网络表示学习方法研究综述
2021-02-24孙金清赵中英
孙金清,周 慧,赵中英
(山东科技大学 计算机科学与工程学院,山东 青岛 266590)
信息网络是最为常见的一种信息载体和形式,随着互联网的不断发展,以社交媒体网络、移动通信网络、维基百科等为代表的信息网络已成为日常生活中不可或缺的一部分。人类的各种交互行为产生了极为丰富的信息网络数据。与此同时,面向信息网络的数据挖掘也逐渐得到学术界和产业界的广泛关注。然而随着数据的规模逐渐增大和网络的复杂性的提升,使用传统的高维稀疏数据的编码方式难以对网络进行处理。因此,如何恰当的表示网络中的信息是研究人员首先要面对的重要问题。
网络表示学习(network representation learning),又被称之为网络嵌入(network embedding),是衔接网络中原始数据和网络应用任务的桥梁,旨在将网络中的组件(节点、边或子图等)表示成向量形式,同时最大程度地保留组件在原网络中的信息和属性。传统的网络表示一般使用高维的稀疏向量,网络表示学习旨在将网络中的复杂关系以更加直观、更加高效的方式对原始网络空间中的节点关系进行还原。近年来,研究者通过大量研究实验不断探索网络中组件的高效表示方法,使得学得的低维表征向量能够被机器学习算法处理,复杂的网络分析任务(节点分类[1-2]、链接预测[3-4]、社区发现[5-6]和推荐[7-8]等)得以高效地进行。例如,在基于位置的社交网络中,Luan等[9]使用张量分解等方法对网络中用户的行为进行建模,根据用户偏好进行推荐[10];在电子商务网络中,Liu等[11]提出欠采样高斯矩阵等方法机器学习方法对欺诈行为建模,针对欺诈样本不均衡[12]、欺诈行为的概念飘逸[13]等进行了研究[14]。
为有效地掌握网络表示学习领域的学术思路和动态,本研究对近年来面向同构网络和属性网络的代表性的表示学习算法进行分类介绍和比较。特别地,对于同构网络,根据算法所应用的理论基础进行分类介绍。对于属性网络,根据算法所结合的属性信息种类进行分类介绍。此外,对比分析了各类别下的网络表示学习算法的时间复杂度和优缺点。
1 问题定义
本节给出网络和属性网络形式化定义,并对同构网络和属性网络上的表示学习进行问题描述。
定义1网络[15]。网络是对关系型数据的刻画,主要由节点和和连接这些节点的边构成,表示诸多对象及其相互联系,符号表示为G(V,E),其中V表示网络G中的节点集,E表示边集。

问题1同构网络表示学习[17]。给定同构网络G(V,E),目标是为网络中的节点v∈V(或边、子图等)学习映射关系f:v→rv∈Rd,其中rv为节点v学得的低维稠密向量,d是表征向量的维度,d≪|V|,转换函数f用于捕获原网络中节点之间的拓扑关联关系。
问题2属性网络表示学习[16-17]。给定属性网络G(V,E,A),目标是为属性网络中的节点v∈V(或边、子图等)学习映射关系f:v→rv∈Rd,其中rv是为节点v学得的低维稠密向量,d是表征向量的维度,d≪|V|,转换函数f用于捕获原网络中复杂的拓扑和属性关联关系。
在介绍算法分类之前,首先列出论文中用到的主要符号以及其含义如表1所示。

表1 论文中的常用符号
2 同构网络表示学习
本节介绍基于网络拓扑信息的同构表示学习算法。根据理论基础,将代表性算法分为基于非线性流形学习、基于自定义损失函数、基于简单神经网络、基于矩阵分解以及基于深层神经网络的网络表示学习算法等5类。
2.1 基于非线性流形学习的网络表示学习算法
非线性流形学习常用于对高维的流形数据进行非线性降维,代表性算法有Isomap(isometric feature mapping)[18]、LLE(locally linear embedding)[19]和LE(laplacian eigenmaps)[20]等。这些算法通过构建邻域图来发现高维空间中的数据的低维结构,并得到对应的低维向量表示,属于网络表示学习的早期成果。下面对这些代表性算法分别进行介绍。
在Isomap算法[19]中,设计了能够衡量高维流形数据之间的测地距离的有效方法。相比欧氏距离,测地距离更接近非线性数据之间的实际距离。如图1所示,该算法首先通过计算原数据节点间的欧式距离来建立邻域连接图,然后通过寻找邻域图上的两点间的最短路径(红线)近似逼近测地距离(蓝线);接下来,基于数据点之间的测地距离构建距离矩阵;最后通过多维标度(multidimensional scaling,MDS)方法根据距离矩阵对数据进行降维。

