基于知识自蒸馏的轻量化复杂遥感图像精细分类方法
2021-02-14孙显杨竹君李俊希刁文辉付琨
孙显 杨竹君 李俊希 刁文辉 付琨
1. 中国科学院空天信息创新研究院北京100190 2. 中国科学院网络信息体系重点实验室北京100190 3. 中国科学院大学电子电气与通信工程学院北京100190
随着人类逐步迈入“智能+”时代,信息与智能技术催生的战争正呈现出物理、网络和社会系统虚实互动、协同共生的发展态势[1−2]. 数字化战场建设作为战场信息保障系统的首要任务和决定战争胜负的关键因素, 在未来的长期作战中起到至关重要的作用. 遥感图像覆盖区域广、探测范围大,并且可以返回不同时刻的地表状态, 是数字化战场的重要信息传输媒介. 基于遥感图像开展地物要素精细分类,获取真实场景的多维实时战场数据和敌我对抗信息,是构建数字化战场环境的技术基础.
传统基于深度神经网络的遥感图像精细分类方法往往存在参数量大、计算资源要求高等问题,难以部署应用在低功耗、低性能的边缘计算设备上[3],极大限制了深度学习等方法的应用. 轻量化网络模型在保持网络模型高预测精度的同时, 降低智能模型的参数量和计算资源消耗, 从而使智能模型能够在边缘设备上部署和应用.
实现模型轻量化的主要方式包括剪枝[4−7]、量化[8−10]等, 然而此类方法往往伴随着模型精度明显降低问题,而知识蒸馏是解决以上问题的有效方法.知识蒸馏的主要思想是从参数量多、模型结构复杂、特征表征能力更强的教师网络中提炼知识, 从而训练并提升轻量级学生网络的精度. 传统知识蒸馏方法由Hinton 在2015年首次提出[11],陈关州等首次将知识蒸馏引入遥感场景分类中[12], 以提高小而浅的网络模型的性能. 文献[13] 利用高性能但计算量大的复杂网络和知识蒸馏, 对教师模型使用自编码器特征, 对学生模型使用适配单元来适配教师模型的特征,提高了轻量级网络的分割性能.
传统知识蒸馏[14−15]方法中,学生网络的性能高度依赖于教师网络, 且教师网络的设计和训练需要大量时间, 给模型压缩带来额外负担. 文献[16−17]采用知识自蒸馏框架, 其作为传统知识蒸馏的延伸方法,不仅降低传统深度模型的参数量,同时无需教师网络,与传统知识蒸馏方法的区别如图1 所示.
