基于GPS数据的交通出行模式及转换点识别算法
2021-02-24朱少武孙海春罗万杰赵晓凡
朱少武,孙海春,罗万杰,赵晓凡
(中国人民公安大学 信息技术与网络安全学院,北京 102623)
伴随着移动通讯设备普及应用,全球定位系统(global position system, GPS)产生的数据对个人位置的展现越来越充分。依据GPS数据识别个人的交通出行模式,可以对居民出行信息准确摸排,有助于城市交通规划和管理,解决当前城市中存在的公交线路规划、交通拥堵等问题;也可分析个人的出行特点,并有针对地推荐相关服务。利用转换点识别算法识别出GPS轨迹数据中的出行模式转换点,可以分段对GPS数据进行分析研判,给出出行模式标签,最终得到整段GPS数据的出行模式变化过程。
分类算法的不同对最终识别结果的精度有很大的影响。出行模式识别算法主要使用神经网络、随机森林、支持向量机等分类算法。Liang等[1]利用卷积神经网络(convolutional neural networks,CNN)进行识别,并加入一些滤波算法对数据进行平滑处理来降低数据的波动,其最高识别精度在94%左右。Xiao等[2]利用贝叶斯网络和K2算法,最终得到的步行模式识别率超过97%。Martin等[3]开发了一种新的分类算法,并与K近邻分类算法(k-nearest neighbor,KNN)和随机森林算法进行对比,实验表明结合随机森林算法的识别准确率更高,约为94%。Zhu等[4]提出一种出行模式选择模型和一种有向图引导的融合Lasso方法,降低了出行模式研判算法的时间复杂度。Guvensan等[5]提出基于分段的传输模式检测体系结构,其综合识别准确率在93%左右。此外,有效的识别特征对提升出行模式识别准确率很有帮助。Sun等[6]结合谱聚类分析和隐Markov模型,加入位置信息和信号强度等特征,得到的出行模式算法平均识别准确率超过93%。Dabiri等[7]使用CNN算法,利用急动度和方向变化率辅助算法的识别,相比之前研究的准确率提升超过10%。
一些研究利用深度数据挖掘大幅度提高了单种出行模式的识别准确率。Wang等[8]提出地铁模式单独识别的方法,并结合地理信息系统(geographic information system, GIS)进行精度识别,使得地铁模式的识别准确率超过98%。Zong等[9]提出步行/骑行模式单独识别的方法,在3万余条数据中识别正确率接近100%。然而,一段出行记录中往往涉及多种出行模式。确定出行模式转换点是识别过程的难点,而要精准地识别出一段GPS日志中的不同出行模式更为困难。针对多种模式转换问题的深入研究较少,沈云[10]对转换点进行了研究,对比了基于多段窗口识别和基于移动窗口识别,其多段窗口识别率达到78.8%,移动窗口识别率达到76.7%。
