基于卷积神经网络和双向门控循环单元网络注意力机制的情感分析
2021-02-24刘新亮高彦平
张 腾,刘新亮,3,高彦平*
(1.北京工商大学计算机与信息工程学院,北京 100048;2.农产品质量安全追溯技术及应用国家工程实验室,北京 100048;3.中国农业大学信息与电气工程学院,北京 100083)
随着互联网的高速发展,越来越多的用户通过社交媒体表达自己的观点、抒发自己的情感评论,其中大多数评论以短文本的形式存在。热点事件会引起社会的广泛关注讨论,所以及时掌握舆情、获取用户情感倾向是一个极具挑战性的任务。
情感分析通过对文本的预处理,分析和挖掘用户的情感倾向,可以了解大众对热点事件的情感变化,也是自然语言处理的重要方向之一。情感分析研究方法主要分为基于构建情感词典的词典方法[1],基于规则融合的机器学习方法[2]和深度学习方法。基于构建情感词典的词典方法主要依赖于词典的构建与选择判断句子情感极性,不同的词语有着不用的情感积分,对句子情感分类的贡献度不同,但因其领域适应性较差,通常作为辅助方法。基于机器学习的方法依赖选取有效特征组合,利用分类器进行情感分类,但这种方法需要大量人工标注数据集来训练模型,费时费力。基于深度学习的方法,可以挖掘深层的情感信息,Jeffrey于20世纪90年代提出了循环神经网络(recurrent neural network,RNN)[3],该网络处理时序性数据效果显著,但是会出现特征梯度消失或爆炸问题。Hochreiter等[4]提出了长短时记忆网络(long short-term memory,LSTM),该网络通过加入输入门、遗忘门和输出门,改善了循环神经网络梯度消失或梯度爆炸问题,但结构复杂运算量过大。Bahdanau等[5]在处理机器翻译时引入自注意力机制,其翻译准确率显著提高。Liu等[6]将双向LSTM(BiLSTM)与自注意力(self-attention)结合起来做文本分类,但是忽略了情感词自身情感信息。姜同强等[7]将BiLSTM与注意力机制用于食品安全裁减文书分类,忽略了否定词、程度副词和转折词对于判断句子极性的重要性。
针对以上问题,现提出在CNN和双向门控循环单元(bi-directional gated recurrentunit,Bi-GRU)基础上,利用情感积分来区别不用情感词所表达的情感程度,将其融入卷积网络;对影响句子极性的否定词、程度副词和转折词通过Bi-GRU注意力机制深入获取句子表征,最终得到较高的准确率。
