面向分布式作战的智能模型持续演化方法
2021-02-14朱晓敏张雄涛王吉陈超
朱晓敏 张雄涛 王吉 陈超
1.国防科技大学系统工程学院湖南长沙410073
各类信息技术飞速发展, 战争行为已经由武器装备支撑下火力、机动力和防护力的简单叠加,转变为信息流主导下火力投送、战场机动和动态防护的有机整合.在计算、通信的共同推动下, 指挥控制流和信息流交融愈发紧密, 同步引导能量流作用于物理世界, 作战行动变得更为快、准、狠. 作战方式由面向能量流的平台中心战, 逐渐转变为面向信息流的网络中心战和面向指挥控制流的决策中心战. 此时,战场力量成为细粒度的马赛克块,以拼图式力量组织方式,复合成为多元环路、高度鲁棒的杀伤网[1].信息时代下,杀伤网节点关联愈发紧密,战术、战役、战略边界逐渐模糊,“战术将军,战略士兵”等新形态不断涌现,形成了牵一发而动全身的新格局.指挥控制流从传统中心式架构转变为发现即摧毁的分布式形式, 指挥控制边缘开始崛起[2]. 总体而言, 在信息技术的推动下,信息流在战场边缘得到显著增强,从而推动指挥控制模式呈现出去中心化、分布式发展趋势. 指挥控制模式决定了作战方式和作战效能,在分布式指挥控制模式下, 分布式作战[3]成为战争新形态. 此时,作战节点必须具备高度自主性和智能能力,从而减轻指挥控制节点的决策和控制负担,提升作战环路运转效率.
一般而言, 作战节点的自主智能性主要来自于智能模型,包括神经网络模型、强化学习模型等. 这些智能模型以作战节点的观察作为输入信息, 计算得出作战节点当前状况应该作出的响应. 为了赋予和提升作战节点这一智能性, 需要通过智能模型部署和智能模型训练两个方面实现. 其中,智能模型部署是指将预训练的智能模型直接部署到作战节点中,从而使之具有新的智能能力. 智能模型训练则是指智能模型部署后,通过收集作战过程中的数据,以有监督或无监督方式对部署后的模型进行训练. 由于战争迷雾的存在和对抗双方的动态博弈, 作战节点智能模型必须随战争发展和敌对策略而不断调整演化. 因此,作战节点必须具备智能模型持续演化的能力. 更准确地说,作战节点必须能够对智能模型进行持续训练,形成具备终生学习能力的智能体.
传统的作战节点智能演化主要通过作战节点本地独立训练和数据中心集中训练两种方式实现. 其中, 本地独立训练需要消耗作战节点大量计算资源,诸如小型无人机等作战节点不具备如此强大的训练能力. 此外,将所有数据收集到中心后再行训练的集中训练方式, 对有限且高度动态的战场通信链路造成了巨大压力,加上作战过程中,对上联通信道具有极高重要性,过分占用战术边缘-决策中心的通信资源并不适合.因此,需要一种与分布式作战方式相适应的分布式智能演化方法. 从其功能特点来看,分布式作战中智能模型演化具有如下特点:
1)任务动态多样. 分布式作战系统中,大量节点并行同步地推进上级指挥控制命令执行, 无可避免地面临多样的作战任务,加上战场形势瞬息万变,各类任务动态到达, 对分布式作战中智能模型演化的敏捷性和多样性有较高需求.
2)自身能力受限. 分布式作战中存在大量性能受限的异构节点,如无人车、无人机、无人艇、智能战术终端等设备, 这些节点受载荷、计算等因素限制,难以独立完成智能模型训练演化和计算,需要协同进行模型训练.
3)通信环境复杂. 战场复杂电磁环境使通信条件极其恶劣,分布式作战节点会频繁地出现断网、失联等情况,导致节点间通信困难,对分布式作战节点在不稳定通信下的协同训练和模型演化提出了极高的挑战.
针对上述挑战,本文结合联邦学习、gossip 学习等分布式协同训练技术, 面向分布式作战节点智能演化问题,考虑区域拒止/电磁干扰压制等复杂通信环境, 构建具备终身学习能力的分布式作战节点模型持续演化架构,通过通信状况感知,根据链路状态动态切换智能学习方法, 从而提供分布式作战节点智能性提升的可行途径, 进而为指挥控制模式分布式变革提供信息系统架构与计算方法支撑.
