基于HNBJSON的物联网数据压缩方法
2021-02-24钟永彦
刘 凯,钟永彦,陈 娟,朱 震
(南通大学电气工程学院,江苏 南通 226019)
随着物联网技术的飞速发展,万物互联(Internet of Everything,IoE)的规模将越来越大[1-3]。 据思科、摩根士丹利与华为等公司估计,2019年全球约有400亿户的IoE连接,2020年连接规模达到750亿户,2025年将高达1 000亿户[4]。尤其在智能电网中,由于引入了大量先进的计算技术、通信技术与数据采集技术[5-6],海量的传感器与智能电表接入电网,这将带来井喷式的通信数据增长,进而造成数据阻塞现象,导致云边网络通信时延增大[7-8],这对数据压缩方法提出新的挑战。 常见的无损数据压缩方法主要有LZW算法和Huffman算法,它们具有通用性强、压缩效果好的特点[9-10]。然而,LZW算法易造成大量内存浪费,Huffman算法则占用CPU大量时间。当处理器内存和CPU性能受限时,将这两种算法直接用于物联网数据处理往往达不到预期效果[11-12]。
考虑到物联网终端设备常采用JSON或XML数据格式进行数据传输,而JSON数据格式在浏览器中使用更加广泛[13-14],因此,对 JSON 数据进行压缩成为研究热点。文献[15]使用Zlib将JSON数据进行压缩,减少了数据文件大小,但缩减量有限且仅用于数据存储。文献[16]提出通过数据映射的方式对JSON数据进行压缩,在原始数据分隔符较少的情况下,该方法存在压缩效率低的缺点。文献[17]介绍了SJSON算法,该方法将JSON键值对拆分,再分别编码压缩。当JSON数据结构较复杂时,具有压缩效率高、压缩时间短的优势,而数据内容复杂时,压缩率表现较差。文献[18]提出从云端主字典中提取用户字典的方式实现JSON数据压缩,但该方法并未涉及到具体的提取方式且字典未进行自适应更新,当JSON数据发生变化时,压缩效率会大打折扣。文献[19]使用共享压缩字典的方式实现JSON数据压缩,但此方式根据通讯成本更新压缩字典,导致压缩率仍有提升空间。