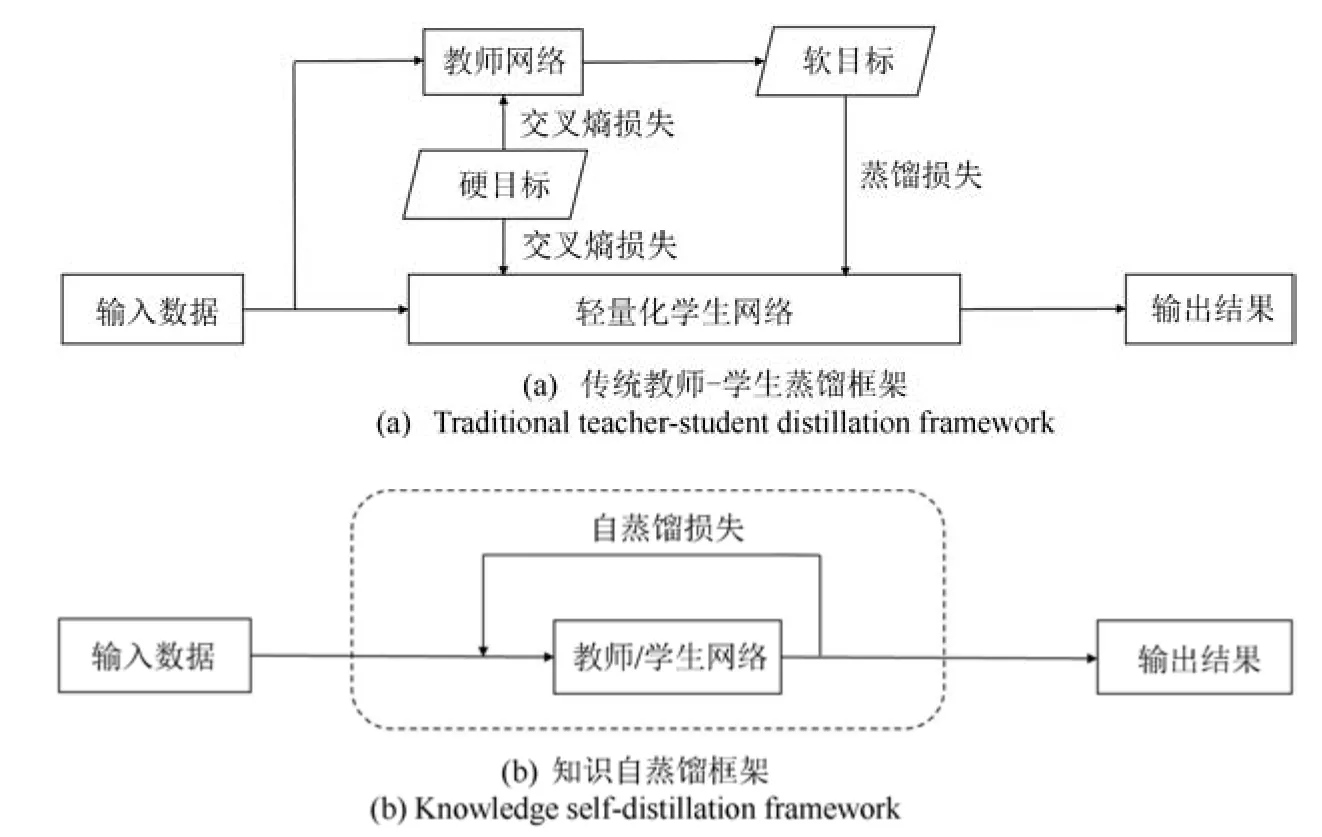
图1 传统知识蒸馏框架与知识自蒸馏框架区别Fig.1 The difference between traditional knowledge distillation framework and knowledge self-distillation framework
基于以上问题分析, 提出一种基于知识自蒸馏框架的轻量化复杂遥感图像精细分类方法, 将知识自蒸馏框架和金字塔池化模块相结合, 提升轻量化网络的精细分类精度.一方面,金字塔池化模块通过融合不同尺度特征信息, 实现全局上下文信息的有效利用;另一方面,应用知识自蒸馏框架避免了对教师网络的训练,在保持较低的模型参数量的同时,实现遥感图像精细分类的精度提升. 实验表明,所提出的方法可以相对有效地避免建筑物阴影造成的误判,并在建筑物精细分类细节上表现优异, 在大规模复杂遥感数据集的精细分类上具有更优性能.
1 相关工作
1.1 遥感图像精细分类
遥感图像精细分类是遥感领域的一个重要问题. Long 等提出全卷积网络(fully convolutional networks,FCN),实现对输入图像进行像素级分类,从而解决了语义级别的图像精细分类问题[18]. 自此以后,研究人员针对FCN 具有不同方向的改进: 其一, 由于增加感受野可以获取更加丰富的特征,因此,Chen等提出DeepLab 模型,将DCNNs 层的响应和完全连接的条件随机场融合,从而改善精细分类效果[19],文献[20] 在传统的FCN 模型上增加两种类型的注意力模块,将注意力模块的结果进行相加,从而改善特征表示, DANet 进一步提升了精细分类效果; 其二,针对FCN 模型具有无法准确使用全局场景中的类别线索的问题,Zhao 等提出了金字塔场景解析网络(pyramid scene parsing network,PSPNet)[21],该网络通过金字塔池化模块进行有效的全局先验表示, 解决了网络无法充分获得重要的全局先验的问题. 本文的对比网络采用PSPNet.