1 国内外研究现状
分布式作战节点进行智能模型训练技术不同于传统的分布式人工智能训练技术. 从其应用场景来看, 分布式作战节点在地理位置上分布于广泛的战场区域,且节点间信息链路具有高度不确定性,因此,其训练方式相比传统分布式人工智能训练技术具有更高要求.
巧合的是在边缘计算、物联网等领域,随着5G通信技术和智能移动设备的发展, 针对大规模分布于网络边缘的各类设备中智能模型训练问题, 边缘智能[4]等融合边缘计算和深度学习的新兴技术正在迅猛发展, 为分布式作战节点智能模型持续训练提供了可行路径. 当前,边缘智能模型训练技术主要为有中心和完全无中心两类方法.
有中心的智能模型训练方法以联邦学习等技术为代表.2016年,Google 公司的Koneˇcn´y等针对在大量手机等设备中协同进行模型训练的问题, 提出了一种被称为联邦学习的架构[5]. 该架构在迅速发展的同时,也得到了国内学者的广泛认可,被视为打通人工智能最后一公里的重要途径[6],并被运用到金融分析等领域[7]. 此后, Wang 等在此基础上提出了一种资源自适应的方法, 该方法可以调整联邦学习训练过程以优化联邦学习在特定资源预算情况下的学习效率[8]. 为了全面利用云、边缘节点和终端设备中的资源,Teerapittayanon 等针对分布式计算的层次架构解决了分布式深度神经网络部署问题[9]. Torti 等在可穿戴系统中嵌入嵌入式递归神经网络以进行实时跌倒检测[10]. Chen 等提出了一种面向推荐任务的联合元学习框架[11]. 这些工作以联邦学习技术为代表,在保障模型收敛性和大规模方面具有显著优势,参与训练节点已经可以达到数十万以上的级别, 极大地促进了边缘智能发展.然而,这类方法都需要一个参数服务器作为中心节点调整训练过程, 并未考虑到分布式作战节点可能面临的诸多不确定情况,无法很好地适应分布式作战节点模型智能演化需求.
另一方面, 无中心的智能模型训练方法大多基于并行化随机梯度下降算法(stochastic gradient descent, SGD)[12]和gossip 等方式实现. Lian 等将并行化的SGD 算法分为中心式并行SGD (centralized parallel SGD,C-PSGD)和去中心式并行SGD(decentralized parallel SGD,D-PSGD),并从理论和实验两个方面证明了D-PSGD 算法的优越性[13]. Blot 等提出了一种名为GoSGD 的去中心化完全异步式训练方法, 该方法致力于通过在gossip 机制启发下的不同线程之间共享信息来加快卷积神经网络的训练针对深度学习训练的可扩展性[14], Daily 等设计了一种基于异步梯度下降的gossip 算法,GossipGrad[15]. 考虑到分布式训练过程中不可靠网络的影响,Tang 等结合参数分块和gossip 协议设计了一种新的训练机制[16]. 这类方法很好地考虑了多节点协同模型训练的鲁棒性问题, 对于不可靠网络和节点损毁具有较强的抵抗能力. 然而, 当节点数量达到一定限度时,该类方法的模型收敛性难以保证, 加上节点数量巨大,数据多样,节点间达成一致共识更为困难.
值得注意的是, 不同于只采用有中心方式或去中心方式的边缘智能模型训练架构, 面向分布式作战节点智能模型持续演化问题, 提出了一种可根据通信链路状况进行分布式作战节点智能模型训练方法自适应选择的架构。当通信状况较差,后端链路不可达时, 所提出架构可以通过gossip 训练方式进行邻居节点间参数训练和梯度共享;当后端链路可达时,则采用分层联邦学习方法进行模型训练,利用作战过程中营、旅、军、战区等多级中心,构造多级缓存机制,在加速模型收敛的同时,减轻战术边缘决策中心链路负担,从而实现分布式作战场景下,作战节点智能模型持续演化的效果.
2 面向动态通信状况的分布式作战节点智能模型持续演化架构
从分布式作战节点智能模型训练的角度来看,对分布式作战节点智能学习影响最大的在于网络通信状况,可根据分布式作战节点的通信状况感知,实现通信环境现状感知, 从而推断合理分布式作战节点智能模型演化方法. 设计面向动态通信状况的分布式作战节点智能模型持续演化架构,如图1 所示.

