科技文献挖掘工具平台与关键技术综述
2021-02-12白如江赵梦梦张玉洁董坤
白如江*,赵梦梦,张玉洁,董坤
山东理工大学,信息管理研究院,山东 淄博 255000
引言
《中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要》中指出要构建国家科研论文和科技信息高端交流平台,这也是加强国家战略科技力量的重要举措之一。毋庸置疑,在大智物移云时代,数据已成为社会发展的核心战略资源,如何从海量信息数据中精准挖掘有价值的信息,并转化为解决国民经济社会发展中遇到问题的知识情报决策支持,越来越成为社会各界关注的焦点。
科技文献作为重要的知识载体,凝聚着全人类的智慧,科技文献挖掘已被广泛应用于把握科技发展脉络、探测科技研究前沿、洞悉科技竞合态势、识别“卡脖子”技术难题及评价学术影响力等众多领域。然而,随着科技文献数量的爆发式增长,真正有用的知识被嵌入和隐藏在大量无关的自然语言表述中,如何高效并且精准地定位、理解和利用这些有用信息,形成“数据+知识+技术+应用”四轮驱动的科技情报服务,成为当前科技文献挖掘面临的挑战。为系统把握当前科技文献挖掘的研究进展,前瞻科技文献挖掘未来发展趋势,本文将梳理科技文献挖掘的历史发展脉络,科技文献挖掘的数据源情况,科技文献挖掘平台工具情况以及科技文献挖掘的关键技术,并在此基础上对科技文献挖掘未来发展做出展望。
1 科技文献挖掘发展脉络
科技文献挖掘可以分为广义和狭义两种理解。广义来看,文献检索是文献挖掘的数据基础,文献计量、文本挖掘是文献挖掘的技术手段,知识发现是文献挖掘的主要目的,可视化是文献挖掘的一种展示形式,都可认为是科技文献挖掘活动。狭义理解指针对科技文献全文本内容利用文本挖掘、自然语言处理等计算机技术自动进行信息抽取、理解、融合等,从而实现知识发现。本文将聚焦狭义理解,兼顾广义理解展开论述。
在广义理解上,科技文献挖掘可以追溯到1945年美国学者维纳·布什(Vannevar Bush)在《大西洋月刊》上发表的《诚如所思》(As We May Think)。该文章提出了一种用于文献自动检索挖掘的机器设想Memex,这一思想也开启了利用计算机技术进行科技文献挖掘的历史[1]。1954年,美国海军兵器中心把文献号和少量检索词输入计算机,建立了世界上第一个计算机文献检索系统[2]。1958年,卢恩等人利用计算机编制了上下文关键词索引(KWIC), 这是人们在实现索引编制工作自动化方面最早的尝试[3];1961年,美国化学文摘社在此基础上成功研制了化学题录[4]。1963年,Garfield 提出了科学引文索引(Science Citation Index, SCI),开启了利用文献计量方法进行科技文献挖掘的新时代[5]。此后,学者们围绕期刊影响因子、文献被引频次等进行了科技文献挖掘,提出了“共被引分析”、“共被引相似度”、“共被引轻度”、“文献耦合分析”等思想以及科学地图的概念,并开发了HistCite、VxInsight 等科技文献可视化工具。1965年,Price 提出了利用科技文献共被引分析方法识别科学研究前沿的思想[6]。1985年,芝加哥大学Swanson 教授提出了利用非相关文献知识发现的方法进行文献分析和挖掘[7]。到了20 世纪90年代,随着计算机技术的发展,科技文献挖掘逐步深入到科技文献文本内容进行分析。1992年,美国海军研究总署(ONR)的Kostoff 博士提出了数据库内容结构分析方法,从科技文本内容出发,通过共现窗口分析科技文献内部词语的共现关系,进而发现科技文献的主题热点等[8]。1995年以后,随着互联网商业化,各类科技文献网络数据库也如雨后春笋般蓬勃发展起来,各类数据库的建立为科技文献挖掘提供了坚实的数据保障。
进入21 世纪以来,科技文献挖掘研究一方面在数据源端不断提升数据的质量,另一方面借助飞速发展的计算机信息处理技术更加深入到文本内容挖掘科技文献蕴含的宝贵知识,特别是统计机器学习和深度学习的方法,例如:LDA 主题模型[9]、word2vec、循环神经网络、卷积神经网络[10]等。通过LDA 主题模型可以有效识别科技文献中的研究主题,利用循环神经网络可以对科技文献内容进行命名实体识别,自动标注科技文献中蕴含的新理论、新方法、新材料、新工具等。