基于ANP-RF算法的泥石流严重度评估
2021-02-23王艳锦武晓春郭荣昌
王艳锦,武晓春,郭荣昌
(兰州交通大学 自动化与电气工程学院,兰州 730070)
泥石流自身的复杂性和不确定性使得泥石流的评估成为研究难点,文献[1-2]研究表明,泥石流多发生在山区,大雨则更可能直接导致泥石流的爆发;文献[3]利用多元回归计算风险因子权重,计算过程较复杂;文献[4]提出使用数字高程模型(digital elevation model,DEM)进行了区域敏感性评估,DEM作为评估的唯一数据集;文献[5]利用基于模糊数学的层次分析方法,对研究区内泥石流灾害进行危险性评估,但主观性较强;文献[6]运用遥感和GIS技术进行数据处理与综合分析,对各条泥石流沟的危险性进行评估;文献[7]以单沟危险度及易损度作为基础评价指标,在不同降雨频率下评估单沟泥石流灾害风险,但评估方法不适用于未发生泥石流的区域;文献[8]以雨强、坡降和物源作为三要素进行泥石流危险性的评价,但未考虑因素之间的相关性.综上研究,对泥石流灾害严重度的评估多采用主观赋权或者客观验证的方法,主观赋予权重易造成评估准确度的降低,且未能考虑因素间的关联性;基于历史数据的客观权重则对未发生过泥石流区域的评估适应性较差.
基于此,首先选出与泥石流灾害严重度相关的因素;对各因素进行预排序,考虑因素间的影响和作用,采用网络分析法(analytic network process,ANP)计算主观权重;采用随机森林(random forest,RF)计算客观权重,并利用相对熵建立数学模型求解组合权重;最后以成康铁路为例,综合加权得出沿线泥石流灾害严重度结果,并对照四川省泥石流风险区划图,验证评估方法的合理性和准确性.
1 ANP-RF评估方法介绍
1.1 ANP原理
ANP是在层次分析法的基础上,考虑了各层次内部元素的依存性、低层元素对高层元素的支配作用后得到的一种系统决策方法.ANP结构模型包括控制层和网络层,网络层包含受控制层支配的所有元素[9-11].典型的ANP结构模型如图1所示.
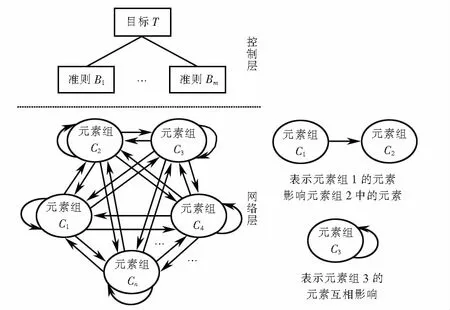
图1 网络分析法的结构模型Fig.1 Structure model of analytic network process
设ANP模型中的控制层中有准则B1,B2,B3,…,Bm;网络层有元素组C1,C2,C3,…,Cn,其中元素组Ci包含元素Di1,Di2,…,Dini,以Bs(s=1,2,…,m)为准则,以Cj(j=1,2,…,n)中元素Djl(l=1,2,…,nj)为次准则,比较Ci中各元素对Djl的影响程度,构造判断矩阵并进行一致性检验;同理,构造Ci中各元素对Cj中其他各元素影响程度的判断矩阵,然后对各判断矩阵求其特征向量矩阵Wij(i=1,2,…,n;j=1,2,…,n),Wij反映了元素组Ci与Cj间的依存关系,合并所有的Wij便可得到超矩阵W,如式(1)所示.
(1)
以Bs(s=1,2,…,m)为准则,以元素组Cj(j=1,2,…,n)为次准则,构造网络层各元素对Cj的重要度判断矩阵,检验一致性,得到特征向量,从而得出加权矩阵,如式(2)所示.