图1 面向动态通信状况的分布式作战节点智能模型持续演化架构Fig.1 A continuous evolution architecture of the intelligent model for distributed operations node oriented to dynamical communication conditions
该架构中, 共含有指挥中心/数据中心模块和分布式作战节点模块两部分内容.其中,指挥中心/数据中心模块部署于计算资源充足的后方节点及边缘服务器节点(如营、连指挥所等),而分布式作战节点模块则部署于分布式作战节点. 图中,虚线表示控制流,实线表示指挥流. 各模块均包含通信器、拓扑分析器、方法选择器、参数聚合器和本地训练器这5 个组件, 数据中心模块还有模型库及孪生系统数据集两个模块, 分布式作战节点则额外有本地数据集模块,受限于平台存储能力, 分布式作战节点中的本地模型不再以模型簇的形式存储, 而是只存储最新的本地模型. 该架构工作时,分布式作战节点的通信器定时尝试与指挥/数据中心模块进行通信, 若多次重连后连接失败, 则选择基于gossip 的分布式训练方法,否则,采用有中心的联邦学习方法进行训练.
具体而言,架构工作时,通信器负责对数据打包传输,分析链路状况,并根据链路状况对所要传输的数据进行自适应的通信压缩(主要针对具有一定规模的神经网络梯度参数). 拓扑分析器根据通信器收到的历史信息分析当前可能的拓扑结构, 如星形结构、无中心结构(后端不可达,邻居节点可达)、孤立节点(无邻居、无后端)等. 在进行拓扑结构分析后,拓扑分析结果被送到方法选择器, 方法选择器在每个决策周期进行决策.
在指挥中心/数据中心模块, 当拓扑分析器发现无法和大多数分布式作战节点建立联系时, 方法选择器发送控制指令给参数聚合器, 停止参数聚合器工作,并发送指令给本地训练器,由本地训练器取出模型库中的模型, 根据孪生系统平行推演生成的数据集进行平行模型训练. 当大多数分布式作战节点可达时, 方法选择器发送控制指令停止本地训练器工作,并重启参数聚合器,参数聚合器按照联邦学习相同方法,定期进行参数聚合和更新,并有通信器对参数聚合器聚合后的最新版本模型进行模型发布.发布后的模型被分发给部分可达的分布式作战节点,并由分布式作战节点利用本地数据集进行训练, 并将训练后的模型上传到参数指挥中心/数据中心模块,以进行下一轮的参数聚合.
在分布式作战节点模块中, 当拓扑分析器发现无法和指挥中心/数据中心模块建立联系但邻居可达时, 方法选择器通知参数聚合器启动, 而后, 分布式作战节点之间进行gossip 分布式学习, 将本地数据集进行训练后, 通过通信器将本地模型分享给邻居节点, 并由参数聚合器对所有邻居节点的模型参数进行聚合,而后更新本地模型. 当拓扑分析器发现指挥中心/数据中心可达时, 方法选择器关闭参数聚合器,并通知通信器将本地模型上传至云端,一段时间后从云端下载新的通用模型, 以提升本地模型性能.当拓扑分析器发现本节点为孤立节点时, 则在本地进行单体的智能模型训练.
3 基于通信状况感知的分布式作战节点智能模型持续演化方法
基于所提出的架构, 设计了一种基于通信感知的拓扑分析和链路预测模型, 根据模型可以对每个节点得到其可达节点及可达节点间链路的可靠性,依据这一可靠性度量, 可以对节点的智能模型持续演化方法进行自适应调整;当后端可达时,引入分层联邦学习方法, 高效进行大规模分布式作战节点的智能模型训练;当后端不可达时,设计基于链路可靠性的自适应gossip 分布式学习机制, 高效利用可用链路进行模型协同训练.
3.1 基于通信感知的拓扑分析和链路预测
一般而言, 导致分布式作战节点通信中断主要有节点受损和链路失效两方面原因. 形式化地, 分布式作战节点可以视为m个节点的集合N= {n1,··· ,nm}. 而后端链路则可以视作是一个特殊的节点n∗.
