基于近红外光谱技术马铃薯蛋白质含量定标模型的构建
2021-02-21高红秀
李 赞,高红秀,金 萍,石 瑛*
(1.江苏农林职业技术学院,江苏 镇江 212400;2.东北农业大学农学院,黑龙江 哈尔滨 150030)
马铃薯在全世界范围内一直是重要的粮食作物之一。随着人们生活水平的不断提升,对马铃薯的品质要求也逐渐提高,蛋白质含量是研究马铃薯品质中重要的指标之一。传统测试马铃薯块茎蛋白质含量的方法一般采用凯式定氮法,其作为一种国际通用的测试方法,技术比较成熟且标准化,但应用过程中存在一些明显不足。该方法需要对检测样品进行前处理,操作过程消耗时间长(至少需要2 h 才能完成),工作量较大,费工费时,且所使用试剂具有强烈的腐蚀性,对环境污染大。因此,需要找到一种快速和准确检测马铃薯蛋白质含量的有效方法,为马铃薯蛋白质含量的评价提供依据。
采用近红外方法测定蛋白质含量可以大幅度减少操作过程中消耗的各类材料,去掉了很多繁琐且有危险的工作程序,降低了有害气体的污染和对操作人员的伤害,大幅提升测试分析的工作效率,并显著降低测试成本。近红外光谱分析技术实际上是一个二级分析方法,在对未知样品进行分析之前,必须选择一组具有代表性的样品作为一个定标集,对应其中的每个样品测量光谱及对应的组分或性质,并采用多元校正的方法将已测量的光谱与对应的性质或组成数据关联,建立该组分的定标模型,然后进行未知样品光谱数据的采集,并将其与校正模型相互对应,计算出此未知样品的组分。因此,近红外光谱分析技术的广泛应用,最重要的是建立定标模型,定标模型的合理性直接影响检测结果的准确度和稳定性。
近红外光谱分析技术在测定农副产品(如饲料、谷物、肉、蛋、奶、水果和蔬菜)的品质(包括蛋白质、脂肪、纤维、灰分、氨基酸等)方面得到广泛使用[1-7],已成为粮食品质分析的重要手段。近年来,已有不少作物利用近红外技术测定蛋白质含量。研究者利用近红外光谱技术分别对小麦[8]、水稻[9]、大豆[10]、玉米[11]和食用向日葵子仁[12]中的蛋白质含量进行了定标模型的建立,并取得了良好的效果。由此可见,利用近红外技术对谷物品质建立定标模型的方法已经相当成熟,并已有相关报道近红外技术应用于马铃薯研究中[13,14],但利用近红外技术在马铃薯蛋白质含量分析测试方法或建立相关模型方面的报道还很少。本研究以不同年份、不同区域的马铃薯块茎为试验材料,进行马铃薯块茎蛋白质含量近红外光谱定标模型的建立,并对其准确性进行验证,以期提供一种准确、快速、无需预处理测定马铃薯块茎中蛋白质含量的分析方法,为以后的相关研究与应用提供理论指导。
1 材料与方法
1.1 试验材料
供试材料为东北农业大学马铃薯育种基地的无性系种质材料,马铃薯品种审定区域试验、生产试验的品种(系),来自于克山、讷河等地的马铃薯品种(系)。样品数目为986 份,按不同年份、地域、生长季节等条件收集有代表性的马铃薯样品,将新鲜样品切碎,放在105℃的恒温箱内杀青30 min,然后将温度调到70.5℃,继续烘干14~16 h,使样本材料至恒重,将样品粉碎至30~40 目,装于小塑料袋中密封保存。
1.2 试验方法
1.2.1 样品扫描