目前围绕识别算法的改进大多侧重于提供新的识别算法和新的运动特征,得到了较高的识别精度。已有研究中速度特征选取以平均速度和分位速度为主,但平均速度和分位速度受其他干扰因素影响较大。受到整体速度变化过程的影响,每个静止点的增加会在一定程度上降低平均速度和分位速度。同时,停留点的次数特征受到出行距离的影响,出行距离长的样本的停留次数相对更高。本研究通过“稳定速度”和“平均停留间隔”两个特征来弥补以上不足,并提出了基于低速度移动研判的出行模式转换点识别方法,通过转换点将GPS轨迹分段研判,进一步提高出行模式识别的准确率。
1 基于低速度移动研判的转换点识别方法
出行模式转换点识别是出行模式识别过程的重要组成部分,转换点识别的准确率很大程度上影响了出行模式研判的正确率。目前有两种典型的转换点识别方法:基于多段窗口的识别方法和基于移动窗口的识别方法[10]。在移动窗口的识别方法中,通常利用遍历的方式,计算每一个数据点窗口两侧的欧氏距离;比较两侧的相似度大小,将低于一定阈值的点认定为转换点。
通过观察个人GPS轨迹数据,对个人出行模式中交通方式的转换过程进行了分析,发现:①每一次交通出行模式转换均包含一定的时间间隙,而这段时间间隙总是被步行模式或者静止模式占用;②由于步行模式和静止模式本身的速度特性,相对其他的出行模式来说可以较为简便地区分。利用以上特征,对基于移动窗口的转换点识别方法进行改进,提出一种基于低速度移动研判的出行模式转换点识别方法。
将一段GPS轨迹数据表示为:G0={g|g=(Lat,Lon,H,date,time)}。其中g代表某一个时刻的GPS数据,由5个维度数据组成,分别指某个时刻的纬度值、经度值、海拔高度、日期、时间;转换点集合表示为T={g|g∈G0∧g是转换点}。此外,设定一个速度阈值经验值V0和研判移动窗口的步长S,其中,V0指步行或者静止时人的最高移动速度,S决定取样的时间间隔。
首先将出行模式划分为步行模式与非步行模式两类。针对一段GPS轨迹数据中的出行模式转换点候选集的研判方法如下:
1)设定研判窗口大小Δt,设定研判移动窗口的步长S;
2)对于轨迹数据中某一时刻t的GPS数据g,依据研判窗口大小,完成g前后Δt时间内的GPS出行轨迹的数据取样;
3)分别研判取样窗口内轨迹数据的出行模式。如果两段样本中出行模式不同,则g计入转换点候选集;若果两段样本中出行模式相同,g不计入转换点候选集;
4)移动步长S,选取t+S时刻的GPS数据g′;
5)转入2),继续研判直到轨迹数据结束。
利用以上方法筛选出一段出行轨迹中的出行模式转换点备选集合。常规情况下,在较短的时间间隔内不会出现多次出行模式的转换。因此,设定筛选阈值ST,剔除时间范围内欧氏距离较小、相似度较大的转换点,留下时间范围内唯一的转换点。依据测试数据集情况设定时间ST=20 min。
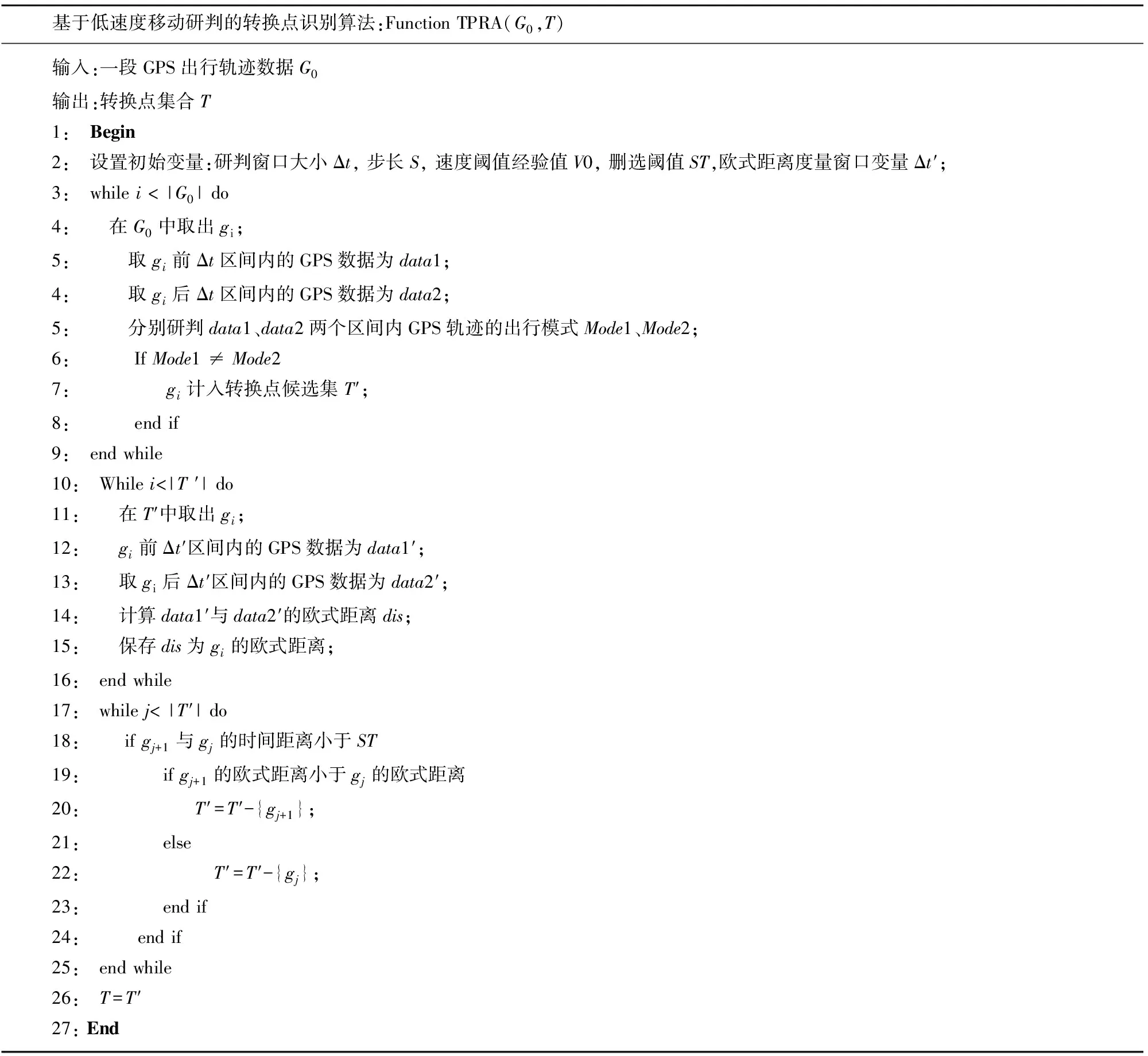