假设分布式作战节点间链路失效和节点受损是相互独立的. 则节点ni和nj之间的通信链路在一段时间内的可靠性rij可通过如下方法计算:
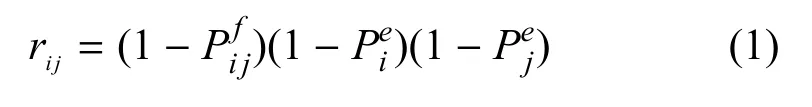
其中,为节点ni和nj之间链路失效的概率,为节点ni的损毁概率.
战场节点损毁概率方面, 可借鉴系统可靠性[17−18]方面的研究,这些研究都证实了在特定时间内节点故障的概率通常服从泊松分布.与此相似,将敌对作战行为而导致的节点损毁视为一个导致节点故障的因素.可以认为,在作战强度基本不变的一段时间内,作战节点损毁概率服从泊松分布.当作战强度发生较大变化, 如从侦察布势阶段转变为焦灼阶段时, 认为作战节点其所对应的泊松分布参数发生变化. 因此,节点在单位时间内不会损毁的概率为:
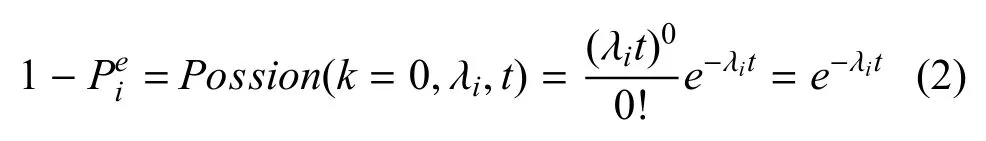
其中,λi是单位时间内节点ni的损毁次数.
节点间链路失效概率方面,障碍物阻挡、多径效应、敌方电磁干扰压制等各种影响导致节点间状况难以准确地计算. 考虑到通信状况感知主要用于分布式作战节点智能模型演化方法选择上, 因此,作战节点链路可靠性不必是绝对精确的值, 而只需要是一个相对准确的度量即可. 由于大多数分布式作战节点都采用无线通信手段进行数据共享,因此,可以将接收信号强度指示(received signal strength indication,RSSI)作为通信链路可靠性的度量指标.此时,可以将式(1)中的第1 项替换为:

其中,vij是节点ni和nj的相对速度,RS S Iij是ni和nj之间链接的RSSI.RS S Imax是通信协议中RSSI 的最大值. 此时, 式(3)的取值范围为[0,1], 与基于失效概率计算的链路可靠性取值范围一致.此时,式(1)可改写为:

由此可以得出包括无人机、无人车、手持战术终端等分布式作战节点间通信状况的可靠性. 需要注意的是,由于与实际可靠性不同,因此,其不能用于分析节点智能模型演化的收敛性.
对于任意节点ni, 其目前的通信状况可用一个m+1 维的向量进行描述,即:
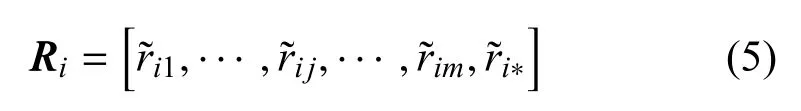
其中,ri∗是与后端n∗之间的通信状况.
此时,对于分布式战场环境下的任意节点,设置后端链路可达阈值r(∗),当该节点ni与后端节点n∗之间的链路可靠性≥r(∗)时, 则认为节点ni后端链路可达,适合采用有中心的智能模型演化技术,即分层联邦学习方式进行训练,否则,则采用gossip 学习方式进行智能模型演化.
3.2 面向动态链路的分层联邦学习方法
在完成通信状态感知和模型演化方式选择后,只需根据不同通信状况选择方法, 引入有中心的联邦学习架构和完全分布式的gossip 学习架构即可.
在自适应压缩的分层联邦学习方法部分, 首先将联邦学习泛化为一个一般性的优化问题, 即大量节点分布在不同地理位置上, 每个节点有各自的参数而优化目标是通过调整所有节点的参数以达到全局最优:
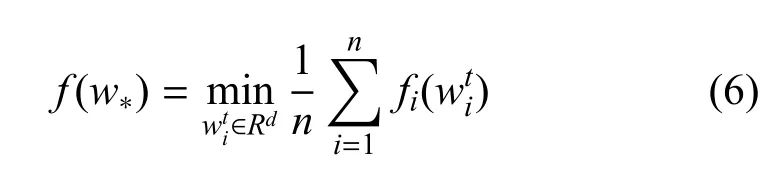
其中,f是全局优化目标,fi:Rd→R是由每个节点ni上可用的本地数据决定的局部优化目标,∈Rd表示fi的解. Google 官方将这一优化问题称为联邦优化问题[19].