图1 Isomap算法节点距离计算示例[19]
LLE算法[19]首先假设非线性数据在局部范围内存在线性关系,那么每个数据节点可表示成其邻居节点的加权组合。同时,该算法又假设这些高维数据映射到低维空间后仍能够保持原数据空间上的局部线性关系。利用这些假设,数据在高维和低维空间上的联系能够被建立起来。最后,通过对关系矩阵求解特征向量来获取数据的低维表示。随后,科研人员针对局部线性关系的构建方法提出了对LLE算法的改进,相关算法有LE[20],Hessian LLE[21]等。
LE算法[20]同样根据数据节点在高维空间上的邻近关系来进行低维映射,核心思想是保持相邻节点在低维表示空间中的邻近关系。数据的低维表示是对应的拉普拉斯矩阵的前d个最小特征值所对应的特征向量。由于以上介绍的算法都只能处理无向网络,DGE(directed graph embedding)算法[22]基于LE算法进行了改进,采用基于随机游走的方法为不同点加入不同的权重信息,使之能够处理有向和无向两种类型的网络。
本节中所介绍的算法仅保留了节点的一阶相似度,无法衡量全局性的数据特征,而且计算时间复杂度较高,不能扩展到大规模网络上。
2.2 基于自定义损失函数的网络表示学习算法
LINE算法[23]通过设计自定义的损失函数来建模网络中节点的一阶和二阶相似度。其中一阶相似性指的是相连节点间的相似度,对应的目标函数如式(1)所示;二阶相似性指的是共享多个相同邻居的节点之间的相似度,对应的目标函数如式(2)所示。该算法使用随机梯度下降法优化目标函数并更新节点的向量表示。
(1)
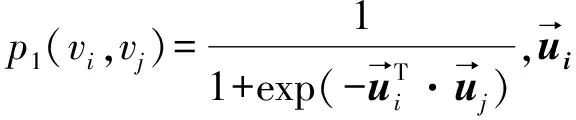
(2)
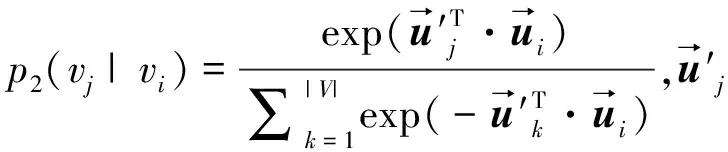
2.3 基于简单神经网络的网络表示学习算法
简单神经网络在网络表示学习中的应用主要受到Word2vec[24]词向量训练模型的启发。DeepWalk算法[25]首次将词向量训练模型引入到网络中,用于学习网络中节点的向量表示;该算法采用截断随机游走的方式为网络中的每个节点构建邻域节点,然后使用词向量训练模型Skip-Gram[24]进行训练,最大化邻域节点在目标节点周围出现的概率,由此得到每个节点的低维向量表示。
Grover等[26]进一步对DeepWalk算法的随机游走方式进行了改进,设计了node2vec算法,通过引入两个参数p和q来控制随机游走的方向,进而能够捕获更加丰富的网络结构信息。值得注意的是,当p=q=1时,node2vec等同于DeepWalk算法。此外,在struc2vec算法[27]中,为了捕获节点间的全局结构相似性,作者设计了多层加权图来选取更具代表性的临域节点。