1.2 知识蒸馏
由于冗余化的参数量, 大型深度神经网络通常具有强大的泛化能力. 知识蒸馏利用教师网络指导学生网络的学习,使冗余参数被抛弃,是实现模型轻量化的方法之一.Hinton 首次提出知识蒸馏的概念,实现了模型轻量化. 自此以后,研究人员的研究重点集中于寻找更好的匹配准则使学生网络可以更充分地学习教师网络的知识. Komodakis 等认为注意力图是更具有价值的匹配信息[22],因此,使用教师网络生成的注意力图来指导学生网络的注意力图进行学习.近年来, 使用模型之间的关系进行配准取得了显著发展. Yim 通过计算相邻阶段特征通道之间的关系进行配准[23]. 在遥感领域,文献[12]首次将知识蒸馏应用于遥感图像场景分类问题中, 在大量实验的支撑下,验证了知识蒸馏方法在低分辨率遥感影像、遥感地物类别较多、遥感影像数量较少等情况下的适用性与可行性.
2 面向遥感图像精细分类的自蒸馏网络
2.1 遥感图像地物要素特性分析
遥感图像进行精细分类已经取得显著进展, 但其在边缘设备上的部署仍然具有挑战性. 知识自蒸馏可以很好地训练轻量化模型, 但对于不同的应用场景,模型精度提升并不明显.
遥感图像具有显著特点: 一方面,遥感图像覆盖范围大, 图像信息容量大, 提取兴趣区域困难, 难以充分利用上下文信息;另一方面,遥感图像和目标本身存在复杂性, 常见的有遮挡问题和图像精细分类细节很难精准定位问题.
基于上述分析, 在知识自蒸馏框架的基础上引入金字塔池化模块,如图2 所示,该模块通过融合不同子区域感受野,实现有效利用全局上下文信息,并且通过实验观察得到, 金字塔池化模块对于遥感图像的遮挡问题也有一定的改善, 遥感图像精细分类性能提升明显.

图2 金字塔池化模块示意图Fig.2 Schematic diagram of pyramid pooling module
2.2 面向地物要素特性的自蒸馏网络
知识自蒸馏可以实现在缩小卷积神网络规模的同时不明显降低网络精度, 采用直接面向学生网络的一步式自蒸馏框架, 简洁而有效地提升轻量化模型性能. 但是直接用于要素分类的知识自蒸馏忽略了浅层网络中包含的图像位置和精细信息, 对遥感图像中常见的遮挡、缺失和要素细节信息很难精准提取等问题难以有效处理,因此,提出采用基于知识自蒸馏的轻量化分类方法, 融合自蒸馏框架和金字塔池化模块,进一步提升遥感图像精细分类性能.
2.2.1 主干网络
基于知识自蒸馏的轻量化遥感图像精细分类模型如图3 所示. 模型主要包括特征提取器部分、金字塔池化部分和自蒸馏部分. R1-R4 是特征提取器部分:本方法采用预训练ResNet18[24]和ResNet34 进行特征提取. ResNet18 和ResNet34 根据网络结构, 分为4 个ResBolck. 金字塔池化部分: ResBlock 的输出特征图分别送入金字塔池化模块, 每个金字塔池化模块采用4 层金字塔结构,经过卷积后上采样,不同层的特征图进行连接后输出.自蒸馏部分: 所有浅层网络通过学习最深层输出的精细分类结果进行蒸馏,浅层网络可以视为学生网络, 最深层模型在概念上被视为教师网络.