而联邦学习, 则是把联邦优化中每个节点的优化目标用智能模型的损失函数来代替,即:

其中,Fi:Rd→R为分布式作战节点中智能模型所对应的损失函数,ξi为数据集Di中的数据样本.
为了解决这一联邦优化问题, 每个分布式作战节点都根据其本地数据搜索fi的局部最优解可通过SGD 等最优解搜索算法对寻找该问题的最优解:
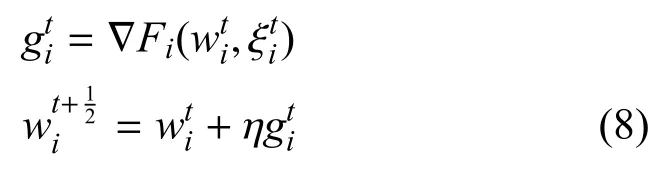
而后, 每个分布式作战节点将其局部最优解上传到后端节点中, 后端节点使用聚合算法agg(例如FedAvg[20],FSRRG[21]等)对所有进行聚合:
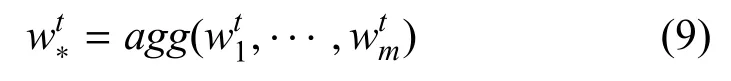
在完成聚合后, 后端节点将所有聚合后的智能模型参数再次分发给每个分布式作战节点,节点将收到的参数替代原来的解以作为新的起点, 开始下一轮解的搜索.
为了缓解同步数据上传对后端通信链路带来的巨大压力,自适应压缩的分层联邦学习将式(9)中的参数上传和下载由云-端模式,换为云-边缘-端的模式. 具体而言,分布式作战节点的模型参数被首先上传到边缘服务器中, 战术边缘服务器在完成分布式作战节点智能模型参数的聚合后, 将聚合参数直接下发到与其连接的分布式作战节点中. 当分布式作战节点在本地进行智能模型训练时, 系统带宽压力减小, 战术边缘节点将本地聚合的模型参数上传到云中心, 云中心聚合后直接发送给战术边缘节点,从而减少通信的带宽占用.
此外, 对于每个分布式作战节点在上传和下载模型参数前,还会根据可用通信链路状态,自适应地对模型参数进行压缩:

其中,C(·)为梯度压缩运算, 可以是稀疏化(topk,randk)[22], 二次抽样[23], 或kbit 量化[24]等方法, εt为压缩运算C(·)的压缩率, 根据链路可用带宽进行动态调整.
形式化地,当可用链路带宽为bt时,压缩率εt被设置为:
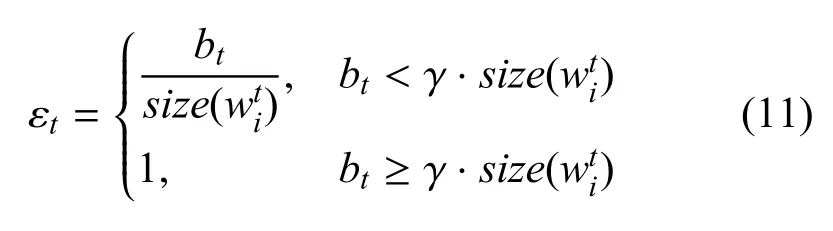
其中,γ 为可占用带宽系数,size()为分布式作战节点智能模型参数的大小. 与此同时,记压缩运算C(·)的逆运算为C−1(·), 即解压运算.需要注意的是,C(·)和C−1(·)可能带来部分信息损失.