目前已有的JSON数据压缩方法,在进行物联网实时数据传输时,虽然实现了通讯数据的降低,但存在着压缩率较低,通用性不强且更新速度不显著等缺点。
本文结合边云协同思想,提出了一种基于HNBJSON(Huffman⁃Naive Bayesian JSON)算法的数据压缩方法。该方法在云端通过朴素贝叶斯分类器对实时 JSON数据进行分类,提取 JSON数据的Keyword组,根据Huffman编码原理生成若干压缩字典,并将生成的压缩字典发送至边缘设备。同时,云端服务器根据压缩率实现压缩字典的自适应更新。将该压缩算法应用于某高校教学场景中的用电监控,有效降低了边云通信数据量,缓解了因数据阻塞而造成的时延现象。
1 HNBJSON算法
1.1 朴素贝叶斯公式
贝叶斯决策利用事件发生的先验概率来推断后验概率,通过调整因子保障后验概率更加贴近真实概率,是概率框架下实现分类决策的基本方法。
假设一个变量集U={X,C}是样本数据与类别标记集合,其中X={X1,X2,…,Xn} 是样本数据集,C={c1,c2,…,cm} 是类别标记集。x=(x1,x2,…,xq)是样本数据集X的特征值集,样本Xi属于类别cj的后验概率P(C=cj|X=Xi)可表示为
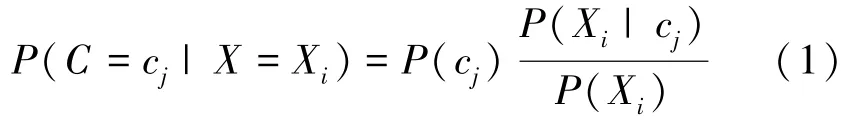
式中,P(cj)为先验概率,表示cj在集合C中出现的概率。P(Xi|cj)/P(Xi) 为调整因子,通过样本Xi对于cj的类条件概率P(Xi|cj) 与证据因子P(Xi) 计算得出。在此基础上假设每个特征值属性都是相互独立的,不难得出朴素贝叶斯公式的类条件概率公式为