NBNE(neighbor based node embeddings)算法[28]和ProxEmbed算法[29]也运用了随机游走与神经网络相结合的思想对网络进行表示学习。总的来说,基于简单神经网络方法的优点是时间复杂度低,但此类算法缺少明确的目标函数,同时通过特定步长的随机游走并不能够充分捕获复杂的网络结构信息[23]。
2.4 基于矩阵分解的网络表示学习算法
矩阵分解指的是将一个矩阵分解成多个矩阵,分解后的矩阵能够以低于原矩阵的维度来近似地保留原矩阵的特征,这种理论被广泛用于网络表示学习任务中。
刘知远等[30]首先证明了DeepWalk算法[25]等同于对网络转移概率矩阵进行矩阵分解。由于以往的算法局限于捕获节点间的低阶相似度信息或直接建模高阶相似性,忽略了从低阶到高阶的过程中所蕴藏的拓扑信息。为解决以上问题,GraRep算法[31]被提出,分别对不同k步范围内的网络拓扑信息进行奇异值分解,并将每一步得到的向量表示相连,由此得到的节点表示能够更加精确地反映真实的网络结构信息,但是该算法的时间复杂度较大,仅适用于规模较小的网络。
Yang等[32]指出在网络表示学习的过程中考虑节点的高阶相似度信息是非常重要的,但同时也会增加模型的复杂度,无法适用于大规模网络;为解决上述的问题,作者提出了NEU(network embedding update)算法,在不增加算法复杂度的同时,通过在原有表示学习算法基础上添加附加项,来快速生成能够捕获高阶信息的向量近似值。
2.5 基于深层神经网络的网络表示学习算法
深层神经网络在不同的领域都有着广泛的应用,而且在学习不同层次的数据特征方面已经取得了较好的研究成果[33]。在网络表示学习方向上,学者运用深层神经网络来捕获网络中复杂的非线性信息。
Jacobs等[34]提出一种基于深层神经网络的半监督模型SEANO,为具有局部标签和属性信息的网络节点进行向量表示。该模型通过深度学习框架将节点的拓扑结构信息、属性信息相关联。
Cao等[35]指出基于奇异值分解的网络表示学习算法局限于从线性关系中推出节点的向量表示,无法捕获到网络中存在的复杂非线性关系,为解决此问题提出DNGR模型(如图2所示),该模型首先采用带权随机游走方法来捕获网络结构信息,并生成概率共现矩阵;然后在此基础上计算得到点互信息矩阵;最后采用SDAE(dtacked denosing autoencoders)算法[36]对向量进行分层学习并降维,最终得到网络中节点的向量表示。