基于低速度移动研判的转换点识别算法:FunctionTPRA(G0,T) 输入:一段GPS出行轨迹数据G0输出:转换点集合T1: Begin2: 设置初始变量:研判窗口大小Δt,步长S,速度阈值经验值V0,删选阈值ST,欧式距离度量窗口变量Δt′;3: whilei<|G0|do4: 在G0中取出gi;5: 取gi前Δt区间内的GPS数据为data1;4: 取gi后Δt区间内的GPS数据为data2;5: 分别研判data1、data2两个区间内GPS轨迹的出行模式Mode1、Mode2;6: IfMode1≠Mode2 7: gi计入转换点候选集T′;8: endif 9: endwhile 10: Whilei<|T′|do11: 在T′中取出gi;12: gi前Δt′区间内的GPS数据为data1′;13: 取gi后Δt′区间内的GPS数据为data2′;14: 计算data1′与data2′的欧式距离dis;15: 保存dis为gi的欧式距离;16: endwhile17: whilej<|T′|do18: ifgj+1与gj的时间距离小于ST19: ifgj+1的欧式距离小于gj的欧式距离20: T′=T′-{gj+1};21: else22: T′=T′-{gj};23: endif24: endif25: endwhile26: T=T′27:End
2 借助转换点识别的GPS轨迹出行模式生成方法
研判输出一段GPS轨迹的出行模式分5步进行:①将一段GPS数据进行预处理,如:滤波、插值等,剔除脏数据;②根据清洗后的数据计算相关特征;③通过上一章的转换点识别算法识别出GPS轨迹中的出行模式转换点,依据转换点将一段GPS数据分为不同子段;④利用随机森林分类器,研判不同子段的出行模式;⑤依照时间次序将模式标签连接,得到整段GPS数据携带的出行模式信息。方法的总体框架如图 1所示。
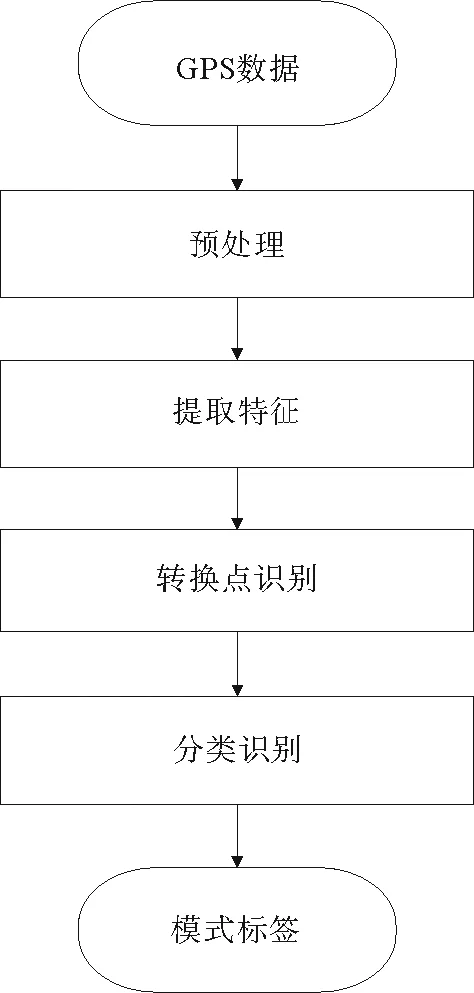
图1 出行模式识别框架图
2.1 数据预处理
2.1.1 高斯滤波
鉴于定位系统的准确性,所有的GPS定位数据都无法绝对精确地定位被采集位置,收集的数据会在一定范围内波动,产生不必要的噪声,因此需要将其进行平滑处理。参考黄仁等[11]、孙冰怡等[6]、Liang等[1]的工作,利用滤波方法将数据进行平滑处理。具体地,利用高斯滤波算法,滤除掉数据中的高斯白噪声。
gi.Lat=(gi-1.Lat+gi.Lat+gi+1.Lat)/3。
(1)
其中:gi.Lat为滤波后的第i点经纬度值,gi-1.Lat为原GPS数据中第i-1点经纬度值,gi.Lat为原GPS数据中第i点经纬度值,gi+1.Lat为原GPS数据中第i+1点经纬度值。用一点及其附近点的平均值代替这一点的原值,能够降低数据的突变,使轨迹变得更平滑、连续,更符合实际情况的变化规律。
2.1.2 插值法
由于信号传输的不稳定或定位系统采集的问题,在某些时间点上的数据会产生缺失,而在一些信号弱或无信号的隧道等地区甚至会出现大面积的数据缺失,严重影响模式识别。为此,需要将这些数据进行修补,在一定程度上保持数据的合理性。
实验采用了一维线性插值法来补充缺失的数据,使数据频率更稳定。具体地,利用缺失点两侧的数据,将两侧数据的时间、经纬度取均值,按时间以匀速状态插入缺失点。
gi=(gi-1+gi+1)/2。
(2)
其中,gi为缺失点GPS数据,gi-1为缺失点上一时刻GPS数据,gi+1为缺失点下一时刻GPS数据。对缺失点的值进行预测,数据标注为缺失点前后相应数据的均值。