3.3 基于可靠性排序的gossip 学习机制
基于可靠性排序的gossip 学习机制以gossip 通信协议为基础进行设置, 用于后端不可达时分布式作战节点协同进行智能模型训练的场景. 将3.1 节中每个节点的通信状况进行合并, 可以得到所有节点的通信状况矩阵如下:

可知通信状况矩阵RRR为m×(m+1)维的矩阵.由于每个节点不一定采用完全分布式的训练方式进行训练. 因此,将≥r(∗)的所有节点去除,矩阵RRR可以转换为只有m'个节点的无中心通信矩阵:

其中,为去掉最后一个元素的通信状况向量.为便于推导,记当ri j>0 时,即可认为节点nj为节点ni的邻居.取出节点ni的所有邻居,并按照链路可靠性对节点进行排序,然后选择可靠性最高的前k个节点进行参数共享,并采用下列方法进行所欲收到参数的共享, 即可实现基于可靠性排序的完全分布式gossip 学习.其中表示节点nj发送给节点ni的梯度参数是否被成功收到, 如果被成功收到, 则= 1, 否则,= 0. 此外,为了提升基于可靠性排序的gossip 学习机制通信效率,对于gossip 中的每次信息共享,同样采用和自适应分层联邦学习相同的方式进行梯度压缩.
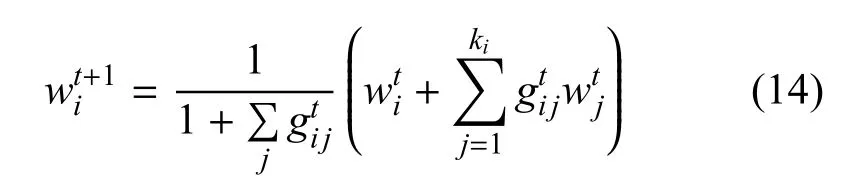
3.4 面向动态通信状况的分布式作战节点智能模型持续演化算法
结合前述模型, 可将本文所提出的方法总结为与所提架构相适应的算法, 即基于通信状况感知的分布式作战节点智能模型持续演化算法(简称为通信感知学习),如算法1 和算法2 所示. 算法1 为基于通信状况的分布式作战节点模型持续演化算法在分布式作战节点部分的内容, 而算法2 则是该方法在指挥/数据中心节点的内容.

?
在算法1 中,每个分布式作战节点都是并行地执行该算法. 由于不同分布式作战节点计算资源有显著差异,因此,节点间的同步控制均采用固定间隔时间的方式进行. 每个分布式作战节点首先利用SGD或其他人工智能模型优化算法, 基于本地数据进行训练. 而后,根据通信状况和带宽对本地参数进行压缩,参数压缩后,根据通信状况上传给后端节点或与邻居节点协同进行学习,最终完成模型训练. 在实际作战过程中,这一算法的终止条件可以为T→∞,就可以使得分布式作战节点智能模型具备随战争发展变化而持续迭代演化的能力.

?
根据本文所提架构, 分布式作战节点智能模型持续演化方法除了分布式作战节点外, 也需要指挥/数据中心节点的配合. 因此, 将指挥/数据中心所应执行的算法以算法2 的形式进行表述. 算法2 中,每个边缘服务器在开始任务执行前首先将预训练好的初始智能模型分发给每个分布式作战节点, 而后作为分层联邦学习的中间节点进行参数初步聚合和缓存. 之后,利用分布式作战节点本地训练时的空余带宽与中心进行参数同步.在实际作战过程中,算法2 既可以部署在联指一级的指挥部中,也可以部署在旅、营级指挥中心,从而减少作战过程中由智能模型迭代演化造成的巨大负担.
将算法1 和算法2 共同部署到分布式作战体系结构中,按照本文所提架构的形式进行组织,即可以实现分布式作战的智能模型持续演化.
4 实验设置与结果分析
为了验证所提出架构和算法的有效性和可行性,本节将根据分布式作战场景进行实验设置. 考虑到目前以深度学习为代表的智能模型在作战领域的应用价值,以4 种常用的神经网络作为智能模型,对分布式作战节点智能模型演化效果进行分析, 以验证所提出分布式作战节点智能模型持续演化算法的可行性和有效性.
4.1 实验参数设置
采用NS-3 模拟分布式作战节点在战场环境下的相互通信情况, 设置了50 个分布式作战节点, 并通过WiFi 802.1a 协议, 以Ad-Hoc 方式进行相互通信. 在所设置的实验场景中,所有节点都只和其他节点通过Ad-Hoc 进行单跳传输,以减少因转发本地模型而造成的大量带宽浪费. 以基站形式模拟后端链路的特殊节点n∗,任务区域为3 000×3 000 m2,除基站节点外所有分布式作战节点均在该任务区域内进行随机游走.