在此期间涌现出了一大批具有代表性的科研成果,比如:佐治亚理工学院Alan Poter 教授致力于利用专利等科技文献将文本挖掘技术用于技术预测与评估[11];印第安纳州立大学布卢明顿分校的Katy Börner 教授开发了Sci2工具用于科技文献文本内容挖掘,并出版了《Atlas of Science—Visualizing What We Know》图书介绍科学地图;美国Drexel 大学陈超美教授开发了CiteSpace,成为文献计量学和文献挖掘的重要工具,并广泛使用[12];荷兰莱顿大学Ludo Waltman 教授开发了科学知识图谱绘制软件VOSviewer,可以处理大规模的文献数据,具有极强图形展示能力[13];中国科学院文献情报中心开发了SciAIEngine,以科技文献大数据为数据源,实现了科技文献摘要语句识别、自动科技文献分类、科技文献关键词、命名实体、概念定义句自动识别等功能[14]。此外,中国科学院成都分院张志强、胡正银等开发了干细胞领域知识发现大数据平台,清华大学唐杰团队开发了科技情报大数据挖掘与服务系统平台Aminer 等[15],这些工具与平台极大地丰富了科技文献挖掘方式,降低了科技文献挖掘的技术门槛,为科研工作者提供了极大的便利。
在科技文献挖掘的应用场景上,中国科研团队更加注重面向国家重大战略需求展开重大科技文献挖掘研究项目,比如:中国科学院科技战略咨询研究院冷伏海团队自2015年起编制《研究前沿》系列报告[16],从科技文献中洞悉科学研究前沿,2020年发布《技术聚焦》[17],利用专利文献识别当前技术焦点,为我国科技领域前沿准确把握和未来发展趋势预测做出了重要贡献。中国工程院致力于工程技术前沿挖掘[18-19],为科研工作者研究前沿与技术解读提供参考范本。
随着学科交叉融合发展,科技文献挖掘与计算社会科学、科学学等领域相互交织,并逐渐向各个子领域下沉。例如,2009年,David Lazer 等15 名来自不同学科领域的学者在Science 发表《Computational Social Science》[20],提出“计算社会科学”,其中提及利用技术与数据来更新科学研究的范式。2018年,Fortunato 等14 名学者在Science 发表《Science of science》[21]提出“科学学”研究,致力于利用科学研究的大数据来发现具有普遍性或者跨领域性的科学规律,为科技政策评估、学术创新研究提供更大的驱动力。
总体而言,科技文献挖掘的发展过程伴随着文献计量、信息检索、知识发现等领域的发展,这些概念之间既有联系又有区别。文献计量和信息检索等方法有效地推动了科技文献挖掘的发展,这些方法也极大地增强了基于科技文献的知识发现能力。
2 代表性科技文献挖掘工具系统介绍
工欲善其事,必先利其器,科技文献挖掘离不开科学高效的工具。本文系统总结分析了目前在支持科技文献引文分析、著者耦合分析、社会网络分析、科技文献文本内容挖掘方面的重要工具,并对不同工具在支持文献数据源、挖掘维度、可视化功能等维度进行了比较分析,解决了科技文献挖掘“用什么工具挖”的问题。
2.1 科技文献引用网络挖掘工具介绍
引文分析工具主要是对文献中的参考文献进行挖掘和分析,运用直接引文分析、共被引分析、耦合分析等方法进行分析,挖掘高被引论文、高影响力论文、高质量论文。目前使用频率比较高的主要有HistCite[22]、CitNetExplorer[23]、Citespace[12]、VOSviewer[24]、SCI2等, 见表1。

表1 科技文献网络分析挖掘工具Table 1 Network mining tools for S&T literature
2.2 科技文献文本内容挖掘工具介绍
通过科技文献内容挖掘工具可以深入到科技文献文本内容进行挖掘分析,比如文献的标题、摘要、关键词甚至是全文,运用词频分析、共词分析、主题分析等方法对科技文献进行分析,挖掘蕴含在文献中的研究主题、研究前沿、关键技术、新思想、新材料、新方法等内容。目前,主要的开 源工具 有KNIME[25]、RapidMiner[26]、ORANGE[27]、 PubMedMiner 等,商业挖掘工具有IBM SPSS Modeler、Tableau 等,如图2 所示。
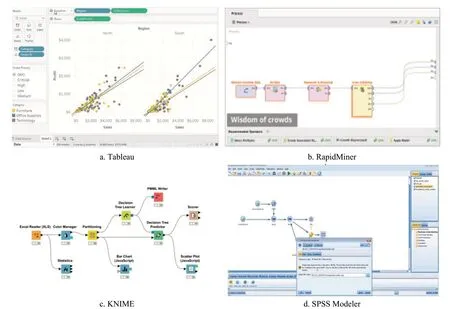
图2 科技文献文本内容挖掘工具Fig.2 The content mining tools of S&T literature mining