1 相关工作
1.1 全局向量的词嵌入
短文本需要映射为向量才能作为神经网络的输入,即文本向量化。将短文本以词为单位划分,每个词都有相应的向量表示。
文本向量化的方法主要分为两种:one-hot向量(one-hot representation)和词嵌入(word embedding)。one-hot向量将词表示成一个长度为N(词典中不同词的数量)的向量,这种方法构造起来容易,但无法表达出不同词之间的相识度,即相关性太差。词嵌入可以解决这个问题,它将每个词表示成相同维度的向量,且不同向量之间可以较好地表达不同词之间的相似关系。词嵌入包含连续词袋模型(continuous bag of words,CBOW)[8]和跳字模型(skip-gram)[9]。CBOW原理是基于某个中心词在文本序列周围的词来生成该中心词,跳字模型原理是基于某个词生成该词在文本序列周围的词。此处使用的是全局向量的词嵌入(global vectors for word representation,GloVe)模型,GloVe模型由Pennington等[10]在2014年提出,该模型在跳字模型上使用平方损失,使用背景词向量和中心词向量的和作为改词最终词向量。
1.2 门控循环网络
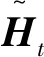

图1 GRU网络内部结构图Fig.1 GRU network internal structure
2 基于Bi-GRU与CNN结合的网络模型
本节将详细介绍基于Bi-GRU与CNN结合的网络模型,如图2所示,对短文本预处理,除噪、分词、词性标注、去除停用词;通过全局向量的词嵌入(GloVe)将句子映射为一个特征矩阵;计算情感词情感积分,利用情感积分来区别不用情感词所表达的情感程度,将其融入卷积网络;词嵌入与特征嵌入拓扑作为卷积神经网络输入,通过卷积、池化得到句子表征;对影响句子极性的否定词、转折词和程度副词通过Bi-GRU网络注意力机制模型,参数查询项为否定词、转折词和程度副词注意力机制获取表征;两种表征拓扑结合作为全连接层输入,输出情感分析结果。
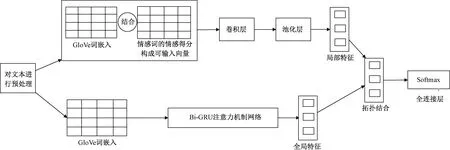