(2)
(3)
1.2 RF算法
随机森林是采用多棵决策树进行训练,通过集成学习将多棵树集成的一种算法[12-13].该算法对样本数据进行有放回的抽取,建立多棵决策树后,以少数服从多数的原则,得到最终决策结果.随机森林进行特征重要性的评估,本质是确定每个特征在每棵树上所做贡献的大小,然后取平均值,从而得出各特征权重.RF算法生成决策树、进行决策的流程框图如图2所示.
1.3 组合权重
计算组合权重的方法有很多,其中:组合权重中的“乘法”适用于因素多、权重均匀分布的主、客观权重的组合;“加法”在参数大小确定上不具有唯一性.因此确定最终权重时仍受决策者的主观影响,或者存在主、客观一强一弱的问题[14-16].本文最终选择了利用相对熵计算组合权重的方法.相对熵的思想就是使最后权重与所有单一权重之间的叉熵总和达到最小[17].计算过程如下:
设有s个概率分布,假定组合权重结果为W0=(ω01,ω02,…,ω0l),为了计算方便,假定初始权重各自的合成结果为1/s,建立如下模型:
(4)
(5)
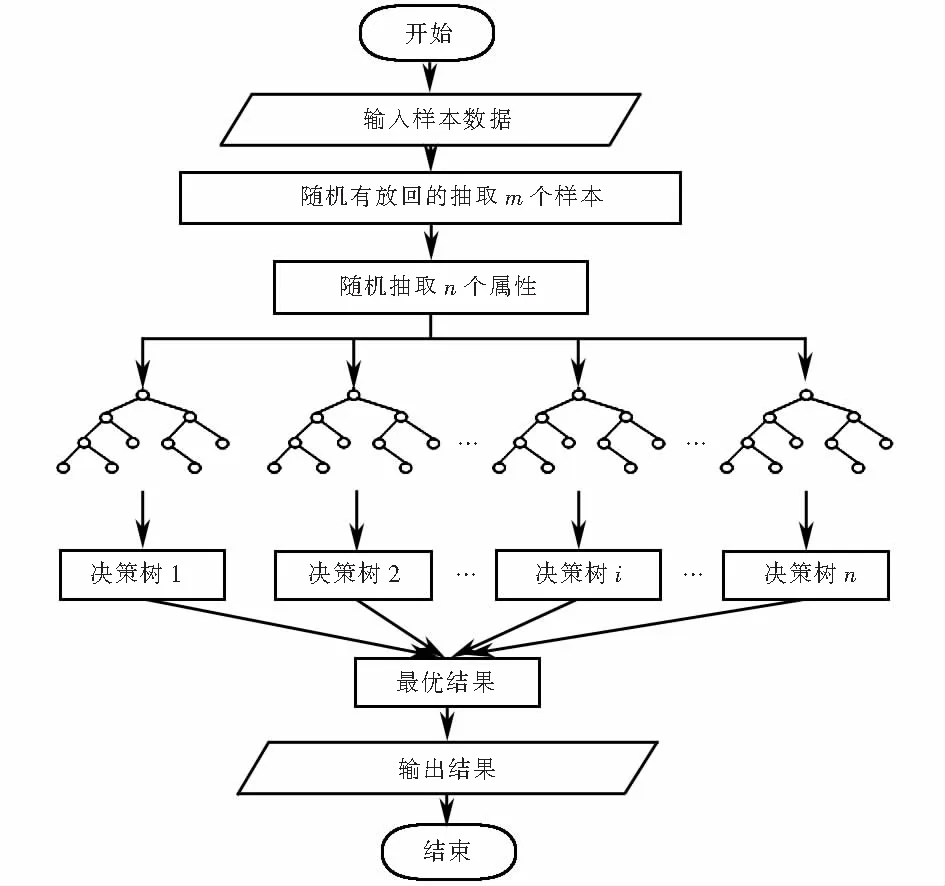
图2 RF算法流程框图Fig.2 RF algorithm flow chart
2 实例应用
2.1 严重度相关因素的选取
川藏铁路起于四川省成都市,经雅安、康定、林芝,抵达西藏拉萨,成康铁路是川藏铁路的重要组成部分,该段铁路位于四川省境内,全长约300 km,由于特定的地质地貌和水文气象环境,铁路沿线泥石流灾害极为活跃,具有活动规模大、危害程度高、影响范围广的特点.