KNIME 平台最初由康斯坦茨大学的工程师团队开发,旨在成为一个协作和研发平台,能够运行各种数据项目。用于科技文献挖掘的文本预处理、决策树分类器、KNN 分类器、K-means 聚类、LDA 主题模型等众多模型、算法都能够运行在该平台上。此外,KNIME 还能够集成文本、数据库、图像等多种类型数据,同时支持R 语言和Python 语言脚本扩展,提供更加美观的可视化产品。
RapidMiner 是一个世界领先的数据挖掘工具,采用JAVA 语言开发,其特点是拖拽建模,自带1500 多个函数,无需编程,简单易用。通过Rapid-Miner 工具可以实现科技文献内容挖掘的大部分功能需求。
ORANGE 是面向初学者的数据挖掘和可视化的强大的工具箱,不需要编程或深入的数学知识,只需要可视化的操作就可以完成文献数据的挖掘和知识可视化。ORANGE 最早起源于1997年的WebLab会议上,它包含大量数据科学和机器学习的常见算法,同时提供Python 扩展库和脚本功能,快速实现自己想要的定制化功能。
此外,Gephi[28]、Pajek[29]等社会网络分析工具,能够在文献内容挖掘工具基础上进行文献共词分析、作者贡献分析等。
2.3 科技文献挖掘系统平台介绍
科技文献挖掘系统平台是科技文献挖掘的数据源基础,也是解决科技文献挖掘“从哪里挖”的问题。随着大数据时代的到来,科技成果的快速涌现导致科技文献数量激增,与此同时,不同学科研究领域之间相互渗透、交叉,单一数据源越来越无法满足研究需求,如何在科技文献洪流保障其数据源的完整性、可靠性、全面性成为科技文献挖掘的新挑战。
科技文献检索平台是科技文献挖掘系统平台获取可信科技文献数据源的重要手段,科技文献挖掘系统平台通过对获取到的科技文献的外部特征、文本内容等进行关联呈现、细粒度分析等深入挖掘,发现隐含、新颖且富有价值的科技知识,满足科研人员的不同层次知识需求。
科技文献挖掘系统平台的数据来源主要包含科技论文数据、专利数据、各个国家地区研究机构的基金资助项目数据、科技规划文本数据等文献类型。随着计算机技术、数字图书馆技术的发展,在科技文献元数据标准制定、数据互操作、资源共享上逐步规范,数据质量不断提升。特别是随着大数据、人工智能时代的到来,科技文献的细粒度标引,并集成各类挖掘工具,融合不同数据源的平台逐步成为趋势。比如:Dimensions[30]、LENS[31]、Europe PMC[32]、AMiner[15]等,见表2。
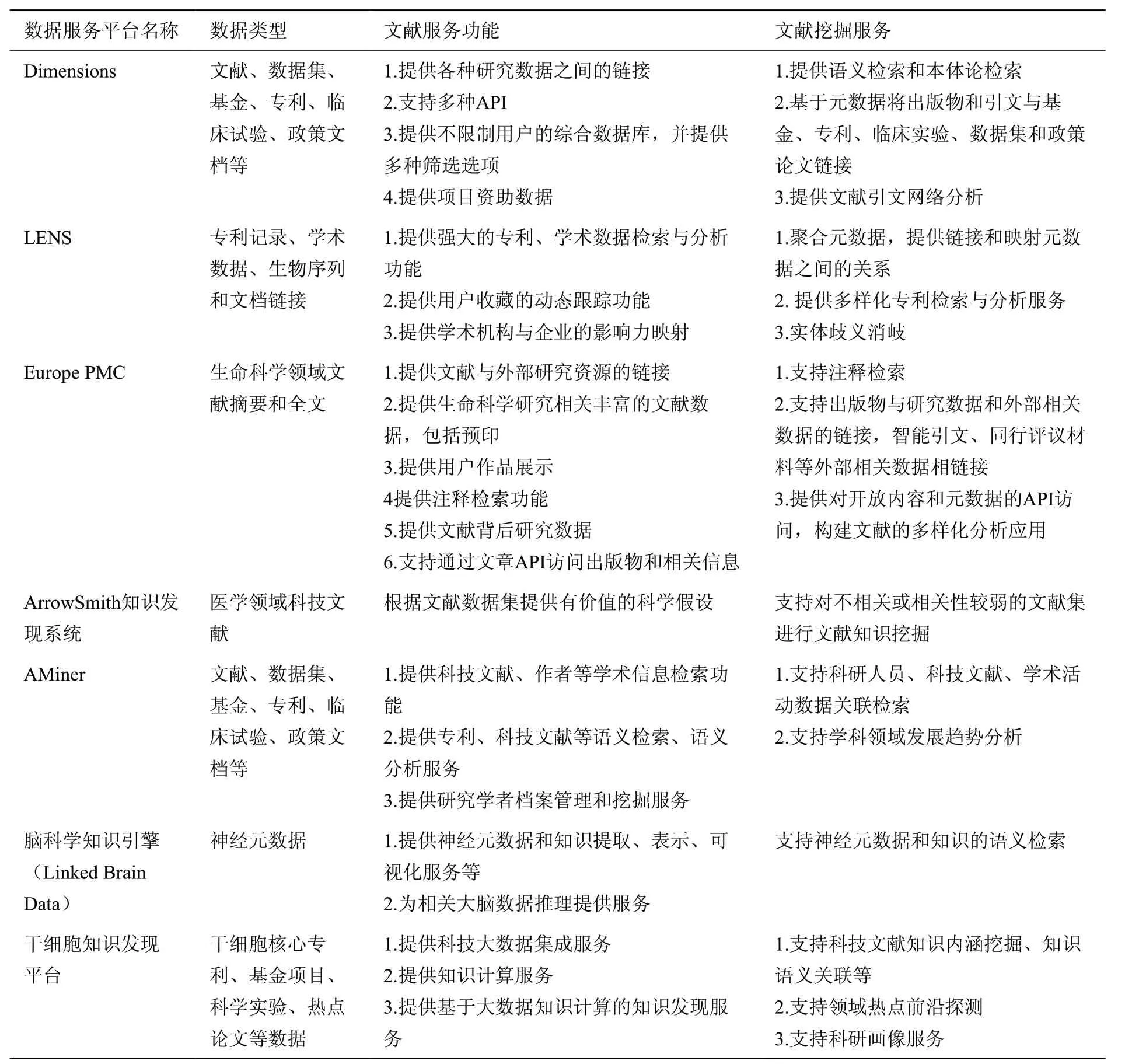
表2 科技文献数据与挖掘分析平台Table 2 S&T literature data and mining analysis platform
3 科技文献挖掘关键技术及其发展趋势
科技文献挖掘始终依靠计算机技术的发展而不断持续推进,挖掘技术始终是解决科技文献挖掘“怎么挖”的法宝。当前,科技文献挖掘的关键技术主要包括基于文献计量方法、基于文献内容的挖掘方法,以及融合智能推理的方法等,各方法下的具体技术见表3。不同方法对科技文献挖掘具有不同作用,有些方法需要融合使用。

表3 科技文献挖掘关键技术Table 3 Key technologies of S&T literature mining
3.1 基于文献计量思想的挖掘方法
早期,计算机处理技术和硬件处理能力还不够强大,科技文献挖掘主要集中于文献外部特征信息,例如影响因子(Impact Factor)[33]、被引频次(cited frequency)、h 指数(h-index)[34]等。研究者多用数学与统计方法,定量地描述知识载体[35-36],以文献计量学为代表的科技文献挖掘研究发展迅速。
F.T.Cole 和N.B.Eales 在1917年首次提出利用文献计量的方法研究科学研究论文,探讨了文献统计方法及其意义。之后,E.W.Hulme 利用文献统计方法研究科技进步要素,着重通过专利数据来研究国家科学技术发展情况[37]。20 世纪中期,在大量研究基础上总结了学术文献演化较为一般化的规律特征,其中最具代表性的是“三大定律”:洛特卡定律[38]、 齐普夫定律[39]、布拉德定律。1963年Garfield 提出 的科学引文索引(Science Citation Index, SCI)[5]为科技文献的度量、评价提供了重要参考,此后,许多学者围绕影响因子、被引频次等指标展开研究,主要涉及定量统计方法的创新及在各个学科领域的具体运用。1973年,Henry Small 发表论文介绍了一种新的研究方法——“共被引分析”[40],将基于文献挖掘的科学结构研究和研究前沿探索带入了一个新的时期。随着出版形式的变化和web2.0 的出现,出现了替代计量学(Altmetrics)的分析方法,Costas等比较了替代计量学与引文分析等指标之间的差 异[41],作者表示替代计量反映的文章价值与引文工具有所不同,能够作为引文分析的补充工具,发挥其应有价值,二者并不存在相互矛盾关系。