图2 DNGR模型框架[36]
SDNE(dtructural deep network embedding)模型[37]同样基于深层神经网络模型,并采用半监督方法进行网络表示学习(如图3所示),该模型由两部分组成:第一部分为无监督的深层自编码器,用于捕获节点的邻域结构相似性,即节点的二阶相似度;另一个部分建立在自编码器的中间层,用于有监督地建模节点的一阶相似度。

图3 SDNE模型框架[37]
2.6 同构网络表示学习算法对比
本节中,对同构网络表示学习算法进行对比,包括算法的时间复杂度和优缺点,总结如表2所示。
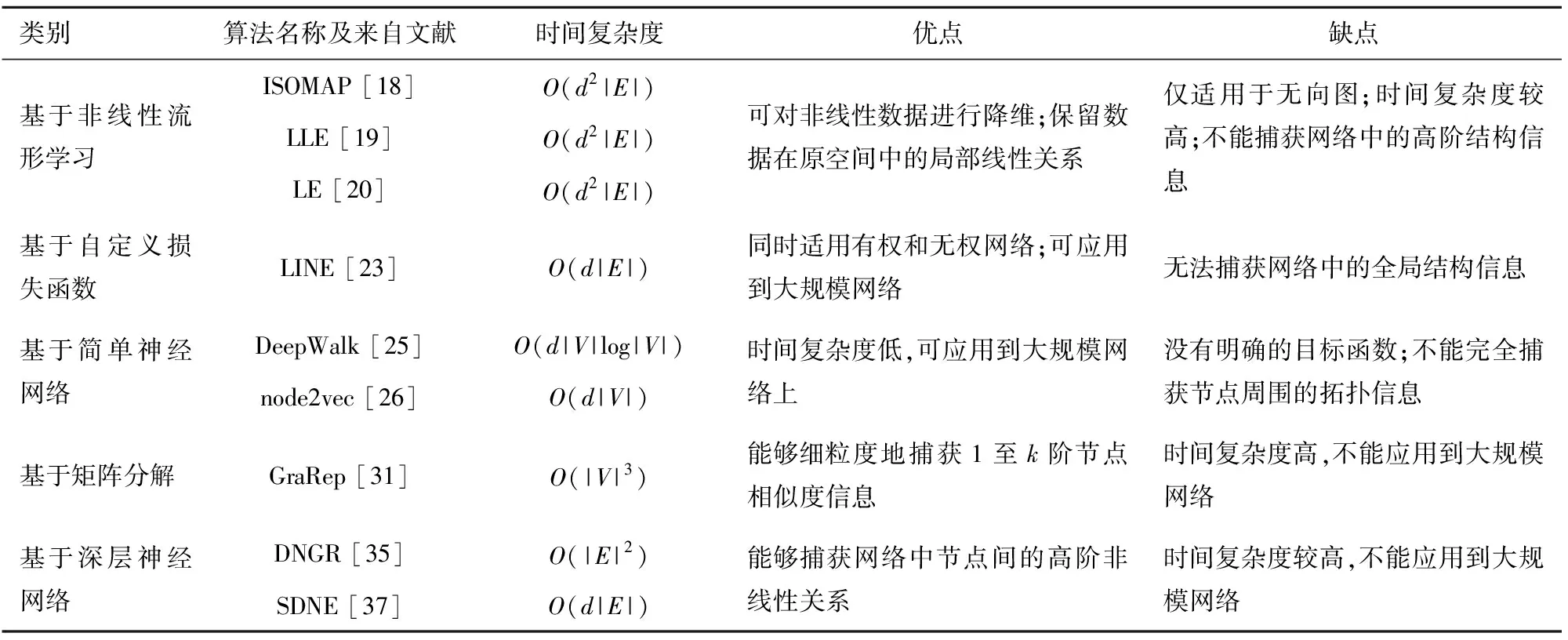
表2 同构网络表示学习算法对比
3 属性网络表示学习算法
第2节中介绍的网络表示学习算法只是对节点在网络中的拓扑关系和结构相似性进行编码与计算。现实生活中的网络蕴含着丰富的异构信息,例如网络中节点和边上的标签信息以及文本特征信息等,若这些信息得到合理的运用,会对网络表示学习起到很好的辅助作用。本节中以异构信息的种类作为分类依据,对现有的属性网络表示学习算法进行具体的描述,并分析这些算法的异同之处。
3.1 嵌入社区信息
现实网络中蕴藏着丰富的社区信息,尤其在社交网络中最为常见,反映了网络中的个体与其他个体之间的关联关系,是对网络中节点进行分析和研究的重要属性,也是对网络中节点交互关系预测的重要依据。
M-NMF(modularized nonegative matrix factorization)算法[38]分别从微观和宏观的角度学习对网络节点进行向量表示,模型同时考虑了节点之间的相似度以及节点所属的社区信息。微观层面上,算法计算节点的一阶和二阶相似度;宏观层面上,算法运用基于模块性最大化社区发现方法[39]来建模网络中的社区结构。M-NMF算法将这两个方面进行了融合,其目标函数如式(3)所示,将目标函数最小化即得到节点的向量表示。
(3)