2.2 特征的选择
实验选定中位速度、95%分位速度、平均速度、稳定速度、平均停留间隔作为出行模式识别算法的基本特征。特征的选择主要针对速度类进行提取,用95%分位速度代替最高速度,是因为最高速度有可能无法反映真实的速度,是突变的,波动性较强。中位速度、95%分位速度、平均速度的计算很多文献中都有,在此不赘述。
一段完整的速度数据,必然会有加速-匀速-减速的过程。在运动过程中,取均值会受到加减速时速度变化的影响,使得提取值不准确。而提取稳定速度,可以避免加减速对于提取值的影响,从而得到更为准确的提取值。实验采用以下方法提取一段GPS轨迹数据的稳定速度SV。首先,识别出一段完整的加速-匀速-减速的过程,作为运动趋势;在这段运动趋势中取匀速段的平均速度作为稳定速度。一段GPS轨迹数据G0={g|g=(Lat,Lon,H,date,time)},其中g代表某一个时刻的GPS数据。用符号P=(Lat,Lon,V,A,date,time)表示GPS数据的特征数据,其中6个的维度数据分别指某个时刻的纬度值、经度值、速度、加速度、日期、时间。g的特征数据表示为Pg,G0的特征数据表示为PG0。
此外,许多研究在识别中采用停驻点作为研判出行模式的基本特征。如Liang等[12]利用公交站停留点占总停留点的比率,提高了bus模式的识别准确率。但在实际中,受到出行段总时间、总距离的影响,停驻次数会产生较大的差异。出行时间长、距离较长的出行段,停驻次数更多。因此,结合出行距离与停驻次数,得到平均停留间隔,在一定程度上消除了出行时间、距离对出行模式研判的干扰影响,对模式识别有较大帮助。
Asd=D/SN。
(3)
其中:Asd为平均停留间隔,D为出行段的总路程,SN为出行段中停驻次数(采集点后10 s速度小于0.3 m/s时判定为停驻点)。平均停留间隔代表平均情况下两次停驻之间的距离。对于公交、地铁等停驻有规律的模式具有较好的识别效果。

稳定速度提取算法:FunctionSVE(P,SV) 输入:一段GPS轨迹的特征数据PG0输出:本段GPS轨迹的稳定速度特征SV1: Begin2: Whilei<|PG0|do3: 取出Pgi;4: ifabs(average(Pgi-5.V,Pgi-4.V,…,Pgi-1.V)-Pgi.V)<0.2m/s than5: m=i+5;6: whilem<|PG0|do7: ifabs(average(Pgi+m+5.V,Pgi+m+4.V,…,Pgi+m+1.V)-Pgi+m.V)<0.2m/s than8: MV←i至i+m的中位速度;9: else m+1;10: endif11: endwhile12: i=i+m;13: elsei=i+1;14: endif15: SV←average(MV); endwhile16: End
2.3 随机森林分类器
随机森林算法的本质是利用阈值进行的二分法,更适合解决分类问题[12-14]。因此,实验将一段GPS轨迹的出行模式识别问题转换为分类问题,采用随机森林算法完成出行模式识别。