分析泥石流灾害风险严重度时,指标选取依据泥石流发生的三要素,即地形地貌、物质来源和诱发原因.泥石流发生的可能性不等同于泥石流发生的严重度高低,当各指标对泥石流的发生有利时会引发更严重的泥石流.地形地貌有利固体、液体物质流动,丰富的物质来源和堆积物在外界因素的诱发下会爆发较为严重的泥石流.海拔和坡度可以为泥石流的发生提供一定的能量,植被覆盖度、土壤类型、土地利用类型等因素会影响泥石流发生的物质来源;汇流积累量、降雨等是泥石流的诱发因素,坡向可以决定发生的泥石流是否冲向铁路线路;线路与历史灾害点距离、线路与地面高差与发生泥石流后铁路受损情况密切相关,从已有研究看,不同线路类型在同样泥石流发生下受损情况也不一样.综上,从灾害的致险性和承灾体的脆弱性两方面考虑,共选取了11个风险因素,见表1.

表1 风险因素表
2.2 风险因素主观权重计算
泥石流发生时各因素之间并不是完全独立的,存在相互影响和作用,例如土地利用类型和土壤类型都受限于坡度,坡度的改变会使汇流积累量随之改变.因此,采用ANP方法进行分析.ANP在分析多因素存在相互影响的问题中有明显优势,但其计算量大、一致性检验不符合标准时,需要重新调整打分结果的特点使其未得到广泛应用,本文在打分前运用预排序的方法改进传统ANP,即专家对各因素重要性进行预先的重要性排序,然后进行打分,从而减少了计算量和一致性检验等繁琐步骤.由表1生成风险因素结构模型,如图3所示.
在风险因素ANP结构模型中的控制层有B1,B2两个准则;网络层灾害致险性包括D11、D12、D13、D14、D15、D16、D17、D18,承灾体脆弱性包括D21、D22、D23.分别以B1、B2为准则,以Cj(j=1,2)中元素Djl(l=1,2,…,nj)为次准则,构造判断矩阵并进行一致性检验,求其特征向量后得矩阵Wij(i=1,2;j=1,2),合并Wij得到超矩阵W.
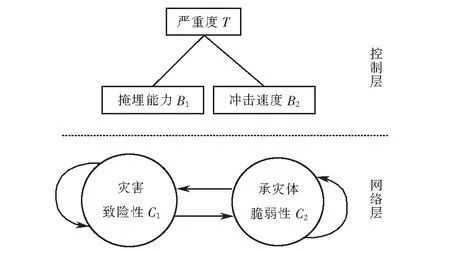
图3 风险因素ANP结构模型Fig.3 ANP structural model of risk factors
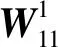
(6)
以B1、B2为准则,以元素组Cj(j=1,2)为次准则,构造网络层各元素对Cj的重要度判断矩阵,进行一致性检验,得出加权矩阵
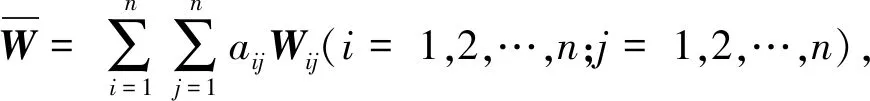
求超矩阵最大特征值对应的特征向量即可得到各因素对应的主观权重.
2.3 风险因素客观权重计算
采用Python对200组数据进行训练、测试,其中训练占75%,即用于训练的数据为150组,用于测试的数据为50组,得到各因素客观权重,算法流程图如图4所示.