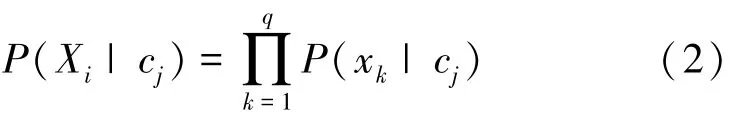
根据式(1)和(2),可联立得朴素贝叶斯公式为
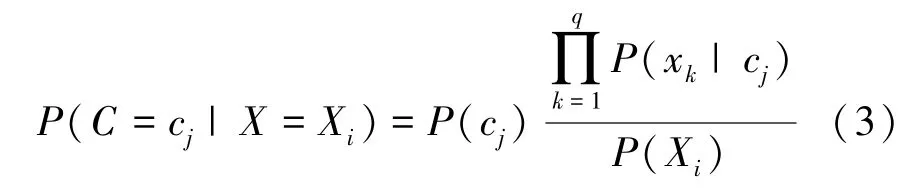
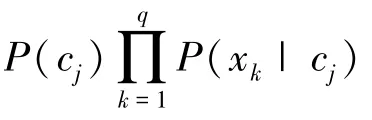
考虑到实际分类过程中,新出现的样本可能不包含某些特征值xk。在进行概率计算时,需要进行拉普拉斯平滑,避免概率为0的误判,修正后的概率公式为
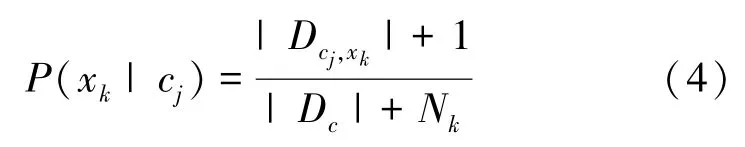
式中,Dcj,xk表示特征值xk出现在类别标签Cj中的集合,Dc表示所有类别标签的集合,Nk表示第k个特征值可能的类别数。
在进行数据分类判定时,类条件概率为避免因连乘导致下溢出,需将乘积结果取自然对数,最终的样本数据Xi归属设备的表达式L(Xi)为
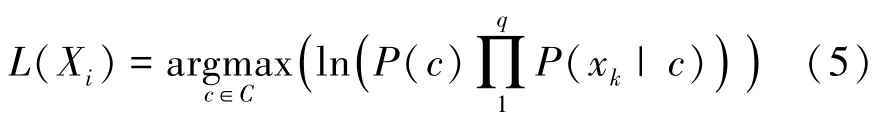
通过对比样本数据Xi归属于不同类别标签的概率,即可实现样本数据快速分类。
1.2 HNBJSON 结构
根据JSON数据结构与朴素贝叶斯分类器,针对多设备源的JSON数据,设计一种自适应更新的压缩算法HNBJSON,算法体系结构图如图1所示。

图1 HNBJSON算法体系结构图
首先,边侧获取原始JSON数据,解析对应的JSON对象。其次,将JSON对象Keyword与 Value进行分离,Keyword根据压缩字典进行字典压缩,Value保留不处理。最终,整合压缩后的Keyword与Value形成压缩后的JSON数据。同时,云端服务器解压并解析压缩后的JSON数据,通过朴素贝叶斯分类器完成对数据特征值的提取。再根据特征值将JSON对象数据进行设备源分类。然后统计同种设备源中数据字符长度较长且出现频率较高的特征值,按Huffman编码原理(用较短代码映射概率高的字符串数据,较长代码映射概率低的字符串数据)编入每个设备对应的压缩字典,保障JSON数据压缩率。最终,云端服务器压缩字典与边侧同步,实现边缘侧压缩字典自适应更新。
