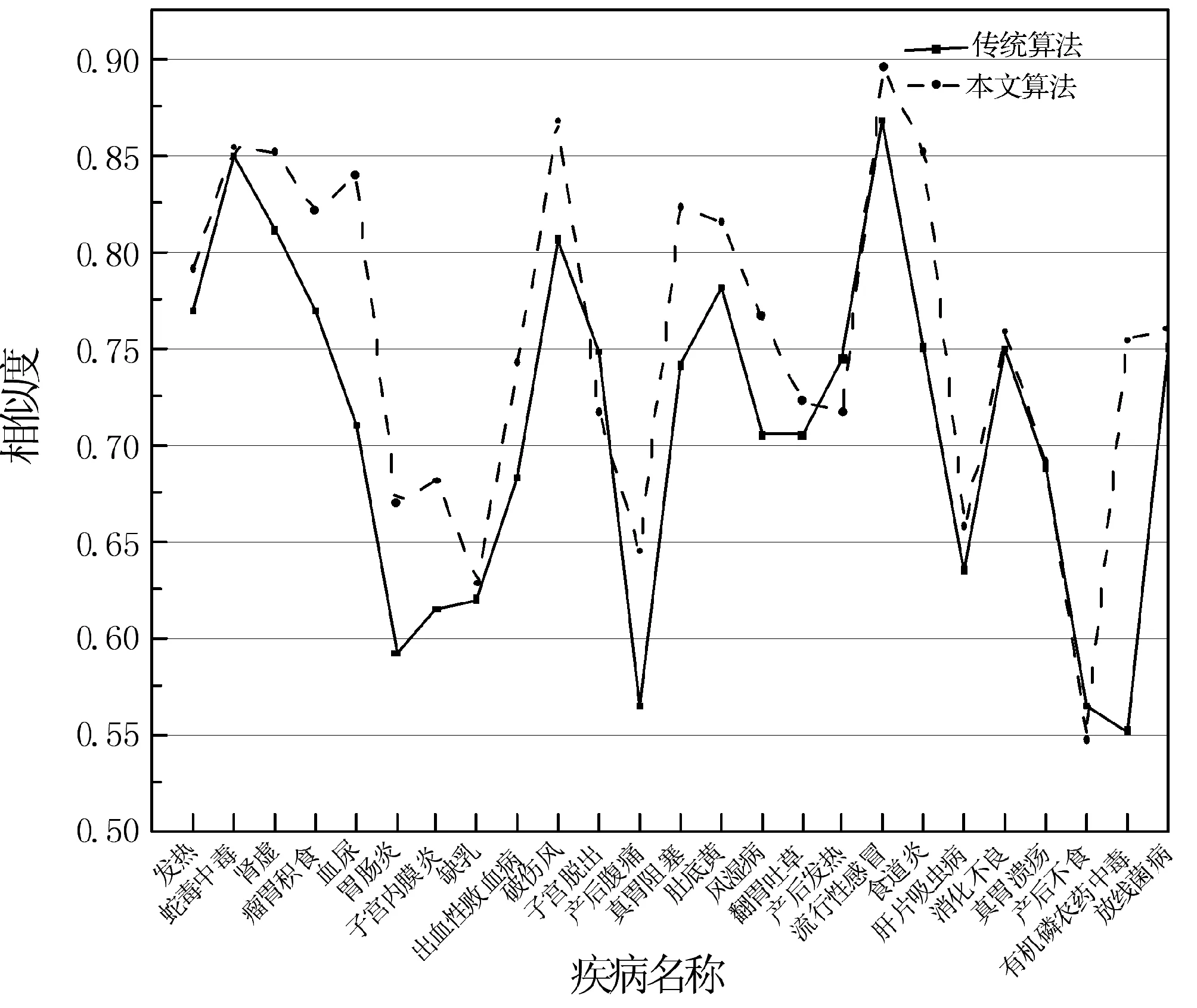
图3 相似度结果对比图
4 结 语
针对传统TF-IDF算法提取关键词不能合理地描述疾病的关键症状,本文提出一种改进的TF-IDF算法提取关键症状词并设计了牛疾病智能诊断系统。通过实验对比验证了该算法的有效性。该方法的不足是在提取关键症状词时依赖疾病症状词的语料库。下一步研究将重点考虑在不依赖疾病症状词语料库的基础上更加智能地实现疾病诊断。