除了利用社区信息对网络中的单个节点进行表示学习之外,还有算法可以直接对网络中的整个社区进行表示学习。ComE算法[40]首先运用一些经典的社区发现算法(如谱聚类)对网络进行社区发现,根据社区发现结果为每个节点进行社区标注;然后运用经典的表示学习算法(LINE、DeepWalk等)对节点进行嵌入;最后把所属相同社区的节点表示进行聚合。模型中节点嵌入、社区发现以及社区嵌入之间相互促进,节点的嵌入增强了社区发现并拟合出更好的社区嵌入。
3.2 嵌入标签信息
3.2.1 嵌入节点的标签信息
传统的无监督网络表示学习算法,虽然能够对网络节点的拓扑特性进行学习,但是对后续的一些机器学习任务缺乏区别性和针对性,进而有学者提出了有监督的表示学习方法,训练出具有针对性的表示向量。
在DeepWalk算法基础上,MMDW(max-margin deepwalk)算法[30]添加了一个有监督的最大间隔分类器,利用节点的标签信息进行有监督学习。算法得到的节点向量中包含了网络的拓扑信息和具有区别性的标签信息,分类效果优于其他无监督的算法。Li等[41]将截断随机游走的DeepWalk算法与分类器相结合,提出了与MMDW算法相类似的DDRW(discriminative deep random walk)算法。
另一方面,MVE(multi-view network embedding)算法[42]为节点收集并整合了网络中多视角的相似度信息,将其用于表示学习。模型训练的过程如图4所示,算法为节点在每个视角下都学得向量表示,并将学得的向量进行整合。MCGE(multi-view clusting framework with grapg embedding)算法[33]同样运用了多视角的方式将表示学习运用在聚类任务中。
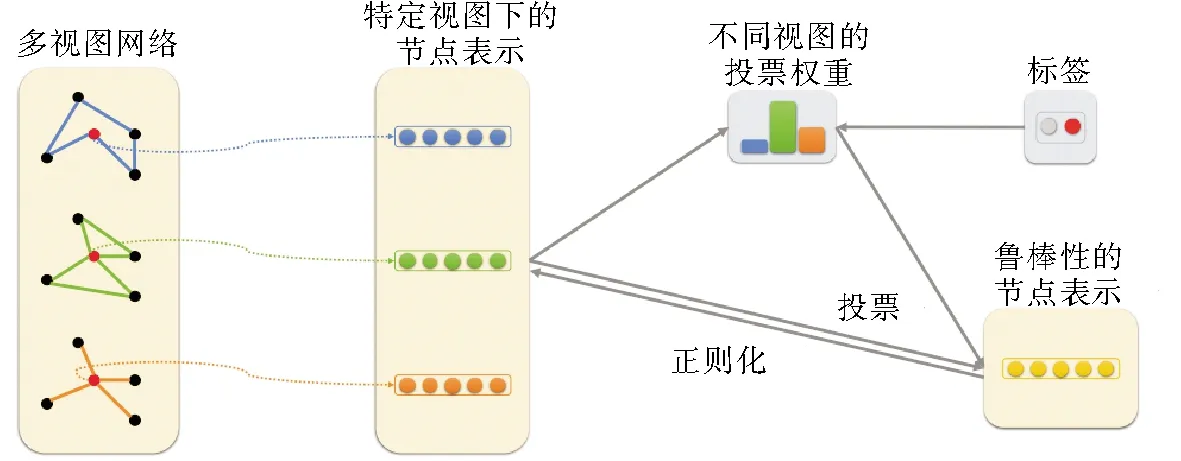
图4 MVE模型框架[43]
3.2.2 嵌入边的标签信息
TransNet模型[43]将转换机制[44]和深度神经网络运用到属性网络表示学习。该模型分为两个模块,如图5所示,第一个模块对边的标签信息进行自编码;第二部分算法将边的首尾节点和边上的标签向量嵌入到相同的空间中,并使得U+1≈V′,运用转换机制并最小化铰链损失函数。TransNet算法在社会关系提取的任务中表现出较好的结果。