基于计量思想的科技文献挖掘方法多依靠文献外在计量指标来人工构建规则,能够简单、快速地统计知识变化规律,在特定场景下能够发挥巨大作用。但是,其存在的问题同样不容忽视:
首先,计量方法难以深入到文献内部,难以准确地剖析结构化的知识体系。其次,随着学科交叉现象日渐深化,单一计量指标发挥的能力捉襟见肘,尤其面对多学科融合的交叉研究时,难以反映细粒度、精准化的表征内容。再次,随着计算机技术、自然语言处理技术的进步,计量指标缺乏与文献全文内容挖掘的融合。
因此,单纯基于计量指标难以深入挖掘文献内容特征,随着自然语言处理技术逐渐成熟,“计量+内容挖掘”方法逐渐成为主流的文献挖掘方法。
3.2 基于科技文献内容挖掘的方法
科技文献中包含丰富的新思想、新理论、新方法、新材料、新工具等知识,以及众多的概念、定理、图表,还包括学者、机构和各类资助体系。因此,针对科技文献全文本的知识发现方法成为近年来最为主流的研究范式。
在挖掘技术方法上主要有简单规则、统计机器学习和各类深度学习的方法。在科技文献内容挖掘的应用场景上有知识主题发现、学术创新评价、篇章结构识别、学科交叉融合等。
3.2.1 简单规则方法
简单规则的文献内容挖掘与计量思想的方法类似,都是通过手工构建特征来匹配文本或挖掘关键要素。常见的方法例如词频统计、人工编码特征、社会网络分析、布尔检索和统计规则等。
(1)基于词频分析的挖掘方法
词频分析是最为简单、直接的文本挖掘方式,即通过统计文中出现的词的频率来发现高频词,以此来表示不同的词的重要程度。词频统计思想在科技文献挖掘中产生了很深的影响,例如,基于词频统计演化出了基于0/1 的二进制文本编码方法[42]和基于计数的文本编码方法[43],这些方法为后续的文本表征和向量化奠定了非常重要的基础。
(2)基于句子表示的挖掘方法
词的统计分析只能反映文献的局部特征,由词向句子挖掘的过渡能够体现出更加全面的内容表达。基于句子的表达是运用统计方法将单个词组成有意义的序列,再通过频率或概率计算得到句子的向量表达,其中BOW[44]和N-gram[45]是两个具有代表性的句子表示方法。例如,有文章通过N-grams 方法实现阿拉伯文本内容搜索挖掘[46]并达到良好效果。
(3)基于社会网络分析的挖掘方法
作者合作网络[47]、共词网络[48]等社会网络分析方法能够有效揭示关键词、学术合作、主题关联的演化发展情况[49]。例如:共词网络可以通过文献中词汇的共现状况来反映文章之间的关联程度,从而分析学科之间的研究相似程度、学科交叉热点等。Su 等发文揭示了基于共现关键词映射的知识结构识别和技术前瞻发现的研究[50],作者分别构建了一个三维的偏标网络和一个关键词共现网络,以及二维的知识网络,从而发现知识结构的变化,采集不同的学术观点。大连理工大学陈悦、王贤文等分别提出被引频次的影响因素研究[51]和专利共被引聚类分析的研究[52],分别探讨了专利、论文等文献成果的引用网络关系和被引的内在机理。
值得注意的是,基于社会网络分析的方法除了分析引文信息外,更是逐渐向全文本内容的计量分析拓展。例如,Liu 等人在2013年提出全文引文分析(Full-text Citation Analysis)的方法,作者通过有监督的主题建模和网络分析方法从全文文献中发现主题并对创新指标排序,以此衡量学术论文的创新程度[53]。章成志等通过分析165 篇相关文献,调研了学术文献的全文本内容评价,作者得出结论认为未来的计量方案和学术评价将会向内容特征转移并深化至语义和语用层面[54]。胡志刚[55]、白如江[56]等学者同样认为未来的学术评价和文献挖掘将融入于全文内容的计量评价分析。
此外,由于社会网络分析大都来源于图论的相关理论,因此借助图论算法能够实现多样化的文献分析。例如,2019年,美国西北大学王大顺团队在Nature 发文分析了科学研究的引文网络,并采用回归分析方法揭示了团队规模与一些指标之间的联 系[57],作者提出“小团队提出创新,大团队继承创新”的研究,他们在分析了大量论文、专利、代码后,发现小型研究团队善于提出问题,而大规模团队更擅长解决这些问题,科研政策应当鼓励不同规模的研究团队,支持多样性的科学研究,以促进学术生态平衡发展。此外,该团队在科学学[21]、科学影响力评价[58]等方面展开一系列研究。其他的算法诸如网络的度、中心性、最短路径、拓扑结构与社会网络、知识网络的结合,能够简单有效地衡量知识创造、组织、传播的过程[59-62]。