图2 基于Bi-GRU与CNN结合的网络Fig.2 Network based on the combination of Bi-GRU and CNN
2.1 任务分析
对于给定短文本进行情感分析,即将句子以词为单位进行分词,进而文本向量化输入Bi-GRU与CNN结合的网络模型提取特征,输出分类结果。情感中性对于研究意义不大,将情感划分为积极情感和消极情感。例如短文本“不是说好的么,怎么又变卦了!”,利用模型判断此短文本情感是积极还是消极。
2.2 词嵌入
使用GloVe模型对文本进行编码,即每一个词va都会由一个多维的向量qi表示,GloVe模型的最小化损失函数为
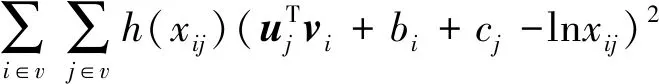
(1)
式(1)中:xij为整个数据集所有以wi为中心词的背景窗口里词wj的个数;词为背景词时,向量表示为uj∈Rd;词为中心词时,向量表示为vi∈Rd;bi为中心词偏差项;cj为背景词偏差项;权重函数h(x)为单调递增函数,值域为[0,1],公式为
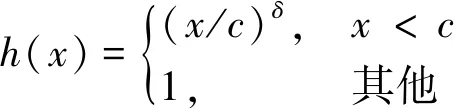
(2)
式(2)中:δ为偏置项。
2.3 情感词情感得分
对短文本进行情感分析是根据句中词信息进行特征提取,尤其是情感词,情感词带有很强的感情色彩,对情感归类至关重要。例如“我非常喜欢这款电脑,配置一流”,句中“喜欢”即是重要情感词,根据情感词在不同数据集文档出现频数计算情感分值,继而转化成特征向量,计算公式为
F(wi)=|αNTwi-βNFwi|
(3)
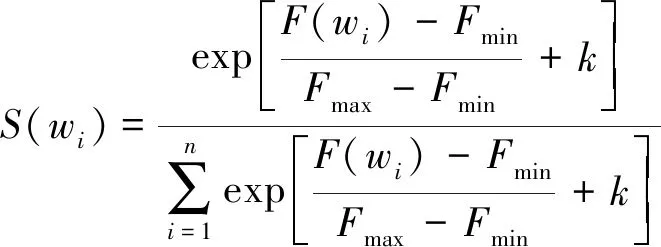
(4)
式中:使用Hownet情感词典计算情感积分,wi为Hownet情感词典中第i个词;F(wi)为包含情感词wi短文本个数,其中Fmin为最小个数,Fmax为最大个数;积极数据中包含词wi的短文本个数为NTwi,消极文本中包含词wi的短文本个数为NFwi;α、β、k为可变参数;情感词wi的情感积分为S(wi);每个情感词wi的情感积分S(wi)都能用一个多维向量e(wi)表示,若wi词为情感词,将词嵌入与情感积分相结合为
xi=qi⊕qi·e(wi)
(5)
2.4 注意力机制