2 基于HNBJSON的数据压缩
2.1 数据采集
在智能电网中,数据集中器采集用电侧产生的单相/三相电压、单相/三相电流、功率因数、频率和开关状态等数据,并上传至云端,最终在云端服务器完成数据的处理和分析。典型的数据采集流向图如图2所示。
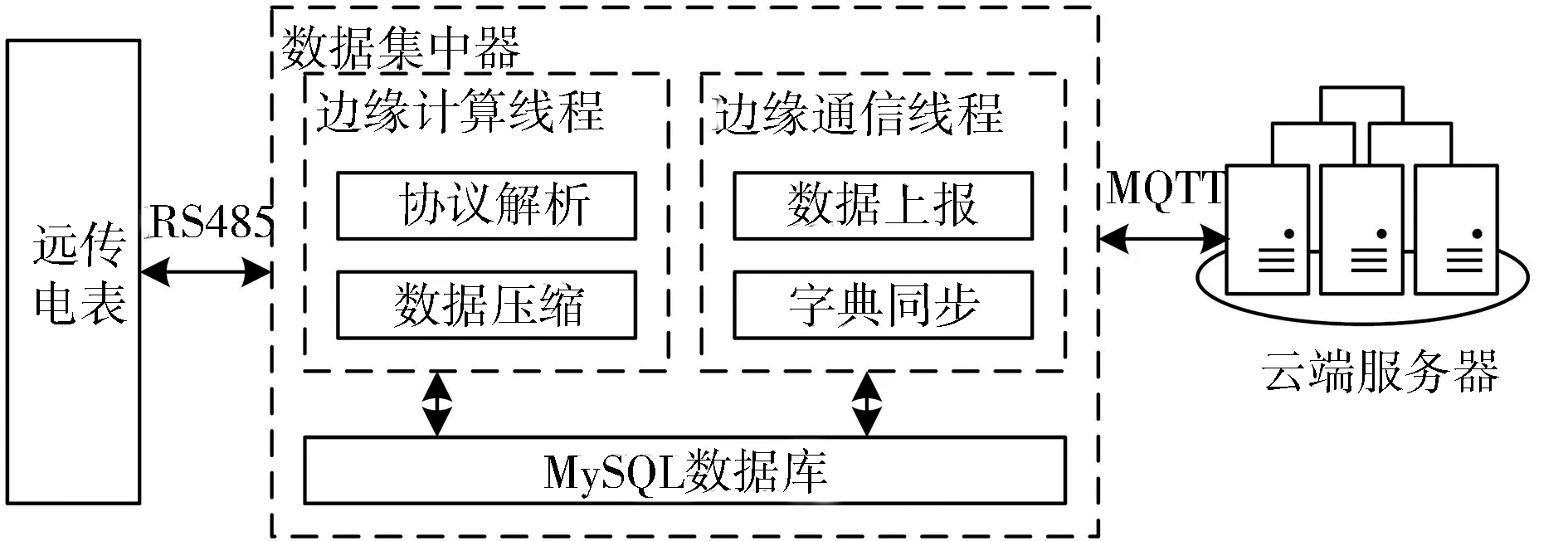
图2 数据采集流向图
远传电表通常采用支持RS485协议智能电表,用来实时采集电网用电侧电力数据。数据集中器设计边缘计算线程与边缘通信线程,实现数据采集与字典同步。边缘计算线程通过数据解析线程转化边缘数据为标准JSON格式,然后利用内置数据压缩模块,配合储存在MySQL数据库的压缩字典,实现数据压缩。边缘通信线程通过MQTT协议,实现边缘数据上报与压缩字典同步更新。
2.2 压缩字典
JSON是一种轻量级的数据交换格式,易于阅读与编写,常通过一对大括号与“Keyword/Value”的无序键值对组合进行数据传输。“Keyword”与“Value”通过冒号分割,不同无序键值对通过逗号进行分割,形如:{‘keyword1’:Value1,‘keyword2’:Value2}。考虑到电网JSON数据中的Value常为数字量,压缩收益不高,因此选取“Keyword”组进行压缩字典构造,如图3所示。
云端服务器根据各个采集器采集的历史JSON数据训练出的朴素贝叶斯分类器,对实时上云的JSON数据进行分类,添加至对应的采集器镜像数据库中,用于生成压缩字典。若JSON数据压缩率小于等于预期压缩率Cmin,则更新压缩字典,具体步骤如下。