分布式作战节点智能模型采用4 种典型的深度神经网络模型, 即逻辑回归(logistic regression, LR),多层感知机(multi-layer perceptron, MLP), 卷积神经网络(convolu-tional neural network, CNN)和循环神经网络(recurrent neural network, RNN). 这些模型的参数设置如下:
1)LR 模型采用一个784×10 维的权重参数和一个10 维的偏置向量.
2)MLP 模型由1 个含784 个神经元的输入层,2个含500 个神经元的隐藏层和10 个神经元的输出层组成. 除输出层外均采用ReLu 作为激活函数.
3)CNN 模型由2 个5×5 的卷积层,1 个3×3 的卷积层和1 个softmax 输出层构成. 其中,第1 个卷积层采用10 个通道, 第2 个卷积层为20 通道, 第3个卷积层为40 通道,且每个卷积层后都附加了1 个2×2 的池化层.
4)RNN 模型由2 个128 神经元的长短时效记忆层(long short-term memory,LSTM)和1 个10 神经元全连接层组成.
所有这些模型都使用交叉熵作为其损失函数,每5 个样本作为一个训练批次,每20 个批次作为一个分布式作战节点本地训练周期.以PyTorch 实现这些模型,并根据NS-3 的通信仿真结果进行节点间参数的共享.
智能模型所对应的数据集采用非独立非同分布的MNIST 手写数字识别数据集[20], 该数据集为McMahan 验证联邦学习等大规模分布式智能学习性能时提出,是在原始MNIST 数据集基础上的改进版本, 其数据分布特性更符合分布式作战场景下的智能模型演化场景.
为验证本文所提出方法在分布式作战节点智能演化方面的优越性, 选择3 种最常用的人工智能模型训练方式作为对比, 即联邦学习方法[5]. gossip 学习方法[25]和本地学习方法.
4.2 逻辑回归智能模型演化效果对比
分布式作战节点对于逻辑回归类智能模型采用本地学习,联邦学习,gossip 学习和通信感知学习的智能演化效果如图2 所示. 从图2 中可以看出,通信感知的联邦学习在该场景下表现出了最快的训练速度,且训练结果最为稳定. 而本地学习方法则极为波动, 这可能是由于分布式作战节点数据的非独立非同分布特性, 导致没有进行参数共享和梯度交换的简单本地学习效果较差. 因此,在分布式作战过程中,各作战节点智能性提升必须进行协同共享, 以共同学习达到较好的训练效果.
4.3 多层感知机智能模型演化效果对比
作为一类更复杂的智能模型,多层感知机在4 种不同智能演化方法上训练的效果如图3 所示.

图3 MLP 智能演化效率对比Fig.3 Comparison of intelligent evolution efficiency of MLP
从图3 中可以看出,本地学习,gossip 学习,联邦学习和通信感知学习4 种方法, 在智能模型演化初期都表现出了较为相似的性能.甚至,gossip 学习和本地学习一度超过了通信感知学习. 这是由于模型训练初始阶段时, 模型参数优化方向还未进入到局部最优的陷阱中,随着训练过程的不断推进,采用通信感知学习方法进行智能演化的分布式节点准确率持续提高,且在训练结束时依然保持上升趋势. 这说明本文所提出的通信感知的分布式作战节点模型持续演化架构相比其他传统模型训练, 可以更好地适应分布式作战环境, 提升分布式作战环境下作战节点智能演化的效率.
4.4 卷积神经网络智能模型演化效果对比
不同于常被用于数值分析的多层感知机和逻辑回归等智能模型, 卷积神经网络在图像识别领域表现出了更好的性能,可以对无人作战、高价值目标识别等场景提供有效的智能信息服务. 其在分布式作战环境中的智能模型演化效果如图4 所示.
从图4 中可以看出,4 种智能模型的表现和多层感知机及逻辑回归中的表现大体相似. 值得注意的是, 在模型训练的起始阶段, gossip 学习和本地学习表现出了相似的性能, 而通信感知学习则和联邦学习表现出了相似的性能. 从这4 种模型智能演化算法的作用机理来看, 联邦学习在模型训练时通过参数服务器确保了所有节点模型参数的一致, 而通信感知学习同样会让分布式作战节点利用链路可达的机会进行模型同步,导致二者表现相似. 但联邦学习演化方法未考虑节点损毁和链路失效等带来的影响,而此时通信感知学习可以将学习模式切换为分布式学习,从而提升其训练效果,因此,当训练结束时,基于联邦学习的智能演化方法开始收敛, 而通信感知学习演化方法仍然呈现出上升的趋势.