短文本中的否定词、转折词和程度副词会使句子极性发生偏移,例如“这手机看着还不错,但是用起来特别卡”,这时学习句子特征重点在于“但是”之后的表达,而不是过多关注“不错”,因此在模型中需要重点关注否定词、转折词和程度副词这类影响句子极性词才能取得更好的分类结果。如图3所示,引入注意力机制,将参数查询项设为否定词、转折词和程度副词。
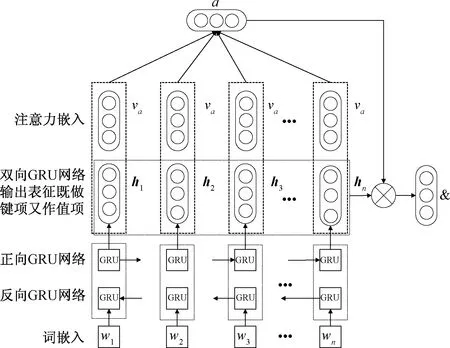
图3 Bi-GRU网络注意力机制模型Fig.3 Bi-GRU network attention mechanism
词嵌入表征经过Bi-GRU网络输出句子的隐含层表征向量h。在Bi-GRU循环网络中对于每一个输入wi都有输出h,即
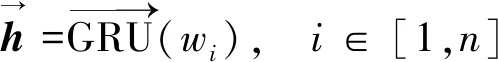
(6)
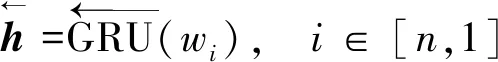
(7)
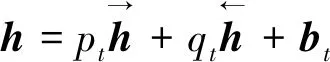
(8)
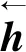
将否定词、转折词和程度副词作为参数化查询项va,由Bi-GRU网络输出的句子表征和参数化查询项va得到M,由M和参数化查询项va得到特征权重αi,最终由特征权重αi和Bi-GRU网络输出的句子表征hi得到关于否定词、转折词和程度副词作为参数化查询项注意力机制的特征向量&。
M=tanh(wshi+wtva)
(9)
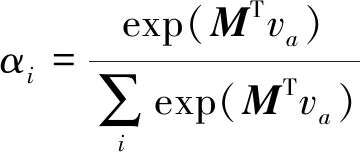
(10)

(11)
式中:ws为特性向量hi的可调节权重矩阵;wt为参数化查询项va的可调节权重矩阵;MT为权重矩阵M的转置矩阵。
2.5 特征接合与模型训练
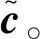
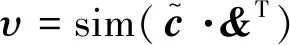
(12)
ζ=&+υ·&
(13)
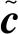
p=softmax[wp×ζ+δ]
(14)
式(14)中:wp为权重矩阵。将反向传播算法应用于模型迭代,使用最小化交叉熵损失函数进行模型优化。损失函数为