首先,统计同类型采集器内边缘终端设备数据的Keyword,当Keyword字符长度大于设定最短字符长度Lmin且出现频率高于设定最小频率fmin时,将Keyword缓存至字典队列。
其次,将缓存的Keyword进行字符串切割,根据字符段出现频率进行排序与编码。
最后,根据排序结果更新压缩字典,生成压缩字典如表1所示。
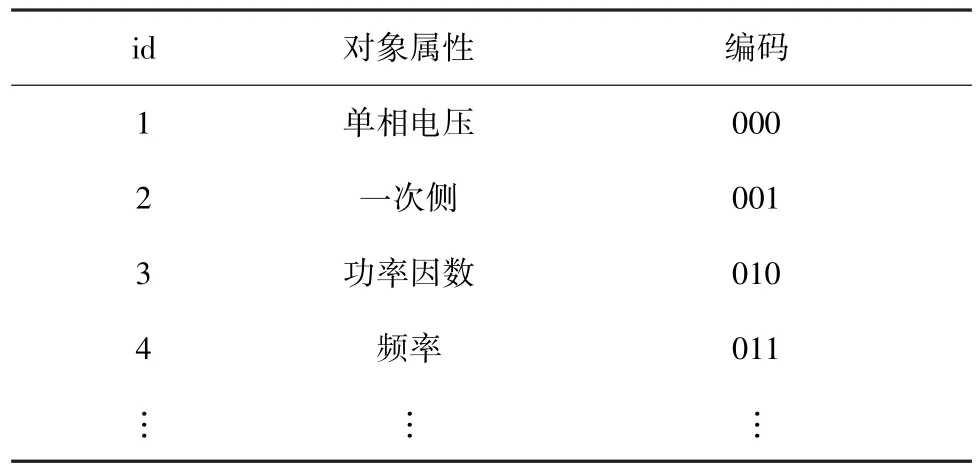
表1 压缩字典示例
2.3 压缩字典边云协同
为满足压缩需求,保障云边通信稳定可靠,需确保边缘侧与云端压缩字典同步并进行自适应更新,压缩字典边云协同示意图如图4所示。场景1表示数据集中器连接云端上传数据并进行压缩字典优化的过程。首先,数据集中器根据压缩字典将原始数据进行字典压缩,压缩后的数据发送至云端,默认初始压缩字典为空;其次,根据数据集中器类型在云端查找压缩字典,若没有同类型集中器,则建立新的压缩字典并将其发送至数据集中器1,若有同类型集中器,则调用同类型集中器的压缩字典,如请求场景2中数据集中器2的压缩字典;最后,数据集中器根据压缩字典进行数据压缩,再将压缩数据上传至云端,若压缩效果未达到设定的压缩率,则迭代更新压缩字典,直至满足压缩要求。
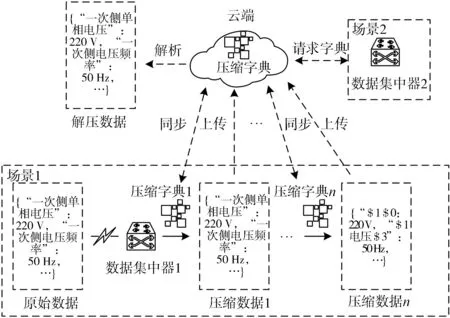
图4 压缩字典边云协同示意图
3 网关测试与结果分析
实际测试中,选取DDSU666型单相费控智能电表对教室1、实验室与图书馆3个应用场景的电压、电流、有功功率与频率数据进行采集,样本数据共3 000组,随机选取样本数据的80%作为训练集,其余作为测试集。基于树莓派CM4开发数据集中器,其内存为 4 GB,处理器为 ARM Cortex⁃A72,包含RS485接口、RS232接口与无线网卡。云端服务器内存16 GB,处理器为 Intel i5⁃9300H,使用库函数sklearn构建朴素贝叶斯分类器。云服务器与数据集中器均安装python3.8.0与MySQL5.7.25,使用库函数paho⁃mqtt实现MQTT通信。