随机森林是由决策树改进而来,由多棵决策树组成。对于单棵树,在训练模型时,通过随机选取数据和特征创建结点,结点值定为将数据最优分割情况时的界值,即分割后GPS数据的出行模式某一种标签占全部数据比例最高的情况。当标签种类唯一时,停止生长。用模型识别时,将待测数据与结点的值进行比较,相应落到某一个子结点中,重复比较特征。当数据掉落到某一个叶子结点中时,叶子结点的标签就表示为这段GPS轨迹数据的识别结果。将所有决策树的识别结果进行投票,得票最高的模式标签定为这片随机森林的识别结果。
2.4 算法实现过程
将一段GPS轨迹数据表示成:G0={g|g=(Lat,Lon,H,date,time)},G0对应的出行模式序列表示为M=〈M0,M1,…,Mk〉,其中,M0代表G0中第一个子段的出行模式标签。
首先对收集的GPS轨迹数据进行预处理和特征计算,处理过程见2.1和2.2节;然后,将不符合一般规律的数据剔除,如步行速度大于10 m/s的;通过转换点识别将待测数据分段,并利用训练好的模型对数据进行模式识别,得到对应的出行模式标签;最后,将得到的模式标签组合形成预测结果。
符 号 说 明
3 实验结果与分析
3.1 测试条件与数据集
实验所采用的硬件条件是:主板,华硕 X455LJ;CPU,(英特尔)Intel(R)Core(TM)i5-5200U @ 2.20 GHz;内存,12.00 GB(1 600 MHz)。软件环境是Microsoft Windows 10 企业版(64位)、Pycharm集成开发环境。
由于研究者所采用的数据集的收集方式有所不同,因此各个数据集中的异常数据量会有很大不同,导致识别的准确率不同,所以需要将差距较大的数据集分开对比。收集的数据集分为自主收集数据集和工程数据集。自主收集的数据一般是由手机App的内置功能实现,采集个体一段时间内的运动情况。工程数据集是由专业的某项工程收集测定,例如大多数研究[4,7,12,13,17]采用的工程—Geo Life project[15-16]。相对于App收集的数据,工程收集的数据更具有专业性、准确性、客观性。实验选用Geo Life project数据并进行了筛选,最终采用982条单出行模式个人数据、65条多模式个人数据完成测试。

GPS数据的交通出行模式序列识别算法:FunctionTME(G0,M) 输入:一段GPS出行轨迹数据G0输出:G0对应的出行模式序列M1: Begin2: Whilei<|G0|do3: gi.Lat=(gi-1.Lat+gi.Lat+gi+1.Lat)/3;4: i=i+1;5: Endwhile6: Whilei<|G0|do7: gi=(gi-1+gi+1)/2;8: i=i+1;9: Endwhile10: T=FunctionTPRA(G0,T);11: whilej<|T|do12: G0′={g|gj.time<=g.time 将“稳定速度”和“平均停留间隔”这两个新增特征加入,对以往基于随机森林的出行模式识别算法进行改进,并将改进后的算法与已有算法的识别准确率进行对比。 测试发现,在每次训练与识别时,算法的准确率略有不同。