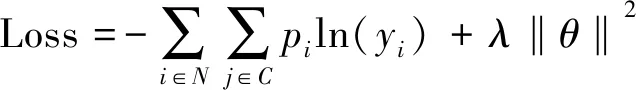
(15)
式(15)中:N为短文本数量;C为类别数量;pi为实际类别;yi为预测类别;λ‖θ‖2为交叉熵正则项。
3 实验结果和分析
3.1 实验数据
数据集一部分选自中文倾向性分析评测(COAE2014)任务4中的识别观点句数据集中5 078条含有极性转移的数据,在此基础上又在不同领域爬取了2 243条微博语料数据进行人工标注。其训练集、验证集、测试集数分别为4 706、894和1 721。表1为数据集样例。

表1 COAE2014数据集经典样例Table 1 Classic example of COAE2014 dataset
3.2 实验参数设置
使用GloVe方法训练词向量,其中词向量维度设为200,损失函数中参数c取值为100,δ取值0.75最佳,对于情感积分中α和β的取值,取值过小就无法反映情感词自身的情感特性,取值过大映射复杂影响整体网络分类效能。在CNN中多窗口卷积大小为3、4、5,每个窗口卷积核的个数均为100。为防止过拟合,采用丢弃机制,丢弃值设为0.5[11],如表2所示。

表2 模型参数Table 2 Parameters of model
3.3 对比实验
为了验证本文模型的有效性,通过在现有的5 078条COAE2014数据和2 243条微博语料的基础上进行几组实验进行性能对比。评价指标采用的是通常使用的准确率(P)、召回率(R)和F值(F-score),准确率评估的是查准率即分类正确数占该分类总数的比率,召回率评估的是查全率即正确分类占该类原有总数的比率,F值是准确率和召回率的调和均值也是综合评价指标。

(16)
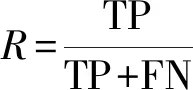
(17)
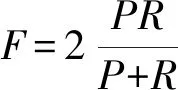
(18)
式中:TP为预测为积极,实际为积极;FP为预测为积极,实际为消极;FN为预测为消极,实际为积极。
为了验证模型的有效性,按照表2中的模型参数,在相同的实验环境下,将本文模型与其他模型进行对比,结果如表3所示。
(1) CNN[12]:不加入情感积分单纯的CNN网络进行情感分类。
(2) WCFCNN[13]:利用情感词典中的词条对文本中的词语进行抽象表示,使用词嵌入跳字模型(skip-gram)训练词向量,结合卷积神经网络进行情感分析。