图5 TransNet模型框架[43]
3.3 嵌入文本信息
文本信息在网络中普遍存在,例如:社交网络中用户写的动态和发表的评论;合著网络中作者的论文等文本信息。这些文本信息对于学习网络丰富的向量特征具有重大意义。CANE模型[45]引入一种相互注意机制(mutual attention),对节点的结构信息和文本信息进行了融合,从而考虑节点的上下文信息,在和不同的节点交互时具有不同的表示。
Yang等[46]证明DeepWalk算法计算过程实际上相当于矩阵分解过程,同时注意到现实网络中的节点蕴含着丰富的文本信息,提出了TADW(text-associated deep walk)算法。算法利用矩阵分解的方法把节点的附加文本信息加入到矩阵分解的过程中。如图6所示,矩阵M被分解成三个矩阵,其中T矩阵中包含了节点的文本特征。通过最小化损失函数(4)来更新W和H矩阵,最终使用W、H和T三个矩阵作为节点的低维向量表示。

图6 TADW算法[46]
(4)
Huang等[16]提出AANE算法。根据网络拓扑结构,算法对节点间的一阶相似度进行建模,同时根据属性信息生成节点的属性关联矩阵,使得节点向量与节点的属性信息尽可能的匹配。算法将网络中的属性信息和拓扑信息进行高效汇聚,使用矩阵分解方法生成向量表示。
GraphSAGE模型[47]是对传统图卷积神经网络的延伸,模型中目标节点的向量表示由其邻居节点的信息(拓扑信息和属性信息)所决定。模型训练的过程如图7所示,首先从源节点的k阶邻居中选择一定数量的节点;接下来对不同的k阶邻居节点训练出相应的聚合函数(例如Mean aggregator、LSTM aggregator等)。最终得到的节点向量表示汇聚了其各自邻居的信息,不仅可对训练过程中不可见的节点信息进行预测,而且能够结合后续的任务进行有监督学习。

图7 GraphSAGE模型[48]
3.4 嵌入多类型属性信息
另外还有一些网络表示学习算法,综合学习了不同类型的属性信息。
LANE(label informed attributed network embedding)算法[48]同时学习属性网络中的节点相似度信息和标签信息,综合两者生成节点的向量表示。图8展示了算法的计算流程。算法主要分为两个模块,在第一个模块中算法对网络的属性信息和拓扑信息进行嵌入,第二个模块将节点的标签信息进行嵌入。LANE算法通过相关投影模式将学得的这三类信息映射到新的维度空间中,最大化三者在新空间上的关联性,进而得出最终的向量表示。

图8 LANE模型框架[49]
SNE(docial network embedding)算法[49]运用深层神经网络对不同类型的节点信息进行综合学习,如图9所示。该算法将节点的属性作为神经网络的输入,由两个全连接层组成的嵌入层对属性向量进行降维,进而通过隐含层对向量进行非线性映射,最后经过一个隐含层后得到的向量转化成目标节点与其它节点连接的概率向量。最终节点的向量表示由最后一个隐含层的向量和连接到输出层的权重向量相加得到。

图9 SNE模型框架[50]
3.5 属性网络表示学习算法对比
从算法的时间复杂度和其优缺点等方面对上述属性网络表示学习算法进行比较,如表3所示。

表3 属性网络表示学习算法对比
4 应用场景
网络表示学习具有多种任务应用场景,典型的有节点分类、链接预测、聚类和推荐等。本节选取不同类别下的代表性算法,并将这些算法在节点分类这一应用场景下进行测试,比较不同算法在相同数据集上的实验结果。选取了8个代表性的网络表示学习算法进行实验对比,分别为同构网络表示学习类别下的DeepWalk[25]、Node2vec[26]、LINE[23]和GraRep[31]等算法,和属性网络表示学习类别下的CANE[45]、TADW[46]、SEANO[34]和GraphSAGE[47]等算法。
4.1 数据集
选用以下三种常用的数据集进行实验。
①Cora引文数据集的子集,包括2 708个节点和5 429条边,其中每个节点代表一篇论文,每条边代表论文之间的引用关系。所有论文根据学科领域被划分为7个类别,且每篇论文具有一个1 433维度的属性向量,属性向量提取自论文中的关键词。
②Citeseer引文数据集的子集,包含3 312个节点(论文)和4 732条边(引用关系)。论文来自计算机科学和信息科学等相关领域,共分为6个类别。每篇论文具有一个3 703维的属性向量,属性向量提取自论文的题目和摘要。
③Wiki数据集来自Wikipedia,共包含2 405个节点和17 981条边,其中每个节点表示一篇文章,边表示文章之间的链接关系。所有节点被划分为17个类别,且每篇文章具有一个4 973维度的属性向量。
将这三种数据集的信息整理如表4所示。

表4 三种数据集的信息
4.2 节点分类实验结果
将代表性算法在不同数据集上学得的表征向量输入到one-vs-all分类器中,并选取一定比例的节点进行有监督训练,目标是预测剩余节点的标签。在节点分类任务中选用Micro-F1和Macro-F1这两种常用的评价指标对分类结果进行评价。图10、图11和图12分别为代表性算法在Cora、Citeseer和Wiki数据集上的实验结果,其中各个子图的横轴代表数据训练的比例,纵轴表示两种指标(Micro-F1和Macro-F1)的评价结果。从图中可以清晰地对不同算法的实验结果进行观察和对比。总的来说,结合属性信息的表示学习算法在节点分类任务中的表现更加优越。