采用福斯公司生产的近红外分析仪Infraxact对样品进行光谱扫描,扫描前,先将光谱仪开机预热1 h。波长范围570~1 850 nm,每份样品重复3 次。然后使用WinISI III 软件对光谱进行平均,生成平均光谱文件。
1.2.2 蛋白质含量化学值测定
马铃薯蛋白质含量化学测定方法为凯氏定氮法(GB 5009.5—2016)[15],使用瑞典福斯公司的2300 型全自动凯氏定氮仪进行测定。每个样品采用双平行分析,测定结果取平均值。
1.2.3 剔除超常和过剩样品,确定定标样品集
采用主成分分析技术(聚类分析技术)将光谱数据进行压缩,并分解为主成分和得分矩阵数据。然后利用得分矩阵数据,比较各样品光谱间的差异,以及某样品与主组群样品组间的差异,以此确定相似样品及超常样品,从而可确定参与定标的最好样品。首先,利用光谱文件创建得分文件,计算出数据的平均值和每一个样品到平均值的距离。边界是数据集的3 倍标准偏差。然后从剔除超常样品后的光谱文件中选择代表性样品,即剔除过剩样品。过剩样品剔除限是0.6,0.6 的定义为以某一个样品为中心,在半径为0.6以内的样品将被认为是与此样品相似,其光谱的性质则不能增加定标集样品的变异范围,即作为过剩样品,不可参加定标样品集。
1.2.4 定标模型的建立
首先将测定的样品化学值输入到定标集的光谱文件中,使每个样品的近红外光谱与化学值一一对应,然后用软件中的改进最小二乘法(Modified partial least squares,MPLS)回归技术法建立马铃薯蛋白质含量的近红外分析模型,预处理方法None(无散射处理)和SNV+Detrend(标准正常化+散射处理),导数处理参数选择分别为0.0.1.1、1.4.4.1。观察统计数据列交叉验证相关系数(1 minus the variance ratio,1-VR)和交叉验证误差(Standard error of cross-validation,SECV),找出1-VR 值最大,而SECV 值最小的即为最佳定标模型,这两组数据基本能反应定标模型对其他未知样品的预测性能。
1.2.5 定标模型的验证
在定标方程建立后,以一组没有参与定标的样品集作为验证集,对该方程的预测性能进行验证。验证样品集样品应具有代表性,其成分应覆盖在一定范围,并且其传统实验室参考数据须准确可靠,才能保证验证结果的合理性[16]。定标验证工作是通过WinISI 软件的Monitor Program 程序进行的,其验证结果表征为实验室数据和近红外预测数据相互比较所计算出的一系列统计结果。
2 结果与分析
2.1 马铃薯测试样品的近红外光谱图
在收集样品光谱后,首先观察每一样品的吸收图谱,对于异常图谱要重新进行扫描或作剔除处理。样品的近红外光谱图如图1 所示,马铃薯近红外光谱图有明显的吸收峰。

图1 马铃薯测试样品近红外光谱图Figure 1 Near infrared spectrogram of potato samples
2.2 确定定标样品集