3.2.2 统计机器学习方法
统计机器学习是利用计算机构建概率统计模型并运用模型对数据进行挖掘、预测与分析的一种方法。统计学习主要分为监督学习(supervised learning)、无监督学习(unsupervised learning)和强化学习(reinforcement learning)等。统计机器学习方法伴随着计算机算力的提升和科技文献数量的增长,推进了科技文献挖掘的知识发现发展,LDA、TD*IDF 等重要算法一直延续至今,产生了深远影响。
(1)关键词挖掘方法
TF-IDF[63]是一种基于关键词统计分析的算法,融合了词频和逆文档频率,强调关键词对于单篇文献的普遍性和对于整个语料库的特殊性,解决了单一词频统计所导致的无意义词过多的问题。TextRank 算法[64]继承了PageRank 的基本思想,运用同样的理念,将单个词视为网页中的节点,单词之间的连通视为网页之间的跳转,通过高阶马尔可夫过程不断调整滑动窗口,计算词的共现概率。由于PageRank 的通用性较高,所以TextRank 同样能应用于文献自动摘要任务中[65]。
除了TF-IDF 和TextRank 两种经典的算法,许多学者在科技文献关键词抽取方面提出了许多创新技术方法:例如,章成志等提出一种基于条件随机场(Conditional random fields,CRF)的文献关键词抽取算法[66],并验证了其有效性。陆伟等提出从学术文献的标题中抽取结构功能,作者以The Journal of the Association for Information Science and Technology (JASIST) 2000年-2012年间的300 篇文献为数据源,同样运用CRF 抽取其中的关键词;该团队后续又提出从学术文献的全文内容中抽取关键词[67],将支持向量机(Support Vector Machine, SVM)[68]引入到关键词抽取算法中。
(2)基于语言模型的挖掘方法
语言模型是文献内容挖掘的重要技术方法,语言模型是根据语言客观事实而进行的语言抽象数学建模,主要有统计语言模型(比如:n-gram model),神经网络语言模型(比如:NNLM(Neural Network Language Model)、RNNLM 等)。在语言模型中,最著名的莫过于Mikolov 等人于2013年提出的Word2Vec。Word2Vec 设计了一种简单神经网络,输入文本内容,通过计算文本序列概率,将每个词映射到N 维的向量空间中得到词向量,其中神经网络层包括CBOW 和Skip-gram 两种结构,CBOW 即通过词的上下文信息预测当前词,Skip-gram 是已知某个词的情况下预测周围词。
Word2Vec 由于其无监督式的训练方法和简单有效的实现方式得到了广泛应用。许多研究者应用该模型于文本挖掘和知识发现。例如,Tshitoyan 等人2019年在Nature 发文,基于词向量技术从材料科学的文献中挖掘了潜在知识[69],作者借助于Word2Vec模型特性,从三百多万篇包含材料科学、物理学、化学的文献中进行建模、表征,从而发现未来能够被重新使用或具有潜在价值的新材料。Science、PNAS 等期刊发文章表示,有研究将男性与女性之间的个性差异、职业差异映射到词向量中,通过计算二者的距离来衡量性格、性别、民族之间的差异化影响,为定量化地研究社会科学实验提供了重要参考尺度[70-71]。
Word2Vec 的提出启发了许多重要的语言模型。Barkan 等人提出Item2Vec[72],创新性地把词的向量化迁移到其他领域,作者提出可以将单个的物品、文献、作者、机构等均视为一个item,同样采取Skip-gram 训练方式,应用于协同过滤的推荐系统算法,取得了良好效果,这一模型的提出意味着具备先后关系的集合能够被视为序列化的向量表示对象。也有研究者将时序关系拓展到更复杂的图结构,为非关系型的网络提供了更巧妙的向量化表征方式。DeepWalk[73]率先提出通过随机游走(Random Walk)[74]的方式,从网络的任意节点出发生成序列,为图的采样策略提供了重要启发;Grover 等人提出Node2Vec[75],在DeepWalk 的基础上增加了深度优先游走(Depth-first Sampling, DFS)和广度优先游走(Breadth-first Sampling, BFS)两种策略。