图10 Cora数据集上的实验结果
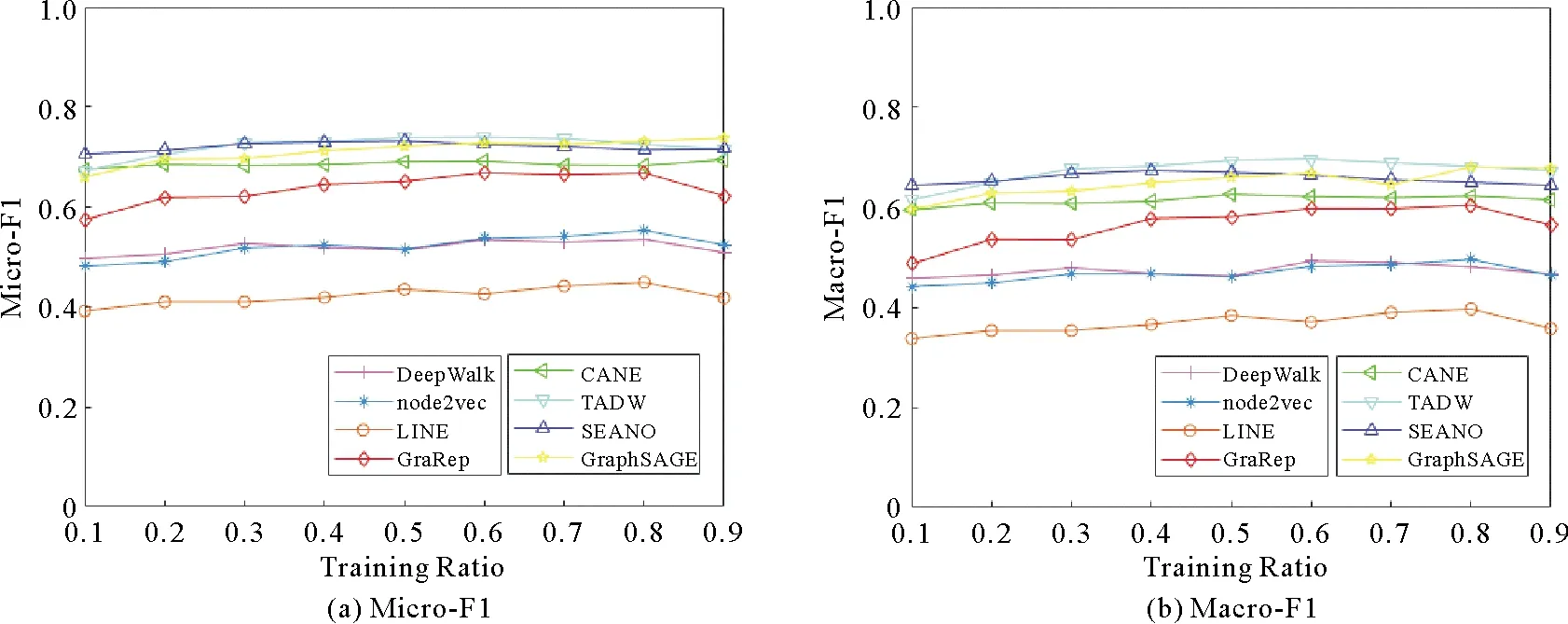
图11 Citeseer数据集上的实验结果

图12 Wiki数据集上的实验结果
5 总结
本研究面向同构网络和属性网络,对相关代表性的网络表示学习算法进行了分类介绍和比较。与基于拓扑信息相比,结合网络中蕴含的属性信息进行表示学习更易捕获到真实网络中的复杂关系,也能获得更具区别力的表征向量。网络表示学习研究虽然已经取得了丰硕的成果,但仍然面临着巨大的挑战:
1)大规模网络表示学习。在实际场景中的社交网络规模可达到上亿节点,然而已有的网络表示学习模型无法应对此类规模的网络。同时网络中包含的噪音甚至误导性数据也逐渐增多,面对噪音数据应该如何有效处理、过滤,也是网络表示学习需要考虑的问题之一。
2)网络动态变化的适应性。随着5G时代的来临,网络结构及其包含的信息瞬息万变。如何将网络表示学习方法与时代的发展步伐相匹配,对动态变化的网络进行表示学习,值得进一步研究。
