不同数据分析方法用于出血性中风证候分析的对比研究*
2021-02-23张琳婷张根明
张琳婷,张根明
1.北京中医药大学,北京100029;2.北京中医药大学东直门医院,北京100700
证候的研究一直是中医的热点和难点,包括对于各个疾病的证候研究[1-3]、证候研究的新思路[4]、证候的规范化研究[5-7]等。如何将中医证候模糊语言叙述转化为现代医学所能理解的科学语言是证候研究中的重要问题。为此,近年来中医证候研究中引入了越来越多的数据分析和挖掘的方法[8-11]。本研究采用了因子分析、聚类分析、Logistic回归分析、Fisher判别分析4种方法对出血性中风证候进行分析研究。因子分析和聚类分析属于无监督的数据分析方法,对原始数据信息依据样本本身特征进行归类,把具有相似特征的目标数据归在同源的类别,并采用相应的可视化技术直观地表达出来。Logistic回归分析和Fisher判别分析属于有监督的数据分析方法,利用先验因素(专家经验辨证)对数据进行辨识、归类和预测。本研究从无监督和有监督的数据分析方法中各选取两种,以探讨不同方法在中医证候分析与挖掘中的差异。
1 资料与方法
1.1 一般资料研究病例来源于“国家中医药管理局国家中医临床研究基地业务建设科研专项——出血性中风证候要素诊断量表编制研究”,2016年6月至2019年1月于北京中医药大学东直门医院、太原市中医院、长春中医药大学附属医院门诊及住院收治的脑出血患者499例。
1.2 诊断标准西医诊断标准:采用《中国脑出血诊治指南(2014)》脑出血诊断标准[12]。①急性起病;②局灶神经功能缺损症状(少数为全面神经功能缺损),常伴有头痛、呕吐、血压升高及不同程度意识障碍;③头颅CT或MRI显示出血灶;④排除非血管性脑部病因。
中医诊断标准:采用1995年中国中医学会内科学会脑病专业委员会提出的《中风病诊断与疗效评定标准》[13]。
1.3 病例纳入与排除标准纳入标准:①符合脑出血诊断标准[12-13]的患者;②发病在90 d以内;③年龄>18岁;④自愿参加本研究并签署知情同意书。排除标准:①蛛网膜下腔出血、脑外伤引起的脑出血患者;②梗死后出血患者;③合并其他器官的严重疾病;④精神障碍或严重痴呆。
1.4 研究方法将出血性中风临床常见的四诊信息(包括症状、舌、脉)编制成统一的调查表。参照《中风病诊断与疗效评定标准》,分为风、火、痰、血瘀、气虚、阴虚、阳亢7个基本证候要素。分析2000年之后有关出血性中风的证候学相关研究,整理其中提到的证候要素出现频率进行排序,将出现频率≥10%的证候要素作为研究备选证候要素,增加湿、气滞、阳虚3个证候要素。选择有临床经验的中医神经内科医师,按统一要求填写调查表格,记录患者四诊信息,同时由固定的3位临床医师背对背做出证候要素是否存在的判断,每位患者允许同时存在多个证候要素。