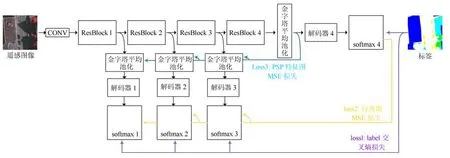
图3 基于知识自蒸馏的轻量化遥感图像精细分类模型Fig.3 Fine classificatio model of lightweight remote sensing image based on knowledge self-distillation
学生网络根据教师网络的预测输出经过softmax变换后的软目标(soft target)和硬目标(hard target)的加权求和损失进行训练. 其中,硬目标是样本的真值标签,软目标定义如下:
假设给定M种类别的N个样本, 则记样本集为样本集标签记为其中,yi= {1,2,··· ,M}, 神经网络的分类器表示为:其中,C是卷积神经网络中分类器的数量. 每一个分类器后设置一个软目标层,其激活函数定义如下:

其中,z是全连接层后输出,∈RM是分类器θc/C第ith个概率,T表示蒸馏温度,T越大,分布越平滑.
2.2.2 自蒸馏损失函数
自蒸馏损失函数包括3 部分. 利用真实标签对每个子网络进行监督训练,使用交叉熵损失函数;利用知识蒸馏的思想, 为了将深层教师网络的软目标迁移到浅层的学生网络中, 完成教师网络知识的蒸馏,第2 部分损失函数使用深层网络和浅层网络softmax 输出之间的均方误差(mean-square error, MSE)损失; 由于金字塔池化层的输出有效融合了图像的上下文信息,因此,将深层教师网络的金字塔池化输出作为教师网络的知识, 使用均方误差损失将其蒸馏到浅层网络,提升浅层网络提取特征的能力,进而实现整体网络性能的提升. 基于以上分析,损失函数具体设计如下:
Loss 1:从标签到每一个ResBlock 预测输出的交叉熵损失函数, 数据中的信息直接根据分类器进行学习;

其中,qc,c∈{1,2,··· ,C}是分类器θc/C的softmax 层的输出,y为样本集标签.
Loss 2:所有浅层网络根据最深层的精细分类输出进行自蒸馏的均方误差损失函数, 让浅层Res-Block 具有和最深层网络相当的精细分类效果,增加精细分类准确率;

其中,qc,c∈{1,2,··· ,C}是分类器θc/C的softmax 层的输出,qC是最深层分类器softmax 层的输出.
Loss 3:深层金字塔池化模块后的输出根据最深层金字塔池化结果进行自蒸馏的均方误差函数, 有效利用全局和子区域上下文信息, 增加遥感图像精细分类性能.
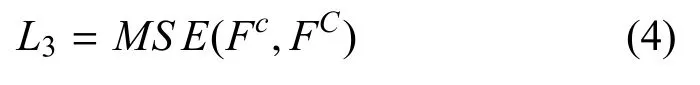
其中,Fc,c∈{1,2,··· ,C}是通过金字塔池化模块块处理后的分类器输出,FC是通过金字塔池化模块后最深层分类器softmax 层的输出.
为了平衡3 部分损失函数的作用,采用3 个超参数: α,β,γ,总损失函数如下:
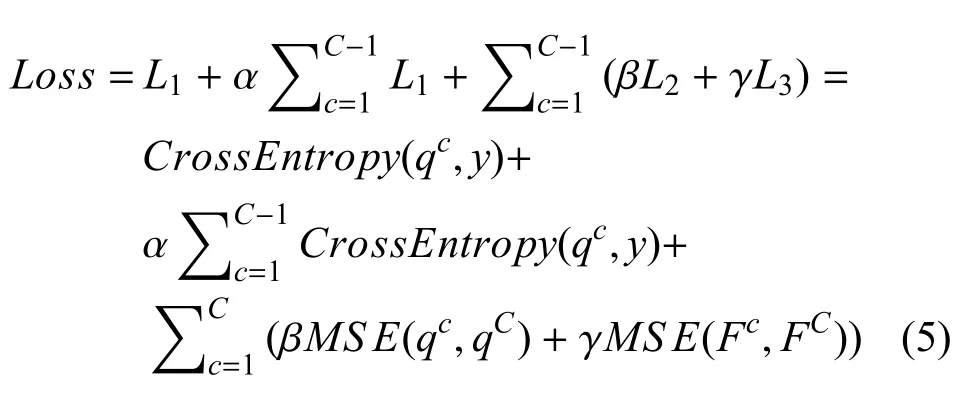
该损失函数包含了ResBlock 作为学生网络的交叉熵损失、教师网络的softmax 输出对浅层学生网络的蒸馏损失, 以及教师网络经过金字塔池化提取的特征图对浅层学生网络的蒸馏损失, 充分利用了深层网络强大的提取特征的能力, 对浅层网络进行知识蒸馏,进而提高网络的整体性能.