为降低测试结果的偶然性,重复进行30次测试。具体地,进行了30次模型训练,产生30片随机森林,取30片森林的平均准确率作为改进后算法最终的准确率,如表1所示。随机森林算法训练过程中,树的数量直接决定了模型的准确度,但当数量到达一定程度后,模型会产生过度拟合,可解释性减弱,导致准确率降低,并且会大大增加模型构建时间。经过多次测试,选定每片森林为60棵树。此外,实验计算了30次识别准确率的方差,对算法与已有算法的稳定性进行了分析,如表2所示。 表1 添加新特征前/后的30次训练识别准确率表 表2 添加新特征前后准确率对比表 与已有算法比较,本算法的平均准确率上升了1.3%,识别准确率波动情况明显改善。综合看来,增加稳定速度与平均停留间隔两个特征对提升出行模式识别算法的准确性有较好效果。 同时,出行模式识别中速度的贡献度较高(贡献度高的特征在识别中的重要性越高,识别时所用到的频率越高,添加后识别准确率也就越大),最大速度、平均速度、中位速度是出行模式中的最主要特征。而添加新的特征后,识别准确率有小幅上升,表明所添加的特征对于不同模式的区分度高于原有特征。 在30片森林中选取识别最优的森林模型用作测试出行模式识别混淆矩阵,如表3所示。混淆矩阵也称误差矩阵,用于比较分类结果和实际测得值,能够清晰地反映出识别值与真实值的关系。在识别最优的情况下,可以最大程度上降低自然误差,更能反映实际的数据与算法对于识别准确率的影响,便于对特征和算法的分析。 表3 添加新特征后/前的出行模式识别混淆矩阵 由表3可知,受到数据限制,在训练集中bus和subway模式较少,在训练过程中不能很好地拟合这两种模式的特征,从而bus和subway模式的识别率明显低于其他模式的识别准确率。在添加稳定速度与停留特征之后,bike模式的识别准确率略有提升。bike中误识为walk和bus模式均有减少,表明两种新特征有助于提高识别的稳定性。 在数据限制的情况下,bus模式与bike、subway、car模式均有交织,在添加停留特征后,识别率明显上升。因此对于含有bus模式的识别,添加停留特征有利于提升识别准确率。 walk与bike模式识别中,相互均有5%~10%的误识率(walk识别为bike或bike识别为walk)。实验选取以速度特征为主时,walk与bike模式在速度上有较大的重合,对于识别准确率产生较大影响。因此,对于需要明确区分walk与bike模式的场景,需要再添加可以明确区分两种模式的特征。 出行模式转换点识别算法利用了步行模式速度低的特性。设置了一个速度阈值经验值V0和步长S。正常人步行速度约为1.5 m/s,其他模式的正常速度都大于这个数值,偶尔产生的低速情况持续时间也较短。研判窗口Δt=300 s能够排除偶然情况的干扰。将300 s窗口内的平均速度与速度阈值经验值V对比,能够有效地区分步行模式和其他模式。同时,步长过小会使得移动前后的窗口区别较小,产生无意义的数据。在保证识别准确率的情况下,尽可能地增大步长能够有效降低识别时间。 