(3) MF-CNN[14]:将情感词的情感积分和权重作为CNN网络的输入进行情感分类。
(4) Bi-GRU-Attention[15]:BiGRU神经网络层获取到短文本情感信息,注意力机制层对文本深层次信息分配相应的权重放入softmax层进行情感分类。
(5) Bi-GRU-M-CNN:在本文模型基础上保留情感积分,去掉关于否定词、转折词和程度副词的注意力机制层。
(6) Bi-GRU-Att-CNN:本文模型基于卷积神经网络和双向门控循环网络注意力机制的短文本情感分析方法。使用GloVe训练词向量,在卷积神经网络的基础上引入情感积分,充分利用情感词自身信息,通过双向门控循环网络获取全局特征,对影响句子极性的否定词、转折词和程度副词引入注意力机制实现对这类词的重点关注,保留重要信息。
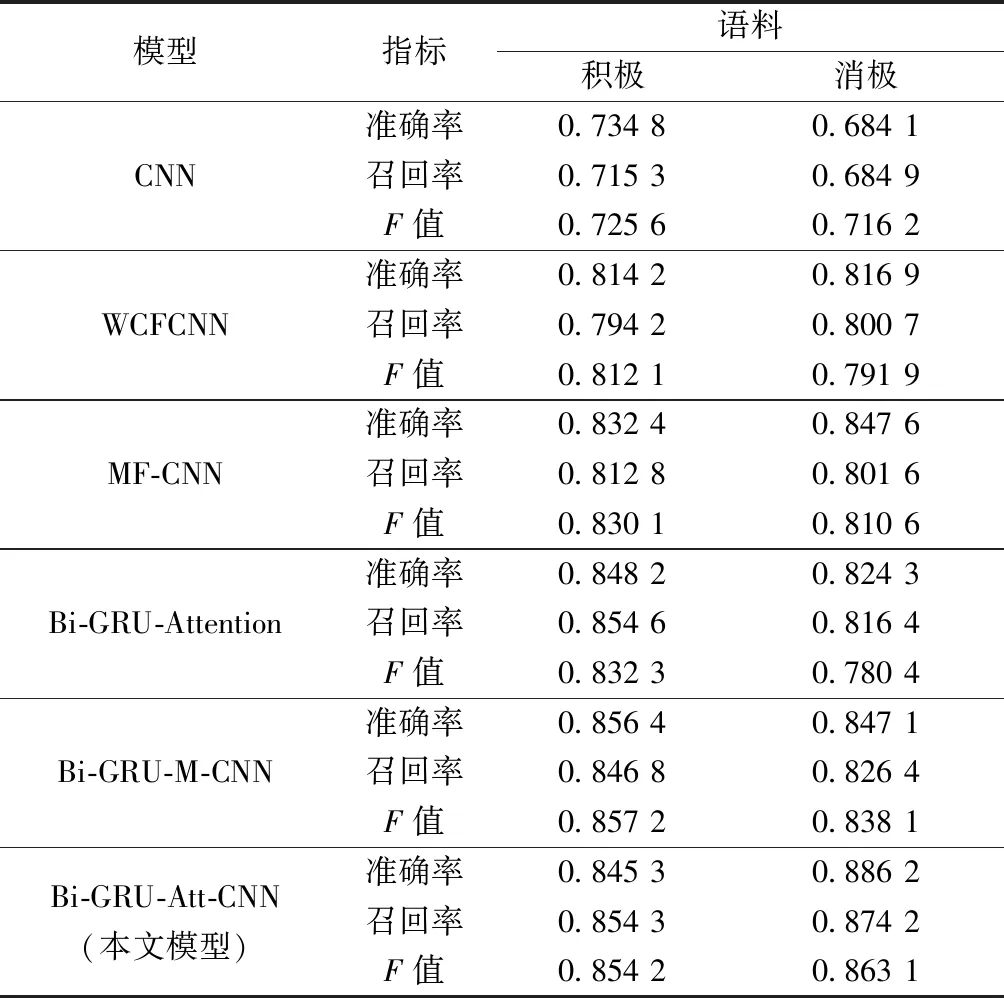
表3 6种模型情感分类结果对比Table 3 Comparison of 6 models’ sentiment classification results
3.4 实验结果分析
根据各模型实验结果,将反映各模型性能的综合评价指标F值做对比,如图4所示。总体来看,模型1~5各自在积极语料的表现优于在消极语料上的表现,BiGRU-Att-CNN 模型在消极语料下的性能优于积极语料,这是由于积极语料只要确定情感词的极性获取句子特征就可以很好地进行情感分类,相应的消极语料句中包含了否定词、转折词和程度副词,情感词有消极的和积极的,模型在学习句中特征时不能很好地确定哪些主要情感词决定句子极性,本文模型对影响句子极性的否定词、转折词和程度副词引入注意力机制实现对这类词的重点关注,因而在消极语料中有较好的表现。
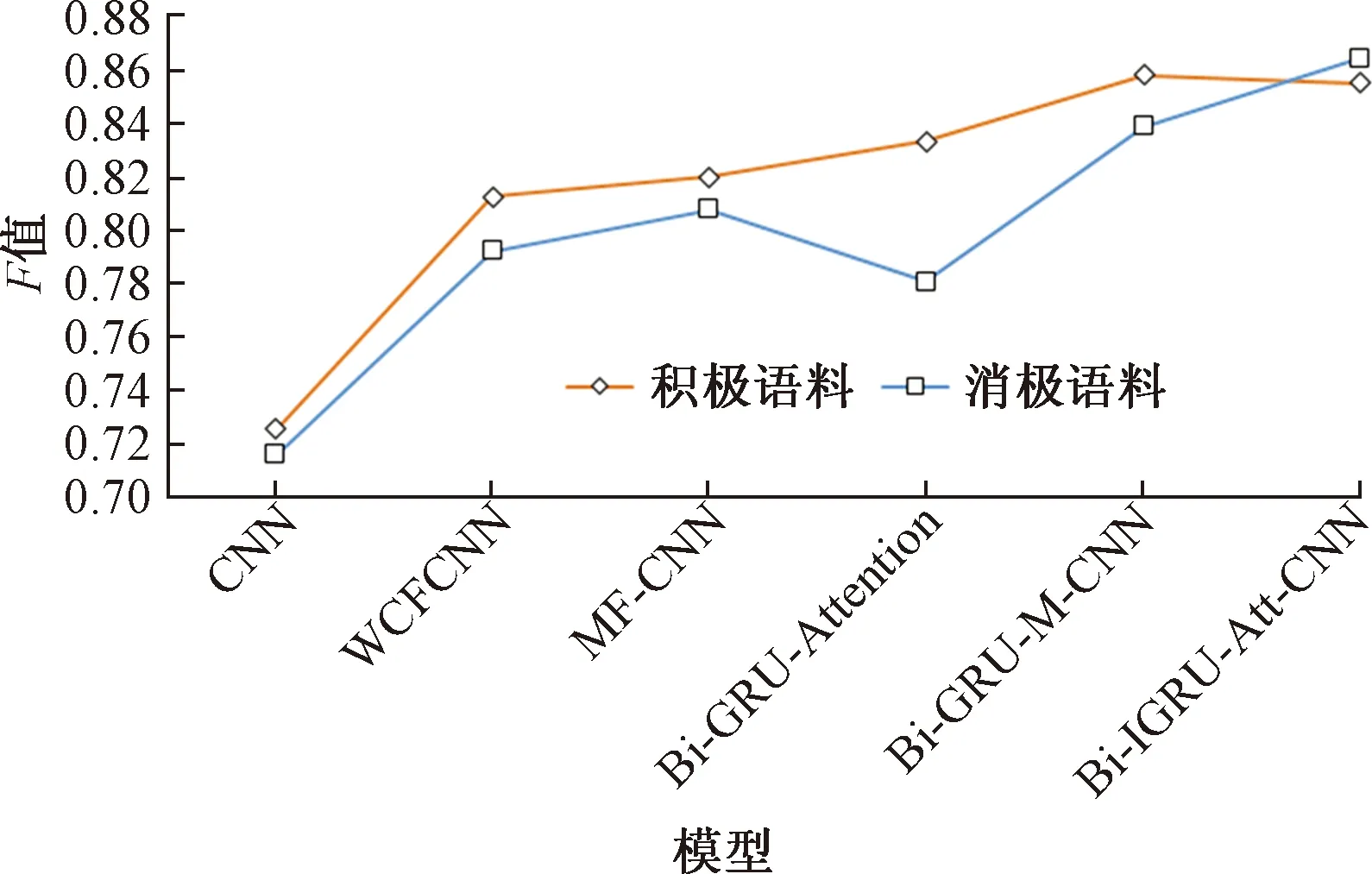
图4 6种模型F值对比Fig.4 Comparison of F-score of 6 models
CNN模型的分类性能明显低于其他模型,虽然CNN 模型比支持向量机、线性分类模型有较好的分类性能,但是与模型2~模型6还是有很大的差距,CNN模型只能取到局部特征信息,无法获取到文本全局特征。
WCFCNN模型和MF-CNN模型通过引入情感词典和情感积分增强情感特征,比CNN模型有较好的分类结果。