2.3 基于知识自蒸馏的复杂遥感图像精细分类
遥感图像精细分类算法总体流程如图4 所示,利用特征提取器对输入图像提取特征, 并送入金字塔池化模块, 进行了3 次蒸馏. 分别为:将每一个Res-Block 作为学生网络进行知识蒸馏、教师网络经过金字塔池化提取的特征对浅层学生网络进行知识蒸馏,和教师网络的softmax 输出对浅层学生网络进行知识蒸馏,最终完成了对特征提取器性能的提升,得到精度提升的精细分类结果.
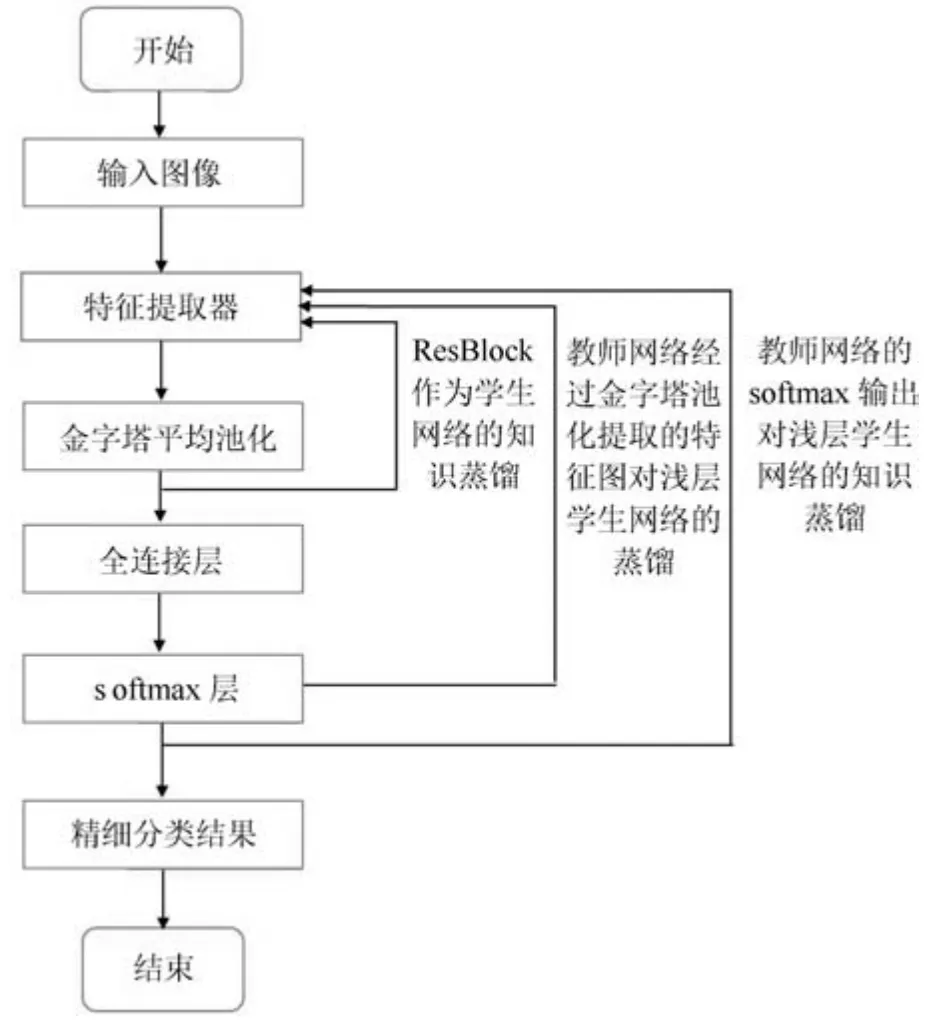
图4 遥感图像精细分类流程图Fig.4 Flow chart of fin classificatio of remote sensing images
3 结果与分析
3.1 数据集介绍
Vaihingen 城市数据集.德国Vaihingen 城市数据集由国际摄影测量与遥感学会(International Society for Photogrammetry and Remote Sensing,ISPRS)提供[25],图像大小根据区域进行确定,共包含6 个类别,包括建筑物、草地、车辆、树木和道路,红色代表背景. 部分数据和标签如图5 所示. 该数据集共含有大小不等的33 幅图像,图像顺序如图6 所示,选取其中23 幅图像作为训练集,10 幅图像作为测试集.