对于转换点识别,由于单一的准确率无法正确描述识别准确率,给出以下准确率判别方法: precision:查准率,代表识别出的真实转换点占识别全部转换点数的比例。 (4) recall:查全率,代表识别出的真实转换点占实际全部转换点的比例。 (5) F-score:准确率,代表查准率与查全率的均值,作为识别的准确率。 (6) 其中:Nt是识别正确的转换点个数,Np是识别的全部转换点个数,Nr是实际出行中应有的转换点个数。 将F-score作为最终识别的准确率可以有效针对识别转换点冗余和漏识问题,较为准确地描述识别准确率。转换点识别准确率如表4所示。 表4 转换点识别准确率对比 由表4可知,所提出方法的查全率较高,而查准率较低。在识别正确个数一定的情况下,查准率较低而查全率较高,表明识别出的转换点数量比真实的全部转换点数量要多,即识别的转换点冗余较大。横向比较发现,由于本方法是基于移动窗口的识别方法改进的,在程序上还保留着移动窗口的框架,因此准确率与移动窗口识别类似,呈现查准率较低、查全率较高和转换点多冗余的特征。 实验随机选取一段GPS数据,将移动窗口方式与本方式进行对比。为避免偶然因素对实验结果的影响,对同一段数据进行10次识别,识别时间如图 2所示。 图 2 转换点识别时间对比图 在移动窗口的研究中,需对数据进行遍历,计算特征的欧氏距离时间复杂度较高。已有工作[10]对数据集中每一点前后的欧氏距离做了计算,先提取了前后数据集的特征,然后通过特征计算得到前后的欧氏距离,提取欧氏距离的极值点,最后进行筛选。算法用移动步长代替遍历,并且只判断窗口内的平均速度,减少了计算量。判定为初步转换点的窗口后,才进行模式识别和欧氏距离计算。由实验结果可知,本算法的时间复杂度有明显降低。 研究针对GPS数据进行挖掘,从一段GPS数据中研判出这段数据的出行模式及其转换点。通过“稳定速度”和“平均停留间隔”两个特征的加入,交通出行模式识别的整体精度和bus模式识别准确度有较大提高,但对于walk和bike两种模式的识别效果改善不明显。此外,由于数据集限制,用于训练的数据较少,对于bus模式和subway模式的识别尚不能做出精确判断。 选用训练数据集中转换间隔较长的数据较多,使本算法对长间隔转换数据的识别精确度较高,对于长时间GPS数据的转换点识别有较好的应用价值。 本研究提出了一种基于低速度移动研判的出行模式转换点识别方法,增加了两种用于出行模式研判的新特征。通过步行模式的低速特征和转换点两端的欧氏距离判断出GPS轨迹数据中的出行模式转换点,并利用“稳定速度”和“平均停留间隔”提高了出行模式识别的精度。通过对比实验发现,本研究提出的方法能够较好地提高长时间GPS数据的模式识别的准确率和转换点识别的准确率、降低转换点识别的时间复杂度。但是,研究的转换点研判算法不适用于短时间内多次模式转换的情况,模式识别也仅局限在设定的5种模式中。下一步将针对短时间内多次转换的情况进行研究。3.2 出行模式识别测试对比结果



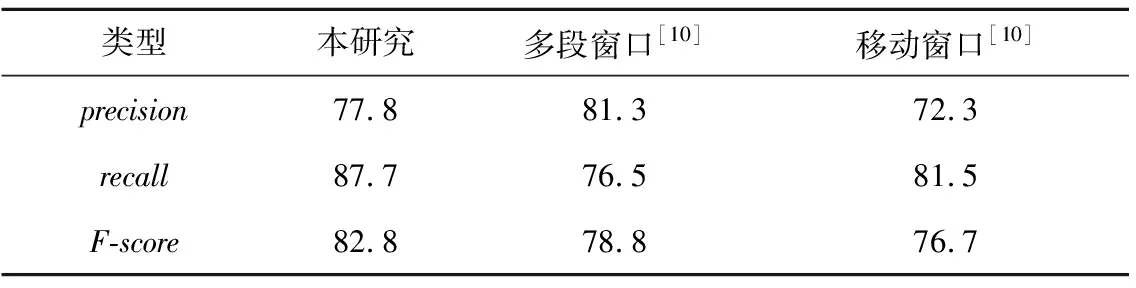
3.3 出行模式转换点测试对比结果

3.4 实验结论
4 结束语