1.5 统计学方法采用EpiData3.1数据库录入数据,采用SPSS 20.0进行统计分析处理。计量资料以均数±标准差(±s)表示;计数资料以频数(百分比)表示。检验水准为双侧α=0.05。主要统计方法包括:因子分析、聚类分析、Fisher判别分析、Logistic回归分析。
2 结果
2.1 因子分析对217个四诊信息进行频率分析,保留频率≥10%的89个变量用于进一步数据分析。进行KMO 检验和Bartlett球形检验,结果显示KMO=0.848,Bartlett球形检验P=0.000,数据可以做因子分析。采用主成分分析法,最大方差法旋转,保留因子载荷系数>0.3的变量,因子分析结果见图1、表1。
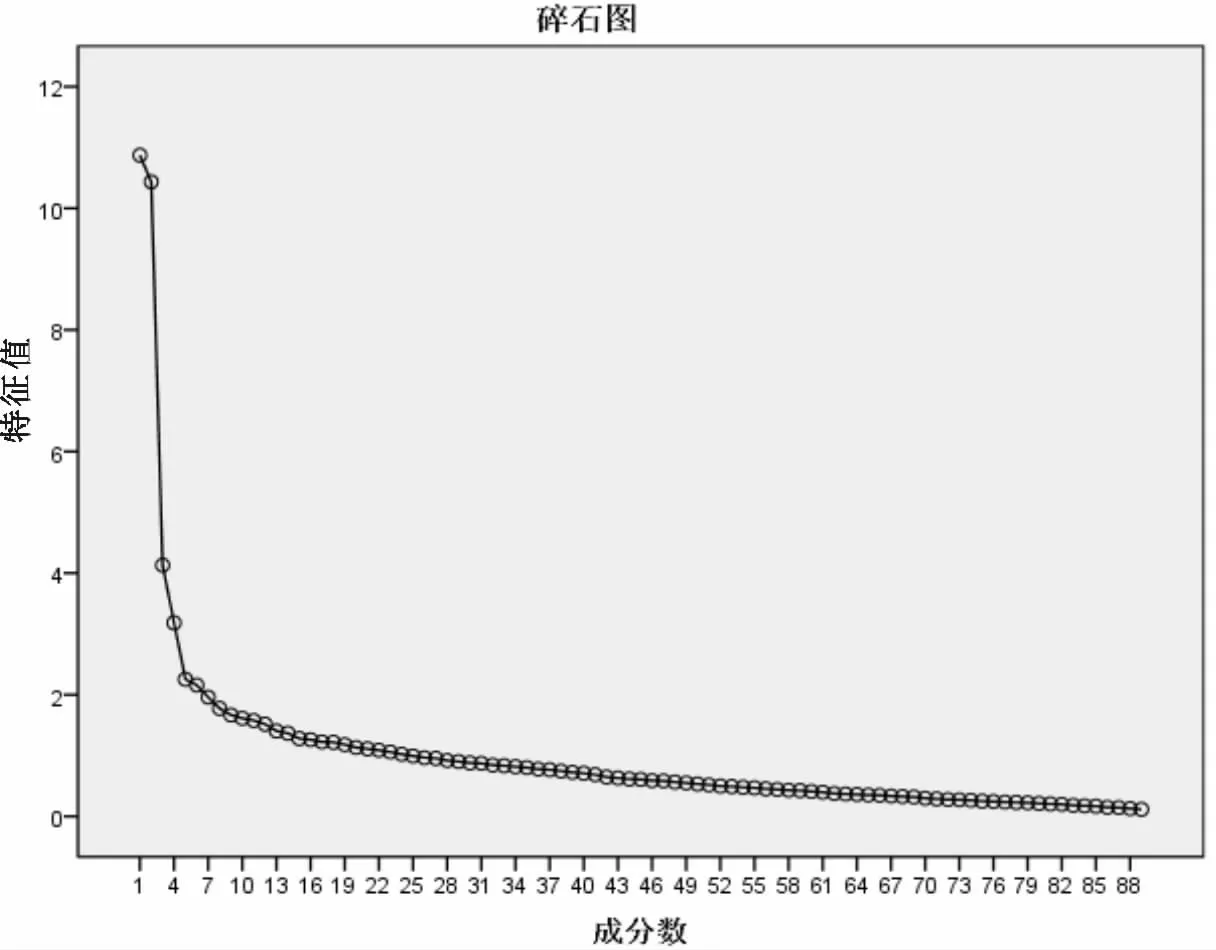
图1 因子分析碎石图

表1 因子分析
2.2 聚类分析对89个变量分别进行层次聚类分析和K-means聚类分析,K-means聚类过程中K值分别取4~10,K值为5时效果相对较好,聚类结果见图2、表2。
2.3 Logistic回归分析以89个四诊信息为协变量,10个证候要素分别作为因变量,采用“向前:条件”方法做Logistic回归分析,结果见表3。
2.4 Fisher判别分析以89个四诊信息为自变量,10个证候要素分别作为分组变量,采用步进式方法做Fisher判别分析,结果见表4。

表2 K-means聚类分析

表3 Logistic回归分析

表4 Fisher判别分析
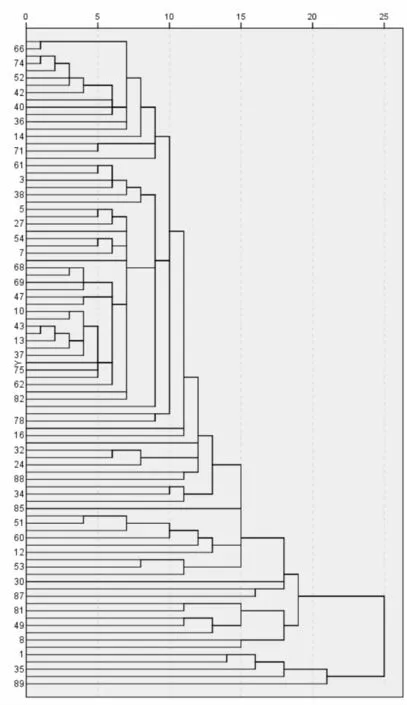
图2 层次分析树状图
3 讨论
本研究表明,因子分析更多的是基于出血性中风整个疾病的降维分析,代表了出血性中风出现频次多的证候,而出现频次少的证候则难以体现。公因子F1、F2的特征值及方差贡献度远大于其他的公因子,F1、F2中的变量数量都比较多,就其临床意义而言并没有代表单一证候要素,而是多个证候要素的组合,大体而言,F1代表了实证、F2代表了虚证。因子分析并没有如我们所预期的出现多个相对大的且能被中医理论解释的公因子。从公因子F3以后,每个公因子中所含的变量数目急剧减少,其对总方差的贡献度也很小,但某些公因子也仍然很有意义,例如公因子F7中的消瘦、瘦薄舌、脉细按中医理论都是阴虚的表现,而仅就数据自身的特征也确实被分到同一公因子,代表了理论与实际的统一。
聚类分析效果不佳,层次聚类没有很清晰地分为几个大的类别,K-means聚类较层次聚类稍好一些。一个患者同时具有几个证候要素兼夹,而层次聚类和K-means聚类的过程中都只能将1个患者分类到1个证候类型,导致每一个聚类组中可能有多个证候要素,而非单一的证候要素,使得每个聚类中的证候特征显得并不明确。K-means聚类过程取K值>5发现聚类组彼此会有明显的重复和相似性,表明更多的分类可能是不合理的,将出血性中风证候分为10个证候要素可能分类过于细致。