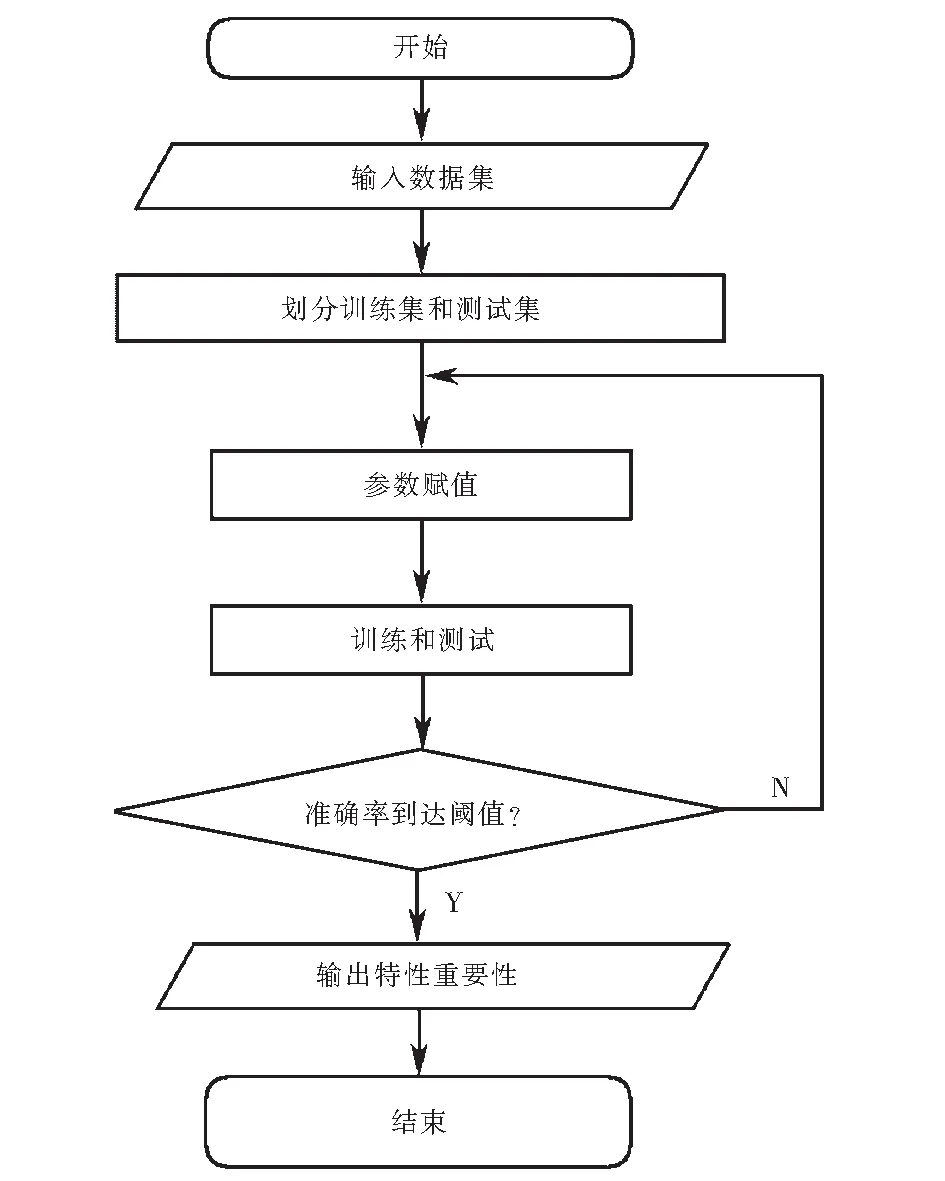
图4 RF计算客观权重流程图Fig.4 RF calculation objective weight flow chart
2.4 严重度等级表的生成
综合参考文献[18-19]等相关规范,生成了以死亡或重伤人数、线路行车中断时间和需要转移或救助的人数为指标的铁路沿线泥石流灾害严重度等级表,见表2.