采用主成分分析PCA 法,根据马氏距离或相关性去除超常样品和过剩样品,超常样品剔除限是3.0,过剩样品剔除限是0.6,最终确定定标样品集为411 份。样品蛋白质含量分布见图2,样品化学含量的梯度分布较均匀,基本覆盖了马铃薯的化学指标含量范围,有较好的代表性,满足建标的需要。本试验随机选取100 份样品组成验证集,其余311 份样品自动生成定标集,其中最小值为6.77,最大值为23.21。定标样品集及验证集蛋白质含量的分布见表1。

表1 蛋白定标集及验证集化学分析数据Table 1 Chemical analysis of protein content calibration and validation sets
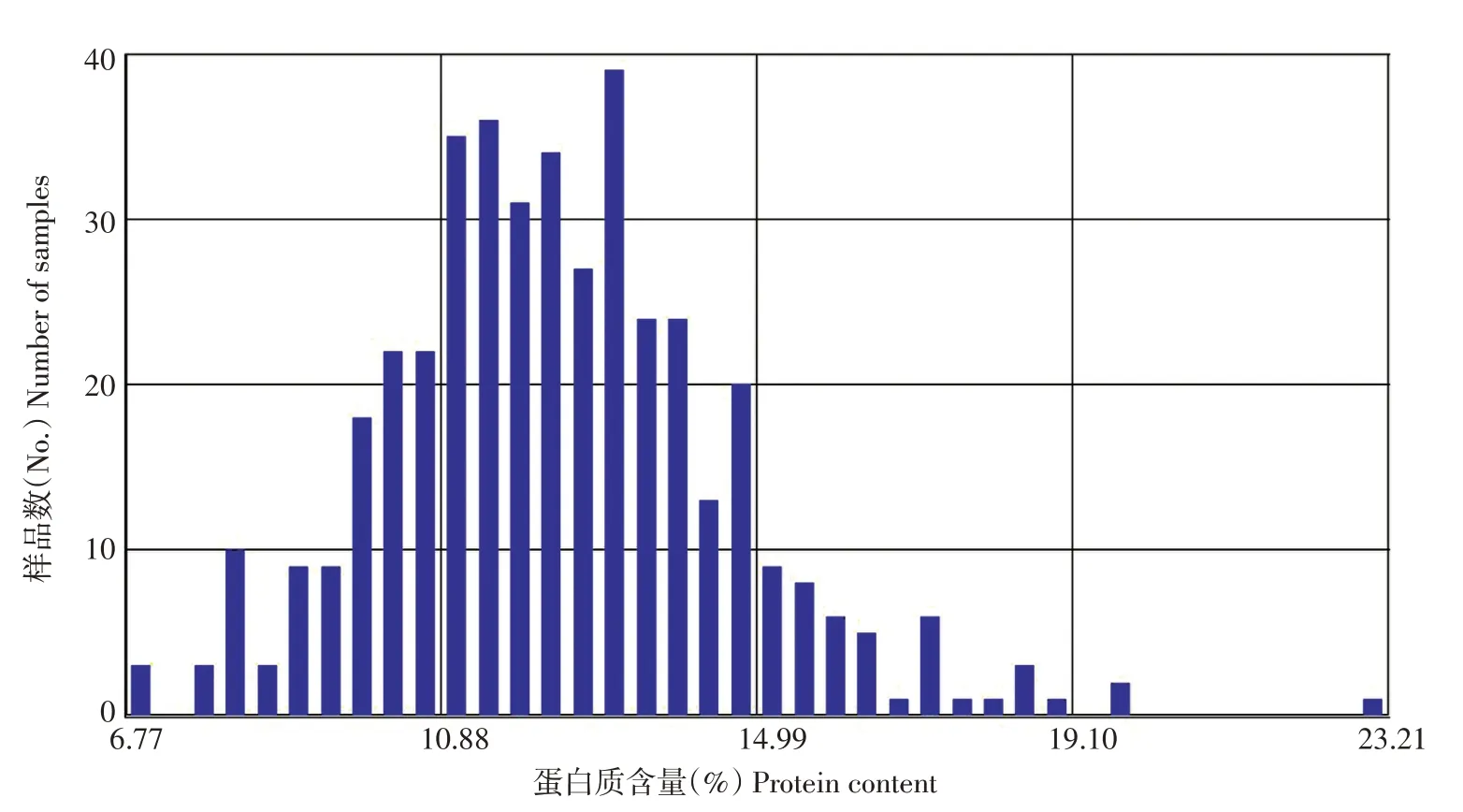
图2 马铃薯测试样品蛋白质含量柱形图Figure 2 Histogram of protein contents of potato test samples
2.3 定标模型的建立
将测定的样品化学值输入到定标集的光谱文件中,用MPLS 法建立蛋白质含量的近红外分析模型,预处理方法分别为无散射处理(None)和去散射处理(SNV + Detrend),导数处理参数选择分别为0.0.1.1、1.4.4.1。观察统计数据列1-VR 和SECV,找出1-VR 值最大的,而SECV 值最小的即为最佳定标模型。最终采用一阶导数的数学处理(1, 4, 4, 1)、去散射处理(SNV + Detrend)组合的预处理方法为最优定标模型。马铃薯蛋白质定标方程参数如表2 所示,其定标标准偏差(SEC)、交叉检验标准误差(SECV)和交叉验证相关系数(1-VR)分别为0.566、0.632 和0.912,说明所建的定标模型可用于马铃薯块茎蛋白质含量的快速检测,该模型可代替常规测试方法使用。

表2 马铃薯蛋白质组分定标模型参数Table 2 Parameters of calibration model for potato protein contents
2.4 定标模型的验证
定标模型建立后用100 份没有参与定标的样品来评估定标方程的预测性能。得到预测结果与常规方法测定结果及其偏差见表3 以及马铃薯蛋白质预测值与化学值相关图(图3)。
在表3中,85号样品、89号样品和98号样品的化学值和预测值之间的差值偏大,视为异常样品,作剔除处理,剔除异常样品后对剩下的97个样品的化学值和预测值进行相关性分析,结果如图3所示。

表3 化学法测定值和近红外预测值的比较Table 3 Comparisons of values measured by chemical analysis and near infrared predicted

图3 近红外预测值与实验室分析值相关分析Figure 3 Correlation analysis between near infrared predicted value and chemical analysis value
与常规化学分析测量结果之间的相关系数(R)为0.931,斜率为0.986,其斜率和相关系数均接近于1,结果表明近红外预测马铃薯蛋白质含量与传统方法结果无显著差异,所建的模型用于马铃薯蛋白质含量检测是准确可靠的。