对比各模型的召回率,如图5所示,可以看出本文模型召回率高于前几个模型,即本文模型可以获取更多信息,同时本文模型分类效果明显优于前3个模型,尤其是CNN模型更加明显,这样就很好证明了Bi-GRU在提取特征信息的优势,同时本文模型在积极语料中的表现虽然比Bi-GRU-Attention模型低一些,但是总体效果可以;消极语料中,本文的模型分类效果最好,这是因为在卷积神经网络的基础上引入情感积分充分利用情感词自身信息,通过双向门控循环网络获取全局特征,对影响句子极性的否定词、转折词和程度副词引入注意力机制实现对这类词的重点关注,分类效果较好。
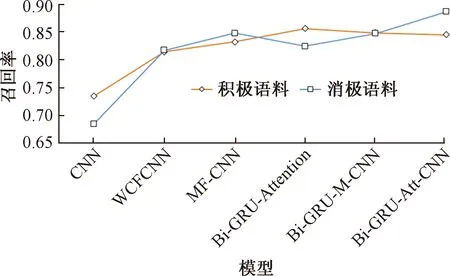
图5 6种模型召回率对比Fig.5 Comparison of recall of 6 models
本文模型使用全局向量的词嵌入(GloVe)对文本进行编码取得较好分类效果,为了分析本文模型在不同特征维度下的分类性能,使用不同维度的特征向量在相同的积极语料和消极语料上进行对比实验,图6所示为本文模型在语料上召回率对比结果。
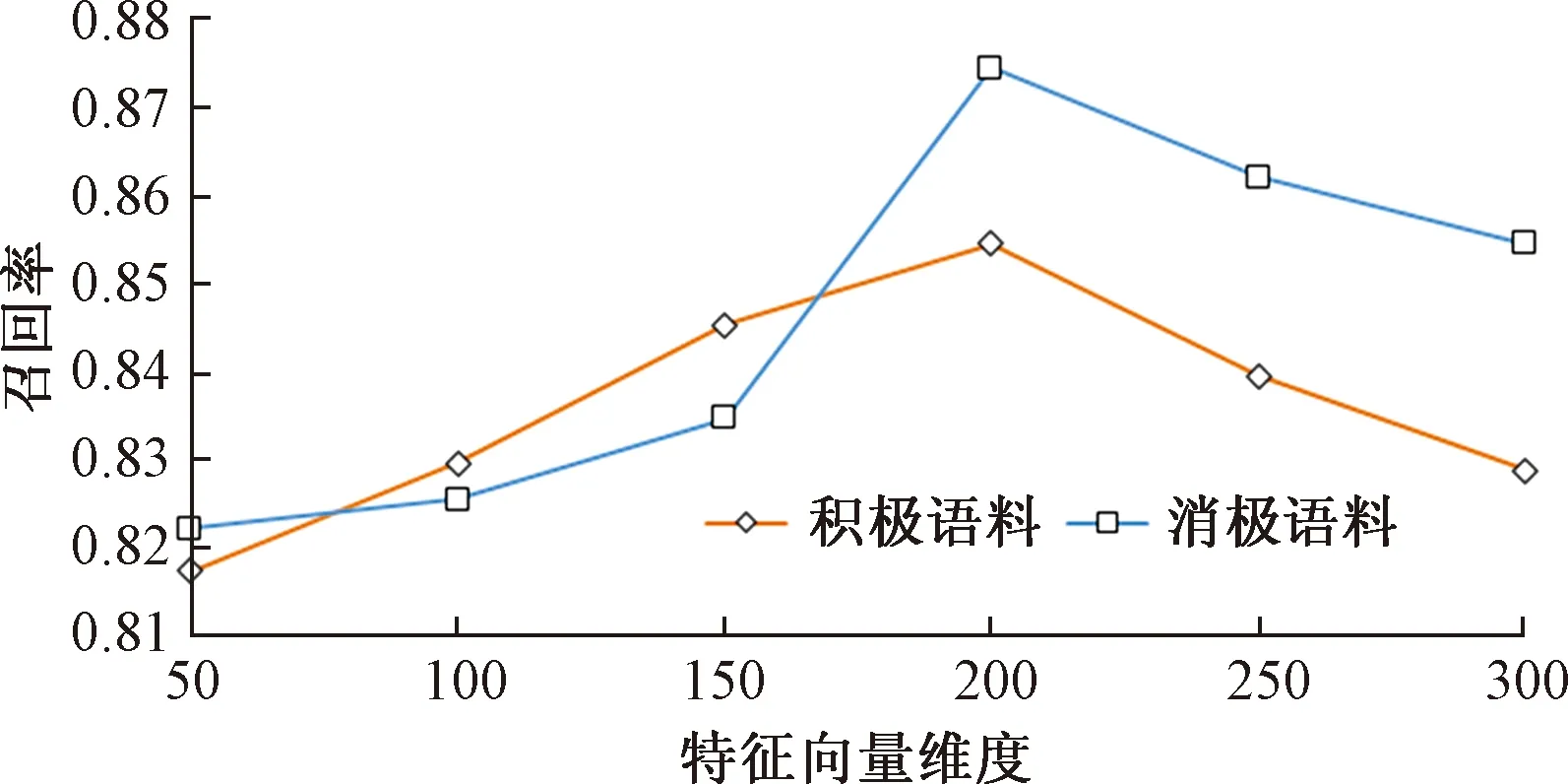
图6 本文模型在语料上召回率对比Fig.6 Comparison of text model recall rate on corpus
由图6以看出,特征向量维度小于200时,模型的分类召回率单调递增,表明模型随着特征向量维度的增加而获取更多的特征信息;特征向量维度大于200时,分类召回率下降,表明特征向量维度取值过大会出现过拟合现象,因此特征向量的维度取200分类效果最佳。
4 结论
基于卷积神经网络和双向门控循环单元网络注意力机制的短文本情感分析方法在卷积神经网络的基础上引入情感积分充分利用情感词自身信息,通过双向门控循环网络获取文本全局特征,对影响句子极性的否定词、转折词和程度副词引入注意力机制实现对这类词的重点关注,保留重要信息,将本文模型在不同语料上进行实验,结果表明该模型在情感分类上有较好的分类效果,在积极语料上的F值为0.854 2,在消极语料上的F值为0.863 1,分类性能优其他几个模型,从而验证模型的有效性。本文模型重点关注情感词信息,下一步可以将非情感词特征融入到模型中以更好提高分类性能。