随着基于统计机器学习的语言模型的完善,其应用场景也从计算机领域扩展到更广阔的社会学、民族学、经济学、医学、图书情报等跨学科研究中,并与其他方法结合,在文献挖掘、知识发现方面做了许多具有价值的研究。有研究通过收集大规模期刊、文献数据,挖掘了期刊的发文状况,对比了“软科学”与“硬科学”的文章特征,揭示了知识的创造和组织过程[76]。有研究基于Node2Vec 模型,分析了期刊群落反映在科学计量分析中的有效性,提出了期刊规范化指标,并指出未来值得注意的指标参数[77]。W.Boyack 等提出构筑科学研究的“地图”,作者通过多种相似度计算方法,将自然科学和社会科学的一百余万篇文献映射到“科学地图”上[78],该方法能够直观地反映文献、学科的演化发展、增长衰落的过程,为后续研究提供了重要参考价值。崔雷、钱庆等学者致力于医学文献挖掘,在药物作用发现[79]、医学数据库管理[80]、医药知识发现[81]等方面提出许多见解。
(3)主题模型
主题模型是文献挖掘的另一重要工具,在统计机器学习的基础上发展出诸如LSA[82]、LDA[9]、STM[83]、LDA2Vec[84]等不同模型方法。主题模型包含两个重要假设,即每篇文献中包含若干主题,每个主题下又包含若干文献,基于这两个假设,主题模型的核心思想是将文献拆分为句子,将句子拆分为单个的词,为每个词分配到适当的主题下[85]。例如词袋模型LDA 就是通过计算共轭先验概率,将每篇文献的主题以概率分布的形式给出。
主题模型常用于科技文献中的知识主题发现、主题演化分析,反映知识的兴起发展、迁移衰落等动态变化过程。早在上个世纪开始,主题发现就已经被学者研究[86-87],之后随着各种文本挖掘技术、可视化手段的进步,知识主题挖掘方法从简单的聚类分析发展到话题检测[88]、主题演化[89]和知识可视化[90]等方面。
除了主题模型本身,知识主题发现往往交织着数据挖掘算法、文献计量指标、学科领域特性等多个方面,从不同的侧面挖掘科学研究的知识流动、扩散、演化状况[91-92]。例如,Zhou 等人结合文献内容特征和引文特征来研究科学研究的话题演化过 程[93],作者提出了一种新颖的基于引用-内容的LDA 话题发现模型,证明了在文献知识发现方面的有效性。
在国内,许多学者将知识主题发现拓展到更广泛的科技情报分析、知识组织、前沿识别等领域。胡正银等系统地总结了专利文献挖掘的研究进展[94], 归纳了专利挖掘的通用流程和典型应用场景,提出未来应当注重专利文本深层次的语义信息识别和技术演化趋势识别;作者还在个性化语义TRIZ 构建[95]、 学科演化路径[96]方面提出许多见解。此外,朱东华、汪雪峰、李欣、徐硕等学者在专利文献挖掘方面深耕多年,致力于科技文献的主题分析、前沿识别、战略研究,提出了许多颇具参考价值的研究成果[97-101]。
3.2.3 深度学习方法
深度学习方法直接推动了人工智能的又一次浪潮,基于深度学习的文献挖掘一个最大的特征就是开始利用大规模数据来发现知识特征,这也能最大程度上发挥算法、算力、数据相结合的效力,并且随着学科交叉融合趋势越来越明显,深度学习驱动的文献挖掘正在渐渐向各个子领域下沉。
经典的深度学习模型诸如卷积神经网络(Convolutional Neural Networks, CNN)[10]、循环神经网络(Re- current Neural Network, RNN)、长短期记忆网络(Long Short-Term Memory, LSTM)[102]是文献挖掘中应用最 为广泛的模型。之后的Attention、Transformer 等[103]在此基础上提高了模型的专注力,从平均分配权重改变为对局部重点的关注,提高了模型适应性和准确性。这些模型方法无论是知识主题发现、文献篇章识别还是学科交叉研究,均在一定程度上运用到了相关知识。例如,有研究从PubMed 文献中利用深度学习方法抽取作者名称,并提出了解决作者歧义的方案[104]; 有研究设计不同算法来抽取能够表征文献主旨的关键词和影响力指数[105-106];亦有研究从大规模科学文献中抽取实体名称、实体属性,并取得了良好效果[107]。陆伟等曾提出识别学术文献的结构功能[108], 该团队分别从标题[108]、内容[109]、段落[110]等不同粒度识别学术文献的内在结构;并运用Attention机制[111]、BERT 预训练模型[112]等深度学习技术实现文献图表识别[113]、关键词用户行为选择[114]、 学术查询意图分类[115]。