Fisher判别分析、Logistic回归分析在出血性中风的不同证候的表现类似,但不完全一致。两者在内火证、痰证、湿证、血瘀证、阴虚证均表现较好,内风证、气滞证、阳虚证、阳亢证均表现相对差一些,而在气虚证Logistic回归优于Fisher判别。在Fisher判别分析、Logistic回归分析中,先验因素(专家经验辨证)对最终的结果影响会非常大。以内风证为例,不同专家对内风证的认识存在差异性,尤其在中风病中,有相当一部分专家认为急性起病、病情波动大符合风善行数变的特点,属于风的表现。这就把风的概念扩大和类推,从而认为中风病必有风的存在,导致最终进入内风证的四诊信息多种多样且与传统认识中的风证并不一致。此外,用这两种分析方法得到的血瘀证的四诊信息是一致的,但均见口唇淡白、气短、神疲乏力这3个明显为气虚的症状,考虑在出血性中风中血瘀常伴见气虚,从而难以将血瘀完全独立出来。气滞证、阳虚证、阳亢证在499例患者证候中出现频率相对较少,且几乎都兼夹内火证、痰证等,几乎很少单独出现,导致Fisher判别分析和Logistic回归分析的结果相对差一些。
总体而言,有监督的数据分析方法比无监督的数据分析方法更有效率,更加符合传统中医的认识。无监督的数据分析方法则和传统的认识有一定的差距,可能有以下几个方面的原因:①无监督的方法需要更长时间、更多数据的训练,仅凭499例患者的分析、训练肯定是难以达到几千年中医认识的水平;②中医的很多证候不完全是根据临床经验归纳而来的,融入了哲学的思维[14-16],不仅是理性的思考,也是感性的认知;③证候具有动态时空、内实外虚、多维界面的特征[17],证候的“内实”能够在数据分析的过程中被归为一类,但“外虚”可能反而与其他的证候关系更为紧密而归到其他类别。但是,无监督的方法对于进一步发展中医的理论是非常有益的,通过无监督的方法可能是验证过去的已有的中医理论,也可能是完善和修改已有的结论,也可能是发现潜在的未被认识到的证候规律;而有监督的方法则只能把我们现有的中医认识通过数据分析方法规范化、清晰明了地展现出来。此外,有监督的数据分析方法也有其难以克服的缺陷,就是其受先验因素(专家经验辨证)的影响很大。目前,中医证候研究缺乏统一的金标准。目前,证候研制往往以临床医师或专家判断作为参考标准,依据个体的知识水平和临床经验,辨证结果必然存在差异,可靠性难以保证。本研究选用3位临床医师背对背做出证候要素是否存在的判断也考虑到这方面的原因。在这种情况下,基于这种“金标准”进行有监督方法的数据分析、挖掘结果往往缺乏说服力,很难得到广泛认可与应用,导致很多的证候研究会不够客观以及难以摆脱先入为主的经验框架。
综上所述,每种数据分析方法各有优势,单一的数据分析方法不能同时满足我们证候研究中的多种需求。在中医证候研究的过程中,应当根据自己的研究实际选用多种数据分析方法,取其优势,或者引入其他更复杂的数据分析方法。