3 计算结果与分析
3.1 研究对象离散化
本研究对象是川藏线成康铁路,对其沿线泥石流灾害严重度进行评估,各因素数据随着线路的改变差异也愈加明显,因此将研究对象划分成小段进行评估.从成都至康定依次经过新津、蒲江、名山、雅安、天全、泸定,以地方为分界点,以相邻地点之间的区段为具体研究对象,进行离散化.
3.2 数据来源
数据来源多样化,其中土壤类型数据来自中国土壤数据库中的1∶100万数字化土壤图(2009年制图),土壤利用类型和植被覆盖度采用地理国情监测云平台中的数据,年平均降雨选取了中国气象数据网的1959年至2009年的数据,坡度、坡向、海拔和汇流积累量数据来自国家基础地理信息中心官网(取2010年),灾害发生的历史数据来自中国地质环境监测局,共计200组数据(包括发生和未发生),数据格式见表3,以其中10条进行示意.

表2 泥石流灾害严重度等级表
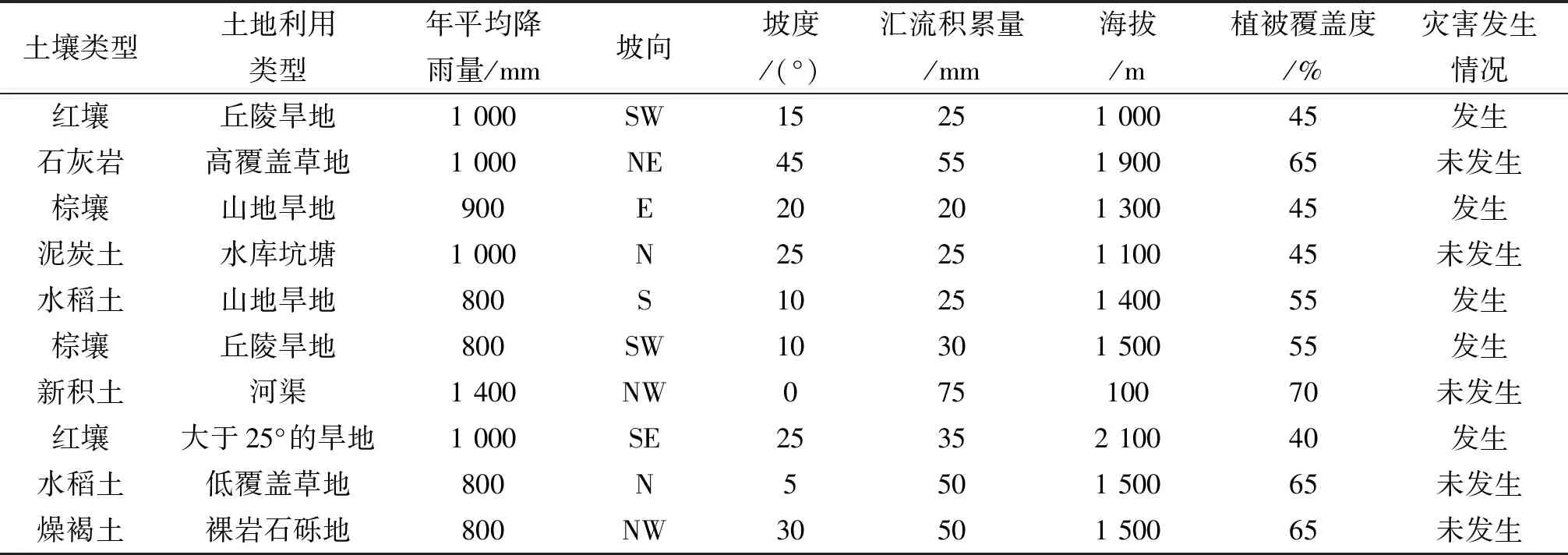
表3 各因素数据示意
3.3 组合权重的计算
按照2.1所述计算方法得到各因素主观权重,见表4.以Python中的Sklearn模块实现随机森林算法,其中:max_feature设为3,即每次分裂时选出信息增益最大的3个最优特征变量,小于本文中所选因素个数,且计算速度不会明显降低;n_estimators设为201,即树的个数;利用feature_importances函数得出每个因素的重要性,即所需客观权重.结果见表5.