近几年来,随着训练语料的增加,针对大规模预训练模型的研究也逐渐丰富,BERT[116]及其变形体[117]、ERNIE[118-119]、GPT-3[120]等包含超级参数的大模型正在更新文本挖掘的研究范式,传统的从“0”开始训练的方式正在被“Fine-tune”取代,越来越多的研究倾向于基于预训练模型来微调数据。例如,有研究提出研究预印本文献的出版状况[121],作者以arXiv 上的计算机学科为例,应用BERT 模型来映射文献的出版情况,从而发现预印本这一形式对学术研究产生的影响。
深度学习的方法还弥补了传统社会网络分析方法对大规模数据处理的不足,运用各种图神经网络(Graph netural natwork, GNN)[123]研究学术文献中的引文、共现等情况,这种深层次模型结构结合大规模文献数据的方法能够全面、有效地反映学科变化、知识流动状况。例如,有研究基于NLP 和GNN 方法研究了科学学中语义与关系空间的映射[124],对比了不同图神经网络对文献数据的映射关系,结果表明GNNs 的方法能够有效编码科学知识的实体关系和社区演化情况。亦有研究设计了一种融合BERT和图卷积神经网络(Graph Convolutional Network, GCN)[125]的上下文感知的引文推荐模型[126]并取得了良好效果。
综上所述,基于内容的文献挖掘方法从简单规则到统计机器学习再到深度学习模型,技术的发展也伴随着知识发现方法论的不断完善。其中,文献挖掘与文献计量学、计算机科学、NLP 技术、科学学研究、学术评价等不同研究领域交织在一起,学科交叉和融合逐渐深化,每一种技术方法都有其对应的优势和不足,在具体运用时需要考虑具体情况和实际需求进行整合使用。
3.3 融合智能推理的挖掘方法
科技文献全文本内容挖掘能够获取更细粒度的知识,但是当跃向更高阶的认知关系时,其发挥的效力有限,尤其在信息泛滥的时代,从海量、多源、异构的数据中获取有用的情报信息显得尤为重要。因此,如何自动地从大规模科技文献中感知到有用、有效的情报,如何能够实现知识的自动推理、溯因是未来重要的发展方向,这其中涉及到知识图谱、因果推断、因果涌现等因果智能方向。
首先,大规模知识图谱能够为知识推理提供可能。知识图谱的发展将稀疏的知识碎片连接到语义化的知识网络,从单一的领域知识关联成为全局化的学术体系,这种语义化的关联为科技文献挖掘提供了更智能的工具,诸如谷歌知识图谱(Google Knowledge Graph)[127]、微软学术图谱(Microsoft Academic Graph,MAG)[128]、Open Academic Graph[129]、AceKG[130]、SciKGraph[131]等大规模知识库或知识图谱方法能够将信息转换为及时的情报、知识。
此外,因果智能理论为知识的推理、溯因提供推断引擎。文献和知识挖掘由感知向认知的发展过程离不开对因果关系的剖析,因果理论能够揭示事物发展的本质联系[132],能够实现关联、干预、反事实推理等[133],尤其在医学[134]、社会科学、经济 学[135]、计算机科学[136]的发展已经得到广泛关注。
因果涌现[137]对复杂系统的宏观状态做出细粒度、规律性的解释,这种解释同样适用于知识的产生、沉睡、爆发、消亡等生命周期,未来如何借助相关理论挖掘科技文献的涌现规律,揭示知识系统运动的因果规律,是值得关注的重要话题。
因果推断的实验方法、融合机器学习的因果观测方法同样是文献挖掘、知识发现一个值得重视的方面。许多研究者已经着手开始这一方面的研究,例如,著名机器学习学者Bengio 提出因果表示学习[138], 作者期望通过引入因果推断理论提高深度学习的鲁棒性和可解释性。有学者研究了机构知识库对知识创造的因果关系,作者使用经典的随机对照试验方法研究了开放知识库(如维基百科)对学术研究产生的影响,他们认为这些通俗的读物不仅能够反映科学文献的研究现状,更能塑造学术研究,使其向更有益的方向发展。此外,许多研究者应用因果推断方法致力于科研业绩[139]、学术生涯[140]、专利标准[141]、用户画像[142]等不同方面的研究。
因此,未来应当注重应用知识图谱技术、因果推断方法、因果涌现理论来挖掘科技文献中的隐藏观点、潜在原因、因果表达结构等深层次的知识信息。
4 总结与展望