图5 Vaihingen 数据集部分图像和标签Fig.5 Part of the Vaihingen dataset images and tags

图6 Vaihingen 数据集图像顺序Fig.6 Vaihingen dataset image order
Airdataset 城市数据集.Airdataset 城市数据集由中科院空天信息研究院提供[26], 数据来源于worldview 卫星, 分辨率为0.3 m, 图像尺寸为2 000像素×2 000 像素,共包含9 个类别,包括草坪、灌木或树木、土地、不透明水地面、建筑物、道路、水体、交通工具和其他. 部分图像和标签如图7 所示. 该数据集共含有72 幅图像,其中,训练集包含47 幅图像,测试集包含25 幅图像.

图7 Airdataset 城市数据集Fig.7 Airdataset Urban dataset
3.2 评价标准
为评估模型在Vaihingen 城市数据集和Airdataset 城市数据集上的精细分类性能, 与多数分割文献[27−30]采用的指标保持一致,在实验中采用平均交并比(mean intersection over union, MIoU)和像素准确率(pixel accuracy,PA)作为评价指标.交并比是遥感图像精细分类常用的标准度量, 平均交并比则是将所有类的交并比计算平均值; 像素准确率表示所有分类正确的像素数占像素总数的比的比例.假设总共有C类语义标签,nij表示真实语义类别为i但是被预测为像素j的个数,i,j=0,1,··· ,C−1,ti表示真实语义类别为i的像素个数,则平均交并比和像素准确率公式分别为:
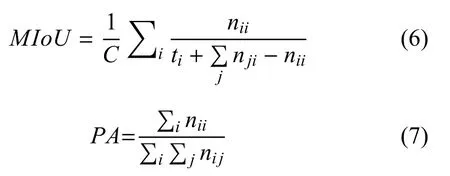
3.3 实验参数细节和参数设置
对于Vaihingen 城市数据集, 实验随机裁取512像素×512 像素图像进行训练, 并对图像进行预处理, 包括随机水平翻转, 使用训练集图像的均值和标准差进行图像归一化; 对于Airdataset 城市数据集, 首先对训练集原图进行切片, 切片大小为512像素×512 像素,共获得1 175 张训练集图像,并使用随机水平翻转和图像归一化进行处理. 测试时,采用重叠率为1/3 的滑动窗口进行预测,窗口大小为512像素×512 像素.
实验在GPU 上进行训练和测试,采用的显卡为Tesla K80 和GeForce GTX 1080Ti,内存分别为12.6 G和16 G.模型基于PyTorch 框架实现,使用单块GPU进行加速.训练过程中,batchsize 设置为2,并使用随机梯度下降算法进行优化,初始学习率设置为0.002.