3.1 分类测试
分别将训练集与测试集代入构建的朴素贝叶斯分类器中,调整特征值的数量,计算分类准确率,如表2所示。
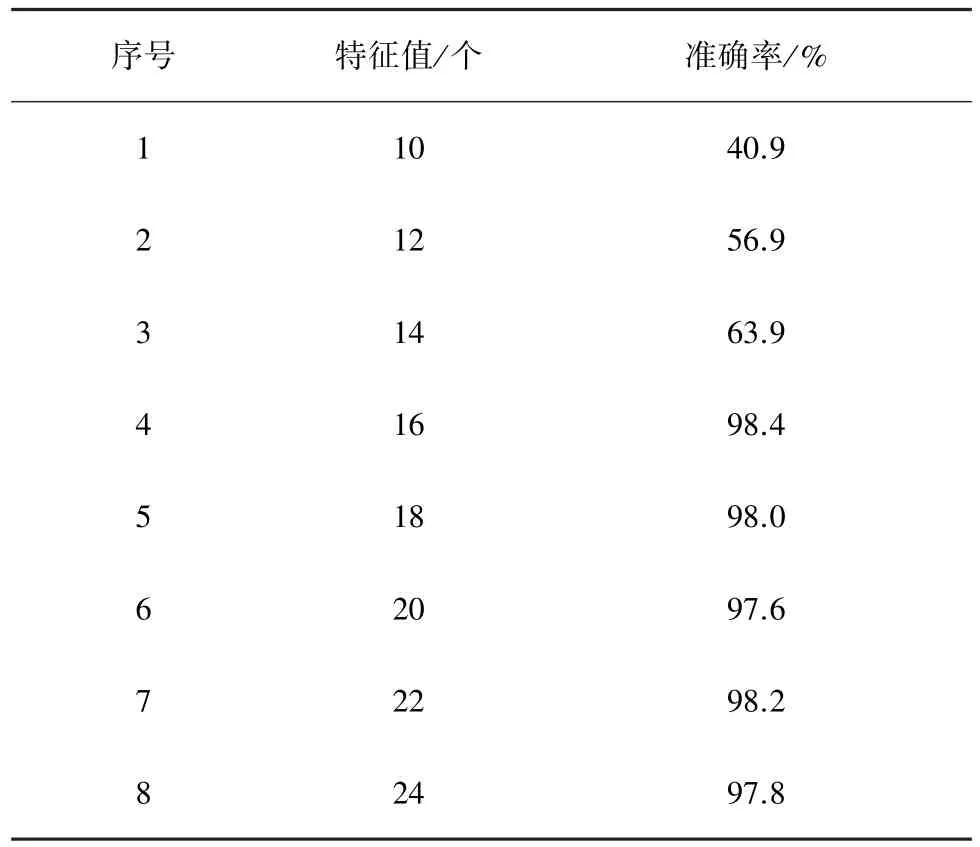
表2 压缩字典示例
测试结果表明,随着设定的特征值数量的提高,分类准确率逐渐提升,当特征值数量大于16时,分类准确率在98%左右。考虑到特征值数量的提高会引起CPU占用率的提高,且分类准确率并未明显变化,故采取特征值数量为16的朴素贝叶斯分类器进行数据分类,为构建压缩字典提供正确数据源。
3.2 压缩测试
根据分类后的数据构建压缩所需的压缩字典,对实时JSON数据进行HNBJSON压缩,并将其与传统的LZW压缩、Huffman压缩与字典压缩进行对比,根据压缩率公式计算压缩率,压缩率公式为
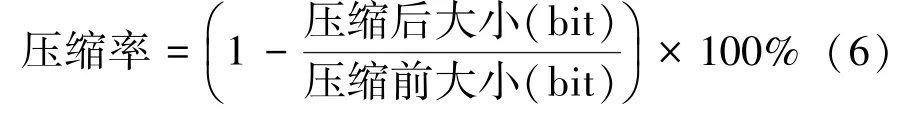
每隔300条数据计算一次数据压缩率与数据压缩总时间,以数据量为横轴,绘制压缩效果对比图,如图5所示。
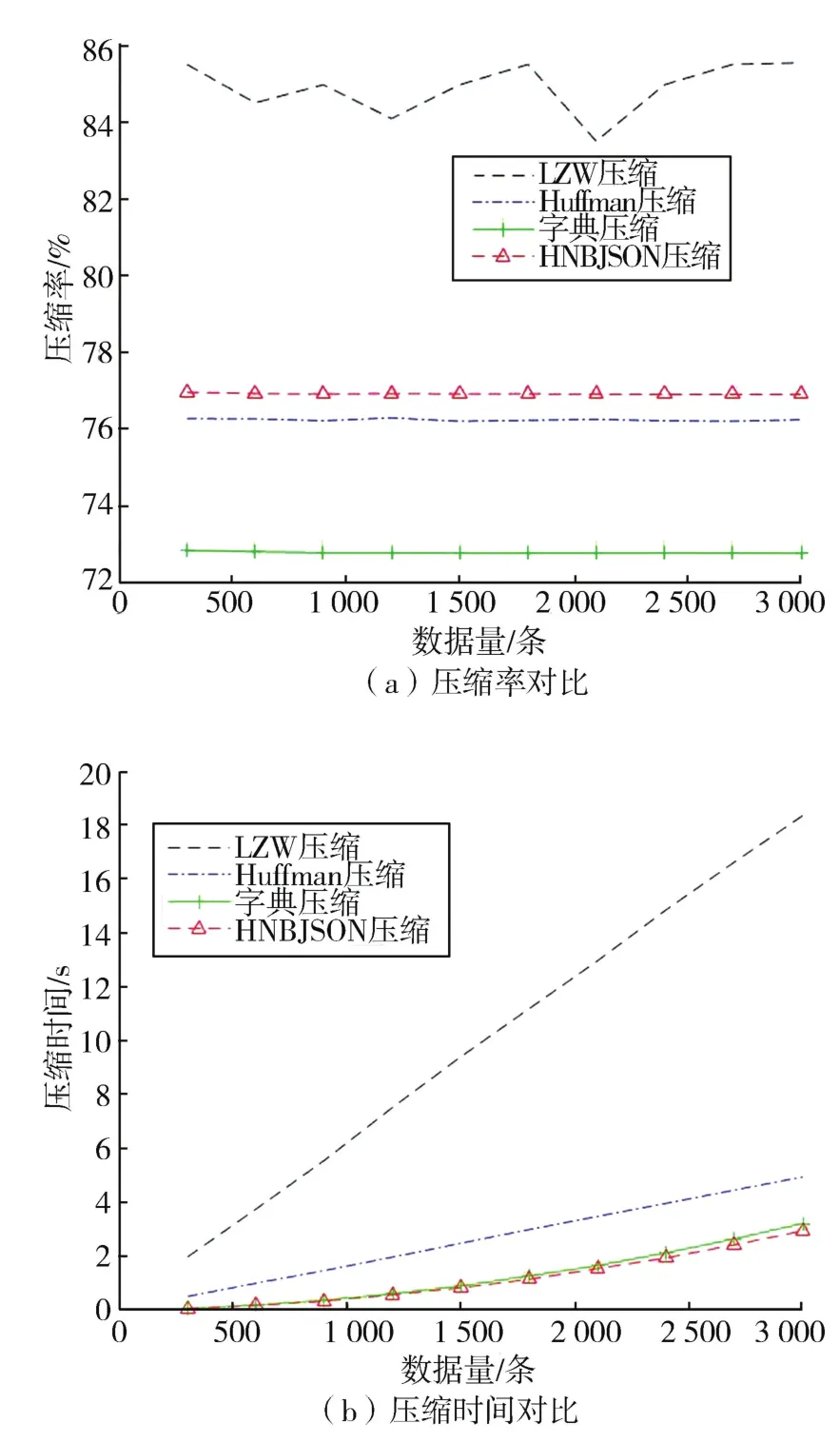
图5 字典压缩与HNBJSON压缩效果对比图
图5(a)中,随着数据量的增长,LZW压缩率在85%左右波动,HNBJSON压缩、Huffman压缩与字典压缩分别稳定在 76.9%,76.2%与 72.8%左右。HNBJSON压缩率稍逊于LZW压缩,优于其他两种压缩算法。图5(b)中,HNBJSON压缩所需压缩时间少于其他3种压缩算法,且4种算法的压缩时长呈线性增长。当压缩数据达到3 000条时,HNBJSON压缩仅需要2.94 s,即平均每条数据压缩时长约为0.98 ms,而字典压缩、Huffman压缩和LZW压缩的压缩时间总长分别为3.22 s、4.95 s和18.37 s。