3 讨 论
试验建立了一个马铃薯块茎蛋白质含量的近红外定标模型,并对构建的定标方程的预测性能进行了评估。试验结果表明,马铃薯块茎蛋白质含量定标模型的SECV 值为0.632,而1-VR 值为0.912,蛋白质含量的验证参数SEP 值为0.558,R值为0.931(图3),说明所建模型与凯氏定氮法测定的蛋白质含量无显著差异,结果可靠、理想,检测精度高、重复性好,可以用于今后马铃薯蛋白质含量的快速测定。
应用近红外技术不仅可以大大缩短品质育种工作中的材料筛选时间,而且可以节省大量的人力、物力和财力,并且减少了很多工序,提高了工作效率,降低了有害气体的污染和对实验操作人员的伤害。但是,近红外光谱技术是通过样品近红外光谱与化学值之间的定标模型来预测未知样品的组分含量,实际上是一个二级分析方法[16]。影响定标准确度的因素很多,如参与定标的样品数量不足,不具代表性;定标样品差异性不显著造成定标不具代表性;样品近红外扫描数据差;定标所使用的实验室数据分析不精确;非线性因素对定标的影响等[17]。特别是在定标集的样品选择上并不是样品数量越多越好,应选择具有代表性的,芦永军等[18]研究表明,采用相似样品剔除算法从178 个玉米粉样品中成功提取了94 个优选样品,通过对178 个样品和94 个优选样品分别进行定标试验发现优选样品保持了由原始样品集参与定标所达到的定标精度,给出了满意的定标结果。样本比例分配也应适当,韩春亮等[19]研究表
明以70%的比例样本作为定标模型的建立,其余30%比例样本作为该模型的验证样本,可以获得更好的预测效果。
定标模型并不是一劳永逸的,由于自然样品其成分随着种植季节、施肥量、降雨量和种植条件的变化而发生相应变化,因此,定标方程应定期补充新样品的扫描光谱和化学分析数据进行逐步调整或升级,目的是使定标方程不断适用待测样品的变化。如果样品的验证效果符合要求,则不需要进行定标调整,如果验证效果不符合要求,则从实验室成分分析的准确性以及定标模型的适用性等方面寻找问题根源,并进行相应的再次验证,直到符合定标要求,该模型才可以使用[16]。在定标的过程中如遇到超常样品,应对超常样品进行化学分析,然后将样品添加到原定标样品系对模型进行升级,对模型进行升级将使模型的预测性能更稳定。
目前,天然样品近红外定标最常使用的定标技术为改进最小二乘法回归(MPLS),很多广泛应用的商品化软件中都采用此种建模方式。但当选择的校正集样本中出现奇异点(即超常样品),或个别样品的性质范围已经超出校正集样本的范围时,则会出现较大偏差的可能。随着技术的不断革新,人工神经网络(ANN)技术解决了定标面临的吸收非线性问题,适用于处理大样品数据库,至少需要1 000 份样品,因此其模型适用范围广,可以减少或降低定标模型的调整工作,在很多领域的应用中已取得了良好效果。如全球通用谷物定标开发,即使样品地域或收购季节和品种变化时仍然获得较好结果。但是在光谱模型的构建过程中,必须投入相对较多的材料和时间成本,才能得到更加准确的校正模型。所以,如何实现技术优化和更有效的模型共享,仍是将近红外光谱技术研究及广泛应用的重要课题。