3.4 实验结果和分析
3.4.1 消融实验
为评估ResNet-ours 模型的性能, 针对ResNetours 模型的每个模块在Vaihingen 城市数据集上进行消融实验, 特征提取器采用ResNet34, 分别对模型进行30 000 轮的训练后测试, 统计实验结果. 其中, Loss1、Loss2、Loss3 分别为ResBlock 作为学生网络的交叉熵损失、教师网络的softmax 输出对浅层学生网络的蒸馏损失, 以及教师网络经过金字塔池化提取的特征图对浅层学生网络的蒸馏损失. 消融实验结果如表1 所示, 当仅使用ResNet-34 行遥感图像精细分类时, 像素准确率为78.54%; 当增加真实标签对浅层网络的监督后, 即在总损失函数中增加Loss1, 像素准确率有了部分提升; 再次增加使用真实标签对浅层网络的监督和自蒸馏损失后, 增加了自蒸馏模块,实现从高层到底层的知识迁移,精度优于前者,但是提升效果较小,这是因为使用自蒸馏模块难以解决上下文信息不够充分的问题; 当使用基于知识自蒸馏的轻量化遥感图像精细分类模型(ResNet-ours)时,精度有了进一步提升. 这个结果验证了ResNet-ours 模型对遥感图像精细分类性能的合理性.

表1 Vaihingen 城市数据集消融实验结果Table 1 Vaihingen urban dataset ablation results
3.4.2 Vaihingen 城市数据集实验结果与分析
ResNet-ours 在Vaihingen 训练集上loss 的变化曲线如图8 所示.

图8 ResNet-ours 在Vaihingen 训练集上loss 的变化曲线Fig.8 ResNet-ours loss curves on Vaihingen training dataset
深度模型在Vaihingen 城市数据集上的精细分类结果如图9 所示,从左至右依次为:RGB 原图、真值图、ResNet18 精细分类结果图、PSPNet18 精细分类结果图和ResNet-ours 精细分类结果图,其中,蓝色代表建筑物,绿色代表草地,黄色代表车辆,浅蓝色代表树木,白色代表道路,红色代表背景. 图9(a)中,阴影面积和车辆数目具有显著不同,第1 幅图像道路较宽,车辆较多,建筑物与道路可以显著区分,并且建筑物阴影面积较大.第1 幅图像草地和建筑物、道路距离较近,道路与部分建筑物颜色较为相近.从图9(c)中可以得到, ResNet 的精细分类结果与真值图相差较大,精细分类出来的信息不够完整,存在斑点区域,即image1 中最大建筑物精细分类不够完整,阴影区域精细分类效果不好; image2 中道路与相似颜色建筑物之间无法区分,精细分类结果不够理想;图9(d)的image1 中,车辆精细分类效果较好,建筑物的精细分类结果仍然不够理想;在image2 中,仍然无法区分道路和相似颜色建筑物;图9(e)中, 在image1 中的大型建筑物的精细分类效果最好, 不再出现斑点现象,并且相对有效地避免了建筑物阴影造成的误判,但是对车辆小目标的检测效果不够理想,在image2中, ResNet-ours 模型能对容易混淆的建筑物与道路作出更好的判别. 与PSPNet 相比, ResNet-ours 模型与实际精细分类效果更为相近,精细分类细节较好,对容易出现误判的位置可以准确作出判断, 精细分类效果有了很好的提升.
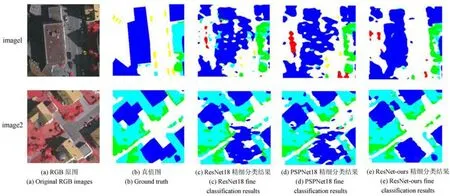
图9 Vaihingen 数据集中深度模型精细分类结果Fig.9 Results of fin classificatio of the deep model in Vaihingen dataset
为了充分验证ResNet-ours 模型的精细分类性能,对模型进行精细分类性能测试,在特征提取阶段,本文采用ResNet18 和ResNet34 作为特征提取器进行特征提取, 在相同条件下, 测试结果如表2 所示.从像素准确率方面来看,ResNet18-ours 和ResNet34-ours 具有最好表现,分别高出PSPNet18 和PSPNet34模型2.31 个百分点和2.22 个百分点,并且ResNet34-ours 较ResNet18-ours 具有更加准确的像素准确率;从平均交并比方面来看,ResNet18-ours 和ResNet34-ours 仍然具有突出表现,分别高出PSP Net18 和PSP Net34 模型2.17 个百分点和2.27 个百分点, 并且ResNet34-ours 较ResNet18-ours 精细分类效果更好.