特别是LZW压缩的压缩时间过长,反而会导致时延的增长,使得压缩率高的优势丧失。因此,HNBJSON压缩对比于其他3种经典压缩算法,不仅在数据压缩率方面具有一定的优势,压缩时间也得到了充分保证,在缩减边缘侧电力数据的同时,减少了数据在边缘侧传输时的排队时间,从而缓解了边云间通信时延。
3.3 自适应更新测试
选取与教室1数据源相似的应用场景教室2作为测试对象,使用数据集中器采集电压、电流、有功功率、频率以及投影仪等多媒体设备的开关状态。根据设计的分类器,教室2数据集中器将会被分类到教室1所属的大类中,并获取教室1的压缩字典作为初始压缩字典。以数据量为横轴,每隔300条数据计算一次压缩率,绘制的教室1与教室2数据压缩率变化趋势如图6所示。

图6 压缩字典自适应更新压缩效果图
图6中,教室1的压缩字典在教室1数据集中器中表现良好,压缩率基本恒定在76.9%左右。但在教室2数据集中器中,初始压缩率低于期望值,仅为58%左右,此时云端服务器根据教室1数据镜像生成教室2数据集中器镜像,并接收教室2实时数据进行压缩字典更新,经过600条实时数据的训练后,压缩率为76.9%左右,满足数据压缩要求。测试结果说明HNBJSON算法兼容性与扩展性强,新接入设备可以继承同类设备压缩字典,具有良好的自适应更新能力。
4 结束语
本文针对物联网中的 JSON数据,提出了HNBJSON压缩算法,并将其应用于某高校教学场景用电监测。该算法采用边云协同的思想,在云端建立压缩字典,然后分发至数据集中器,有效降低了边缘侧计算压力。采用先分类再编码的方式创建多个压缩字典,减少了查表时长,缩短了压缩时间,缓解通信时延问题。经实验测试,该系统面对复杂情况时具有自适应能力强、压缩效果优良的优点,具有广阔的应用前景。