表4 主观权重计算结果

表5 客观权重计算结果
3.4 评估结果
对照数据范围、历史灾害中因素数据量、灾害严重度,将各因素数据进行五等级的划分,即与严重度等级对应,得出每个区段的11个数据等级,和其对应的权重进行加权和运算,结果在0~5之间,所得结果四舍五入后得出该段灾害风险严重度等级.所得结果见表7,其中:雅安至天全泥石流灾害严重度最高,应加强管理防范措施;名山至雅安、天全至泸定、泸定至康定严重度较高,也应引起重视以减少人员伤亡,降低经济损失.

表6 组合权重计算结果
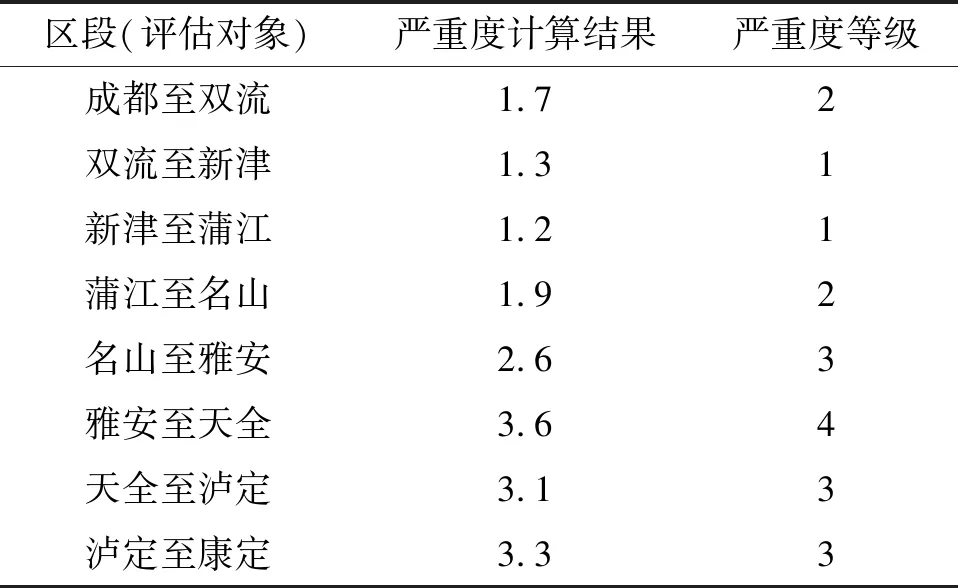
表7 成康段各区段评价结果
4 结论
本文提出了一种基于ANP-RF算法的泥石流严重度评估方法,以川藏线成康铁路沿线泥石流严重度为研究对象,得出以下结论:
1) ANP-RF评估方法可以解决泥石流严重度评估中各因素之间存在相互影响和作用的问题,且采用预排序法改进传统的ANP,简化了运算过程,提高了评估效率.
2) 随机森林中随机抽取样本和因素避免了机器学习中的过拟合问题,对各因素贡献取平均值增加了该方法的泛化能力,最终使得ANP-RF方法具有更加广泛的适用性.
3) 将成康段泥石流严重度评估结果与四川省泥石流风险区划图对比,二者基本吻合,说明本文计算方法可靠、准确,具有良好的应用价值,同时,该评估方法也可应用于其他线路、其他地质类灾害、其他评估领域.