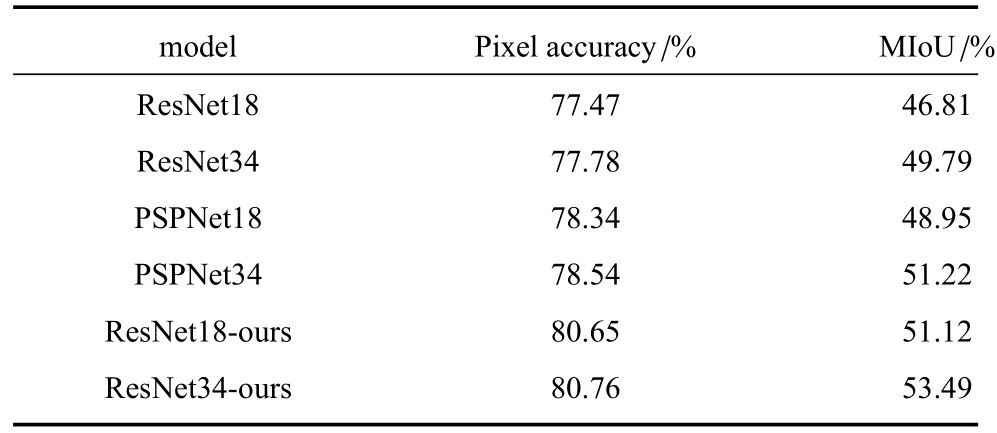
表2 不同深度模型在Vaihingen 测试集上的精细分类评价指标Table 2 Fine classificatio evaluation indicators of models of different depths on Vaihingen training dataset
Vaihingen 城市数据集中的图像共包含5 个目标类和1 个背景类,为了衡量ResNet-ours 在该数据集上各个种类的交并比,更好地体现ResNet-ours 模型的有效性, 对此进行统计, 如表3 所示, 可以看出ResNet18-ours 除了在车辆上的检测结果不够理想外, 在其他类别上的像素准确率及平均交并比的性能都有所提升,因此,本文模型在精细分类数据集上具有良好效果, 可以作为前沿的遥感图像精细分类方法进行应用.

表3 不同深度模型在Vaihingen 测试集上每种类别的像素准确率和平均交并比Table 3 Pixel accuracy and mean intersection over union for each category of Vaihingen training dataset for models of different depths
3.4.3 Airdataset 城市数据集实验结果与分析
在对Airdataset 城市数据集进行实验时, 采用ResNet34 作为特征提取器进行特征提取, 深度模型的精细分类结果如图10 所示, 从(a)~(b)依次为:RGB 原图、真值图、PSPNet 精细分类结果图和ResNet-ours 精细分类结果图,其中绿色表示草坪,墨绿色表示灌木或树木,灰色表示土地,白色表示不透明水地面, 蓝色表示建筑物, 黄色表示道路, 青色表示水体,品红色表示交通工具,黑色表示其他.
通过将PSPNet 模型和ResNet-ours 模型的精细分类结果与真值图对比, 可以较为明显地观察到ResNet-ours 具有显著优势. 例如,在图像左下角区域可以明显观察到,PSPNet 对于建筑物的精细分类具有一定误判,而ResNet-ours 则与真值图更为相近.因此,采用ResNet-ours 在遥感图像数据集上进行精细分类具有更加精确的效果.
4 结论
提出基于知识自蒸馏的轻量化复杂遥感图像精细分类方法, 通过在自蒸馏阶段引入金字塔池化模块, 融合不同尺度的特征信息, 加强特征图上该通道包含的信息量,进而有效利用全局上下文信息,在ISPRS 提供的德国Vaihingen 城市数据集和我国自有的高分遥感数据集上取得了较好的实验性能, 实现了面向大规模遥感图像的地物要素自动分类和提取,为高效、精准构建数字化战场环境夯实基础.