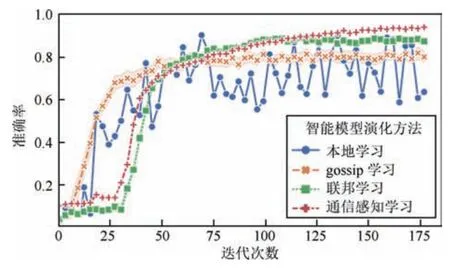
图4 CNN 智能演化效率对比Fig.4 Comparison of intelligent evolution efficiency of CNN
4.5 循环神经网络智能模型演化效果对比
除了数值分析和图像识别外,包括语音、文字等的时序数据通常被循环神经网络进行处理. 这对人机混合系统等分布式作战中的实际系统具有重要支撑作用. 此外,循环神经网络也是强化学习方法的重要网络基础,考虑到强化学习在支撑机器人、游戏智能体、数字孪生系统推演等方面的巨大潜力,循环神经网络对于分布式作战智能模型演化具有同样重要的作用,其智能演化效果对比如图5 所示.
从图5 中可以看出, 基于通信感知学习的分布式作战节点智能模型演化方法表现出了较好的性能,主要体现在训练效果的稳定性和训练准确率的增长方面. 由于循环神经网络具有一定的注意力机制,在训练时容易出现模型准确率较长时间停滞的情况,如图中联邦学习方法. 但通信感知学习很好地避免了这一问题, 达到了较快的模型演化效果. 因此, 本文所提出的通信感知学习方法, 能更好地适应分布式作战环境特点, 在逻辑回归, 多层感知机, 卷积神经网络和循环神经网络等智能模型演化方面表现出了较好的效果.

图5 RNN 智能演化效率对比Fig.5 Comparison of intelligent evolution efficiency of RNN
5 应用场景
本文面向分布式智能化战争愿景, 旨在为分布式作战节点智能模型持续演化问题提供方法支撑, 所提出架构和方法可以适应多种不同的通信状况, 服务于指挥控制模式的智能化变革, 进而加速OODA 环运转,提升作战效能.
1)无人集群作战. 敌方进行通信干扰和压制等活动时,无人集群利用本文所提方法,根据通信状况自适应切换智能模型训练和提升方式, 减轻敌方压制影响的同时, 不断提高智能模型的准确性和行动速率.
2)拒止环境协同作战.在GPS 拒止和后端链路不可达情况下, 分布式作战节点通过所提出框架进行协同通信, 自适应地切换为完全分布式的智能模型演化方法.
3)人机混合智能协同作战.有人/无人混合班组、忠诚僚机等场景下, 人需要和无人平台进行大量交流和协作.由于战场环境的动态性和不确定性,人机混合编队可能遭遇多种不同通信状况, 通过本文方法,可以确保模型的持续迭代演化,打造终生学习的分布式作战节点.
4)多部门协同决策. 作战过程中,不同部门收集到大量战场数据, 对这些数据进行充分挖掘和分析,可以为作战决策提供有效支撑. 通过本文方法,以智能模型为桥梁, 在确保各类战场数据本地存储的同时,通过智能模型协同训练,形成多部门共有的知识模型,盘活不同部门所收集的数据.
6 结论
围绕分布式作战过程中海量作战节点智能模型持续演化问题, 提出了一种面向分布式作战的智能模型持续演化架构, 根据分布式作战节点通信状况,该架构可自适应地选择有中心的分层联邦学习训练方法和完全分布式gossip 学习方法, 并随战场环境变化进行模型演化方法的动态切换. 所提出的模型演化架构和方法得到了实验结果的有效验证. 本文研究工作对分布式作战场景下作战节点的智能模型持续训练问题提供了架构支撑和方法途径. 作为后续工作, 计划将本文所提出的通信感知学习方法运用在多无人平台协同作战系统具体等场景中, 以进一步验证和完善本文方法, 为分布式无人作战提供计算架构支撑.