本文对科技文献挖掘的发展历史脉络进行了梳理,对科技文献挖掘的主要工具、系统平台和关键技术进行了全面分析,具体分析了科技文献从哪里挖、用什么挖、怎么挖的问题。图3 详细说明了科技文献挖掘的总体情况。
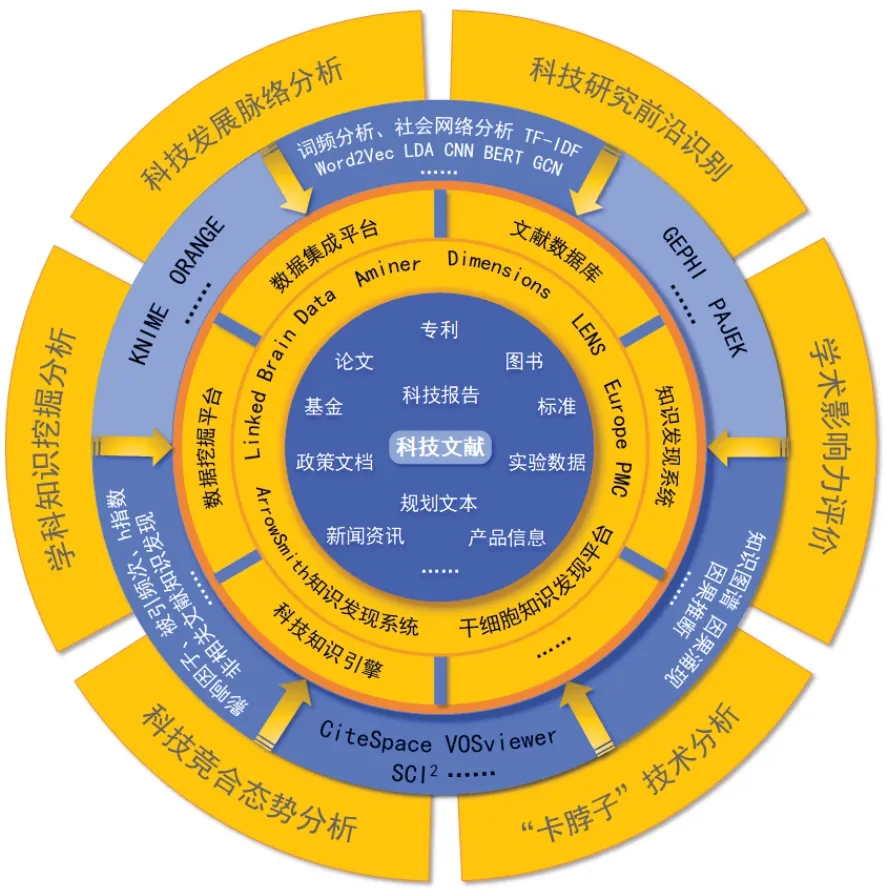
图3 科技文献挖掘总体概览Fig.3 General overview of S&T literature mining
展望未来,科技文献挖掘的发展趋势主要有以下几个方面:
(1)科技文献挖掘将更加注重多源数据的有机融合当前科技文献数量庞大,并且具有多源异构的特点,不同类型的数据源、不同结构数据源蕴含着不同的科学价值,例如专利文献侧重于技术知识,而科技论文侧重于科学知识。随着学科交叉的深度融合,像计算机科学、数学、自动化科学等关联性很强的领域,将局部学科领域的知识进行融合、消岐、对齐,转化为全局化的可被利用的知识是成为科技文献挖掘在数据源建设方面的主要任务之一。多源数据融合一方面是数据内容的深度融合,另一方面是元数据和细粒度知识点的融合,通过多源数据的有机融合能够更加有效地支撑科技文献挖掘的发展。今后,提升多源异构数据的解构、映射、重组与视觉呈现效果和效率,并且尽可能使融合分析结果可以随数据源的变化而自动重组、调整和更新将是重要的方向。
(2)数据源的可信性研究将逐步深入
科技文献挖掘只有依靠可信准确的数据源才能获得有效的结论,当前科技文献数据库中存在大量无效信息和不相关的隐性因素,因此,需要对这些数量庞大、质量良莠不齐的数据源进行知识价值稠密度、时效性、完整性、准确性、可靠性的有效评估。不然,极其容易造成数据挖掘领域内“垃圾进系统,垃圾出系统”的现象。
此外,科技文献挖掘将更加与学术评价相结合,突出评估科技文献的创新价值和内容价值,针对不同质量的文献数据,提供不同程度的挖掘思路。例如,对于创新性高、内容丰富的数据,需要着重挖掘深层次的内涵;对于行文思路晦涩、专业化强的文献,需要结合专业人员与专业背景进行交叉合作。
科技文献可信性研究还要注重对其知识价值稠密度进行评价,以最大限度地降低数据利用成本。未来将会产出更多数据可信性评价模型与方法,例如基于复杂系统的数据可信性评价及面向动态数据的可信性评价等,并且自动化的数据可信性验证模型也将不断被开发。
(3)以因果推断为代表的智能化语义挖掘技术将不断被应用
科技文献挖掘由感知向认知的发展过程离不开对因果关系的剖析,以随机对照试验、准实验设计、倾向得分匹配法、断点回归等为代表的因果智能推理方法为基于科技文献的知识推理与溯因提供了强大的引擎。未来,以因果推断为代表的智能化语义挖掘技术将在科技文献挖掘中广泛应用,特别是将机器学习、自然语言处理与因果推断理论相结合,以提高复杂模型的可解释性和推理能力,从而更好地探索和挖掘科技文献中蕴藏的深层知识。
(4)多维度、细粒化的科技文献语义组织方式将不断被探索
科技文献数据区别于日常的通用语料数据,前者是研究人员的创新思想体现,无论是语言风格还是行文结构,都更加专业化、晦涩化。另外,学术文献包含诸多专业知识、学者、研究机构、参考文献,这些信息在文献挖掘时都是不能忽略的,如何设计有效方法、模型,选择恰当的技术来挖掘有效的知识情报,是具有挑战性的问题。
未来将会有更多多维度、细粒化的语义组织方法和模型产生,并且主要应用于科技文献知识抽取、本体构建、知识图谱构建等过程,从而更加全方位、立体化地挖掘和展现科技文献中蕴含的语义知识。
(5)科技文献挖掘的应用场景将更加丰富
未来科技文献挖掘将更加注重解决国家重大战略需求,在构建国家科研论文和科技信息高端交流平台方面深入研究,在助力国家科技战略力量增强方面也将不断探索。科技论文挖掘在以下方面将凸显其社会价值和理论贡献:一是在深化新时代教育评价改革方面,将深入研究如何破除“五唯”,识别出高质量、高价值的科研成果;二是面对国外科技封锁和“卡脖子”技术,如何尽早准确地识别出潜在科技前沿、颠覆性技术以及产业关键核心技术为政府决策提供准确的数据支持,前瞻擘画布局科研方向;三是创新科技文献挖掘基本理论范式,数据、算法、应用并重,逐步突破引文分析束缚,更加注重挖掘科技成果实际贡献;四是科技文献挖掘将服务于社会民生发展的各个方面,例如网络舆情监测与预警、中西医用药规律研究、智慧图书馆、数字人文等。
科技文献挖掘将在挖掘工具、系统平台、关键技术以及应用场景方面全面推进发展,进而解决国民经济社会发展中遇到的与之相关的重大问题。
利益冲突声明
所有作者声明不存在利益冲突关系。
